AI Explanations bindet Attributionen von Attributen in AI Platform Prediction ein. Auf dieser Seite finden Sie eine kurze konzeptionelle Übersicht über die Methoden der Feature-Attribution, die mit AI Platform Prediction verfügbar sind. Eine ausführliche technische Erläuterung finden Sie in unserem Whitepaper zu AI Explanations.
Mit AI Explanations können Sie die Ausgaben Ihres Modells besser verstehen und für Klassifizierungs- und Regressionsaufgaben nutzen. Wenn Sie eine Vorhersage auf der AI Platform anfordern, erfahren Sie mit AI Explanations, wie stark die einzelnen Features in den Daten zum vorhergesagten Ergebnis beigetragen haben. Anhand dieser Informationen können Sie dann prüfen, ob das Modell wie erwartet funktioniert, Verzerrungen in Ihren Modellen erkennen und Ideen zur Verbesserung Ihres Modells und Ihrer Trainingsdaten erhalten.
Feature-Attributionen
Feature-Attributionen geben an, wie viel jedes Feature in Ihrem Modell zu den Vorhersagen für die jeweilige Instanz beigetragen hat. Wenn Sie Vorhersagen anfordern, erhalten Sie entsprechende vorhergesagte Werte für Ihr Modell. Wenn Sie Erläuterungen anfordern, erhalten Sie die Vorhersagen zusammen mit Informationen zur Feature-Attribution.
Feature-Attributionen arbeiten mit tabellarischen Daten und beinhalten integrierte Visualisierungsfunktionen für Bilddaten. Betrachten Sie folgende Beispiele:
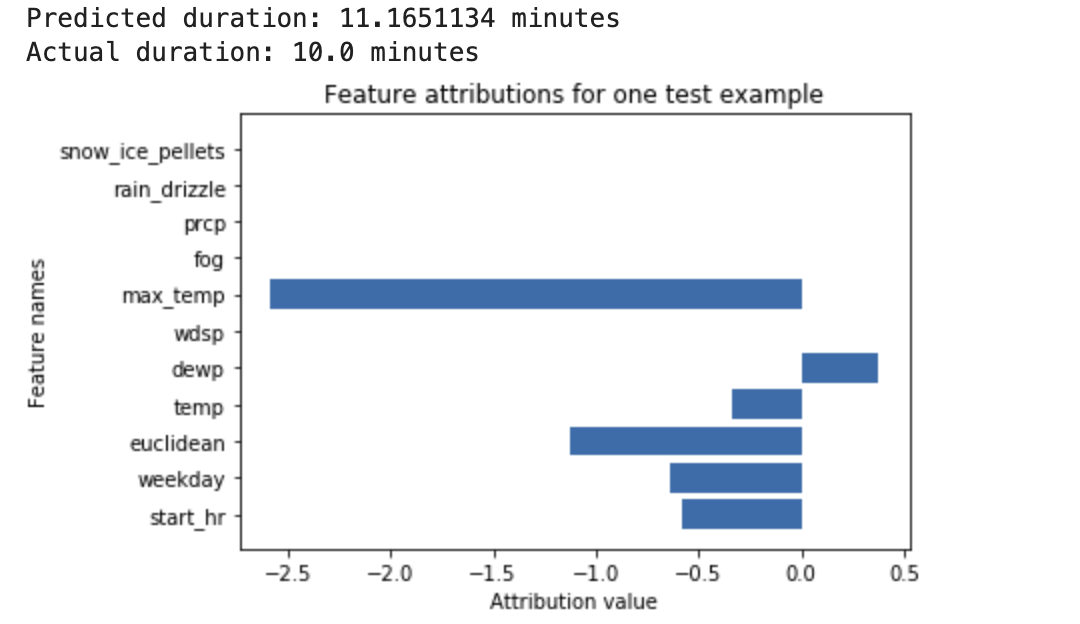
Ein neuronales Deep-Learning-Netzwerk wird trainiert, damit es die Dauer einer Fahrradtour auf Basis von Wetterdaten und früheren geteilten Daten vorhersagt. Wenn Sie nur Vorhersagen von diesem Modell anfordern, erhalten Sie die vorhergesagte Dauer von Fahrradtouren in Minuten. Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Fahrzeit sowie einen Attributionswert für jedes Feature in Ihrer Erläuterungsanfrage. Die Attributionswerte geben an, wie stark sich das Feature relativ zum von Ihnen angegebenen Referenzwert auf die Änderung des Vorhersagewerts auswirkt. Wählen Sie eine aussagekräftige Referenz für Ihr Modell aus. In diesem Fall die mittlere Fahrtzeit. Sie können die Feature-Attributionswerte grafisch darstellen, um zu sehen, welche Features am stärksten zur resultierenden Vorhersage beigetragen haben:
Ein Bildklassifizierungsmodell wird trainiert, um vorherzusagen, ob ein bestimmtes Bild einen Hund oder eine Katze enthält. Wenn Sie Vorhersagen von diesem Modell für einen neuen Satz von Bildern anfordern, erhalten Sie eine Vorhersage für jedes Bild ("Hund" oder "Katze"). Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Klasse zusammen mit einem Overlay für das Bild, das zeigt, welche Pixel im Bild am stärksten zur resultierenden Vorhersage beigetragen haben:

