|
|
|
Neste tutorial, demonstramos a otimização de objetivos condicionais do AI Platform Optimizer.
Dataset
O conjunto de dados de renda do censo usado para treinamento nesta amostra está hospedado no Repositório de machine learning da UC Irvine (páginas em inglês).
Usando dados do censo que contêm a idade, a educação, o estado civil e a ocupação da pessoa, os recursos serão usados para prever se a pessoa ganha mais de US$ 50.000 por ano (o rótulo de destino). Você treinará um modelo de regressão logística que, com as informações de um indivíduo, gera um número entre 0 e 1. Esse número pode ser interpretado como a probabilidade de o indivíduo ter uma renda anual de mais de 50.000 dólares.
Objetivo
Neste tutorial, demonstramos como usar o AI Platform Optimizer para otimizar a pesquisa de hiperparâmetros para modelos de machine learning.
Este exemplo implementa uma demonstração de aprendizado automático que otimiza um modelo de classificação em um conjunto de dados do censo usando o AI Platform Optimizer com algoritmos integrados do AI Platform Training. Use o AI Platform Optimizer para receber valores de hiperparâmetros sugeridos e enviar jobs de treinamento de modelo com os valores de hiperparâmetros sugeridos por meio de algoritmos integrados do AI Platform Training.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud:
- AI Platform Training
- Cloud Storage
Saiba mais sobre os preços do AI Platform Training e os preços do Cloud Storage e use a calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Pacotes de instalação e dependências do PIP
Instale outras dependências não instaladas no ambiente do notebook.
- Use a versão principal do GA mais recente do framework.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Configurar seu projeto do Google Cloud
As seguintes etapas são necessárias, independentemente de seu ambiente de notebook.
Se você estiver executando este notebook localmente, será necessário instalar o SDK do Google Cloud.
Insira o ID do projeto na célula abaixo. Em seguida, execute a célula para garantir que o SDK do Cloud use o projeto certo para todos os comandos neste notebook.
Observação: o Jupyter executa linhas com prefixo ! como comandos shell e interpola variáveis Python com prefixo com $ nesses comandos.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Autenticar sua conta do Google Cloud
Se você estiver usando notebooks do AI Platform, seu ambiente já estará autenticado. Ignore estas etapas.
A célula abaixo exigirá que você se autentique duas vezes.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Importar bibliotecas
import json
import time
import datetime
from googleapiclient import errors
Tutorial
Configuração
Nesta seção, definimos alguns parâmetros e métodos util para chamar APIs AI Platform Optimizer. Preencha as informações a seguir para começar.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
Criar o cliente da API
A célula a seguir cria o cliente da API gerado automaticamente usando o serviço de descoberta da API do Google. O esquema da API de formato JSON é hospedado em um bucket do Cloud Storage.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Configuração do estudo
Neste tutorial, o AI Platform Optimizer cria um estudo e solicita testes. Para cada teste, você criará um job de algoritmo integrado do AI Platform Training para fazer o treinamento de modelo usando os hiperparâmetros sugeridos. Uma medição para cada teste é informada como accuracy de modelo.
Os recursos de parâmetro condicional fornecidos pelo AI Platform Optimizer definem um espaço de pesquisa semelhante a uma árvore para hiperparâmetros. O hiperparâmetro de nível superior é model_type, que é decidido entre LINEAR e WIDE_AND_DEEP. Cada tipo de modelo tem hiperparâmetros de segundo nível correspondentes para ajustar:
- Se
model_typeforLINEAR,learning_rateserá ajustado. - Se
model_typeforWIDE_AND_DEEP, os parâmetroslearning_rateednn_learning_rateserão ajustados.
