Dieser Artikel ist der dritte Teil einer vierteiligen Reihe, in der erläutert wird, wie Sie mithilfe von AI Platform auf Google Cloudden Customer Lifetime Value (CLV) vorhersagen können.
Die Artikel dieser Reihe umfassen die folgenden Punkte:
- Teil 1: Einführung. Einführung in CLV und zwei Modellierungstechniken zur Vorhersage des CLV.
- Teil 2: Das Modell trainieren. Erklärt, wie die Daten vorbereitet und die Modelle trainiert werden.
- Teil 3: Für die Produktion bereitstellen (dieser Artikel). Zeigt, wie die in Teil 2 erläuterten Modelle für ein Produktionssystem bereitgestellt werden.
- Teil 4: AutoML-Tabellen verwenden. Erläutert, wie Modelle mit AutoML-Tabellen erstellt und bereitgestellt werden.
Code installieren
Zur Durchführung des in diesem Artikel erläuterten Vorgangs müssen Sie den Beispielcode von GitHub installieren.
Öffnen Sie, wenn die gcloud CLI installiert ist, auf Ihrem Computer ein Terminalfenster für die Ausführung der Befehle. Wenn Sie das gcloud-CLI nicht installiert haben, öffnen Sie eine Instanz von Cloud Shell.
Klonen Sie das Beispielcode-Repository:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Folgen Sie der Installationsanleitung in den Abschnitten Installation und Automation (Automatisierung) der README-Datei, um Ihre Umgebung einzurichten und die Lösungskomponenten bereitzustellen. Dazu gehören auch das Beispiel-Dataset und die Cloud Composer-Umgebung.
Bei den Befehlsbeispielen in den folgenden Abschnitten wird davon ausgegangen, dass Sie beide Schritte ausgeführt haben.
Im Rahmen der Installation müssen Sie Variablen für Ihre Umgebung einrichten, wie im Einrichtungsabschnitt der README-Datei erläutert.
Ändern Sie die Variable REGION entsprechend der Google Cloud Region, die Ihnen geografisch am nächsten liegt. Eine Liste der Regionen finden Sie unter Regionen und Zonen.
Architektur und Implementierung
Das folgende Diagramm zeigt die in diesem Dokument beschriebene Architektur.

Bei dieser Architektur kommen folgende Funktionen zum Einsatz:
- Datenaufnahme: Die Daten werden in BigQuery importiert.
- Datenvorbereitung: Die Rohdaten werden so umgewandelt, dass sie von den Modellen verwendet werden können.
- Modelltraining: Die Modelle werden so aufgebaut, trainiert und optimiert, dass sie zur Ausführung von Vorhersagen verwendet werden können.
- Bereitstellung der Vorhersage: Offline-Vorhersagen werden gespeichert und mit niedriger Latenz bereitgestellt.
- Automatisierung: Alle diese Aufgaben werden über Cloud Composer ausgeführt und verwaltet.
Daten aufnehmen
In dieser Artikelserie wird keine spezielle Methode zur Datenaufnahme beschrieben. BigQuery kann Daten aus verschiedenen Quellen aufnehmen, einschließlich aus Pub/Sub, aus Cloud Storage und vom BigQuery Data Transfer Service. Weitere Informationen finden Sie unter BigQuery für Data Warehouse-Experten. Für den in dieser Reihe beschriebenen Ansatz wird ein öffentliches Dataset verwendet. Sie müssen dieses Dataset in BigQuery importieren, wie im Beispielcode der README-Datei dargestellt.
Daten vorbereiten
Führen Sie für die Datenvorbereitung BigQuery-Abfragen aus, wie in Teil 2 dieser Reihe beschrieben. In einer Produktionsarchitektur führen Sie die Abfragen als Teil eines gerichteten azyklischen Graphen (DAG) in Apache Airflow aus. Im Abschnitt zur Automatisierung weiter unten in diesem Dokument wird ausführlich beschrieben, wie Sie Abfragen für die Datenvorbereitung ausführen.
Modell in AI Platform trainieren
Dieser Abschnitt bietet einen Überblick über den Trainingsabschnitt der Architektur.
Unabhängig von der Art des ausgewählten Modells wird der in dieser Lösung dargestellte Code für die Ausführung in AI Platform gepackt, und zwar sowohl für das Training als auch für die Vorhersage. AI Platform bietet folgende Vorteile:
- Sie können sie lokal oder in der Cloud in einer verteilten Umgebung ausführen.
- Sie bietet Optionen für die Herstellung einer Verbindung zu anderen Google-Produkten, beispielsweise Cloud Storage.
- Sie können sie mit nur wenigen Befehlen ausführen.