Ein Foto einer Katze mit Feature-Attributionsoverlay 
Ein Foto von einem Hund mit Feature-Attributionsoverlay Ein Bildklassifizierungsmodell wird trainiert, um die Gattung einer Blume in dem Bild vorherzusagen. Wenn Sie Vorhersagen von diesem Modell für einen neuen Satz von Bildern anfordern, erhalten Sie eine Vorhersage für jedes Bild ("Gänseblümchen" oder "Löwenzahn"). Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Klasse zusammen mit einem Overlay für das Bild, das zeigt, welche Bereiche im Bild am stärksten zur resultierenden Vorhersage beigetragen haben:

Foto eines Gänseblümchens mit Feature-Attributionsoverlay
Vorteile und Anwendungsfälle
Wenn Sie bestimmte Instanzen prüfen und darüber hinaus Feature-Attributionen in Ihrem Trainings-Dataset erzeugen, erhalten Sie genauere Einblicke in die Funktionsweise Ihres Modells. Beachten Sie die folgenden Vorteile und Anwendungsfälle:
- Fehlerbehebungsmodelle: Mithilfe von Feature-Attributionen können Probleme in den Daten erkannt werden, die bei Standardbewertungstechniken für Modelle normalerweise nicht ersichtlich werden. Ein Bildpathologiemodell erzielte beispielsweise auffallend gute Ergebnisse in einem Test-Dataset mit Thorax-Röntgenbildern. Die Feature-Attributionen ergaben, dass die hohe Genauigkeit des Modells von den Stiftmarkierungen des Radiologen im Bild abhing.
- Modelle optimieren: Sie können weniger wichtige Features identifizieren und entfernen, was zu effizienteren Modellen führt.
Konzeptionelle Einschränkungen
Berücksichtigen Sie die folgenden Einschränkungen für Attributionen von Attributen:
- Zuweisungen beziehen sich auf individuelle Vorhersagen. Die Prüfung einer Attribution für eine einzelne Vorhersage kann einen guten Einblick liefern, aber die Erkenntnisse sind möglicherweise nicht für die gesamte Klasse dieser einzelnen Instanz oder das gesamte Modell zu verallgemeinern. Wenn Sie allgemeinere Erkenntnisse erhalten möchten, könnten Sie Attributionen für Teilmengen über Ihr Dataset oder das gesamte Dataset aggregieren.
- Obwohl Feature-Attributionen bei der Fehlerbehebung für Modelle hilfreich sein können, geben sie nicht immer deutlich genug an, ob ein Problem durch das Modell oder die Daten entsteht, auf denen das Modell trainiert wird. Gehen Sie nach bestem Wissen vor und diagnostizieren Sie häufige Datenprobleme, um mögliche Ursachen zu minimieren.
- Feature-Attributionen unterliegen ähnlichen kontradiktorischen Angriffen wie Vorhersagen in komplexen Modellen.
Weitere Informationen zu Einschränkungen finden Sie in der Liste der allgemeinen Einschränkungen und im Whitepaper zu AI Explanations.
