Artikel ini adalah bagian ketiga dari seri empat bagian yang membahas cara memprediksi nilai umur pelanggan (CLV) menggunakan AI Platform (AI Platform) di Google Cloud.
Artikel dalam seri ini mencakup hal berikut:
- Bagian 1: Pengantar. Memperkenalkan CLV dan dua teknik pemodelan untuk memprediksi CLV.
- Bagian 2: Melatih model. Membahas cara menyiapkan data dan melatih model.
- Bagian 3: Men-deploy ke produksi (artikel ini). Menjelaskan cara men-deploy model yang dibahas di Bagian 2 ke sistem produksi.
- Bagian 4: Menggunakan AutoML Tables. Menunjukkan cara menggunakan AutoML Tables untuk membuat dan men-deploy model.
Menginstal kode
Jika ingin mengikuti proses yang dijelaskan dalam artikel ini, Anda harus menginstal kode contoh dari GitHub.
Jika Anda telah menginstal gcloud CLI, buka jendela terminal di komputer untuk menjalankan perintah ini. Jika Anda belum menginstal gcloud CLI, buka instance Cloud Shell.
Clone repositori kode sampel:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Ikuti petunjuk penginstalan di bagian Instal dan Otomatisasi pada file README untuk menyiapkan lingkungan dan men-deploy komponen solusi. Ini mencakup set data contoh dan lingkungan Cloud Composer.
Contoh perintah di bagian berikut mengasumsikan bahwa Anda telah menyelesaikan kedua langkah ini.
Sebagai bagian dari petunjuk penginstalan, Anda menyiapkan variabel untuk lingkungan seperti yang dijelaskan di bagian penyiapan file README.
Ubah variabel REGION agar sesuai dengan Google Cloud wilayah
yang paling dekat secara geografis dengan Anda. Untuk mengetahui daftar region, lihat Region dan Zona.
Arsitektur dan implementasi
Diagram berikut menunjukkan arsitektur yang digunakan dalam diskusi ini.

Arsitektur ini dibagi menjadi fungsi berikut:
- Penyerapan data: Data diimpor ke BigQuery.
- Persiapan data: Data mentah diubah agar dapat digunakan oleh model.
- Pelatihan model: Model dibuat, dilatih, dan disesuaikan agar dapat digunakan untuk menjalankan prediksi.
- Penayangan prediksi: Prediksi offline disimpan dan tersedia dengan latensi rendah.
- Otomatisasi: Semua tugas ini dijalankan dan dikelola melalui Cloud Composer.
Menyerap data
Rangkaian artikel ini tidak membahas cara tertentu untuk melakukan penyerapan data. Ada banyak cara bagi BigQuery untuk menyerap data, termasuk dari Pub/Sub, dari Cloud Storage, dan dari BigQuery Data Transfer Service. Untuk mengetahui informasi selengkapnya, lihat BigQuery untuk Praktisi Data Warehouse. Dalam pendekatan yang dijelaskan dalam seri ini, kita menggunakan set data publik. Anda mengimpor set data ini ke BigQuery, seperti yang dijelaskan dalam kode contoh dalam file README.
Menyiapkan data
Untuk menyiapkan data, Anda menjalankan kueri di BigQuery seperti yang ditampilkan di Bagian 2 dari seri ini. Dalam arsitektur produksi, Anda menjalankan kueri sebagai bagian dari directed acyclic graph (DAG) Apache Airflow. Bagian tentang otomatisasi nanti dalam dokumen ini memberikan detail selengkapnya tentang cara menjalankan kueri untuk persiapan data.
Melatih model di AI Platform
Bagian ini memberikan ringkasan tentang bagian pelatihan arsitektur.
Apa pun jenis model yang Anda pilih, kode yang ditampilkan dalam solusi ini dikemas untuk dijalankan di AI Platform (AI Platform), baik untuk pelatihan maupun prediksi. AI Platform menawarkan manfaat berikut:
- Anda dapat menjalankannya secara lokal atau di cloud dalam lingkungan terdistribusi.
- Layanan ini menawarkan konektivitas bawaan ke produk Google lainnya, seperti Cloud Storage.
- Anda dapat menjalankannya hanya dengan menggunakan beberapa perintah.
- Model ini memfasilitasi penyesuaian hyperparameter.
