Dengan AI Platform Pipelines, Anda dapat mengatur alur kerja machine learning (ML) sebagai pipeline yang dapat digunakan kembali dan direproduksi. AI Platform Pipelines menghemat kesulitan Anda dalam menyiapkan Kubeflow Pipelines dengan TensorFlow Extended di Google Kubernetes Engine.
Panduan ini menjelaskan beberapa opsi untuk men-deploy AI Platform Pipelines di GKE. Anda dapat men-deploy Kubeflow Pipelines di cluster GKE yang ada atau membuat cluster GKE baru. Jika Anda ingin menggunakan kembali cluster GKE yang ada, pastikan cluster Anda memenuhi persyaratan berikut:
- Cluster Anda harus memiliki minimal 3 node. Setiap node harus memiliki minimal 2 CPU dan memori 4 GB yang tersedia.
- Cakupan akses cluster harus memberikan akses penuh ke semua Cloud API, atau cluster Anda harus menggunakan akun layanan kustom.
- Cluster tidak boleh sudah menginstal Kubeflow Pipelines.
Pilih opsi deployment terbaik untuk situasi Anda:
- Gunakan AI Platform Pipelines untuk membuat cluster GKE baru dengan akses penuh ke Google Cloud dan men-deploy Kubeflow Pipelines ke cluster. Opsi ini mempermudah deployment dan penggunaan AI Platform Pipelines.
- Buat cluster GKE baru dengan akses terperinci ke Google Cloud dan deploy Kubeflow Pipelines ke cluster ini. Opsi ini memungkinkan Anda menentukan resource dan API Google Cloud yang dapat diakses oleh workload di cluster Anda.
- Deploy AI Platform Pipelines ke cluster GKE yang ada. Opsi ini menjelaskan cara men-deploy AI Platform Pipelines ke cluster GKE yang ada.
Sebelum memulai
Sebelum mengikuti panduan ini, pastikan project Google Cloud Anda disiapkan dengan benar dan Anda memiliki izin yang memadai untuk men-deploy AI Platform Pipelines.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Gunakan petunjuk berikut untuk memeriksa apakah Anda telah diberi peran yang diperlukan untuk men-deploy AI Platform Pipelines.
-
Buka sesi Cloud Shell.
Cloud Shell akan terbuka dalam bingkai di bagian bawah konsol Google Cloud.
-
Anda harus memiliki peran Viewer (
roles/viewer) dan Kubernetes Engine Admin (roles/container.admin) di project, atau peran lain yang menyertakan izin yang sama seperti peran Pemilik (roles/owner) di project, untuk men-deploy AI Platform Pipelines. Jalankan perintah berikut di Cloud Shell untuk membuat daftar akun utama yang memiliki peran Viewer dan Kubernetes Engine Admin.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
Ganti PROJECT_ID dengan ID project Google Cloud Anda.
Gunakan output perintah ini untuk memverifikasi bahwa akun Anda memiliki peran Viewer dan Kubernetes Engine Admin.
-
Jika ingin memberikan akses terperinci cluster, Anda juga harus memiliki peran Service Account Admin (
roles/iam.serviceAccountAdmin) di project, atau peran lain yang menyertakan izin yang sama seperti peran Editor (roles/editor) atau Pemilik (roles/owner) di project. Jalankan perintah berikut di Cloud Shell untuk mencantumkan akun utama yang memiliki peran Service Account Admin.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
Ganti PROJECT_ID dengan ID project Google Cloud Anda.
Gunakan output perintah ini untuk memverifikasi bahwa akun Anda memiliki peran Service Account Admin.
-
Jika Anda belum diberi peran yang diperlukan, hubungi administrator project Google Cloud Anda untuk mendapatkan bantuan tambahan.
Pelajari lebih lanjut cara memberikan peran Identity and Access Management.
-
Men-deploy AI Platform Pipelines dengan akses penuh ke Google Cloud
AI Platform Pipelines mempermudah penyiapan dan penggunaan Kubeflow Pipelines dengan membuat cluster GKE untuk Anda dan men-deploy Kubeflow Pipelines ke cluster. Saat AI Platform Pipelines membuat
kluster GKE untuk Anda, cluster tersebut akan menggunakan akun layanan Compute Engine
default. Untuk memberi cluster akses penuh ke
resource dan API Google Cloud yang telah Anda aktifkan di project, Anda
dapat memberikan akses cluster ke
cakupan akses https://www.googleapis.com/auth/cloud-platform. Dengan memberikan akses
secara ini, pipeline ML yang berjalan di cluster Anda dapat mengakses API Google Cloud,
seperti AI Platform Training dan AI Platform Prediction. Meskipun proses ini
memudahkan penyiapan AI Platform Pipelines, proses ini dapat memberi developer
pipeline Anda akses berlebihan ke resource dan API Google Cloud.
