本页面介绍了 AlloyDB Omni 标准可用性参考架构,该架构使用备份提供数据保护。
使用场景
此参考架构支持以下场景:
- 您的数据库可以容忍自上次备份以来出现的一些停机时间和数据丢失。
- 您希望在数据库级(而不是服务器或虚拟机映像快照)保护 AlloyDB Omni 数据库免遭用户错误、损坏或物理故障的影响。
- 您希望能够就地或远程恢复数据库,甚至恢复到特定时间点。
参考架构的工作原理
标准可用性参考架构涵盖了 AlloyDB Omni 数据库的备份和恢复,无论这些数据库是在宿主服务器上作为独立实例运行、作为虚拟机运行 (安装 AlloyDB Omni),还是在 Kubernetes 集群中运行 (在 Kubernetes 上安装 AlloyDB Omni)。
虽然标准可用性是一种基本实现,可最大限度地减少所需的额外硬件或服务,但随着数据库的增大,恢复时间目标 (RTO) 也会增加。需要备份的数据越多,恢复和还原数据库所需的时间就越长。数据丢失取决于备份类型。如果仅定期备份数据文件,那么在恢复时,您会丢失自上次备份以来的数据。
减少 RPO
借助 PostgreSQL 的持续归档功能,您可以实现较低的恢复点目标 (RPO),并通过备份启用时间点恢复。此过程涉及归档预写式日志记录 (WAL) 文件和流式传输 WAL 数据,可能传输到远程存储位置。
如果仅在 WAL 文件已满或达到特定时间间隔时才对其进行归档,那么一旦发生完整的数据库丢失(包括当前 WAL 文件),恢复只能恢复到上次归档的 WAL 文件,这意味着恢复点目标 (RPO) 必须考虑潜在的数据丢失。相反,持续 WAL 数据传输可最大限度地减少数据丢失。
在执行持续备份时,您可以恢复到特定时间点。 借助时间点恢复,您可以将数据恢复到发生错误(例如意外删除表或批量更新不正确)之前的状态。不过,除非使用临时辅助数据库,否则此恢复方法会影响恢复点目标 (RPO)。
备份策略
您可以将 AlloyDB Omni Postgres 级备份配置为存储在本地或远程存储空间中。虽然本地存储空间可能在备份和恢复方面更快,但当整个主机或虚拟机发生故障时,远程存储空间通常在处理故障方面更可靠。
非 Kubernetes 中的备份
对于非 Kubernetes 部署,您可以使用以下 PostgreSQL 工具安排备份:
- pgBackRest。如需了解详情,请参阅为 AlloyDB Omni 设置 pgBackRest。
- Barman。如需了解详情,请参阅为 AlloyDB Omni 设置 Barman。
或者,对于小型数据库,您可以选择对数据库执行逻辑备份(使用 pg_dump 备份单个数据库,或使用 pg_dumpall 备份整个集群)。您可以使用 pg_restore 进行恢复。
使用 AlloyDB Omni 操作器在 Kubernetes 中备份
对于部署在 Kubernetes 集群中的 AlloyDB Omni,您可以为每个数据库集群配置使用备份方案的持续备份。如需了解详情,请参阅在 Kubernetes 中备份和恢复。
您可以将 AlloyDB Omni 备份存储在本地或远程 Cloud Storage 中,包括任何云供应商提供的选项。如需了解详情,请参阅图 1,其中显示了可能的备份目标。
