本文是由四篇文章组成的系列文章中的第四篇。该系列文章讨论如何使用 Google Cloud上的 AI Platform 来预测客户生命周期价值 (CLV)。本文介绍如何使用 AutoML Tables 执行预测。
本系列文章包含以下内容:
- 第 1 篇:简介。 介绍了 CLV 以及用于预测 CLV 的两种建模方法。
- 第 2 篇:训练模型介绍了如何准备数据和训练模型。
- 第 3 篇:部署到生产系统。介绍了如何将第 2 篇所述的模型部署到生产系统。
- 第 4 篇:使用 AutoML Tables(本文)。介绍如何使用 AutoML Tables 构建和部署模型。
本文介绍的过程依赖于本系列第 2 篇文章中介绍的 BigQuery 中的数据处理步骤。本文介绍如何将该 BigQuery 数据集上传到 AutoML Tables 并创建模型。本文还将介绍如何将 AutoML 模型集成到第 3 篇文章所述的生产系统中。
用于实现此系统的代码位于与原始系列相同的 GitHub 代码库中。本文介绍如何使用该代码库中与 AutoML Tables 相关的代码。
AutoML Tables 的优势
在本系列的前几篇文章中,您学习了如何使用 TensorFlow 中实现的统计模型和 DNN 模型来预测 CLV。与其他两种方法相比,AutoML Tables 具有以下几项优势:
- 无需编码即可创建模型。您可以通过控制台界面创建、训练、管理和部署数据集和模型。
- 特征的添加或更改十分简便,在控制台界面即可直接完成。
- 训练过程是自动进行的,包括超参数调节。
- AutoML Tables 可以搜索最适合您的数据集的架构,您无需从众多可用选项中进行选择。
- AutoML Tables 可以详细分析训练模型的性能,包括特征重要性。
因此,使用 AutoML Tables 开发和训练完全优化的模型可以缩短时间并节省费用。
AutoML Tables 解决方案的生产部署要求您使用 Python 客户端 API 来创建和部署模型并运行预测。本文介绍如何使用客户端 API 创建和训练 AutoML Tables 模型。如需了解如何使用 AutoML Tables 控制台执行这些步骤,请参阅 AutoML Tables 文档。
安装代码
如果您尚未安装原始系列的代码,请按照原始系列第 2 篇文章所述的步骤安装代码。GitHub 代码库中的 README 文件介绍了准备环境、安装代码以及在项目中设置 AutoML Tables 所需的所有步骤。
如果您之前安装过代码,则需要执行以下附加步骤来完成本文中的安装事项:
- 在您的项目中启用 AutoML Tables API。
- 激活您先前安装的 miniconda 环境。
- 按照 AutoML Tables 文档中的说明安装 Python 客户端库。
- 创建并下载 API 密钥文件,并将其保存在已知位置,供日后用于客户端库。
运行代码
对于本文中的许多步骤,您可以运行 Python 命令。准备好环境并安装完代码后,您可以选择以下方式运行代码:
在 Jupyter 笔记本中运行代码。在激活的 miniconda 环境中,通过终端窗口运行以下命令:
$ (clv) jupyter notebook
本文中每个步骤所对应的代码均位于
notebooks/clv_automl.ipynb代码库的笔记本中。在 Jupyter 界面中打开此笔记本。然后,您便可以按照教程中的说明执行每个步骤。以 Python 脚本的形式运行代码。本教程的代码步骤位于
clv_automl/clv_automl.py文件的代码库中。该脚本将命令行上的参数值作为可配置参数,例如项目 ID、API 密钥文件的位置、 Google Cloud 区域和 BigQuery 数据集的名称。在激活的 miniconda 环境中,您通过终端窗口运行脚本,用您的 Google Cloud 项目名称替换[YOUR_PROJECT]:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
如需获取参数和默认值的完整列表,请参阅脚本中的
create_parser方法,或运行不带参数值的脚本以查看用法文档。按照 README 中的说明安装 Cloud Composer 环境后,执行 DAG 以运行代码,如后文运行 DAG 中所述。
准备数据
本文在 BigQuery 中使用原始系列的第 2 篇文章中所述的数据集和数据准备步骤。完成该文章中所述的数据汇总后,您就可以创建用于 AutoML Tables 的数据集了。
创建 AutoML Tables 数据集
首先,将您在 BigQuery 中准备的数据上传到 AutoML Tables 中。
如需初始化客户端,请将密钥文件名设置为您在安装步骤中下载的文件的名称:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)创建数据集:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
