Selon la taille de votre ensemble de données et la complexité de votre modèle, l'apprentissage peut prendre beaucoup de temps. L'apprentissage à partir de données réelles peut durer de nombreuses heures. Vous pouvez surveiller plusieurs aspects de votre tâche pendant son exécution.
Vérifier le statut de la tâche
Pour connaître l'état général de votre tâche, la méthode la plus simple consiste à consulter la page des Tâches AI Platform Training sur la console Google Cloud. Vous pouvez obtenir les mêmes informations par programmation et avec Google Cloud CLI.
Console
Ouvrez la page Tâches d'AI Platform Training dans la console Google Cloud.
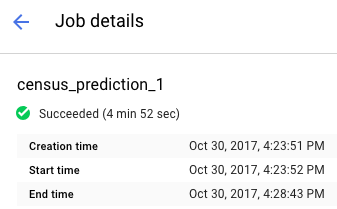
Cliquez sur le nom de votre tâche dans la liste pour afficher la page Informations sur la tâche.
Vous pouvez consulter l'état de la tâche en haut du rapport. L'icône et le texte décrivent son état actuel.
Filtrer les tâches
Sur la page Tâches, vous pouvez filtrer vos tâches à l'aide de plusieurs paramètres, dont Type, JobID (ID de tâche), État, et "Date et heure de création de la tâche".
- Cliquez dans le champFiltrer par préfixe, situé au-dessus de votre liste de tâches. Sélectionnez un préfixe que vous souhaitez utiliser pour filtrer les tâches. Par exemple, sélectionnez Type.
Pour générer le filtre, cliquez sur le suffixe que vous souhaitez utiliser. Par exemple, les options de suffixe du préfixe Type sont les suivantes :
- Entraînement de code personnalisé
- Entraînement à l'aide d'algorithmes intégrés
- Prédiction
Le filtre est appliqué dans votre liste de Tâches. Son nom s'affiche dans le champ de filtre. Par exemple, si vous sélectionnez Entraînement de code personnalisé, le filtre Type:Entraînement de code personnalisé s'affiche en haut de la page et filtre votre liste de tâches. Vous pouvez ajouter plusieurs filtres si nécessaire.
Afficher les essais d'hyperparamètres
Sur la page Informations sur la tâche, vous pouvez afficher les métriques de chaque essai dans la table HyperTune trials (Essais HyperTune). Cette table ne s'affiche que pour les tâches qui utilisent les réglages d'hyperparamètres. Vous pouvez activer/désactiver les métriques pour afficher les essais par filtres rmse, Training steps et learning_rate dans l'ordre croissant ou décroissant.
Pour afficher les journaux d'un essai spécifique, cliquez sur l'icône
gcloud
La commande gcloud ai-platform jobs describe vous permet d'en savoir plus sur l'état actuel de la tâche via la ligne de commande :
gcloud ai-platform jobs describe job_name
Vous pouvez obtenir la liste des tâches associées à votre projet, avec l'état et l'heure de création de chacune, à l'aide de la commande gcloud ai-platform jobs list.
Notez que cette commande, sous sa forme la plus simple, répertorie toutes les tâches créées pour votre projet. Vous devez préciser votre requête afin de limiter le nombre de tâches renvoyées. Les exemples suivants devraient vous y aider :
Utilisez l'argument --limit pour limiter le nombre de tâches. Cet exemple répertorie les cinq tâches les plus récentes :
gcloud ai-platform jobs list --limit=5
Utilisez l'argument --filter pour restreindre la liste aux tâches présentant une valeur d'attribut donnée. Vous pouvez appliquer ce filtre à un ou plusieurs attributs de l'objet Tâche. Outre les attributs principaux de la tâche, vous pouvez filtrer ses objets, tels que l'objet TrainingInput.
Exemples de filtrage de la liste :
Vous pouvez répertorier toutes les tâches démarrées après une certaine date. Dans cet exemple, la date utilisée est le 15 janvier 2017 à 19 heures :
gcloud ai-platform jobs list --filter='createTime>2017-01-15T19:00'Vous pouvez répertorier les trois dernières tâches dont les noms commencent par une chaîne donnée. Par exemple, la chaîne peut représenter le nom que vous utilisez pour l'ensemble de vos tâches d'apprentissage pour un modèle particulier. Dans cet exemple, le modèle utilisé contient l'identifiant de tâche "census", ainsi qu'un suffixe correspondant à un index incrémenté pour chaque tâche :
gcloud ai-platform jobs list --filter='jobId:census*' --limit=3Vous pouvez répertorier toutes les tâches en échec dont le nom commence par "rnn" :
gcloud ai-platform jobs list --filter='jobId:rnn* AND state:FAILED'
Pour en savoir plus sur les expressions disponibles dans l'option de filtrage, consultez la documentation de la commande gcloud.
