Esta arquitectura de referencia es la más adecuada para los siguientes casos prácticos:
- Necesitas protección regional además de la protección zonal para tus aplicaciones críticas.
Esta arquitectura de referencia de disponibilidad incorpora réplicas de lectura en la región para la alta disponibilidad y en varias regiones para la recuperación ante desastres. Esta implementación multirregional protege contra interrupciones importantes, como fallos de suministro eléctrico generalizados y desastres naturales a gran escala.
Consideraciones sobre la arquitectura de referencia de disponibilidad
Cuando evalúes esta arquitectura de referencia de disponibilidad, ten en cuenta los siguientes factores:
- Latencia y ancho de banda de la red dentro de la región y entre regiones
- Ubicación geográfica de las bases de datos y los servidores de aplicaciones
- Estrategia para derivar cargas de trabajo de solo lectura a réplicas
- Implementar la alta disponibilidad en la región de recuperación ante desastres remota
Es posible que se requiera un balanceo de carga de solo lectura, sobre todo si usas servidores de aplicaciones regionales, para que las solicitudes se reenvíen a la base de datos más cercana y se obtenga la respuesta más rápida. Para obtener más información, consulta Solicitar enrutamiento a un balanceador de carga de aplicaciones clásico multirregional.
Puede que se necesite una monitorización adicional para la replicación entre regiones con el fin de asegurarse de que la latencia de replicación no empiece a aumentar debido a la carga de transacciones o a la capacidad de la red.
Para asegurarte de que la recuperación ante desastres se realiza correctamente, haz pruebas exhaustivas. Es importante probar la funcionalidad y el rendimiento de las aplicaciones si hay conexiones de red con una latencia alta entre los servidores de aplicaciones y la base de datos.
Arquitecturas de alta disponibilidad en la misma región y de recuperación tras fallos entre regiones
En la figura 1 se muestra una configuración de alta disponibilidad y recuperación tras fallos sugerida con tres bases de datos de réplica de lectura en espera en tres zonas de disponibilidad y dos regiones.
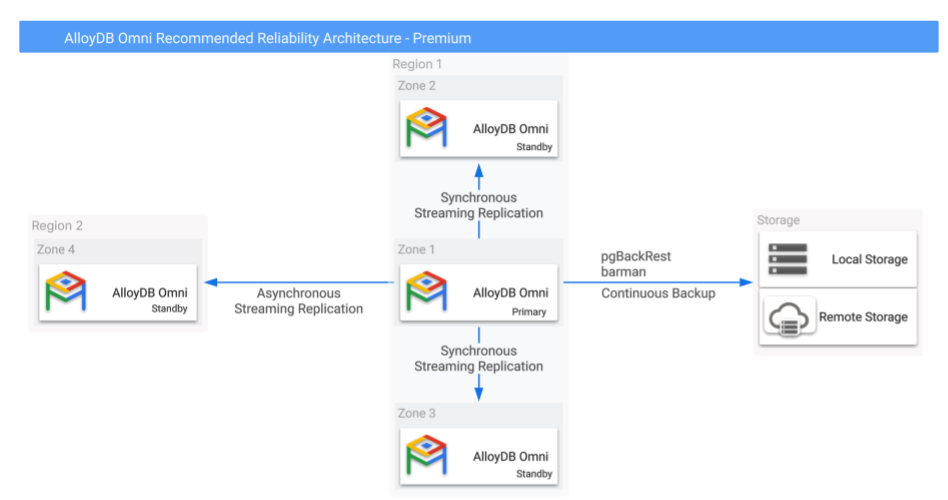
Imagen 1. AlloyDB Omni con copias de seguridad y opciones de alta disponibilidad multirregional.
Como se muestra en la figura 1, la replicación de streaming síncrona en réplicas locales (dentro de la misma región) proporciona alta disponibilidad, mientras que la replicación de streaming asíncrona en una réplica remota geográficamente separada proporciona protección de recuperación tras desastres regional. En toda la configuración, solo la instancia principal puede realizar operaciones de lectura y escritura, mientras que las otras réplicas pueden atender consultas de lectura.
Configura la replicación de la instancia principal a las réplicas de la misma región en modo síncrono, mientras que la replicación a las réplicas de otras regiones se debe configurar en modo asíncrono para evitar que la latencia afecte al rendimiento de escritura de la instancia principal. En caso de que se produzca un fallo regional, esta configuración puede provocar un RPO distinto de cero. Sin embargo, esta configuración permite un tiempo de recuperación más rápido en caso de fallo. Esto se debe a que la base de datos principal no tiene que esperar la confirmación de las bases de datos de reserva remotas para confirmar las transacciones.
Es posible que se creen copias de seguridad entre regiones adicionales a partir de las bases de datos de réplica de lectura y, de este modo, se añada redundancia a las copias de seguridad creadas a partir de la base de datos principal.
Copias de seguridad de réplicas de lectura
Si usas despliegues que no son de Kubernetes, puedes elegir desplegar copias de seguridad que se adapten a las necesidades de tu empresa.
Ten en cuenta lo siguiente:
- Si tu copia de seguridad remota puede verse afectada por un fallo en la región, debes iniciar copias de seguridad adicionales en las regiones alternativas.
- Si necesitas redundancia de copias de seguridad, debes crear copias de seguridad de réplicas de lectura regionales.
Ubicación de la réplica de lectura para admitir la disponibilidad multizona
En las implementaciones que no son de Kubernetes, puedes elegir réplicas de lectura específicas para que asuman el rol de la réplica principal en caso de que esta falle.
Migración de una arquitectura de alta disponibilidad a una de alta disponibilidad y recuperación tras fallos
En las implementaciones que no son de Kubernetes, debes crear una nueva instancia de espera en una nueva región y añadir esta configuración a la configuración del clúster de Patroni.
Implementación
Cuando elijas una arquitectura de referencia de disponibilidad, ten en cuenta las ventajas, las limitaciones y las opciones que se indican a continuación.
Ventajas
- Protege frente a fallos de zona y de instancia
- Protege frente a fallos regionales
- Se reduce el RTO cuando la base de datos sufre un fallo regional
Limitaciones
- Puedes reducir el RPO de la recuperación regional con la replicación síncrona, pero este enfoque provoca una latencia adicional en el rendimiento de las transacciones. Para la recuperación ante desastres y la replicación en regiones remotas, te recomendamos que solo uses la replicación asíncrona.
- Configurar la transmisión de WAL de PostgreSQL en modo síncrono ofrece cero pérdida de datos (
RPO=0) durante el funcionamiento normal o las conmutaciones por error típicas. Sin embargo, este enfoque no protege contra la pérdida de datos en situaciones específicas de doble fallo, como cuando se pierden todas las instancias de espera o no se puede acceder a ellas desde la instancia principal, y a continuación se reinicia la instancia principal.
Opciones de protección de datos
- La arquitectura de disponibilidad estándar para las opciones de copia de seguridad y recuperación.
- La arquitectura de disponibilidad mejorada para las opciones de alta disponibilidad.
Siguientes pasos
- Descripción general de la arquitectura de referencia de disponibilidad de AlloyDB Omni
- Disponibilidad estándar de AlloyDB Omni.
- Disponibilidad mejorada de AlloyDB Omni.
- Trabajar con la replicación entre centros de datos
- Solicitar enrutamiento a un balanceador de carga de aplicación clásico multirregional..