从 BigQuery 导入数据
创建数据集后,您可以从 BigQuery 导入数据。
从 BigQuery 将数据导入 AutoML Tables 数据集:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
训练模型
在为 CLV 数据创建 AutoML 数据集之后,您可以创建 AutoML Tables 模型。
获取数据集内每个 AutoML Tables 列的列规范:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}在后续步骤中,您必须提供列规范。
将其中一列指定为 AutoML Tables 模型的标签:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)此代码使用第 2 篇文章中 TensorFlow DNN 模型所用的标签列 (
target_monetary)。定义用于训练模型的特征:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')用于训练 AutoML Tables 模型的特征与原始系列第 2 篇文章中用于训练 TensorFlow DNN 模型的特征相同。但是,使用 AutoML Tables 在模型中添加或删减特征要容易得多。在 BigQuery 中创建好特征后,它会自动包含在模型中,除非您按照前面代码段中的说明将其显式删除。
定义用于创建模型的选项。建议对此数据集使用最大限度降低平均绝对误差的优化目标,由
MINIMIZE_MAE参数表示。model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }如需了解详细信息,请参阅有关优化目标的 AutoML Tables 文档。
创建模型并开始训练:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.name客户端调用 (
create_model_response) 的返回值将立即返回。值create_model_response.result()是一个 promise,在训练完成之后才会解除阻止。model_name值是执行模型上其他客户端调用所必需的资源路径。
评估模型
模型训练完成后,您可以检索模型评估结果的统计信息。您可以使用 Google Cloud 控制台或客户端 API。
如需使用控制台,请在 AutoML Tables 控制台中转到评估标签页:

如需使用客户端 API,请检索模型评估结果的统计信息:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]您将看到如下所示的输出:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
与原始系列中使用的概率模型和 TensorFlow 模型相比,853.481 的均方根误差结果更优。但正如第 2 篇文章所述,建议您使用数据尝试提供的每种方法,看看哪种方法效果最佳。
部署 AutoML 模型
原始系列中的 Cloud Composer DAG 已进行了更新,加入了用于训练和预测的 AutoML Tables 模型。如需了解有关 Cloud Composer DAG 功能的一般信息,请参阅原始文章第 3 篇中的解决方案自动化部分。
您可以按照 README 中的说明为此解决方案安装 Cloud Composer 编排系统。
更新后的 DAG 调用 clv_automl/clv_automl.py 脚本中的方法,用于复制之前为了创建模型并运行预测而显示的客户端代码调用。
训练 DAG
更新后用于训练的 DAG 包括创建 AutoML Tables 模型任务。下图显示了用于训练的新 DAG。

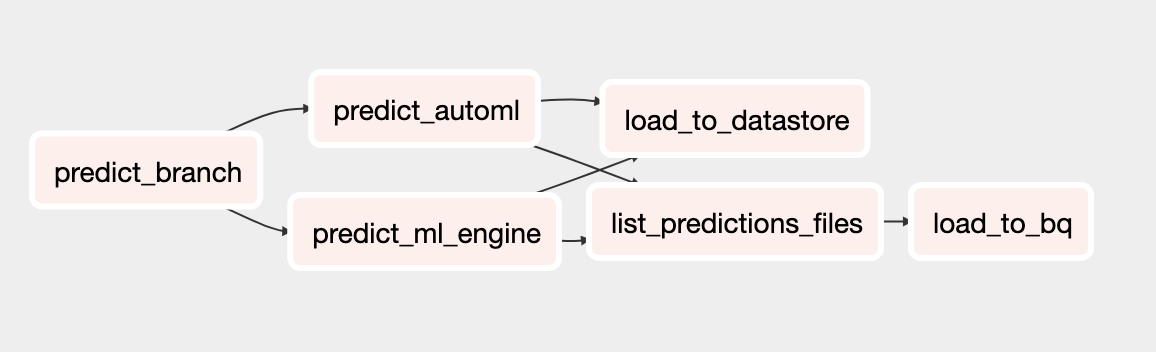
预测 DAG
更新后用于预测的 DAG 包括使用 AutoML Tables 模型执行批量预测任务。下图显示了用于预测的新 DAG。
运行 DAG
如需手动触发 DAG,您可以在 Cloud Shell 中或使用 Google Cloud CLI 运行 README 文件的运行 DAG 部分的命令。
如需运行
build_train_deployDAG,请执行以下操作:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'运行
predict_serveDAG:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
后续步骤
- 查看完整的 CLV 教程集。
- 运行 GitHub 代码库中的完整示例。
- 了解其他预测解决方案。
- 探索有关 Google Cloud 的参考架构、图表和最佳实践。查看我们的 Cloud 架构中心。