- Sie erleichtert die Einstellung der Hyperparameter.
- Sie skaliert mit minimalen Infrastrukturänderungen, wenn diese überhaupt notwendig sind.
Damit AI Platform ein Modell trainieren und bewerten kann, benötigen Sie Datasets zum Trainieren, Auswerten und Testen. Sie erstellen diese Datasets mithilfe von SQL-Abfragen, wie in Teil 2 dieser Reihe dargestellt. Anschließend exportieren Sie diese Datasets aus BigQuery-Tabellen in Cloud Storage. In der in diesem Artikel beschriebenen Produktionsarchitektur werden die Abfragen über einen Airflow-DAG ausgeführt. Dieser DAG wird im Abschnitt "Automatisierung" weiter unten ausführlich erläutert. Sie können den DAG manuell wie im Abschnitt Run DAGs (DAGs ausführen) der README-Datei dargestellt ausführen.
Vorhersagen bereitstellen
Vorhersagen können online oder offline erstellt werden. Das Erstellen von Vorhersagen unterscheidet sich jedoch von deren Bereitstellung. In diesem CLV-Kontext wirken sich Ereignisse, wie die Anmeldung eines Kunden bei einer Website oder der Besuch eines Shops, nicht erheblich auf den Lifetime-Wert dieses Kunden aus. Daher können Vorhersagen offline erstellt werden, selbst wenn die Ergebnisse in Echtzeit präsentiert werden müssen. Die Offline-Vorhersage enthält folgende operative Features:
- Sie können für Training und Vorhersage die gleichen Vorverarbeitungsschritte ausführen. Wenn Training und Vorhersagen unterschiedlich vorverarbeitet werden, führt dies möglicherweise zu weniger genauen Vorhersagen. Dieses Phänomen wird als Abweichung zwischen Training und Bereitstellung bezeichnet.
- Sie können zur Vorbereitung der Daten für Training und Vorhersage die gleichen Tools verwenden. Bei dem in dieser Reihe vorgestellten Ansatz wird für die Datenvorbereitung hauptsächlich BigQuery genutzt.
AI Platform bietet die Möglichkeit, das Modell bereitzustellen und Offline-Vorhersagen mithilfe eines Batchjobs zu erstellen. Für die Vorhersage werden mit AI Platform folgende Aufgaben vereinfacht:
- Versionen verwalten
- Mit minimalen Infrastrukturänderungen skalieren
- Skalierte Bereitstellung
- Interaktionen mit anderen Google Cloud Produkten
- SLA bereitstellen
Beim Batchjob für die Vorhersage werden sowohl für die Eingabe als auch für die Ausgabe Dateien verwendet, die in Cloud Storage gespeichert sind. Für das DNN-Modell bestimmt die folgende, in task.py definierte Bereitstellungsfunktion das Format der Eingaben:
Das Ausgabeformat der Vorhersage wird in einem EstimatorSpec festgelegt, das von der Estimator-Modellfunktion in diesem Code von model.py zurückgegeben wird:
Vorhersagen verwenden
Nachdem Sie die Modelle erstellt und bereitgestellt haben, können Sie sie für CLV-Vorhersagen verwenden. Folgende CLV-Anwendungsfälle sind gängige Beispiele:
- Ein Datenexperte kann Offline-Vorhersagen für das Erstellen von Nutzersegmenten nutzen.
- Ihr Unternehmen kann in Echtzeit spezifische Angebote präsentieren, wenn ein Kunde online oder in einem Shop mit Ihrer Marke interagiert.
Analysen mit BigQuery
CLV zu verstehen, ist wichtig für Aktivierungen. Dieser Artikel konzentriert sich hauptsächlich auf die Berechnung des Lifetime-Werts basierend auf früheren Verkäufen. Verkaufsdaten stammen in der Regel aus Tools für das Customer-Relationship-Management (CRM). Informationen über Nutzerverhalten können jedoch auch aus anderen Quellen stammen, beispielsweise aus Google Analytics 360.
Wenn Sie Aufgaben wie die folgenden planen, sollten Sie BigQuery verwenden:
- Strukturierte Daten aus einer Vielzahl von Quellen speichern
- Daten aus gängigen SaaS-Tools wie Google Analytics 360, YouTube oder AdWords automatisch übertragen
- Ad-hoc-Abfragen ausführen, einschließlich Verknüpfungen für mehrere Terabyte an Kundendaten
- Daten mit führenden Business-Intelligence-Tools visualisieren
Zusätzlich zu seiner Funktion als Engine für verwalteten Speicher und Abfragen kann BigQuery mithilfe von BigQuery ML Algorithmen für maschinelles Lernen direkt ausführen. Wenn Sie den CLV-Wert jedes Kunden in BigQuery laden, stellen Sie Datenanalysten, Wissenschaftlern und Entwicklern zusätzliche Messwerte für ihre Aufgaben zur Verfügung. Der im nächsten Abschnitt beschriebene Airflow-DAG enthält eine Aufgabe zum Laden der CLV-Vorhersagen in BigQuery.
