Trovare la causa degli errori che si verificano durante l'addestramento del modello o l'ottenimento di predizioni nel cloud può essere difficile. Questa pagina descrive come trovare e risolvere i problemi riscontrati in AI Platform Prediction. Se riscontri problemi con il framework di machine learning che utilizzi, leggi la documentazione del framework di machine learning.
Strumento a riga di comando
- ERRORE: (gcloud) Scelta non valida: "ai-platform".
Questo errore indica che devi aggiornare gcloud. Per aggiornare gcloud, esegui il seguente comando:
gcloud components update- ERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.
Questo errore indica che devi aggiornare gcloud. Per aggiornare gcloud, esegui il seguente comando:
gcloud components update- ERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.
Questo errore indica che devi aggiornare gcloud. Per aggiornare gcloud, esegui il seguente comando:
gcloud components update- ERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\x03'. (Codice di errore: 0)
Questo errore indica che è stata utilizzata la libreria sbagliata per esportare il modello. Per risolvere il problema, esporta di nuovo il modello utilizzando la libreria corretta. Ad esempio, esporta i modelli del modulo
model.pklcon la libreriapicklee i modelli del modulomodel.joblibcon la libreriajoblib.- ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.
Questo errore indica che hai specificato
jsoncome valore del flag--data-formatquando hai inviato un job di previsione batch. Per utilizzare il formato dei datiJSON, devi forniretextcome valore del flag--data-format.
Versioni di Python
- ERRORE: modello non valido rilevato con errore: "Impossibile caricare il modello: impossibile caricare il
- model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Effettua
- Assicurati che il modello sia stato esportato utilizzando Python 2. In caso contrario, specifica
- parametro "python_version" corretto durante il deployment del modello. Al momento,
- "python_version" accetta 2.7 e 3.5. (Codice di errore: 0)"
- Questo errore indica che un file del modello esportato con Python 3 è stato di cui è stato eseguito il deployment in una risorsa della versione del modello di previsione di AI Platform con un'impostazione di Python 2.7.
Per risolvere questo problema:
- Crea una nuova risorsa di versione del modello e imposta "python_version" su 3.5.
- Esegui il deployment dello stesso file del modello nella risorsa della nuova versione del modello.
Il comando virtualenv non è stato trovato
Se hai visualizzato questo errore quando hai provato ad attivare virtualenv, una possibile soluzione è aggiungere la directory contenente virtualenv alla variabile di ambiente $PATH. La modifica di questa variabile ti consente di utilizzare i comandi virtualenv
senza digitare il percorso file completo.
Innanzitutto, installa virtualenv eseguendo il seguente comando:
pip install --user --upgrade virtualenv
Il programma di installazione ti chiede di modificare la variabile di ambiente $PATH e fornisce il percorso allo script virtualenv. Su macOS, è simile a /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Apri il file in cui la shell carica le variabili di ambiente. In genere, si tratta di ~/.bashrc o ~/.bash_profile in macOS.
Aggiungi la seguente riga, sostituendo [VALUES-IN-BRACKETS] con i valori appropriati:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Infine, esegui il seguente comando per caricare il file .bashrc
(o .bash_profile) aggiornato:
source ~/.bashrc
Utilizzo dei log dei job
Un buon punto di partenza per la risoluzione dei problemi sono i log dei job acquisiti da Cloud Logging.
Log per i diversi tipi di operazioni
L'esperienza di registrazione varia in base al tipo di operazione, come mostrato nelle sezioni seguenti.
Log di previsione batch
Tutti i job di previsione batch vengono registrati.
Log di previsione online
Per impostazione predefinita, le richieste di previsione online non generano log. Puoi attivare Cloud Logging quando crei la risorsa modello:
gcloud
Includi il flag --enable-logging quando esegui
gcloud ai-platform models create.
Python
Imposta onlinePredictionLogging su True nella risorsa Model che utilizzi per la chiamata a projects.models.create.
Trovare i log
I log dei job contengono tutti gli eventi relativi all'operazione, inclusi gli eventi di tutti i processi nel cluster quando utilizzi l'addestramento distribuito. Se stai eseguendo un job di addestramento distribuito, i log a livello di job vengono registrati per il processo del worker principale. In genere, il primo passaggio per la risoluzione di un errore consiste nell'esaminare i log relativi al processo, escludendo gli eventi registrati per altri processi nel cluster. Gli esempi in questa sezione mostrano questo filtro.
