|
|
|
이 가이드는 AI Platform Optimizer 조건부 목표 최적화를 보여줍니다.
데이터세트
이 샘플에서 학습에 사용하는 인구조사 소득 데이터 세트는 UC Irvine Machine Learning Repository에서 호스팅됩니다.
사용자의 연령, 학력, 결혼 여부, 직업(특성)이 포함된 인구조사 데이터를 사용하여 사용자의 연 소득이 50,000달러(대상 라벨) 이상인지 여부를 예측하는 것이 목표입니다. 개인의 정보를 바탕으로 0과 1 사이의 숫자를 출력하는 로지스틱 회귀 모델을 학습시킵니다. 이 숫자는 개인의 연 소득이 50,000달러 이상일 확률로 해석할 수 있습니다.
목표
이 가이드에서는 AI Platform Optimizer를 사용하여 머신러닝 모델의 초매개변수 검색을 최적화하는 방법을 보여줍니다.
이 샘플은 AI Platform Optimizer와 AI Platform Training 내장 알고리즘을 함께 사용하여 인구조사 데이터세트의 분류 모델을 최적화하는 자동 학습 데모를 구현합니다. AI Platform Optimizer를 사용하여 추천된 초매개변수 값을 가져오고 AI Platform Training 내장 알고리즘을 통해 추천된 초매개변수 값을 사용하여 모델 학습 작업을 제출합니다.
비용
이 가이드에서는 비용이 청구될 수 있는 Google Cloud 구성요소를 사용합니다.
- AI Platform Training
- Cloud Storage
AI Platform Training 가격 책정 및 Cloud Storage 가격 책정에 대해 알아보고 가격 계산기를 사용하여 예상 사용량을 기반으로 비용을 추정해 보세요.
PIP 설치 패키지 및 종속 항목
노트북 환경에 설치되지 않은 추가 종속 항목을 설치합니다.
- 프레임워크의 최신 GA 버전을 사용합니다.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Google Cloud 프로젝트 설정
노트북 환경에 관계없이 다음 단계가 필요합니다.
이 노트북을 로컬로 실행하는 경우 Google Cloud SDK를 설치해야 합니다.
아래 셀에 프로젝트 ID를 입력합니다. 그런 다음 셀을 실행하여 Cloud SDK가 이 노트북에서 모든 명령어에 적합한 프로젝트를 사용하는지 확인합니다.
참고: Jupyter는 ! 프리픽스가 붙은 행을 셸 명령어로 실행하며 $ 프리픽스가 붙은 Python 변수를 이러한 명령어에 보간합니다.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Google Cloud 계정 인증
AI Platform Notebooks를 사용하는 경우 환경이 이미 인증되었습니다. 이 단계를 건너뛰세요.
아래 셀은 두 번의 인증이 필요합니다.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
라이브러리 가져오기
import json
import time
import datetime
from googleapiclient import errors
튜토리얼
설정
이 섹션에서는 AI Platform Optimizer API를 호출하기 위한 일부 매개변수와 util 메서드를 정의합니다. 시작하려면 다음 정보를 입력하세요.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
API 클라이언트 빌드
다음 셀은 Google API 검색 서비스를 사용하여 자동 생성된 API 클라이언트를 빌드합니다. JSON 형식 API 스키마는 Cloud Storage 버킷에서 호스팅됩니다.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
학습 구성
이 가이드에서는 AI Platform Optimizer가 학습을 만들고 시도를 요청합니다. 각 시도마다 추천된 초매개변수를 사용하여 모델 학습을 수행하기 위해 AI Platform Training 내장 알고리즘 작업을 만듭니다. 각 시도의 측정은 모델 accuracy로 보고됩니다.
AI Platform Optimizer에서 제공하는 조건부 매개변수 기능은 초매개변수에 대해 트리와 유사한 검색 공간을 정의합니다. 최상위 초매개변수는 model_type이며 LINEAR과 WIDE_AND_DEEP 사이에서 결정됩니다. 각 모델 유형에는 미세 조정할 두 번째 수준 초매개변수가 있습니다.
model_type이LINEAR이면learning_rate가 미세 조정됩니다.model_type이WIDE_AND_DEEP이면learning_rate및dnn_learning_rate모두 미세 조정됩니다.