Datastore für eine Bereitstellung mit niedriger Latenz verwenden
Offline erstellte Vorhersagen können häufig für Echtzeit-Vorhersagen wiederverwendet werden. In diesem Szenario ist die Aktualität der Vorhersage nicht von wesentlicher Bedeutung, aber der Zugriff auf die richtigen Daten zur richtigen Zeit sinnvoll.
Wenn Sie eine Offline-Vorhersage für die Echtzeitbereitstellung speichern, bedeutet dies, dass die Aktionen eines Kunden dessen CLV nicht sofort ändern. Es ist jedoch wichtig, schnell auf diesen CLV zugreifen zu können. Möglicherweise möchte Ihr Unternehmen schnell reagieren, wenn ein Kunde Ihre Website besucht, Ihrem Helpdesk eine Frage stellt oder an der Kasse bezahlt. In solchen Fällen kann eine schnelle Reaktion Ihre Kundenbeziehung verbessern. Daher sind das Speichern Ihrer Vorhersageausgabe in einer schnellen Datenbank und die Bereitstellung sicherer Abfragen für Ihr Frontend ein Schlüssel zum Erfolg.
Nehmen wir an, Sie haben Hunderttausende von Einzelkunden. Datastore ist aus folgenden Gründen eine gute Wahl:
- Es unterstützt NoSQL-Dokumentendatenbanken
- Es bietet schnellen Zugriff auf Daten mithilfe eines Schlüssels (Kundennummer), ermöglicht aber auch SQL-Abfragen
- Es ist über eine REST API zugänglich
- Es ist sofort einsatzbereit und verursacht keinen Einrichtungsaufwand
- Es skaliert automatisch
Da es nicht möglich ist, ein CSV-Dataset direkt in Datastore zu laden, verwenden wir in dieser Lösung Apache Beam auf Dialogflow mit einer JavaScript-Vorlage, um die CLV-Vorhersagen in Datastore zu laden. Das folgende Code-Snippet aus der JavaScript-Vorlage veranschaulicht die Vorgehensweise:
Wenn sich Ihre Daten in Datastore befinden, können Sie auswählen, wie Sie damit interagieren möchten, unter anderem so:
- Datastore-Clientbibliotheken der Anwendung verwenden
- API-Endpunkt mithilfe von Cloud Endpoints oder der Apigee API-Plattform erstellen
- Cloud Run Functions für serverlose Aufgaben verwenden
Lösung automatisieren
Bisher wurde die Vorgehensweise beschrieben, nach der Sie mit den Daten die ersten Schritte der Vorbereitung, des Trainings und der Vorhersage ausführen. Ihre Plattform ist jedoch noch nicht für die Produktion vorbereitet, da Sie noch die Automatisierung und Fehlerverwaltung benötigen.
Mit einigen Skripts können Sie diese beiden Schritte vereinen. Als Best Practice gilt jedoch, die Schritte mithilfe eines Workflow-Managers zu automatisieren. Apache Airflow ist ein beliebtes Tool für das Workflow-Management. Mit Cloud Composer können Sie eine verwaltete Airflow-Pipeline in Google Cloudausführen.
Airflow arbeitet mit gerichteten azyklischen Graphen (DAGs), mit denen Sie jede Aufgabe und deren Beziehung zu anderen Aufgaben definieren können. Nach dem in dieser Serie beschriebenen Ansatz führen Sie die folgenden Schritte aus:
- Erstellen Sie ein BigQuery-Dataset.
- Laden Sie das öffentliche Dataset aus Cloud Storage in BigQuery.
- Bereinigen Sie die Daten aus einer BigQuery-Tabelle und schreiben Sie sie in eine neue BigQuery-Tabelle.
- Erstellen Sie anhand der Daten in einer BigQuery-Tabelle Features und schreiben Sie sie in eine andere BigQuery-Tabelle.
- Teilen Sie, wenn das Modell ein neuronales Deep-Learning-Netzwerk ist, die Daten in BigQuery in ein Trainings-Dataset und ein Bewertungs-Dataset auf.
- Exportieren Sie die Datasets nach Cloud Storage und stellen Sie sie für AI Platform bereit.
- Legen Sie fest, dass das Modell von AI Platform regelmäßig trainiert wird.
- Stellen Sie das aktualisierte Modell in AI Platform bereit.