Puoi filtrare i log dalla riga di comando o dalla sezione Cloud Logging della console Google Cloud. In entrambi i casi, utilizza questi valori di metadati nel filtro, se necessario:
| Elemento metadati | Filtra per visualizzare gli elementi in cui è… |
|---|---|
| resource.type | Uguale a "cloud_ml_job". |
| resource.labels.job_id | Uguale al nome del job. |
| resource.labels.task_name | Uguale a "master-replica-0" per leggere solo le voci di log per il tuo worker master. |
| gravità | Maggiore o uguale a ERROR per leggere solo le voci di log corrispondenti alle condizioni di errore. |
Riga di comando
Utilizza gcloud beta logging read per costruire una query che soddisfi le tue esigenze. Ecco alcuni esempi:
Ogni esempio si basa su queste variabili di ambiente:
PROJECT="my-project-name"
JOB="my_job_name"
Se preferisci, puoi inserire la stringa letterale in posizione.
Per stampare i log dei job sullo schermo:
gcloud ai-platform jobs stream-logs $JOB
Consulta tutte le opzioni per gcloud ai-platform jobs stream-logs.
Per stampare il log del tuo worker principale sullo schermo:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
Per stampare solo gli errori registrati per il tuo worker principale sullo schermo:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Gli esempi precedenti rappresentano i casi più comuni di filtri per i log del job di addestramento di AI Platform Prediction. Cloud Logging offre molte opzioni efficaci per i filtri che puoi utilizzare se devi perfezionare la ricerca. La documentazione sui filtri avanzati descrive queste opzioni in dettaglio.
Console
Apri la pagina Job di AI Platform Prediction nella console Google Cloud.
Seleziona il job non riuscito dall'elenco nella pagina Job per visualizzarne i dettagli.

- Fai clic su Visualizza log per aprire Cloud Logging.
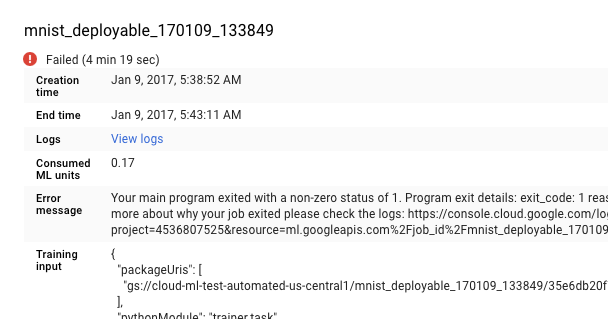
Puoi anche andare direttamente a Cloud Logging, ma devi eseguire un passaggio aggiuntivo per trovare il tuo job:
- Espandi il selettore delle risorse.
- Espandi il job di previsione di AI Platform nell'elenco delle risorse.
- Trova il nome del job nell'elenco job_id (puoi inserire le prime lettere del nome del job nella casella di ricerca per restringere i job visualizzati).
- Espandi la voce del job e seleziona
master-replica-0dall'elenco delle attività.

Ottenere informazioni dai log
Dopo aver trovato il log corretto per il tuo job e averlo filtrato per master-replica-0, puoi esaminare gli eventi registrati per trovare l'origine del problema. Si tratta della procedura di debug di Python standard, ma tieni presente quanto segue:
- Gli eventi hanno più livelli di gravità. Puoi filtrare i dati in modo da visualizzare solo gli eventi di un determinato livello, ad esempio errori o errori e avvisi.
