|
|
|
Tutorial ini menunjukkan pengoptimalan tujuan bersyarat AI Platform Optimizer.
Set data
Set Data Pendapatan Sensus yang digunakan sampel ini untuk pelatihan dihosting oleh Repositori Machine Learning UC Irvine.
Dengan menggunakan data sensus yang berisi usia, pendidikan, status perkawinan, dan pekerjaan seseorang (fitur), sasarannya adalah untuk memprediksi apakah orang tersebut berpenghasilan lebih dari 50.000 dolar per tahun atau tidak (label target). Anda akan melatih model regresi logistik yang, dengan informasi individu, menghasilkan angka antara 0 dan 1. Angka ini dapat ditafsirkan sebagai probabilitas bahwa individu tersebut memiliki pendapatan tahunan lebih dari 50.000 dolar.
Tujuan
Tutorial ini menunjukkan cara menggunakan AI Platform Optimizer untuk mengoptimalkan penelusuran hyperparameter untuk model machine learning.
Contoh ini menerapkan demo pembelajaran otomatis yang mengoptimalkan model klasifikasi pada set data sensus menggunakan AI Platform Optimizer dengan algoritma bawaan AI Platform Training. Anda akan menggunakan AI Platform Optimizer untuk mendapatkan nilai hyperparameter yang disarankan dan mengirimkan tugas pelatihan model dengan nilai hyperparameter yang disarankan tersebut melalui algoritma bawaan AI Platform Training.
Biaya
Tutorial ini menggunakan komponen Google Cloud yang dapat ditagih:
- AI Platform Training
- Cloud Storage
Pelajari harga Pelatihan AI Platform dan harga Cloud Storage, serta gunakan Kalkulator Harga untuk membuat perkiraan biaya berdasarkan penggunaan yang Anda perkirakan.
Paket dan dependensi penginstalan PIP
Menginstal dependensi tambahan yang tidak diinstal di lingkungan notebook.
- Gunakan versi GA utama terbaru dari framework.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Menyiapkan project Google Cloud
Langkah-langkah berikut diperlukan, terlepas dari lingkungan notebook Anda.
Jika menjalankan notebook ini secara lokal, Anda harus menginstal Google Cloud SDK.
Masukkan project ID Anda di sel di bawah. Kemudian, jalankan sel untuk memastikan Cloud SDK menggunakan project yang tepat untuk semua perintah dalam notebook ini.
Catatan: Jupyter menjalankan baris yang diawali dengan ! sebagai perintah shell, dan melakukan interpolasi variabel Python yang diawali dengan $ ke dalam perintah ini.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Mengautentikasi akun Google Cloud
Jika Anda menggunakan AI Platform Notebooks, lingkungan Anda sudah diautentikasi. Lewati langkah-langkah ini.
Sel di bawah akan mengharuskan Anda mengautentikasi diri dua kali.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Mengimpor library
import json
import time
import datetime
from googleapiclient import errors
Tutorial
Penyiapan
Bagian ini menentukan beberapa parameter dan metode utilitas untuk memanggil AI Platform Optimizer API. Isi informasi berikut untuk memulai.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
Mem-build klien API
Sel berikut membuat klien API yang dibuat secara otomatis menggunakan layanan penemuan Google API. Skema API format JSON dihosting di bucket Cloud Storage.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Konfigurasi studi
Dalam tutorial ini, AI Platform Optimizer membuat studi dan meminta uji coba. Untuk setiap uji coba, Anda akan membuat tugas algoritma bawaan AI Platform Training untuk melakukan pelatihan model menggunakan hyperparameter yang disarankan. Pengukuran untuk setiap uji coba dilaporkan sebagai model accuracy.
Fitur parameter bersyarat yang disediakan oleh AI Platform Optimizer menentukan ruang penelusuran seperti hierarki untuk hyperparameter. Hyperparameter tingkat teratas adalah model_type yang ditentukan antara LINEAR dan WIDE_AND_DEEP. Setiap jenis model memiliki hyperparameter tingkat kedua yang sesuai untuk disesuaikan:
- Jika
model_typeadalahLINEAR,learning_rateakan disetel. - Jika
model_typeadalahWIDE_AND_DEEP,learning_ratedandnn_learning_rateakan disesuaikan.