Python
Assemblez votre chaîne d'identifiant de tâche en combinant le nom de votre projet et celui de votre tâche au format suivant :
'projects/your_project_name/jobs/your_job_name':projectName = 'your_project_name' projectId = 'projects/{}'.format(projectName) jobName = 'your_job_name' jobId = '{}/jobs/{}'.format(projectId, jobName)Formulez la requête en appelant "projects.jobs.get" :
request = ml.projects().jobs().get(name=jobId)Exécutez la requête (cet exemple place l'appel
executedans un bloctrypour relever les exceptions) :response = None try: response = request.execute() except errors.HttpError, err: # Something went wrong. Handle the exception in an appropriate # way for your application.Vérifiez la réponse pour vous assurer que, quelle que soit l'erreur HTTP, l'appel de service a renvoyé des données.
if response == None: # Treat this condition as an error as best suits your # application.Obtenez des données relatives à l'état de la tâche. L'objet renvoyé en réponse est un dictionnaire contenant tous les membres applicables de la ressource Tâche, y compris la ressource TrainingInput complète et les membres applicables de la ressource TrainingOutput. L'exemple suivant affiche l'état de la tâche et le nombre d'unités ML consommées.
print('Job status for {}.{}:'.format(projectName, jobName)) print(' state : {}'.format(response['state'])) print(' consumedMLUnits : {}'.format( response['trainingOutput']['consumedMLUnits']))
Les tâches peuvent échouer si votre application d'entraînement ou l'infrastructure AI Platform Training présente un problème. Vous pouvez utiliser Cloud Logging pour lancer le débogage.
Vous pouvez également utiliser un shell interactif pour inspecter vos conteneurs d'entraînement pendant l'exécution du job d'entraînement.
Surveiller la consommation de ressources
Vous pouvez trouver les graphiques ci-dessous illustrant l'utilisation des ressources de vos tâches d'entraînement sur la page Informations sur la tâche :
- L'utilisation globale du processeur ou du GPU, et l'utilisation de mémoire de votre tâche. L'utilisation est répartie par maître, par nœud de calcul et par serveur de paramètres.
- L'utilisation du réseau par la tâche est mesurée en octets par seconde. Les octets envoyés et les octets reçus se trouvent dans différents graphiques.
Accédez à la page Tâches d'AI Platform Training dans la console Google Cloud :
Recherchez votre tâche dans la liste.
Cliquez sur le nom de votre tâche dans la liste pour afficher la page Informations sur la tâche.
Sélectionnez les onglets Processeur, GPU ou Réseau pour afficher les graphiques associés illustrant l'utilisation des ressources.
Vous pouvez également accéder aux informations sur les ressources en ligne utilisées par vos tâches d'entraînement avec Cloud Monitoring. AI Platform Training exporte ses métriques vers Cloud Monitoring.
Chaque type de métrique AI Platform Training inclut "training" dans son nom. Par exemple, ml.googleapis.com/training/cpu/utilization ou ml.googleapis.com/training/accelerator/memory/utilization.
Assurer la surveillance avec TensorBoard
Vous pouvez configurer votre application d'entraînement de manière à enregistrer des données récapitulatives. Vous pouvez ensuite examiner et visualiser ces données à l'aide de TensorBoard.
Enregistrez vos données récapitulatives dans Cloud Storage et redirigez TensorBoard vers l'emplacement correspondant pour les examiner. Vous pouvez également rediriger TensorBoard vers un répertoire avec des sous-répertoires contenant les résultats de plusieurs tâches.
Pour en savoir plus sur TensorBoard et AI Platform Training, consultez le guide de démarrage.
Étape suivante
- Identifiez et résolvez les problèmes associés à votre tâche d'apprentissage.
- Déployez votre modèle entraîné pour effectuer des tests en ligne et diffuser des prédictions.