本頁面說明 AlloyDB Omni 標準可用性參考架構,該架構可透過備份功能提供資料保護。
用途
這項參考架構支援下列情境:
- 您的資料庫可容忍部分停機時間,且自上次備份後可能遺失部分資料。
- 您想保護 AlloyDB Omni 資料庫,避免使用者錯誤、損毀或實體故障 (與伺服器或 VM 映像檔快照不同)。
- 您希望能夠在本機或遠端復原資料庫,甚至復原至特定時間點。
參考架構的運作方式
標準可用性參考架構涵蓋 AlloyDB Omni 資料庫的備份與復原作業,無論資料庫是在主機伺服器上以獨立執行個體形式執行、以虛擬機器形式執行 (安裝 AlloyDB Omni),或是在 Kubernetes 叢集中執行 (在 Kubernetes 上安裝 AlloyDB Omni),都適用這項架構。
雖然標準可用性是基本實作,可盡量減少所需的額外硬體或服務,但隨著資料庫變大,復原時間目標 (RTO) 也會增加。備份的資料越多,還原及復原資料庫所需的時間就越長。資料是否遺失取決於備份類型。如果只定期備份資料檔案,還原時就會遺失上次備份後的資料。
縮短 RPO
PostgreSQL 的持續封存 功能可讓您達到低復原點目標 (RPO),並透過備份啟用時間點復原功能。這個程序包括封存預寫記錄 (WAL) 檔案,以及串流 WAL 資料 (可能傳輸至遠端儲存位置)。
如果只有在 WAL 檔案完整或達到特定間隔時才封存,一旦資料庫完全遺失 (包括目前的 WAL 檔案),復原作業就只能使用最近封存的 WAL 檔案,這表示復原點目標 (RPO) 必須考量潛在的資料遺失。反之,持續傳輸 WAL 資料可將資料損失降至最低。
執行持續備份時,您可以復原至特定時間點。時間點復原功能可將資料庫還原至發生錯誤前的狀態,例如不慎刪除資料表或批次更新錯誤。不過,除非使用暫時輔助資料庫,否則這種復原方法會影響復原點目標 (RPO)。
備份策略
您可以設定將 AlloyDB Omni Postgres 層級備份資料儲存在本機或遠端儲存空間。雖然本機儲存空間的備份和復原速度可能較快,但如果整個主機或 VM 發生故障,遠端儲存空間通常更適合處理這類問題。
非 Kubernetes 備份
如為非 Kubernetes 部署作業,您可以使用下列 PostgreSQL 工具排定備份作業:
- pgBackRest。詳情請參閱「為 AlloyDB Omni 設定 pgBackRest」一文。
- Barman。詳情請參閱「為 AlloyDB Omni 設定 Barman」一文。
或者,如果是小型資料庫,您可以選擇對資料庫執行邏輯備份 (使用 pg_dump 備份單一資料庫,或使用 pg_dumpall 備份整個叢集)。您可以使用 pg_restore 還原。
使用 AlloyDB Omni 運算子在 Kubernetes 中備份
如果 AlloyDB Omni 部署在 Kubernetes 叢集中,您可以為每個資料庫叢集設定備份方案,藉此設定持續備份。詳情請參閱「在 Kubernetes 中備份及還原」。
您可以將 AlloyDB Omni 備份檔儲存在本機或 Cloud Storage 中 (包括任何雲端供應商提供的選項),詳情請參閱圖 1,瞭解可能的備份目的地。