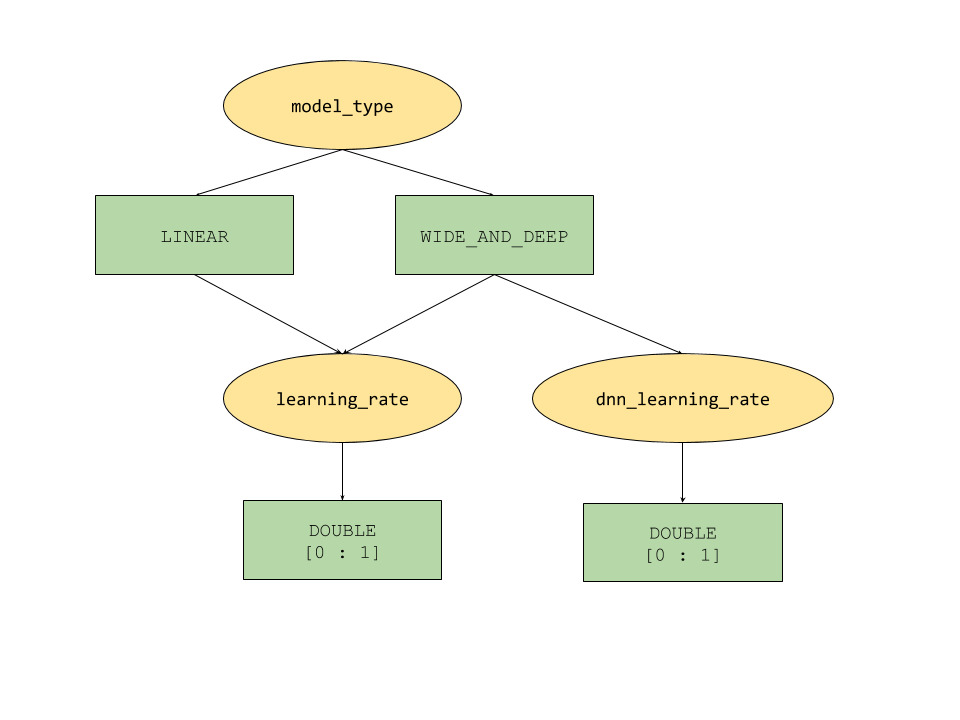
Veja a seguir um exemplo de configuração de estudo, criado como um dicionário hierárquico do Python. Ele já está preenchido. Execute a célula para configurar o estudo.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Criar o estudo
Em seguida, crie o estudo, que será executado posteriormente para otimizar o objetivo.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Definir parâmetros de entrada/saída
Em seguida, defina os seguintes parâmetros de saída.
OUTPUT_BUCKET e OUTPUT_DIR são o intervalo e o diretório do Cloud Storage usados como "job_dir" para jobs de treinamento do AI Platform. OUTPUT_BUCKET precisa ser um intervalo no projeto e OUTPUT_DIR é o nome que você quer dar à pasta de saída no bucket.
job_dir terá o formato de 'gs://$OUTPUT_BUCKET/$OUTPUT_DIR/'
TRAINING_DATA_PATH é o caminho para o conjunto de dados de treinamento de entrada.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Avaliação da métrica
Nesta seção, são definidos os métodos para fazer a avaliação do teste.
Para cada teste, envie um job de algoritmo integrado do AI Platform para treinar um modelo de machine learning usando hiperparâmetros sugeridos pelo AI Platform Optimizer. Cada job grava o arquivo de resumo do modelo no Cloud Storage quando o job é concluído. É possível recuperar a precisão do modelo do diretório do job e denunciá-lo como final_measurement do teste.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Configuração para solicitar sugestões/testes
client_id: o identificador do cliente que está solicitando a sugestão. Se vários SuggestTrialsRequests tiverem o mesmo client_id, o serviço retornará o teste sugerido idêntico se o teste for PENDING e fornecerá um novo teste se o último teste sugerido tiver sido concluído.
suggestion_count_per_request: o número de sugestões (testes) solicitadas em uma única solicitação.
max_trial_id_to_stop: o número de testes a serem explorados antes de serem interrompidos. Ele é definido como 4 para reduzir o tempo de execução do código. Portanto, não espere a convergência. Para a convergência, provavelmente seria cerca de 20 (uma boa regra geral é multiplicar a dimensão total por 10).
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
Solicitar e executar testes do AI Platform Optimizer
Execute os testes.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[OPCIONAL] Criar testes usando seus próprios parâmetros
Além de solicitar sugestões (o método suggest) de parâmetros do serviço, a API AI Platform Optimizer também permite que os usuários criem testes (o método create) usando os próprios parâmetros. O AI Platform Optimizer ajudará a contratar os experimentos feitos pelos usuários e a gerar conhecimento para gerar novas sugestões.
Por exemplo, se você executar um job de treinamento de modelo usando seu próprio model_type e learning_rate em vez daqueles sugeridos pelo AI Platform Optimizer, crie um teste para ele como parte do estudo.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
Listar testes
Liste os resultados de cada treinamento de teste de otimização.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Limpeza
Para limpar todos os recursos do Google Cloud usados neste projeto, exclua o projeto do Google Cloud usado no tutorial.