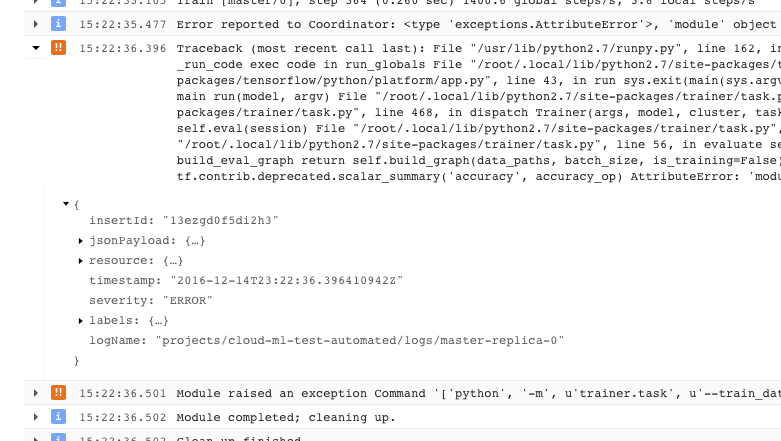
- Un problema che causa l'uscita dell'addestratore con una condizione di errore irrecuperabile (codice di ritorno > 0) viene registrato come eccezione preceduta dalla traccia di stack:
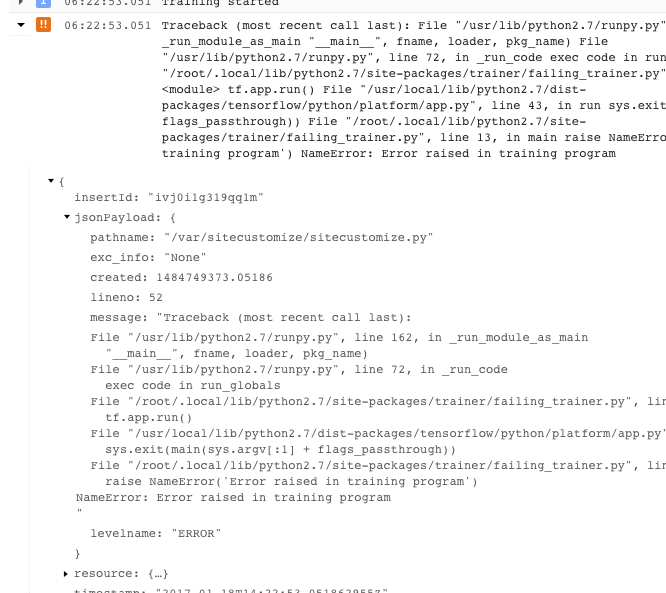
- Puoi ottenere ulteriori informazioni espandendo gli oggetti nel messaggio JSON registrato (indicato da una freccia rivolta verso destra e da contenuti elencati come {...}). Ad esempio, puoi espandere jsonPayload per visualizzare la traccia dello stack in un formato più scorrevole rispetto a quello fornito nella descrizione dell'errore principale:
- Alcuni errori mostrano istanze di errori ripetibili. In genere non includono una traccia dello stack e possono essere più difficili da diagnosticare.
Ottenere il massimo dal logging
Il servizio di addestramento di AI Platform Prediction registra automaticamente questi eventi:
- Informazioni sullo stato interno al servizio.
- Messaggi inviati dall'applicazione di addestramento a
stderr. - Testo di output inviato dall'applicazione di addestramento a
stdout.
Puoi semplificare la risoluzione degli errori nell'applicazione per formatori seguendo buone pratiche di programmazione:
- Invia messaggi significativi a stderr (ad esempio con il logging).
- Quando si verifica un problema, solleva l'eccezione più logica e descrittiva.
- Aggiungi stringhe descrittive agli oggetti eccezione.
La documentazione di Python fornisce maggiori informazioni sulle eccezioni.
Risoluzione dei problemi relativi alla previsione
Questa sezione raccoglie alcuni problemi comuni riscontrati durante l'ottenimento delle previsioni.
Gestione di condizioni specifiche per la previsione online
Questa sezione fornisce indicazioni su alcune condizioni di errore di previsione online che si sa interessano ad alcuni utenti.
Le previsioni richiedono troppo tempo per essere completate (30-180 secondi)
La causa più comune della previsione online lenta è l'aumento dei nodi di elaborazione da zero. Se il modello riceve regolarmente richieste di previsione, il sistema mantiene uno o più nodi pronti per fornire le previsioni. Se il tuo modello non ha fornito alcuna previsione da molto tempo, il servizio "riduce le dimensioni" a zero nodi pronti. La successiva richiesta di previsione dopo uno scale-down di questo tipo richiederà molto più tempo del solito per essere soddisfatta perché il servizio deve eseguire il provisioning dei nodi per gestirla.
Codici di stato HTTP
Quando si verifica un errore con una richiesta di previsione online, in genere viene restituito un codice di stato HTTP dal servizio. Di seguito sono riportati alcuni codici comuni e il loro significato nel contesto della previsione online:
- 429 - Memoria insufficiente
Il nodo di elaborazione ha esaurito la memoria durante l'esecuzione del modello. Al momento non è possibile aumentare la memoria allocata ai nodi di previsione. Puoi provare a eseguire il modello nel seguente modo:
- Riduci le dimensioni del modello:
- Utilizzo di variabili meno precise.
