|
|
|
In dieser Anleitung wird die bedingte Zieloptimierung des AI Platform-Optimierungstools gezeigt.
Dataset
Das in diesem Beispiel für das Training verwendete Census Income Data Set (Dataset zur Einkommenserhebung) wird vom UC Irvine Machine Learning Repository gehostet.
Anhand von Volkszählungsdaten, die das Alter, die Ausbildung, den Familienstand und die Beschäftigung einer Person beschreiben, wird vorhergesagt, ob die Person mehr als 50.000 US-Dollar pro Jahr verdient (Ziellabel). Sie trainieren ein logistisches Regressionsmodell, das bei Angabe der Daten einer Person eine Zahl zwischen 0 und 1 ausgibt. Diese Zahl kann als Wahrscheinlichkeit interpretiert werden, dass die Person ein Jahreseinkommen von mehr als 50.000 US-Dollar hat.
Ziel
In dieser Anleitung erfahren Sie, wie Sie mit AI Platform Optimizer die Hyperparameter-Suche für Modelle für maschinelles Lernen optimieren.
In diesem Beispiel wird eine Demo für automatisches Lernen implementiert. In der Demo wird ein Klassifizierungsmodell anhand eines Datasets mit Erhebungsdaten optimiert. Hierzu wird wiederum das AI Platform-Optimierungstool mit integrierten Algorithmen von AI Platform Training verwendet. Mit dem AI Platform-Optimierungstool können Sie empfohlene Hyperparameterwerte abrufen und Modelltrainingsjobs mit diesen vorgeschlagenen Hyperparameterwerten mithilfe der in AI Platform Training integrierten Algorithmen senden.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloud verwendet.
- AI Platform Training
- Cloud Storage
Informieren Sie sich über die Preise von AI Platform Training und die Preise von Cloud Storage. Mit dem Preisrechner können Sie die voraussichtlichen Kosten anhand der geplanten Nutzung kalkulieren.
PIP-Installationspakete und Abhängigkeiten
Installieren Sie zusätzliche Abhängigkeiten, die nicht in der Notebookumgebung installiert sind.
- Verwenden Sie die neueste GA-Hauptversion des Frameworks.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Google Cloud-Projekt einrichten
Die folgenden Schritte sind unabhängig von der Notebookumgebung erforderlich.
Wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
Wenn Sie dieses Notebook lokal ausführen, müssen Sie Google Cloud SDK installieren.
Geben Sie Ihre Projekt-ID in die Zelle unten ein. Führen Sie dann die Zelle aus, damit das Cloud SDK das richtige Projekt für alle Befehle in diesem Notebook verwendet.
Hinweis: Jupyter führt Zeilen mit dem Präfix ! als Shell-Befehle aus und interpoliert Python-Variablen mit dem Präfix $ in diese Befehle.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Google Cloud-Konto authentifizieren
Wenn Sie AI Platform Notebooks verwenden, ist Ihre Umgebung bereits authentifiziert. Überspringen Sie diese Schritte.
In der Zelle unten müssen Sie sich zweimal authentifizieren.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Bibliotheken importieren
import json
import time
import datetime
from googleapiclient import errors
Anleitung
Einrichtung
In diesem Abschnitt werden einige Parameter und util-Methoden zum Aufrufen von AI Platform Optimizer APIs definiert. Geben Sie zum Einstieg die folgenden Informationen ein.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
API-Client erstellen
Die folgende Zelle erstellt den automatisch generierten API-Client mit dem Google API Discovery Service. Das API-Schema im JSON-Format wird in einem Cloud Storage-Bucket gehostet.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Studienkonfiguration
In dieser Anleitung erstellt der AI Platform Optimizer eine Studie und fordert Tests an. Für jeden Test erstellen Sie einen integrierten AI Platform Training-Algorithmusjob, um Modelltraining mithilfe der vorgeschlagenen Hyperparameter durchzuführen. Eine Messung für jeden Test wird als Modell accuracy ausgegeben.
Die vom AI Platform-Optimierungstool bereitgestellten bedingten Parameter definieren einen baumartigen Suchbereich für Hyperparameter. Der Hyperparameter der obersten Ebene ist model_type, der zwischen LINEAR und WIDE_AND_DEEP festgelegt wird. Jeder Modelltyp verfügt über entsprechende abzustimmende Hyperparameter der zweiten Ebene:
- Wenn
model_typeLINEARist, wirdlearning_rateabgestimmt. - Wenn
model_typeWIDE_AND_DEEPist, werden sowohllearning_rateals auchdnn_learning_rateabgestimmt.