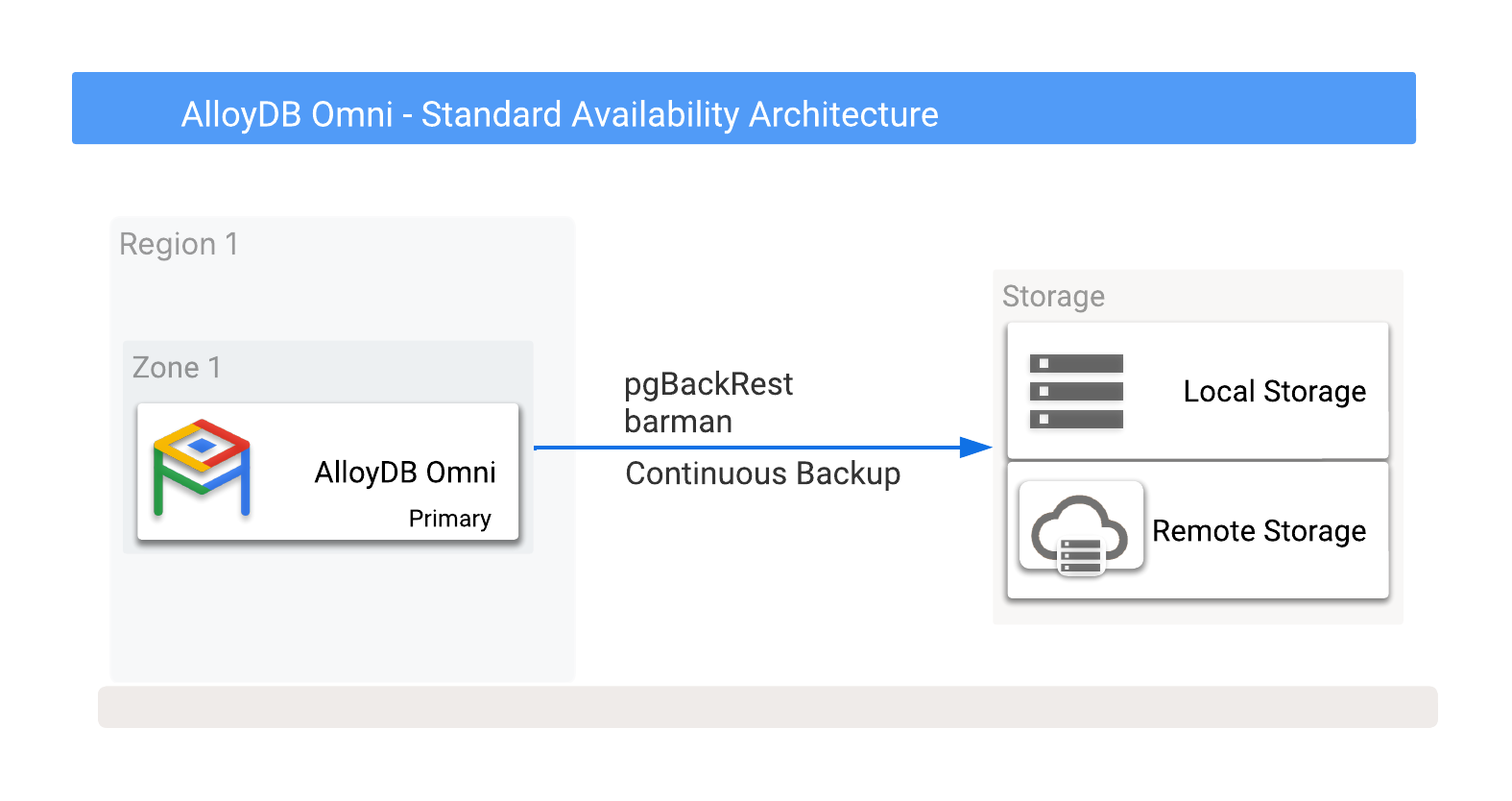
图 1. 具有备份选项的 AlloyDB Omni。
备份可以保存到本地或远程存储空间选项。本地备份往往更快,因为它们仅依赖于 I/O 吞吐量,而远程备份通常具有更高的延迟和更低的带宽。不过,远程备份可提供最佳保护,包括防范可用区级故障。
您还可以将本地备份拆分到本地存储空间或共享存储空间。虽然本地存储空间选项在数据库主机发生故障时会因缺少灾难恢复选项而受到影响,但共享存储空间允许将该存储空间重新定位到另一台服务器,然后用于恢复。这意味着共享存储空间可能提供更快的 RTO。
对于本地和共享存储空间部署,可以按计划或根据需要手动执行以下类型的备份:
- 完整备份:数据恢复所需的所有数据库文件的完整备份。
- 差分备份:仅备份自上次完整备份以来的文件更改。
- 增量备份:仅备份自上次备份(无论何种类型)以来的文件更改。
时间点恢复
持续备份 PostgreSQL 预写式日志记录 (WAL) 文件支持时间点恢复。如果在发生故障事件后,WAL 文件完好无损且可用,则可以使用这些文件进行恢复,而不会丢失数据。
如需控制 WAL 文件的写入,您可以配置以下参数:
| 参数 | 说明 |
|---|---|
|
指定 WAL 写入器将 WAL 刷新到磁盘的频率,除非写入被异步提交的事务提前唤醒。默认值为 200 毫秒。增加此值可降低写入频率,但如果服务器崩溃,可能会增加数据丢失量。 |
|
指定在 WAL 写入器强制刷新到磁盘之前,可以累积多少 WAL 数据。默认值为 1 MB。如果设置为零,则 WAL 数据始终会立即刷新到磁盘。 |
|
指定提交操作是否在将 WAL 数据刷新到磁盘之前向用户返回响应。默认设置为 on,可确保事务具有持久性。换句话说,提交已写入磁盘,然后才向用户返回成功代码。如果设置为 off,则在将事务写入磁盘之前,最多会进行 wal_writer_delay 次。 |
WAL 使用情况监控
您可以使用以下方法来观察 WAL 使用情况:
| 观测方法 | 说明 |
|---|---|
|
此标准视图包含 wal_write 和 wal_sync 列,用于存储 WAL 写入次数和 WAL 同步次数的计数。如果启用配置参数 track_wal_io_timing,系统还会存储 wal_write_time 和 wal_sync_time。定期拍摄此视图的快照有助于显示一段时间内的 WAL 写入和同步活动。 |
pg_current_wal_lsn() |
此函数返回当前日志序列号 (lsn) 位置,该位置与时间戳关联并随时间以快照形式收集时,可使用函数 pg_wal_lsn_diff(lsn1, lsn2) 提供生成的 WAL 的字节/秒。此函数是了解事务速率和 WAL 文件的执行情况的有用指标。 |
将 WAL 数据流式传输到远程位置
使用 Barman 时,还可以将 WAL 数据设置为实时流式传输到远程位置,以确保在恢复时几乎不会丢失数据。尽管是实时流式传输,但仍有丢失已提交事务的可能性,因为默认情况下对远程 Barman 服务器的流式写入是异步的。 不过,您可以使用同步模式设置 WAL 流式传输,该模式会存储 WAL 并将状态响应发送回源数据库。请注意,如果事务必须等待此写入操作完成后才能继续,那么这种方法可能会减慢事务的速度。