Gunakan petunjuk berikut untuk men-deploy AI Platform Pipelines dengan akses penuh ke resource dan API Google Cloud.
Buka AI Platform Pipelines di konsol Google Cloud.
Di toolbar AI Platform Pipelines, klik Instance baru. Kubeflow Pipelines akan terbuka di Google Cloud Marketplace.
Klik Konfigurasikan. Formulir Deploy Kubeflow Pipelines akan terbuka.
Jika link Buat cluster baru ditampilkan, klik Buat cluster baru. Jika tidak, lanjutkan ke langkah berikutnya.

Pilih Zona cluster tempat cluster Anda akan berada. Untuk bantuan dalam menentukan zona yang akan digunakan, baca praktik terbaik untuk pemilihan region.
Centang Izinkan akses ke Cloud API berikut untuk memberikan akses ke resource Google Cloud kepada aplikasi yang berjalan di cluster GKE Anda. Dengan mencentang kotak ini, Anda memberikan akses cluster ke cakupan akses
https://www.googleapis.com/auth/cloud-platform. Cakupan akses ini memberikan akses penuh ke resource Google Cloud yang telah Anda aktifkan di project. Dengan memberikan akses cluster ke resource Google Cloud dengan cara ini, Anda tidak perlu repot membuat dan mengelola akun layanan atau membuat secret Kubernetes.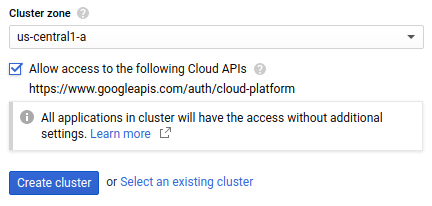
Klik Buat kluster. Langkah ini mungkin memerlukan waktu beberapa menit.
Namespace digunakan untuk mengelola resource di cluster GKE yang besar. Jika Anda tidak berencana menggunakan namespace di cluster, pilih default di daftar drop-down Namespace.
Jika Anda berencana menggunakan namespace di cluster GKE, buat namespace menggunakan menu drop-down Namespace. Untuk membuat namespace:
- Pilih Create a namespace di menu drop-down Namespace. Kotak New namespace name akan muncul.
- Masukkan nama namespace di Nama namespace baru.
Untuk mempelajari namespace lebih lanjut, baca postingan blog tentang mengatur Kubernetes dengan namespace.
Di kotak Nama instance aplikasi, masukkan nama untuk instance Kubeflow Pipelines Anda.
Penyimpanan terkelola memungkinkan Anda menyimpan metadata dan artefak pipeline ML menggunakan Cloud SQL dan Cloud Storage, bukan menyimpannya di disk persisten Compute Engine. Menggunakan layanan terkelola untuk menyimpan artefak dan metadata pipeline akan mempermudah pencadangan dan pemulihan data cluster Anda. Untuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola, pilih Use managed storage dan berikan informasi berikut:
Bucket Cloud Storage penyimpanan artefak: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan artefak pipeline dalam bucket Cloud Storage. Tentukan nama bucket tempat Anda ingin Kubeflow Pipelines menyimpan artefak. Jika bucket yang ditentukan tidak ada, deployer Kubeflow Pipelines akan otomatis membuat bucket untuk Anda di region
us-central1.Nama koneksi instance Cloud SQL: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan metadata pipeline di database MySQL di Cloud SQL. Tentukan nama koneksi untuk instance MySQL Cloud SQL Anda.
Nama pengguna database: Tentukan nama pengguna database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Saat ini, pengguna database Anda harus memiliki hak istimewa MySQL
ALLuntuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola. Jika Anda mengosongkan kolom ini, nilai ini akan ditetapkan secara default ke root.Sandi database: Tentukan sandi database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Jika Anda mengosongkan kolom ini, Kubeflow Pipelines akan terhubung ke database tanpa memberikan sandi, yang akan gagal jika sandi diperlukan untuk nama pengguna yang Anda tentukan.
Awal nama database: Tentukan awalan nama database. Nilai awalan harus diawali dengan huruf dan hanya berisi huruf kecil, angka, serta garis bawah.
