|
|
|
This tutorial demonstrates AI Platform Optimizer conditional objective optimization.
Dataset
The Census Income Data Set that this sample uses for training is hosted by the UC Irvine Machine Learning Repository.
Using census data which contains a person's age, education, marital status, and occupation (the features), the goal will be to predict whether or not the person earns more than 50,000 dollars a year (the target label). You will train a logistic regression model that, given an individual's information, outputs a number between 0 and 1. This number can be interpreted as the probability that the individual has an annual income of over 50,000 dollars.
Objective
This tutorial demonstrates how to use AI Platform Optimizer to optimize the hyperparameter search for machine learning models.
This sample implements an automatic learning demo that optimizes a classification model on a census dataset by using AI Platform Optimizer with AI Platform Training built-in algorithms. You will use AI Platform Optimizer to get suggested hyperparameter values and submit model training jobs with those suggested hyperparameter values through AI Platform Training built-in algorithms.
Costs
This tutorial uses billable components of Google Cloud:
- AI Platform Training
- Cloud Storage
Learn about AI Platform Training pricing and Cloud Storage pricing, and use the Pricing Calculator to generate a cost estimate based on your projected usage.
PIP install packages and dependencies
Install additional dependencies not installed in the notebook environment.
- Use the latest major GA version of the framework.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Set up your Google Cloud project
The following steps are required, regardless of your notebook environment.
If you are running this notebook locally, you will need to install Google Cloud SDK.
Enter your project ID in the cell below. Then run the cell to make sure the Cloud SDK uses the right project for all the commands in this notebook.
Note: Jupyter runs lines prefixed with ! as shell commands, and it interpolates Python variables prefixed with $ into these commands.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Authenticate your Google Cloud account
If you are using AI Platform Notebooks, your environment is already authenticated. Skip these steps.
The cell below will require you to authenticate yourself twice.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Import libraries
import json
import time
import datetime
from googleapiclient import errors
Tutorial
Setup
This section defines some parameters and util methods to call AI Platform Optimizer APIs. Please fill in the following information to get started.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
Build the API client
The following cell builds the auto-generated API client using Google API discovery service. The JSON format API schema is hosted in a Cloud Storage bucket.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Study configuration
In this tutorial, AI Platform Optimizer creates a study and requests trials. For each trial, you will create an AI Platform Training built-in algorithm job to do model training using the suggested hyperparameters. A measurement for each trial is reported as model accuracy.
The conditional parameter features provided by AI Platform Optimizer define a tree-like search space for hyperparameters. The top-level hyperparameter is model_type which is decided between LINEAR and WIDE_AND_DEEP. Each model type has corresponding second level hyperparameters to tune:
- If
model_typeisLINEAR,learning_rateis tuned. - If
model_typeisWIDE_AND_DEEP, bothlearning_rateanddnn_learning_rateare tuned.
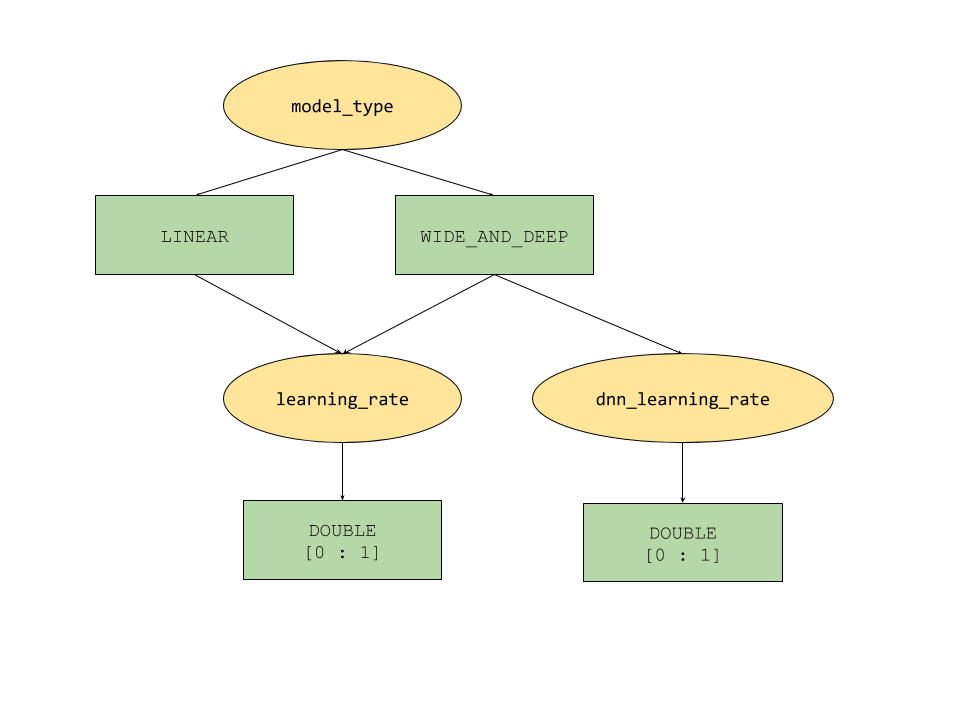
The following is a sample study configuration, built as a hierarchical python dictionary. It is already filled out. Run the cell to configure the study.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Create the study
Next, create the study, which you will subsequently run to optimize the objective.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Set input/output parameters
Next, set the following output parameters.
OUTPUT_BUCKET and OUTPUT_DIR are the Cloud Storage bucket and directory used as 'job_dir' for AI Platform Training jobs. OUTPUT_BUCKET should be a bucket in your project and OUTPUT_DIR is the name you want to give to the output folder in your bucket.
job_dir will be in the format of 'gs://$OUTPUT_BUCKET/$OUTPUT_DIR/'
TRAINING_DATA_PATH is the path for the input training dataset.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Metric evaluation
This section defines the methods to do trial evaluation.
For each trial, submit an AI Platform built-in algorithm job to train a machine learning model using hyperparameters suggested by AI Platform Optimizer. Each job writes the model summary file into Cloud Storage when the job completes. You can retrieve the model accuracy from the job directory and report it as the final_measurement of the trial.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Configuration for requesting suggestions/trials
client_id - The identifier of the client that is requesting the suggestion. If multiple SuggestTrialsRequests have the same client_id, the service will return the identical suggested trial if the trial is PENDING, and provide a new trial if the last suggested trial was completed.
suggestion_count_per_request - The number of suggestions (trials) requested in a single request.
max_trial_id_to_stop - The number of trials to explore before stopping. It is set to 4 to shorten the time to run the code, so don't expect convergence. For convergence, it would likely need to be about 20 (a good rule of thumb is to multiply the total dimensionality by 10).
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
Request and run AI Platform Optimizer trials
Run the trials.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[OPTIONAL] Create trials using your own parameters
Besides requesting suggestions (the suggest method) of parameters from the service, AI Platform Optimizer's API also lets users create trials (the create method) using their own parameters. AI Platform Optimizer will help bookkeep the experiments done by users and take the knowledge to generate new suggestions.
For example, if you run a model training job using your own model_type and learning_rate instead of the ones suggested by AI Platform Optimizer, you can create a trial for it as part of the study.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
List the trials
List the results of each optimization trial training.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Cleaning up
To clean up all Google Cloud resources used in this project, you can delete the Google Cloud project you used for the tutorial.