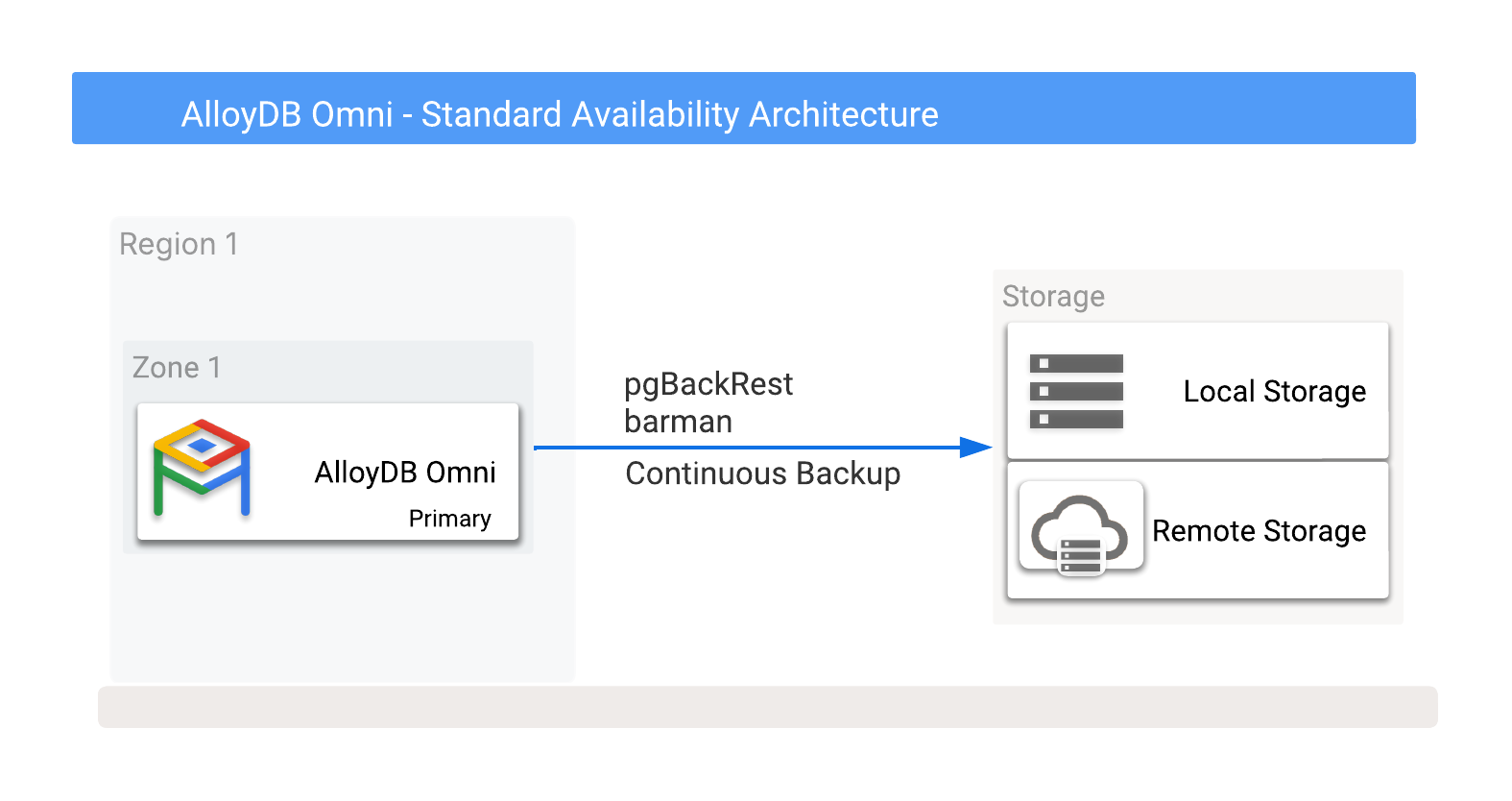
圖 1. AlloyDB Omni 備份選項。
備份作業可儲存至本機或遠端儲存空間。本機備份通常較快,因為只會用到 I/O 處理量,而遠端備份的延遲時間通常較長,網路頻寬也較低。不過,遠端備份可提供最佳防護,包括防範可用區故障。
您也可以將本機備份資料分割到本機或共用儲存空間。如果資料庫主機發生故障,本機儲存空間選項會受到災難復原選項不足的影響,但共用儲存空間可將儲存空間重新定位到其他伺服器,然後用於復原。也就是說,共用儲存空間可能提供更快的 RTO。
如果是本機和共用儲存空間部署作業,可以排定下列類型的備份作業,或視需要手動執行:
- 完整備份:完整備份資料復原所需的所有資料庫檔案。
- 差異備份:僅備份上次完整備份後變更的檔案。
- 增量備份:只備份上次備份後出現的檔案異動。
時間點復原
持續備份 PostgreSQL 預先寫入記錄檔 (WAL) 檔案,支援時間點復原。如果發生失敗事件後,WAL 檔案完好無損且可用,您就能使用這些檔案復原,不會遺失任何資料。
如要控管 WAL 檔案的寫入作業,可以設定下列參數:
| 參數 | 說明 |
|---|---|
|
指定 WAL 寫入器將 WAL 排清至磁碟的頻率,除非寫入作業因非同步提交的交易而提早喚醒。預設值為 200 毫秒。提高這個值可減少寫入頻率,但如果伺服器當機,可能會導致更多資料遺失。 |
|
指定 WAL 寫入器強制將資料排清至磁碟前,可累積的 WAL 資料量。預設值為 1 MB。如果設為零,系統一律會立即將 WAL 資料排清至磁碟。 |
|
指定在 WAL 資料排清至磁碟前,提交是否會將回應傳回給使用者。預設設定為 on,可確保交易持久性。換句話說,在將成功代碼傳回給使用者之前,系統已將提交內容寫入磁碟。如果設為 off,則交易寫入磁碟前最多會經過 wal_writer_delay 次。 |
監控 WAL 使用情況
您可以使用下列方法觀察 WAL 使用情形:
| 觀察方法 | 說明 |
|---|---|
|
這個標準檢視畫面包含 wal_write 和 wal_sync 資料欄,分別儲存 WAL 寫入和 WAL 同步的次數。啟用設定參數 track_wal_io_timing 後,系統也會儲存 wal_write_time 和 wal_sync_time。定期擷取這個檢視畫面,有助於顯示一段時間內的 WAL 寫入和同步活動。 |
pg_current_wal_lsn() |
這個函式會傳回目前的記錄序號 (LSN) 位置,與時間戳記建立關聯並隨時間收集為快照後,即可提供使用 pg_wal_lsn_diff(lsn1, lsn2) 函式產生的 WAL 位元組/秒。這項函式是瞭解交易率和 WAL 檔案效能的實用指標。 |
將 WAL 資料串流至遠端位置
使用 Barman 時,您也可以設定將 WAL 資料即時串流至遠端位置,確保復原時不會遺失資料,或只會遺失少量資料。儘管是即時串流,但由於串流寫入遠端 Barman 伺服器預設為非同步,因此仍有小機率會遺失已提交的交易。不過,您可以使用同步模式設定 WAL 串流,儲存 WAL 並將狀態回應傳回來源資料庫。請注意,如果交易必須等待這項寫入作業完成才能繼續,這種做法可能會導致交易變慢。