- Layanan ini diskalakan dengan perubahan infrastruktur minimum, jika ada.
Agar AI Platform dapat melatih dan mengevaluasi model, Anda perlu menyediakan set data pelatihan, evaluasi, dan pengujian. Anda membuat set data dengan menjalankan kueri SQL seperti yang ditunjukkan di Bagian 2 seri ini. Kemudian, Anda mengekspor set data tersebut dari tabel BigQuery ke Cloud Storage. Dalam arsitektur produksi yang dijelaskan dalam artikel ini, kueri dijalankan oleh DAG Airflow, yang dijelaskan secara lebih mendetail di bagian Otomatisasi di bawah. Anda dapat menjalankan DAG secara manual seperti yang dijelaskan di bagian Jalankan DAG file README.
Menayangkan prediksi
Prediksi dapat dibuat secara online atau offline. Namun, membuat prediksi berbeda dengan menayangkannya. Dalam konteks CLV ini, peristiwa seperti pelanggan yang login ke situs atau mengunjungi toko retail tidak akan memengaruhi nilai umur pelanggan tersebut secara drastis. Oleh karena itu, prediksi dapat dilakukan secara offline, meskipun hasilnya mungkin harus ditampilkan secara real time. Prediksi offline memiliki fitur operasional berikut:
- Anda dapat melakukan langkah prapemrosesan yang sama untuk pelatihan dan prediksi. Jika pelatihan dan prediksi diproses secara berbeda, prediksi Anda mungkin kurang akurat. Fenomena ini disebut kemiringan penayangan pelatihan.
- Anda dapat menggunakan alat yang sama untuk menyiapkan data untuk pelatihan dan prediksi. Pendekatan yang dibahas dalam seri ini terutama menggunakan BigQuery untuk menyiapkan data.
Anda dapat menggunakan AI Platform untuk men-deploy model dan membuat prediksi offline menggunakan tugas batch. Untuk prediksi, AI Platform memfasilitasi tugas seperti berikut:
- Mengelola versi.
- Penskalaan dengan perubahan infrastruktur minimum.
- Men-deploy dalam skala besar.
- Berinteraksi dengan produk Google Cloud lain.
- Memberikan SLA.
Tugas prediksi batch menggunakan file yang disimpan di Cloud Storage untuk input dan output. Untuk model DNN, fungsi penayangan berikut,
yang ditentukan di task.py, menentukan format input:
Format output prediksi ditentukan dalam EstimatorSpec yang ditampilkan oleh
fungsi model Estimator dalam kode ini dari model.py:
Menggunakan prediksi
Setelah selesai membuat model dan men-deploy-nya, Anda dapat menggunakannya untuk melakukan prediksi CLV. Berikut adalah kasus penggunaan CLV yang umum:
- Spesialis data dapat memanfaatkan prediksi offline saat membuat segmen pengguna.
- Organisasi Anda dapat membuat penawaran tertentu secara real time, saat pelanggan berinteraksi dengan merek Anda secara online atau di toko.
Analisis dengan BigQuery
Memahami CLV adalah kunci untuk aktivasi. Artikel ini sebagian besar berfokus pada penghitungan nilai umur pelanggan berdasarkan penjualan sebelumnya. Data penjualan biasanya berasal dari alat pengelolaan hubungan pelanggan (CRM), tetapi informasi tentang perilaku pengguna dapat berasal dari sumber lain, seperti Google Analytics 360.
Anda harus menggunakan BigQuery jika tertarik untuk melakukan salah satu tugas berikut:
- Menyimpan data terstruktur dari banyak sumber.
- Mentransfer data secara otomatis dari alat SaaS umum seperti Google Analytics 360, YouTube, atau AdWords.
- Menjalankan kueri ad hoc, termasuk join pada terabyte data pelanggan.
- Memvisualisasikan data Anda menggunakan alat business intelligence terkemuka.
Selain perannya sebagai mesin kueri dan penyimpanan terkelola, BigQuery dapat menjalankan algoritma machine learning secara langsung menggunakan BigQuery ML. Dengan memuat nilai CLV setiap pelanggan ke BigQuery, Anda memungkinkan analis, ilmuwan, dan engineer data memanfaatkan metrik tambahan dalam tugas mereka. DAG Airflow yang dibahas di bagian berikutnya mencakup tugas untuk memuat prediksi CLV ke BigQuery.