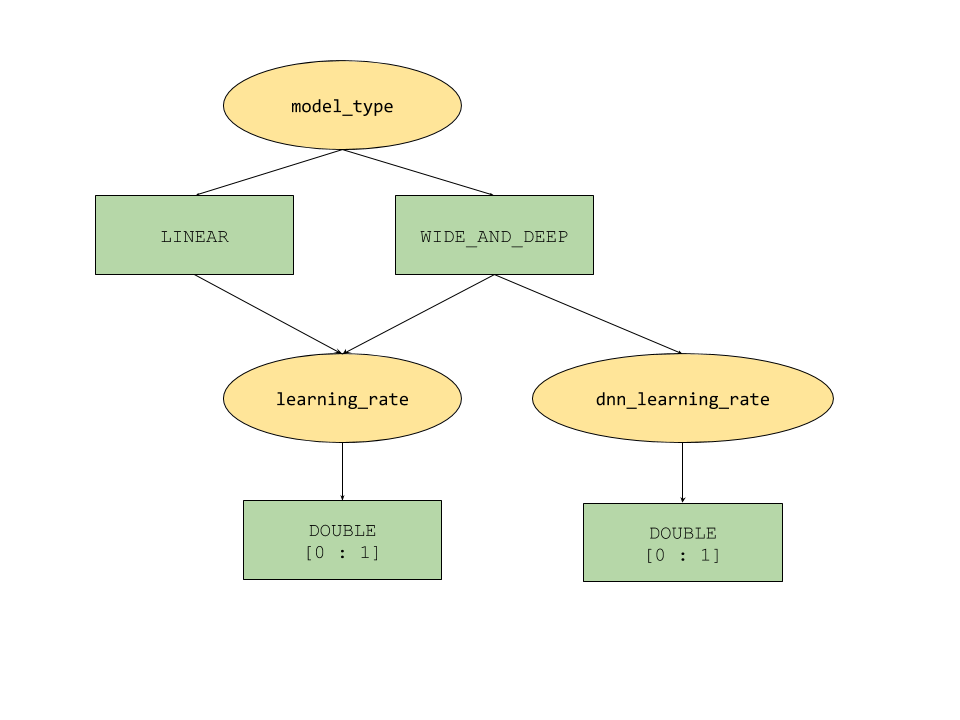
Berikut adalah contoh konfigurasi studi, yang dibuat sebagai kamus python hierarkis. Formulir ini sudah diisi. Jalankan sel untuk mengonfigurasi studi.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Membuat studi
Selanjutnya, buat studi, yang kemudian akan Anda jalankan untuk mengoptimalkan tujuan.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Menetapkan parameter input/output
Selanjutnya, tetapkan parameter output berikut.
OUTPUT_BUCKET dan OUTPUT_DIR adalah bucket dan direktori Cloud Storage yang digunakan sebagai 'job_dir' untuk tugas AI Platform Training. OUTPUT_BUCKET harus berupa bucket dalam project Anda dan OUTPUT_DIR adalah nama yang ingin Anda berikan ke folder output di bucket.
job_dir akan dalam format 'gs://$OUTPUT_BUCKET/$OUTPUT_DIR/'
TRAINING_DATA_PATH adalah jalur untuk set data pelatihan input.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Evaluasi metrik
Bagian ini menentukan metode untuk melakukan evaluasi uji coba.
Untuk setiap uji coba, kirim tugas algoritma bawaan AI Platform untuk melatih model machine learning menggunakan hyperparameter yang disarankan oleh AI Platform Optimizer. Setiap tugas menulis file ringkasan model ke Cloud Storage saat tugas selesai. Anda dapat mengambil akurasi model dari direktori tugas dan melaporkannya sebagai final_measurement uji coba.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Konfigurasi untuk meminta saran/uji coba
client_id - ID klien yang meminta saran. Jika beberapa SuggestTrialsRequests memiliki client_id yang sama, layanan akan menampilkan uji coba yang disarankan yang identik jika uji cobanya adalah PENDING, dan memberikan uji coba baru jika uji coba yang disarankan terakhir telah selesai.
suggestion_count_per_request - Jumlah saran (percobaan) yang diminta dalam satu permintaan.
max_trial_id_to_stop - Jumlah percobaan yang akan dijelajahi sebelum berhenti. Nilai ini ditetapkan ke 4 untuk mempersingkat waktu menjalankan kode, jadi jangan berharap konvergensi. Untuk konvergensi, jumlah ini mungkin harus sekitar 20 (prinsipnya adalah mengalikan total dimensi dengan 10).
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
Meminta dan menjalankan uji coba AI Platform Optimizer
Jalankan uji coba.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[OPSIONAL] Membuat uji coba menggunakan parameter Anda sendiri
Selain meminta saran (metode suggest) parameter dari layanan, API AI Platform Optimizer juga memungkinkan pengguna membuat uji coba (metode create) menggunakan parameter mereka sendiri. AI Platform Optimizer akan membantu mengelola eksperimen yang dilakukan oleh pengguna dan menggunakan pengetahuan tersebut untuk menghasilkan saran baru.
Misalnya, jika Anda menjalankan tugas pelatihan model menggunakan model_type dan learning_rate Anda sendiri, bukan yang disarankan oleh AI Platform Optimizer, Anda dapat membuat uji coba untuknya sebagai bagian dari studi.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
Mencantumkan uji coba
Cantumkan hasil setiap pelatihan uji coba pengoptimalan.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Pembersihan
Untuk membersihkan semua resource Google Cloud yang digunakan dalam project ini, Anda dapat menghapus project Google Cloud yang digunakan untuk tutorial.