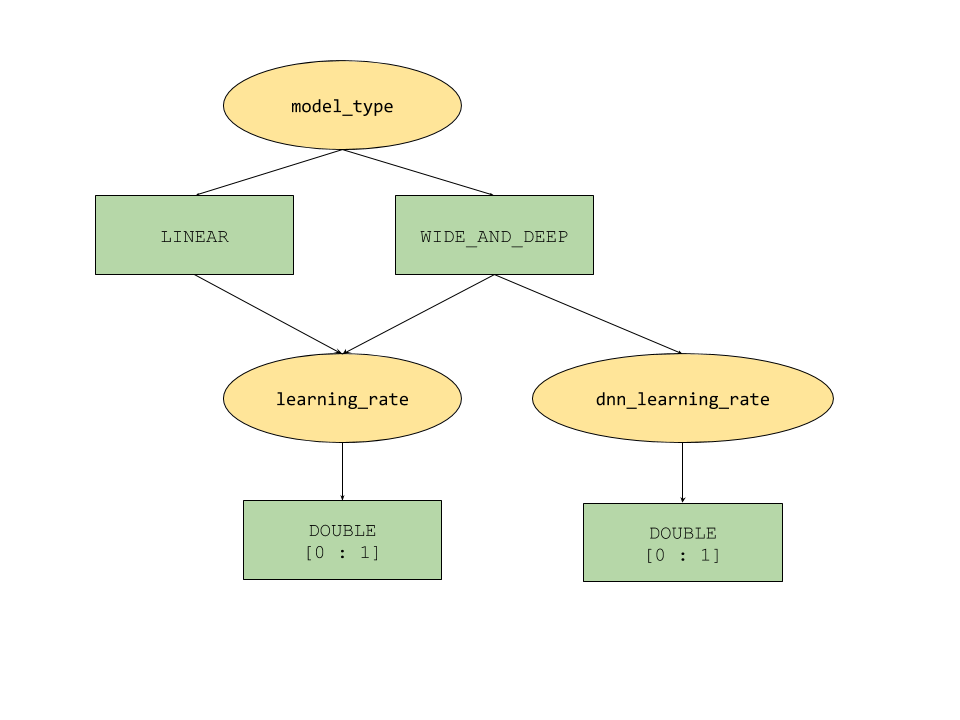
Im Folgenden finden Sie eine beispielhafte Studienkonfiguration, die als hierarchisches Python-Wörterbuch erstellt wurde. Es ist bereits ausgefüllt. Führen Sie die Zelle aus, um die Studie zu konfigurieren.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Studie erstellen
Erstellen Sie als Nächstes die Studie, die Sie später zur Optimierung des Ziels ausführen werden.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Eingabe-/Ausgabeparameter festlegen
Legen Sie dann die folgenden Ausgabeparameter fest.
OUTPUT_BUCKET und OUTPUT_DIR sind der Cloud Storage-Bucket und das Verzeichnis, das für AI Platform Training-Jobs als "job_dir" verwendet werden. OUTPUT_BUCKET sollte ein Bucket in Ihrem Projekt sein und OUTPUT_DIR ist der Name, den Sie dem Ausgabeordner in Ihrem Bucket zuweisen möchten.
job_dir hat das Format "gs://$OUTPUT_BUCKET/$OUTPUT_DIR/".
TRAINING_DATA_PATH ist der Pfad für das Eingabe-Trainings-Dataset.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Messwertevaluierung
In diesem Abschnitt werden die Methoden für die Testbewertung definiert.
Reichen Sie für jeden Test einen integrierten AI Platform-Algorithmusjob ein, um ein Modell für maschinelles Lernen mit vom AI Platform-Optimierungstool vorgeschlagenen Hyperparametern zu trainieren. Jeder Job schreibt die Modellzusammenfassungsdatei nach Abschluss des Jobs in Cloud Storage. Sie können die Modellgenauigkeit aus dem Jobverzeichnis abrufen und als final_measurement des Tests melden.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Konfiguration zur Anforderung von Vorschlägen/Tests
client_id: Die Kennung des Clients, der den Vorschlag anfordert. Wenn mehrere SuggestTrialsRequests dieselbe client_id haben, gibt der Dienst den identischen vorgeschlagenen Test zurück, wenn der Test noch aussteht (PENDING), und stellt einen neuen Test bereit, wenn der letzte vorgeschlagene Test abgeschlossen wurde.
suggestion_count_per_request: Die Anzahl der in einer einzelnen Anfrage angeforderten Vorschläge (Tests).
max_trial_id_to_stop: Die Anzahl der Tests, die vor dem Anhalten betrachtet werden sollen. Sie ist auf 4 festgelegt, um die Zeit für die Ausführung des Codes zu verkürzen. Erwarten Sie deshalb keine Konvergenzen. Für eine Konvergenz müsste sie wahrscheinlich bei 20 liegen. Eine gute Faustregel ist, die Gesamtdimensionalität mit 10 zu multiplizieren.
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
AI Platform-Optimierungstests anfordern und ausführen
Führen Sie die Tests aus.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[OPTIONAL] Tests mit Ihren eigenen Parametern erstellen
Neben dem Anfordern von Vorschlägen (der suggest -Methode) von Parametern aus dem Dienst ermöglicht die API des AI Platform Optimizer Usern das Erstellen von Tests (die create -Methode) unter Verwendung ihrer eigenen Parameter. Mit dem AI Platform-Optimierungstool können Sie die von Nutzern durchgeführten Tests verwalten und das Wissen nutzen, um neue Vorschläge zu erstellen.
Wenn Sie beispielsweise einen Modelltrainingsjob mit Ihren eigenen model_type und learning_rate anstelle der vom AI Platform Optimierungstool vorgeschlagenen ausführen, können Sie im Rahmen des Tests eine Testversion dafür erstellen.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
Tests auflisten
Listen Sie die Ergebnisse der einzelnen Schulungen zur Optimierung auf.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Bereinigen
Wenn Sie alle für dieses Projekt verwendeten Google Cloud-Ressourcen bereinigen möchten, können Sie das Google Cloud-Projekt löschen, das Sie für diese Anleitung verwendet haben.