En esta página, se proporciona una descripción general del ajuste de modelos de texto y de chat, y la síntesis de los modelos de texto. Obtendrás información sobre los tipos de ajuste disponibles y cómo funciona la síntesis. También aprenderás sobre los beneficios del ajuste y la síntesis, y las situaciones en las que es posible que quieras ajustar o sintetizar un modelo de texto.
Ajusta modelos
Puedes elegir uno de los siguientes métodos para ajustar un modelo de texto:
Ajuste supervisado: Los modelos de generación de texto y chat de texto admiten el ajuste supervisado. El ajuste supervisado de un modelo de texto es una buena opción cuando el resultado de tu modelo no es complejo y es relativamente fácil de definir. Se recomienda el ajuste supervisado para la clasificación, el análisis de opiniones, la extracción de entidades, el resumen del contenido que no es complejo y la escritura de consultas específicas del dominio. Para los modelos de código, la única opción es el ajuste supervisado. Para obtener información sobre cómo ajustar un modelo de texto con ajuste supervisado, consulta Ajusta los modelos de texto con ajuste supervisado.
Ajuste de aprendizaje por refuerzo con retroalimentación humana (RLHF): el modelo de base de generación de texto y algunos modelos de transformador de transferencia de texto a texto de Flan (Flan-T5) admiten el ajuste RLHF. El ajuste de RLHF es una buena opción cuando el resultado de tu modelo es complejo. RLHF funciona bien en modelos con objetivos de nivel de secuencia que no se diferencian con facilidad con el ajuste supervisado. Se recomienda el ajuste del RLHF para responder preguntas, resumir contenido complejo y crear contenido, como una reescritura. Para aprender a ajustar un modelo de texto con el ajuste RLHF, consulta Ajusta los modelos de texto con el ajuste RLHF.
Beneficios del ajuste de modelos de texto
Los modelos de texto ajustados se entrenan con más ejemplos de los que pueden caber en un prompt. Debido a esto, después de ajustar un modelo previamente entrenado, puedes proporcionar menos ejemplos en el mensaje que lo que harías con el modelo original previamente entrenado. Si se requieren menos ejemplos, se obtienen los siguientes beneficios:
- Menor latencia en las solicitudes.
- Se usan menos tokens.
- Una menor latencia y menos tokens reducen el costo de la inferencia.
Destilación de modelos
Además del ajuste supervisado y RLHF, Vertex AI admite la síntesis de modelos. La síntesis es el proceso de entrenar un modelo estudiante más pequeño en un modelo profesor más grande para imitar el comportamiento del modelo más grande y, al mismo tiempo, reducir el tamaño.
Existen varios tipos de síntesis de modelos, incluidos los siguientes:
- Basado en la respuesta: Entrena al modelo de estudiante sobre las probabilidades de respuesta del modelo de profesor.
- Basado en atributos: Entrena al modelo de estudiante para que imite las capas internas del modelo de profesor.
- Basado en relaciones: Entrena al modelo de estudiante sobre las relaciones en los datos de entrada o salida del modelo de profesor.
- Autosíntesis: Los modelos de profesor y estudiante tienen la misma arquitectura y el modelo se enseña a sí mismo.
Beneficios de la síntesis paso a paso
Estos son algunos de los beneficios de la síntesis paso a paso:
- Precisión mejorada: La síntesis paso a paso ha demostrado un rendimiento superior al estándar en las instrucciones con ejemplos limitados de los LLM.
- Un LLM sintetizado puede lograr resultados en las tareas finales específicas de los usuarios que son similares a los resultados de LLM mucho más grandes.
- Supera las restricciones de datos. Puedes usar DSS con un conjunto de datos de instrucciones sin etiquetar con solo unos miles de ejemplos.
- Huellas de hosting más pequeñas.
- Menor latencia de inferencia.