- Quantizzazione dei dati continui.
- Ridurre le dimensioni di altre funzionalità di input (ad esempio utilizzando dimensioni del vocabolario più piccole).
- Invia di nuovo la richiesta con un batch di istanze più piccolo.
- Riduci le dimensioni del modello:
- 429 - Troppe richieste in attesa
Il tuo modello riceve più richieste di quante possa gestire. Se utilizzi la scalabilità automatica, le richieste vengono ricevute più velocemente di quanto il sistema possa scalare. Inoltre, se il valore dei nodi minimi è 0, questa configurazione può portare a uno scenario di "avvio a freddo" in cui verrà osservato un tasso di errore del 100% fino a quando il primo nodo non sarà valido.
Con la scalabilità automatica, puoi provare a inviare nuovamente le richieste con backoff esponenziale. Il reinvio delle richieste con backoff esponenziale può dare al sistema il tempo di adeguarsi.
Per impostazione predefinita, la scalabilità automatica viene attivata da un utilizzo della CPU superiore al 60% ed è configurabile.
- 429 - Quota
Il progetto Google Cloud è limitato a 10.000 richieste ogni 100 secondi (circa 100 al secondo). Se ricevi questo errore in caso di picchi temporanei, spesso puoi riprovare con il backoff esponenziale per elaborare tutte le richieste in tempo. Se ricevi costantemente questo codice, puoi richiedere un aumento della quota. Per ulteriori dettagli, consulta la pagina delle quote.
- 503 - I nostri sistemi hanno rilevato traffico insolito dalla rete del tuo computer
La frequenza delle richieste ricevute dal tuo modello da un singolo indirizzo IP è così elevata che il sistema sospetta un attacco di tipo denial of service. Interrompi l'invio di richieste per un minuto e poi riprendilo a una frequenza inferiore.
- 500 - Impossibile caricare il modello
Il sistema ha avuto difficoltà a caricare il modello. Prova a procedere nel seguente modo:
- Assicurati che l'addestratore stia esportando il modello corretto.
- Prova una previsione di test con il comando
gcloud ai-platform local predict. - Esporta di nuovo il modello e riprova.
Errori di formattazione per le richieste di previsione
Questi messaggi riguardano tutti il tuo input di previsione.
- "JSON vuoto o con formato non corretto/non valido nel corpo della richiesta"
- Il servizio non è riuscito ad analizzare il JSON nella richiesta o la richiesta è vuota. Controlla il messaggio per verificare la presenza di errori o omissioni che invalidano il JSON.
- "Manca il campo "instances" nel corpo della richiesta"
- Il corpo della richiesta non segue il formato corretto. Deve essere un oggetto JSON con una singola chiave denominata
"instances"che contiene un elenco con tutte le istanze di input. - Errore di codifica JSON durante la creazione di una richiesta
La richiesta include dati con codifica base64, ma non nel formato JSON corretto. Ogni stringa con codifica base64 deve essere rappresentata da un oggetto con una singola chiave denominata
"b64". Ad esempio:{"b64": "an_encoded_string"}Un altro errore base64 si verifica quando i dati binari non sono codificati in base64. Codifica i dati e formattali come segue:
{"b64": base64.b64encode(binary_data)}Scopri di più sulla formattazione e sulla codifica dei dati binari.
La previsione nel cloud richiede più tempo che su computer
La previsione online è progettata per essere un servizio scalabile che gestisce rapidamente un elevato tasso di richieste di previsione. Il servizio è ottimizzato per il rendimento aggregato di tutte le richieste di pubblicazione. L'attenzione alla scalabilità comporta caratteristiche di rendimento diverse rispetto alla generazione di un numero ridotto di previsioni sulla tua macchina locale.
Passaggi successivi
- Richiedi assistenza.
- Scopri di più sul modello di errore delle API di Google, in particolare sui codici di errore canonici definiti in
google.rpc.Codee sui dettagli degli errori standard definiti in google/rpc/error_details.proto. - Scopri come monitorare i job di addestramento.
- Consulta la sezione Risoluzione dei problemi e domande frequenti su Cloud TPU per assistenza per la diagnosi e la risoluzione dei problemi quando esegui la previsione della piattaforma AI con Cloud TPU.