Penyertaan latensi rendah menggunakan Datastore
Prediksi yang dibuat secara offline sering kali dapat digunakan kembali untuk memberikan prediksi secara real time. Untuk skenario ini, keaktualan prediksi tidak penting, tetapi mendapatkan akses ke data pada waktu yang tepat dan dengan cepat sangatlah penting.
Menyimpan prediksi offline untuk penayangan real-time berarti tindakan yang dilakukan pelanggan tidak akan langsung mengubah CLV mereka. Namun, mendapatkan akses ke CLV tersebut dengan cepat itu penting. Misalnya, perusahaan Anda mungkin ingin bereaksi dengan cepat saat pelanggan menggunakan situs Anda, mengajukan pertanyaan ke layanan bantuan, atau melakukan checkout melalui tempat penjualan Anda. Dalam kasus seperti ini, respons yang cepat dapat meningkatkan hubungan pelanggan Anda. Oleh karena itu, menyimpan output prediksi dalam database yang cepat dan menyediakan kueri aman untuk frontend Anda adalah kunci keberhasilan.
Misalkan Anda memiliki ratusan ribu pelanggan unik. Datastore adalah opsi yang baik karena alasan berikut:
- Layanan ini mendukung database dokumen NoSQL.
- API ini memberikan akses cepat ke data menggunakan kunci (ID pelanggan), tetapi juga memungkinkan kueri SQL.
- Layanan ini dapat diakses melalui REST API.
- Alat ini siap digunakan, yang berarti tidak ada overhead penyiapan.
- Skalanya akan otomatis disesuaikan.
Karena tidak ada cara untuk memuat set data CSV secara langsung ke Datastore, dalam solusi ini kita menggunakan Apache Beam di Dialogflow dengan template JavaScript untuk memuat prediksi CLV ke Datastore. Cuplikan kode berikut dari template JavaScript menunjukkan caranya:
Saat data berada di Datastore, Anda dapat memilih cara berinteraksi dengan data tersebut, yang dapat mencakup:
- Menggunakan Library Klien Datastore dari aplikasi Anda.
- Mem-build endpoint API menggunakan Cloud Endpoints atau Platform Apigee API.
- Menggunakan fungsi Cloud Run untuk tugas serverless.
Mengotomatiskan solusi
Anda menggunakan langkah-langkah yang telah dijelaskan sejauh ini saat memulai data untuk menjalankan langkah prapemrosesan, pelatihan, dan prediksi pertama. Namun, platform Anda belum siap untuk diproduksi, karena Anda masih memerlukan otomatisasi dan pengelolaan kegagalan.
Beberapa skrip dapat membantu menggabungkan langkah-langkah tersebut. Namun, praktik terbaiknya adalah mengotomatiskan langkah-langkah tersebut menggunakan pengelola alur kerja. Apache Airflow adalah alat pengelolaan alur kerja yang populer, dan Anda dapat menggunakan Cloud Composer untuk menjalankan pipeline Airflow terkelola di Google Cloud.
Airflow berfungsi dengan directed acyclic graph (DAG), yang memungkinkan Anda menentukan setiap tugas dan hubungannya dengan tugas lain. Dalam pendekatan yang dijelaskan dalam rangkaian ini, Anda menjalankan langkah-langkah berikut:
- Membuat set data BigQuery.
- Muat set data publik dari Cloud Storage ke BigQuery.
- Bersihkan data dari tabel BigQuery dan tulis ke tabel BigQuery baru.
- Buat fitur berdasarkan data dalam satu tabel BigQuery dan tulis ke tabel BigQuery lain.
- Jika modelnya adalah deep neural network (DNN), bagi data menjadi set pelatihan dan set evaluasi dalam BigQuery.
- Ekspor set data ke Cloud Storage dan sediakan untuk AI Platform.
- Minta AI Platform melatih model secara berkala.
- Deploy model yang diperbarui ke AI Platform.
- Jalankan prediksi batch secara berkala pada data baru.
- Simpan prediksi yang sudah disimpan di Cloud Storage ke Datastore dan BigQuery.