Methoden zur Attribution von Attributen vergleichen
AI Explanations bietet drei Methoden zur Feature-Attribution: Sampled Shapley, integrierte Farbverläufe und XRAI.
| Methode | Grundlegende Erläuterung | Empfohlene Modelltypen | Beispielanwendungsfälle |
|---|---|---|---|
| Integrierte Farbverläufe | Eine auf Verläufen basierende Methode zur effizienten Berechnung von Feature-Attributionen mit denselben axiomatischen Eigenschaften wie der Shapley-Wert. | Unterscheidbare Modelle, z. B. neuronale Netzwerke Besonders für Modelle mit großen Feature-Bereichen empfohlen. Empfohlen für Bilder mit geringem Kontrast, z. B. Röntgenaufnahmen. |
|
| XRAI (eXplanation with Ranked Area Integrals) | Auf Grundlage der Methode "Integrierte Gradienten" werden bei XRAI sich überschneidende Bereiche des Bildes bewertet, um eine Karte mit Ausprägungen zu erstellen, die relevante Regionen des Bildes statt Pixel hervorhebt. | Modelle, die Bildeingaben akzeptieren. Besonders empfohlen für natürliche Bilder, also Szenen aus der realen Welt, die mehrere Objekte enthalten. |
|
| Sampled Shapley | Weist jedem Feature eine Gewichtung für das Ergebnis zu und berücksichtigt verschiedene Varianten der Features. Diese Methode liefert eine Stichprobenapproximation für exakte Shapley-Werte. | Nicht unterscheidbare Modelle, z. B. Gruppen von Bäumen und neuronale Netzwerke1 |
|
Methoden zur Attribution von Attributen verstehen
Jede Methode der Feature-Attribution basiert auf Shapley-Werten. Dabei handelt es sich um einen Algorithmus der Spieltheorie, der jedem Spieler in einem Spiel eine Gewichtung für ein bestimmtes Ergebnis zuweist. Auf ML-Modelle angewendet bedeutet dies, dass jedes Modell-Feature als "Spieler" im Spiel behandelt wird. AI Explanations weist jedem Feature eine proportionale Gewichtung für das Ergebnis einer bestimmten Vorhersage zu.
Mithilfe von AI Explanations können Sie Ihre Spieler sozusagen "auswählen". Wählen Sie dazu die genauen Features für Ihre Erläuterungsanfrage aus.
Methode "Sampled Shapley"
Die Methode Sampled Shapley bietet eine Stichprobenapproximation für exakte Shapley-Werte.
Methode "Integrierte Gradienten"
Bei der Methode Integrierte Gradienten wird der Gradient der Vorhersageausgabe in Bezug auf die Features der Eingabe entlang eines integralen Pfads berechnet.
- Die Gradienten werden in verschiedenen Intervallen eines Skalierungsparameters berechnet. Stellen Sie sich diesen Skalierungsparameter für Bilddaten als "Schieberegler" vor, der alle Pixel des Bildes auf Schwarz skaliert.
- Die Gradienten sind "eingebunden":
- Die Gradienten werden gemittelt.
- Das elementweise Produkt der gemittelten Gradienten und der ursprünglichen Eingabe wird berechnet.
Eine intuitive Erklärung dieses Prozesses für Bilder finden Sie im Blogpost Attributing a deep network's prediction to its input features. Die Autoren des ursprünglichen Artikels über integrierte Farbverläufe (Axiomatic Attribution for Deep Networks) zeigen im vorherigen Blogpost, wie die Bilder bei jedem Schritt des Prozesses aussehen.