Selama proses deployment, Kubeflow Pipelines membuat dua database, "DATABASE_NAME_PREFIX_pipeline" dan "DATABASE_NAME_PREFIX_metadata". Jika database dengan nama ini ada di instance MySQL Anda, Kubeflow Pipelines akan menggunakan kembali database yang ada. Jika nilai ini tidak ditentukan, Nama instance aplikasi akan digunakan sebagai awalan nama database.
Klik Deploy. Langkah ini mungkin memerlukan waktu beberapa menit.
Untuk mengakses dasbor pipeline, buka AI Platform Pipelines di konsol Google Cloud.
Kemudian, klik Buka dasbor pipeline untuk instance AI Platform Pipelines Anda.
Men-deploy AI Platform Pipelines dengan akses terperinci ke Google Cloud
Pipeline ML mengakses resource Google Cloud menggunakan akun layanan dan cakupan akses dari kumpulan node cluster GKE. Saat ini, untuk membatasi akses cluster ke resource Google Cloud tertentu, Anda harus men-deploy AI Platform Pipelines ke cluster GKE yang menggunakan akun layanan yang dikelola pengguna.
Gunakan petunjuk di bagian berikut untuk membuat dan mengonfigurasi akun layanan, membuat cluster GKE menggunakan akun layanan, dan men-deploy Kubeflow Pipelines ke cluster GKE.
Membuat akun layanan untuk cluster GKE
Gunakan petunjuk berikut untuk menyiapkan akun layanan untuk cluster GKE Anda.
Buka sesi Cloud Shell.
Cloud Shell akan terbuka dalam bingkai di bagian bawah konsol Google Cloud.
Jalankan perintah berikut di Cloud Shell untuk membuat akun layanan dan memberikan akses yang memadai untuk menjalankan AI Platform Pipelines. Pelajari lebih lanjut peran yang diperlukan untuk menjalankan AI Platform Pipelines dengan akun layanan yang dikelola pengguna.
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewerGanti kode berikut:
- SERVICE_ACCOUNT_NAME: Nama akun layanan yang akan dibuat.
- PROJECT_ID: Project Google Cloud tempat akun layanan dibuat.
Beri akun layanan Anda akses ke resource atau API Google Cloud apa pun yang diperlukan pipeline ML Anda. Pelajari lebih lanjut peran Identity and Access Management dan cara mengelola akun layanan.
Berikan peran Service Account User (
iam.serviceAccountUser) kepada akun pengguna Anda di akun layanan.gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
Ganti kode berikut:
- SERVICE_ACCOUNT_NAME: Nama akun layanan Anda.
- PROJECT_ID: Project Google Cloud Anda.
- USERNAME: Nama pengguna Anda di Google Cloud.
Menyiapkan cluster GKE
Gunakan petunjuk berikut untuk menyiapkan cluster GKE.
Buka Google Kubernetes Engine di konsol Google Cloud.
Klik tombol Buat cluster. Formulir Dasar-dasar cluster akan terbuka.
Masukkan Name untuk cluster Anda.
Untuk Location type, pilih Zonal, lalu pilih zone yang diinginkan untuk cluster Anda. Untuk mendapatkan bantuan dalam menentukan zona yang akan digunakan, baca praktik terbaik untuk pemilihan region.
Dari panel navigasi, di bagian Node Pools, klik default-pool. Formulir Node pool details akan muncul.
Masukkan Jumlah node yang akan dibuat di cluster. Cluster Anda harus memiliki 3 node atau lebih untuk men-deploy AI Platform Pipelines. Anda harus memiliki kuota resource yang tersedia untuk node dan resource-nya (seperti rute firewall).
Dari panel navigasi, di bagian Node Pools, klik Nodes. Formulir Nodes akan terbuka.
Pilih Machine configuration default yang akan digunakan untuk instance. Anda harus memilih jenis mesin dengan minimal 2 CPU dan memori 4 GB, seperti
n1-standard-2, untuk men-deploy AI Platform Pipelines. Setiap jenis mesin ditagih secara berbeda. Untuk mengetahui informasi harga jenis mesin, lihat lembar harga jenis mesin.Dari panel navigasi, di bagian Node Pools, klik Security. Formulir Node security akan muncul.
Dari menu drop-down Service account, pilih akun layanan yang Anda buat sebelumnya dalam panduan ini.