- Führen Sie regelmäßig eine Batchvorhersage für neue Daten aus.
- Speichern Sie die Vorhersagen, die bereits in Cloud Storage gespeichert sind, in Datastore und BigQuery.
Cloud Composer einrichten
Informationen zum Einrichten von Cloud Composer finden Sie in den Anleitungen der README-Datei des GitHub-Repositorys.
Gerichtete azyklische Graphen für diese Lösung
Diese Lösung verwendet zwei DAGs. Der erste DAG wird für die Schritte 1 bis 8 der vorstehenden Liste verwendet:
Das folgende Diagramm zeigt die Cloud Composer-/Airflow-UI, die die Schritte 1 bis 8 des Airflow-DAGs zusammenfasst.
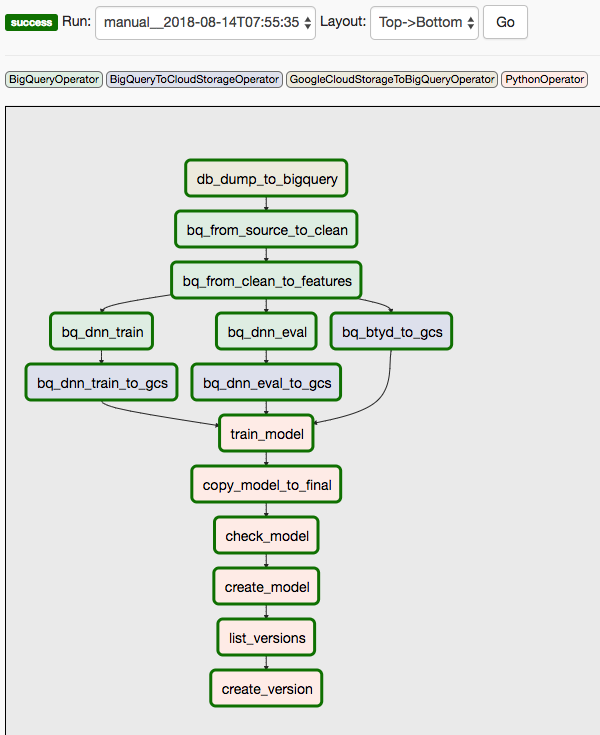
Der zweite DAG wird für die Schritte 9 und 10 verwendet.
Das folgende Diagramm fasst die Schritte 9 und 10 des Airflow-DAG-Prozesses zusammen.
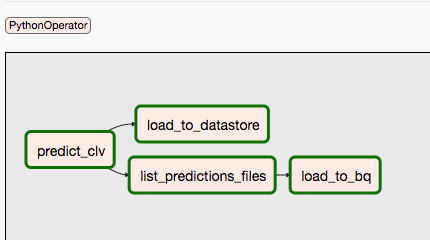
Die DAGs sind getrennt, da Vorhersagen und Training unabhängig voneinander und nach einem anderen Zeitplan ablaufen können. Zum Beispiel könnten Sie Folgendes tun:
- Daten für neue oder bestehende Kunden täglich vorhersagen
- Das Modell wöchentlich neu trainieren, um neue Daten aufzunehmen, oder es auslösen, nachdem eine bestimmte Anzahl neuer Transaktionen eingegangen ist
Sie können den ersten DAG manuell mit dem Befehl im Abschnitt Run Dags (DAGs ausführen) der README-Datei in Cloud Shell oder mit dem gcloud-Befehlszeilen-Interface auslösen.
Der Parameter conf übergibt Variablen an verschiedene Vorgänge der Automatisierung. In der folgenden SQL-Abfrage zum Extrahieren von Funktionen aus den bereinigten Daten werden die Variablen beispielsweise zur Parametrisierung der FROM-Klausel verwendet:
Den zweiten DAG können Sie mit einem ähnlichen Befehl auslösen. Weitere Informationen finden Sie im GitHub-Repository in der README-Datei.
Weitere Informationen
- Komplettes Beispiel im GitHub-Repository ausführen
- Neue Funktionen in das CLV-Modell mithilfe folgender Elemente einbinden:
- Clickstream-Daten, mit denen Sie den CLV für Kunden vorhersagen können, zu denen keine Verlaufsdaten vorhanden sind
- Produktabteilungen und -kategorien, die den Kontext erweitern und das neuronale Netzwerk unterstützen
- Neue Funktionen mit den gleichen Eingaben wie für diese Lösung erstellen, beispielsweise Verkaufstrends für die letzten Wochen oder Monate vor dem Stichtag
- Teil 4: AutoML-Tabellen für das Modell verwenden lesen
- Informationen zu anderen vorausschauenden Prognoselösungen
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center