备份时间表
在大多数环境中,备份通常按每周一次的频率进行安排。以下是典型的每周备份时间表:
- 星期日:完整备份
- 星期一、星期二:备份
- 星期三:差分备份
- 星期四、星期五:增量备份
- 星期六:差分备份
如果采用这种典型的时间表,为期一周的滚动恢复时段需要存储空间来存储最多三个完整备份以及所需的增量备份或差分备份。此方法支持在星期日进行完整备份期间发生的故障的恢复,且需要将数据库恢复到备份开始之前的上一个星期日。
为了最大限度地缩短 RTO 并尽可能提高 RPO,其他数据库可以在持续恢复模式下运行。这涉及重放备份,并通过归档和重放新的 WAL 文件来持续更新辅助环境。实际 RPO(反映潜在的数据丢失)取决于事务频率、WAL 文件大小以及 WAL 流式传输的使用情况。
在非 Kubernetes 环境中恢复
对于非 Kubernetes 部署,恢复 AlloyDB Omni 数据库涉及停止 Docker 容器,然后恢复数据;或者将数据恢复到其他位置,并使用恢复的数据启动新的 Docker 实例。容器重启后,即可使用已恢复的数据访问数据库。
如需详细了解恢复选项,请参阅使用 pgBackRest 恢复 AlloyDB Omni 集群和使用 Barman 恢复 AlloyDB Omni 集群。
在 Kubernetes 中使用操作器进行恢复
如需在 Kubernetes 中恢复数据库,操作器可从指定备份或时间点 (PIT) 克隆中恢复到同一 Kubernetes 集群和命名空间。如需将数据库克隆到其他 Kubernetes 集群,请使用 pgBackRest。如需了解详情,请参阅在 Kubernetes 中备份和恢复以及从 Kubernetes 备份克隆数据库集群概览。
实现
选择高可用性参考架构时,请注意以下优势、限制和替代方案。
优势
- 易于使用和管理,适用于 RTO/RPO 要求不高的非关键数据库。
- 所需额外硬件极少
- 完整的灾难恢复计划始终需要备份
- 可以恢复到恢复时段内的任何时间点
限制
- 存储空间要求可能比数据库本身更大,具体取决于保留要求。
- 恢复速度可能较慢,可能会导致 RTO 较高。
- 可能会导致部分数据丢失,具体取决于数据库故障后当前 WAL 数据的可用性,这可能会对 RPO 产生负面影响。
替代方案
后续步骤
- AlloyDB Omni 高可用性参考架构概览。
- AlloyDB Omni 增强型可用性。
- AlloyDB Omni 高级可用性。
- 在 Kubernetes 上安装 AlloyDB Omni。
- 为 AlloyDB Omni 设置 pgBackRest。
- 为 AlloyDB Omni 设置 Barman。
- 在 Kubernetes 中备份和恢复。
- 使用 pgBackRest 恢复 AlloyDB Omni 集群。
- 使用 Barman 恢复 AlloyDB Omni 集群。
- 在 Kubernetes 中备份和恢复。
- 从 Kubernetes 备份克隆数据库集群概览。