Jika tidak, konfigurasikan cluster GKE Anda sesuai keinginan. Pelajari lebih lanjut cara membuat cluster GKE.
Klik Create.
Menginstal Kubeflow Pipelines di cluster GKE
Gunakan petunjuk berikut untuk menyiapkan Kubeflow Pipelines di cluster GKE.
Buka AI Platform Pipelines di konsol Google Cloud.
Di toolbar AI Platform Pipelines, klik Instance baru. Kubeflow Pipelines akan terbuka di Google Cloud Marketplace.
Klik Konfigurasikan. Formulir Deploy Kubeflow Pipelines akan terbuka.
Di menu drop-down Cluster, pilih cluster yang Anda buat di langkah sebelumnya. Jika cluster yang ingin Anda gunakan tidak memenuhi syarat untuk deployment, pastikan cluster Anda memenuhi persyaratan untuk men-deploy Kubeflow Pipelines.
Namespace digunakan untuk mengelola resource di cluster GKE yang besar. Jika Anda tidak berencana menggunakan namespace di cluster, pilih default di daftar drop-down Namespace.
Jika Anda berencana menggunakan namespace di cluster GKE, buat namespace menggunakan menu drop-down Namespace. Untuk membuat namespace:
- Pilih Create a namespace di menu drop-down Namespace. Kotak New namespace name akan muncul.
- Masukkan nama namespace di Nama namespace baru.
Untuk mempelajari namespace lebih lanjut, baca postingan blog tentang mengatur Kubernetes dengan namespace.
Di kotak Nama instance aplikasi, masukkan nama untuk instance Kubeflow Pipelines Anda.
Penyimpanan terkelola memungkinkan Anda menyimpan metadata dan artefak pipeline ML menggunakan Cloud SQL dan Cloud Storage, bukan menyimpannya di disk persisten Compute Engine. Menggunakan layanan terkelola untuk menyimpan artefak dan metadata pipeline akan mempermudah pencadangan dan pemulihan data cluster Anda. Untuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola, pilih Use managed storage dan berikan informasi berikut:
Bucket Cloud Storage penyimpanan artefak: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan artefak pipeline dalam bucket Cloud Storage. Tentukan nama bucket tempat Anda ingin Kubeflow Pipelines menyimpan artefak. Jika bucket yang ditentukan tidak ada, deployer Kubeflow Pipelines akan otomatis membuat bucket untuk Anda di region
us-central1.Nama koneksi instance Cloud SQL: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan metadata pipeline di database MySQL di Cloud SQL. Tentukan nama koneksi untuk instance MySQL Cloud SQL Anda.
Nama pengguna database: Tentukan nama pengguna database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Saat ini, pengguna database Anda harus memiliki hak istimewa MySQL
ALLuntuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola. Jika Anda mengosongkan kolom ini, nilai ini akan ditetapkan secara default ke root.Sandi database: Tentukan sandi database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Jika Anda mengosongkan kolom ini, Kubeflow Pipelines akan terhubung ke database tanpa memberikan sandi, yang akan gagal jika sandi diperlukan untuk nama pengguna yang Anda tentukan.
Awal nama database: Tentukan awalan nama database. Nilai awalan harus diawali dengan huruf dan hanya berisi huruf kecil, angka, serta garis bawah.
Selama proses deployment, Kubeflow Pipelines membuat dua database, "DATABASE_NAME_PREFIX_pipeline" dan "DATABASE_NAME_PREFIX_metadata". Jika database dengan nama ini ada di instance MySQL Anda, Kubeflow Pipelines akan menggunakan kembali database yang ada. Jika nilai ini tidak ditentukan, Nama instance aplikasi akan digunakan sebagai awalan nama database.
Klik Deploy. Langkah ini mungkin memerlukan waktu beberapa menit.
Untuk mengakses dasbor pipeline, buka AI Platform Pipelines di konsol Google Cloud.
Kemudian, klik Buka dasbor pipeline untuk instance AI Platform Pipelines Anda.
Men-deploy AI Platform Pipelines ke cluster GKE yang ada
Untuk menggunakan Google Cloud Marketplace guna men-deploy Kubeflow Pipelines di cluster GKE, hal berikut harus benar:
- Cluster Anda harus memiliki minimal 3 node. Setiap node harus memiliki minimal 2 CPU dan memori 4 GB yang tersedia.
- Cakupan akses cluster harus memberikan akses penuh ke semua Cloud API, atau cluster Anda harus menggunakan akun layanan kustom.