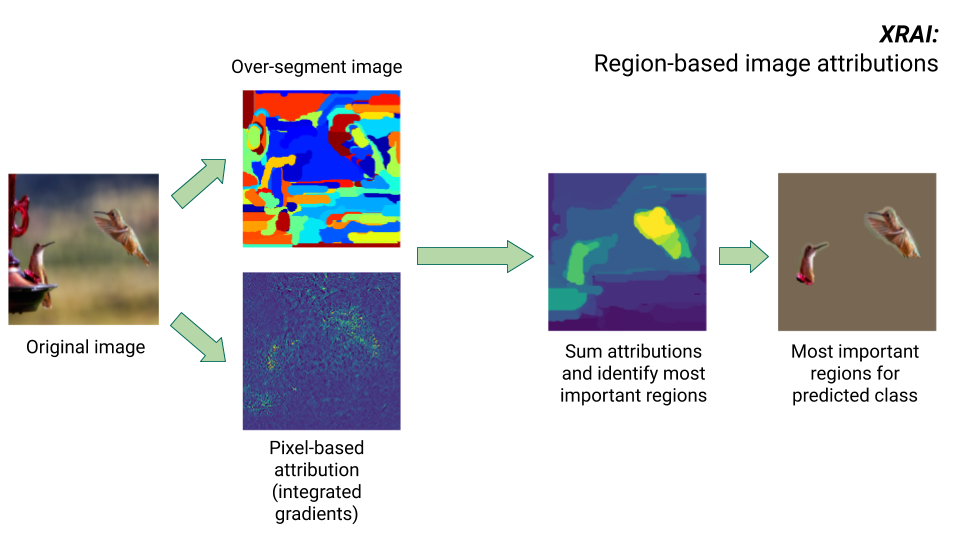
XRAI-Methode
Die Methode XRAI kombiniert die Methode "Integrierte Gradienten" mit zusätzlichen Schritten, um zu bestimmen, welche Regionen des Bildes am meisten zu einer bestimmten Klassenvorhersage beitragen.
- Attribution auf Pixelebene: XRAI führt eine Attribution auf Pixelebene für das Eingabebild durch. In diesem Schritt verwendet XRAI die Methode "Integrierte Gradienten" mit jeweils einer Referenz für Schwarz und für Weiß.
- Übersegmentierung: Unabhängig von der Attribution auf Pixelebene wird das Bild von XRAI übersegmentiert, um ein Flickwerk aus kleinen Regionen zu erstellen. XRAI verwendet zum Erstellen der Bildsegmente die auf Diagrammen beruhende Methode von Felzenszwalb.
- Regionsauswahl: XRAI aggregiert die Attribution auf Pixelebene innerhalb jedes Segments, um die Attributionsdichte zu bestimmen. Anhand dieser Werte ordnet XRAI jedem Segment einen Rang zu und ordnet dann die Segmente vom positivsten zum am wenigsten positiven Segment an. Dadurch wird bestimmt, welche Bereiche des Bildes am auffälligsten sind oder am stärksten zu einer bestimmten Klassenvorhersage beitragen.
Unterscheidbare und nicht unterscheidbare Modelle
In unterscheidbaren Modellen können Sie die Ableitung aller Vorgänge in Ihrer TensorFlow-Grafik berechnen. Diese Eigenschaft ermöglicht die Rückpropagierung bei solchen Modellen. Neuronale Netzwerke sind beispielsweise unterscheidbar. Verwenden Sie die Methode "Integrierte Gradienten", um Feature-Attributionen für unterscheidbare Modelle zu erhalten.
Nicht unterscheidbare Modelle enthalten nicht unterscheidbare Vorgänge in der TensorFlow-Grafik, z. B. Vorgänge, die Decodierungs- und Rundungsaufgaben ausführen. Ein Modell, das aus einer Gruppe von Bäumen und neuronalen Netzwerken besteht, ist beispielsweise nicht unterscheidbar. Verwenden Sie die Sampled Shapley-Methode, um Feature-Attributionen für nicht unterscheidbare Modelle zu erhalten. Sampled Shapley funktioniert auch bei unterscheidbaren Modellen, erfordert in diesem Fall jedoch mehr Rechenleistung als nötig.
Verweise
Die Implementierungen von Sampled Shapley, integrierten Gradienten und XRAI beruhen jeweils auf den folgenden Referenzen:
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation
- Axiomatic Attribution for Deep Networks
- XRAI: Better Attributions Through Regions
Weitere Informationen zur Implementierung von AI Explanations finden Sie im Whitepaper zu AI Explanations.
Bildungsressourcen
Die folgenden Ressourcen bieten weitere nützliche Lehrmaterialien:
- Interpretable Machine Learning: Shapley Values
- Integrated Gradients GitHub Repository von Ankur Taly
- SHAP-Bibliothek (SHapley Additive exPlanations)
- Einführung in Shapley-Werte