Menyiapkan Cloud Composer
Untuk mengetahui informasi tentang cara menyiapkan Cloud Composer, lihat petunjuk dalam file README repositori GitHub.
Directed acyclic graph untuk solusi ini
Solusi ini menggunakan dua DAG. DAG pertama mencakup langkah 1 hingga 8 dari urutan yang tercantum sebelumnya:
Diagram berikut menunjukkan UI Cloud Composer/Airflow, yang menyatakan ringkasan langkah 1 hingga 8 dari langkah DAG Airflow.
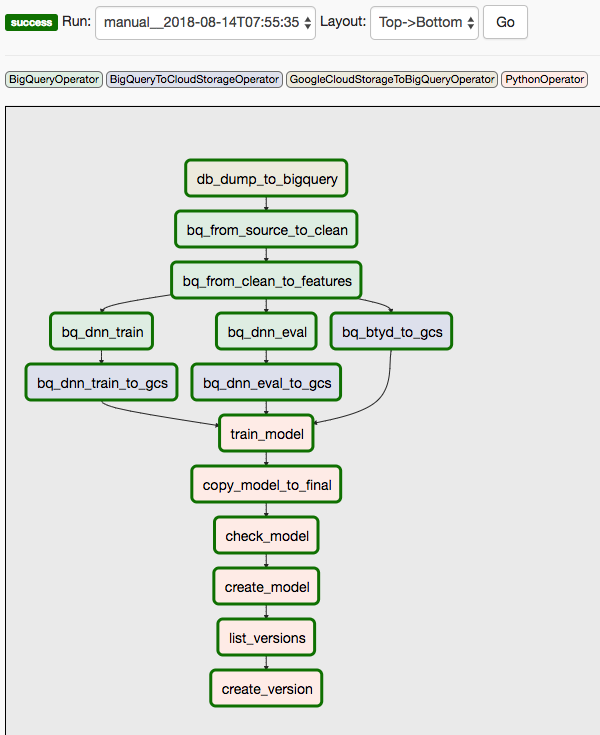
DAG kedua mencakup langkah 9 dan 10.
Diagram berikut merangkum langkah 9 dan 10 dari proses DAG Airflow.
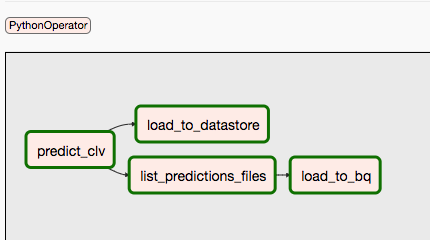
DAG dipisahkan karena prediksi dan pelatihan mungkin terjadi secara independen dan pada jadwal yang berbeda. Misalnya, Anda dapat melakukan hal berikut:
- Prediksi data untuk pelanggan baru atau lama setiap hari.
- Latih ulang model setiap minggu untuk menyertakan data baru, atau picu setelah jumlah transaksi baru tertentu diterima.
Untuk memicu DAG pertama secara manual, Anda dapat menjalankan perintah dari bagian Run Dags pada file README di Cloud Shell atau menggunakan gcloud CLI.
Parameter conf meneruskan variabel ke berbagai bagian otomatisasi. Misalnya, dalam kueri SQL berikut yang digunakan untuk mengekstrak fitur dari data
yang dibersihkan, variabel digunakan untuk memparametrisasi klausa FROM:
Anda dapat memicu DAG kedua menggunakan perintah serupa. Untuk mengetahui detail selengkapnya, lihat file README di repositori GitHub.
Langkah selanjutnya
- Jalankan contoh lengkap di repositori GitHub.
- Gabungkan fitur baru ke dalam model CLV menggunakan beberapa hal berikut:
- Data klik, yang dapat membantu Anda memprediksi CLV untuk pelanggan yang data historisnya tidak Anda miliki.
- Departemen dan kategori produk yang dapat menambahkan beberapa konteks tambahan dan yang mungkin membantu jaringan neural.
- Fitur baru yang Anda buat menggunakan input yang sama dengan yang digunakan dalam solusi ini. Contohnya dapat berupa tren penjualan untuk minggu atau bulan terakhir sebelum tanggal nilai minimum.
- Baca Bagian 4: Menggunakan AutoML Tables untuk model.
- Pelajari solusi perkiraan prediktif lainnya.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.