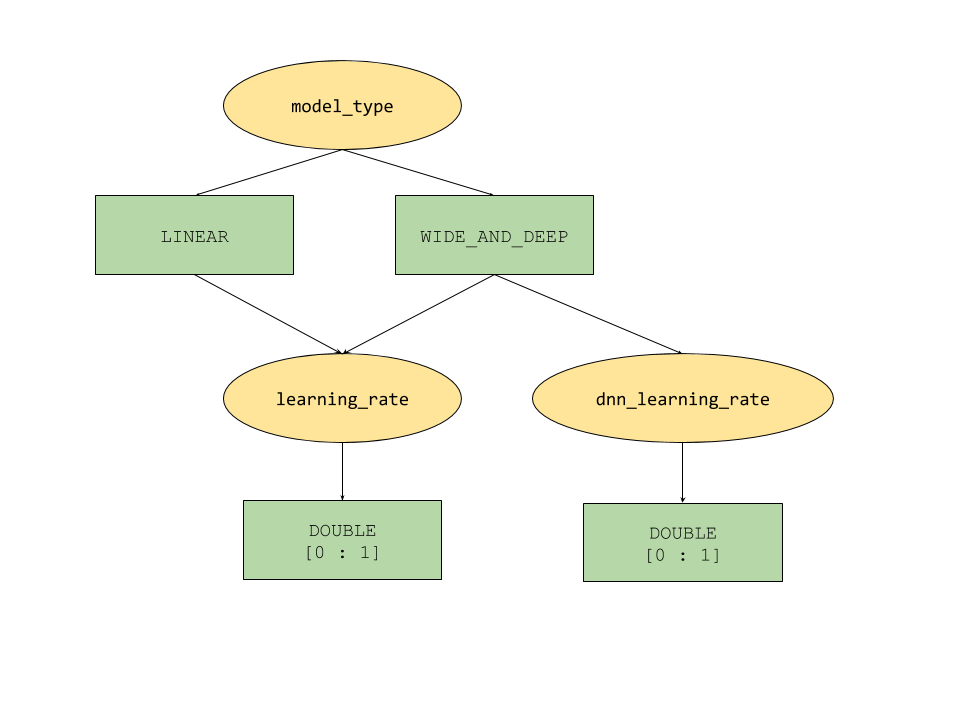
다음은 계층적 Python 사전으로 빌드된 샘플 학습 구성입니다. 이미 작성되었습니다. 셀을 실행하여 학습을 구성합니다.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
학습 만들기
다음으로 학습을 만듭니다. 이 학습은 이후 목표를 최적화하기 위해 실행됩니다.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
입력/출력 매개변수 설정
다음으로 다음 출력 매개변수를 설정합니다.
OUTPUT_BUCKET 및 OUTPUT_DIR은 AI Platform Training 작업의 'job_dir'로 사용되는 Cloud Storage 버킷 및 디렉터리입니다. OUTPUT_BUCKET은 프로젝트의 버킷이어야 하며 OUTPUT_DIR은 버킷의 출력 폴더에 지정할 이름입니다.
job_dir의 형식은 'gs://$OUTPUT_BUCKET/$OUTPUT_DIR/'입니다.
TRAINING_DATA_PATH은 입력 학습 데이터세트의 경로입니다.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
측정항목 평가
이 섹션에서는 시도 평가 방법을 정의합니다.
각 시도마다 AI Platform Optimizer에서 추천하는 초매개변수를 사용하여 머신러닝 모델을 학습시키기 위해 AI Platform 내장 알고리즘 작업을 제출합니다. 작업이 완료되면 각 작업은 모델 요약 파일을 Cloud Storage에 씁니다. 작업 디렉터리에서 모델 정확성을 검색하고 시도의 final_measurement로 보고할 수 있습니다.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
추천/시도 요청 구성
client_id - 추천을 요청하는 클라이언트의 식별자입니다. 여러 SuggestTrialsRequests의 client_id가 동일한 경우 시도가 PENDING이면 서비스는 동일한 추천 시도를 반환하고 마지막 추천 시도가 완료되면 새 시도를 제공합니다.
suggestion_count_per_request - 단일 요청에서 요청된 추천(시도) 수입니다.
max_trial_id_to_stop - 중지하기 전에 살펴볼 시도 수입니다. 코드 실행 시간을 줄이려면 4로 설정해야 하므로 수렴을 기대하지 마세요. 수렴의 경우 약 20이 될 수 있습니다. 일반적으로 총 측정기준에 10을 곱하는 것이 좋습니다.
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
AI Platform Optimizer 시도 요청 및 실행
시도를 실행합니다.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[선택사항] 자체 매개변수를 사용하여 시도 만들기
AI Platform Optimizer의 API를 사용하면 서비스에서 매개변수의 추천(suggest 메서드)을 요청하는 것 외에도 사용자가 자체 매개변수를 사용하여 시도(create 메서드)를 만들 수 있습니다. AI Platform Optimizer는 사용자가 수행한 실험을 예약하고 새로운 추천을 생성하는 데 필요한 지식을 습득하도록 지원합니다.
예를 들어 AI Platform Optimizer에서 추천한 것 대신 자체 model_type 및 learning_rate를 사용하여 모델 학습 작업을 실행하면 학습의 일환으로 시도를 만들 수 있습니다.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
시도 나열
각 최적화 시도 학습의 결과를 나열합니다.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
삭제
이 프로젝트에 사용된 모든 Google Cloud 리소스를 삭제하려면 이 가이드에서 사용한 Google Cloud 프로젝트를 삭제하면 됩니다.