備份排程
在大多數環境中,備份作業通常會每週排定一次。以下是典型的每週備份時間表:
- 星期日:完整備份
- 週一、週二:備份
- 星期三:差異備份
- 週四、週五:增量備份
- 週六:差異備份
如果採用這個一般排程,一週的滾動復原時間範圍最多需要三個完整備份,加上必要的增量或差異備份,才能復原。這個方法支援在星期日完整備份期間發生故障時進行復原,且資料庫復原作業必須延伸至備份開始前的上一個星期日。
如要盡量縮短復原時間,並提高復原點目標,您可以讓其他資料庫以持續復原模式運作。這包括重播備份,以及透過封存和重播新的 WAL 檔案,持續更新次要環境。實際 RPO (反映潛在資料遺失) 取決於交易頻率、WAL 檔案大小,以及是否使用 WAL 串流。
在非 Kubernetes 環境中還原
如果是 Kubernetes 以外的部署作業,還原 AlloyDB Omni 資料庫時,必須停止 Docker 容器,然後還原資料,或是將資料還原至其他位置,並使用還原的資料啟動新的 Docker 執行個體。容器重新啟動後,您就能存取資料庫和還原的資料。
如要進一步瞭解復原選項,請參閱「使用 pgBackRest 還原 AlloyDB Omni 叢集」和「使用 Barman 還原 AlloyDB Omni 叢集」。
使用 Operator 在 Kubernetes 中還原
如要在 Kubernetes 中還原資料庫,運算子會從具名備份或時間點 (PIT) 複製作業,將資料復原到相同的 Kubernetes 叢集和命名空間。如要將資料庫複製到其他 Kubernetes 叢集,請使用 pgBackRest。詳情請參閱「在 Kubernetes 中備份及還原」和「從 Kubernetes 備份資料複製資料庫叢集總覽」。
導入作業
選擇可用性參考架構時,請留意下列優點、限制和替代方案。
優點
- 易於使用及管理,適用於 RTO/RPO 寬鬆的非重要資料庫。
- 只需少量額外硬體
- 完整災難復原計畫一律需要備份
- 可復原至復原期限內的任何時間點
限制
- 儲存空間需求可能大於資料庫本身,視保留需求而定。
- 可能需要較長時間才能復原,且可能導致 RTO 較高。
- 視資料庫故障後目前 WAL 資料的可用性而定,可能會導致部分資料遺失,進而對 RPO 造成負面影響。
替代方案
後續步驟
- AlloyDB Omni 可用性參考架構總覽。
- AlloyDB Omni 增強可用性。
- AlloyDB Omni Premium 適用情形。
- 在 Kubernetes 上安裝 AlloyDB Omni。
- 為 AlloyDB Omni 設定 pgBackRest。
- 為 AlloyDB Omni 設定 Barman。
- 在 Kubernetes 中備份及還原。
- 使用 pgBackRest 還原 AlloyDB Omni 叢集。
- 使用 Barman 還原 AlloyDB Omni 叢集。
- 在 Kubernetes 中備份及還原。
- 從 Kubernetes 備份總覽複製資料庫叢集。