- Cluster tidak boleh sudah menginstal Kubeflow Pipelines.
Pelajari lebih lanjut cara mengonfigurasi cluster GKE untuk AI Platform Pipelines.
Gunakan petunjuk berikut untuk menyiapkan Kubeflow Pipelines di cluster GKE.
Buka AI Platform Pipelines di konsol Google Cloud.
Di toolbar AI Platform Pipelines, klik Instance baru. Kubeflow Pipelines akan terbuka di Google Cloud Marketplace.
Klik Konfigurasikan. Formulir Deploy Kubeflow Pipelines akan terbuka.
Di menu drop-down Cluster, pilih cluster Anda. Jika cluster yang ingin Anda gunakan tidak memenuhi syarat untuk deployment, pastikan cluster Anda memenuhi persyaratan untuk men-deploy Kubeflow Pipelines.
Namespace digunakan untuk mengelola resource di cluster GKE yang besar. Jika cluster Anda tidak menggunakan namespace, pilih default di menu drop-down Namespace.
Jika cluster Anda menggunakan namespace, pilih namespace yang ada atau buat namespace menggunakan menu drop-down Namespace. Untuk membuat namespace:
- Pilih Create a namespace di menu drop-down Namespace. Kotak New namespace name akan muncul.
- Masukkan nama namespace di Nama namespace baru.
Untuk mempelajari namespace lebih lanjut, baca postingan blog tentang mengatur Kubernetes dengan namespace.
Di kotak Nama instance aplikasi, masukkan nama untuk instance Kubeflow Pipelines Anda.
Penyimpanan terkelola memungkinkan Anda menyimpan metadata dan artefak pipeline ML menggunakan Cloud SQL dan Cloud Storage, bukan menyimpannya di disk persisten Compute Engine. Menggunakan layanan terkelola untuk menyimpan artefak dan metadata pipeline akan mempermudah pencadangan dan pemulihan data cluster Anda. Untuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola, pilih Use managed storage dan berikan informasi berikut:
Bucket Cloud Storage penyimpanan artefak: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan artefak pipeline dalam bucket Cloud Storage. Tentukan nama bucket tempat Anda ingin Kubeflow Pipelines menyimpan artefak. Jika bucket yang ditentukan tidak ada, deployer Kubeflow Pipelines akan otomatis membuat bucket untuk Anda di region
us-central1.Nama koneksi instance Cloud SQL: Dengan penyimpanan terkelola, Kubeflow Pipelines menyimpan metadata pipeline di database MySQL di Cloud SQL. Tentukan nama koneksi untuk instance MySQL Cloud SQL Anda.
Nama pengguna database: Tentukan nama pengguna database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Saat ini, pengguna database Anda harus memiliki hak istimewa MySQL
ALLuntuk men-deploy Kubeflow Pipelines dengan penyimpanan terkelola. Jika Anda mengosongkan kolom ini, nilai ini akan ditetapkan secara default ke root.Sandi database: Tentukan sandi database yang akan digunakan Kubeflow Pipelines saat terhubung ke instance MySQL Anda. Jika Anda mengosongkan kolom ini, Kubeflow Pipelines akan terhubung ke database tanpa memberikan sandi, yang akan gagal jika sandi diperlukan untuk nama pengguna yang Anda tentukan.
Awal nama database: Tentukan awalan nama database. Nilai awalan harus diawali dengan huruf dan hanya berisi huruf kecil, angka, serta garis bawah.
Selama proses deployment, Kubeflow Pipelines membuat dua database, "DATABASE_NAME_PREFIX_pipeline" dan "DATABASE_NAME_PREFIX_metadata". Jika database dengan nama ini ada di instance MySQL Anda, Kubeflow Pipelines akan menggunakan kembali database yang ada. Jika nilai ini tidak ditentukan, Nama instance aplikasi akan digunakan sebagai awalan nama database.
Klik Deploy. Langkah ini mungkin memerlukan waktu beberapa menit.
Untuk mengakses dasbor pipeline, buka AI Platform Pipelines di konsol Google Cloud.
Kemudian, klik Buka dasbor pipeline untuk instance AI Platform Pipelines Anda.
Langkah selanjutnya
- Atur proses ML Anda sebagai pipeline.
- Gunakan antarmuka pengguna Kubeflow Pipelines untuk menjalankan pipeline.
- Pelajari AI Platform Pipelines dan pipeline ML lebih lanjut.