Sintetiza paso a paso con Vertex AI
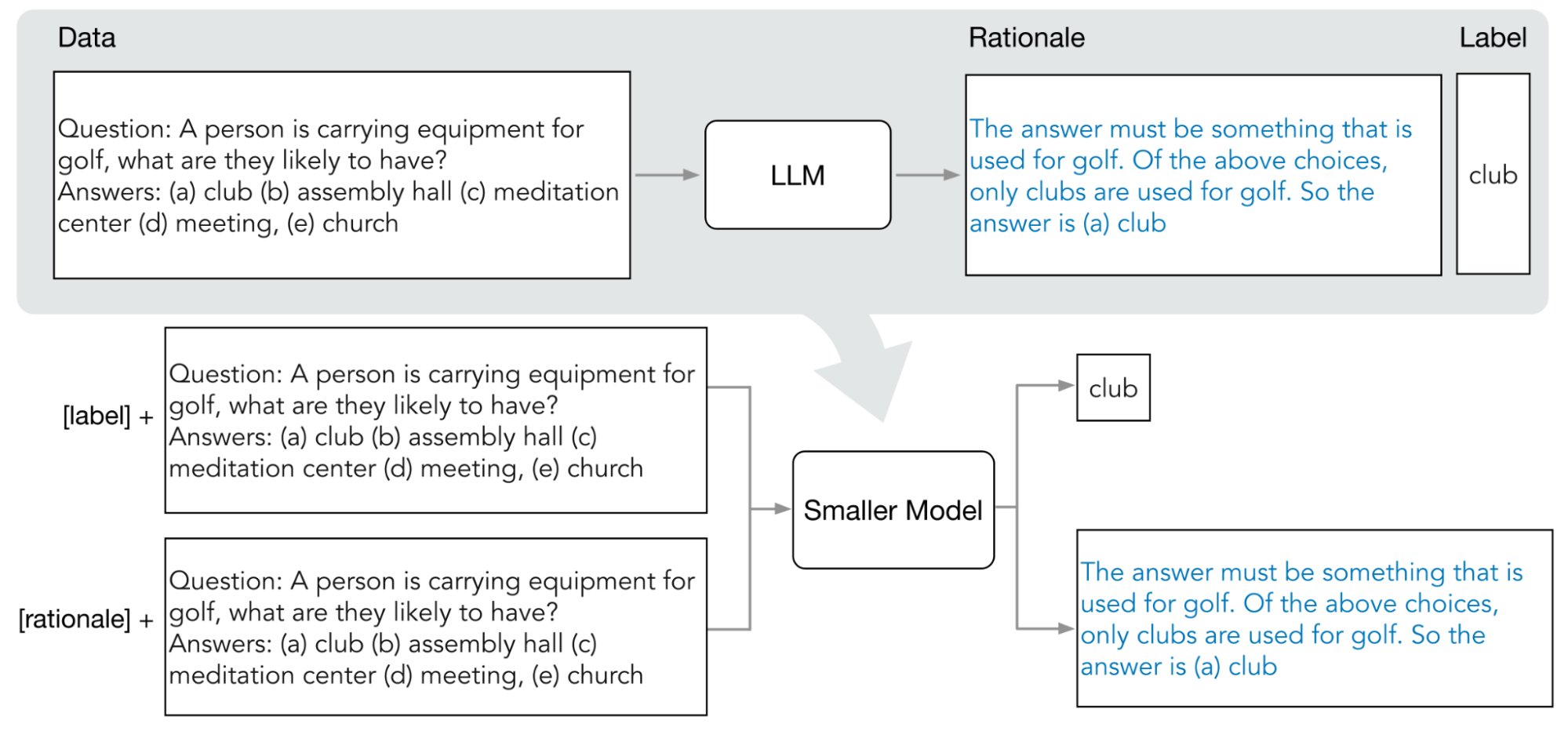
Vertex AI admite una forma de síntesis basada en la respuesta llamada síntesis paso a paso (DSS). DSS es un método para entrenar modelos más pequeños y específicos de una tarea a través de instrucciones de cadena de pensamiento (COT).
Para usar DSS, necesitas un pequeño conjunto de datos de entrenamiento que conste de entradas y etiquetas. Si no hay etiquetas disponibles, el modelo de profesor las genera. El proceso de DSS extrae las justificaciones y, luego, las usa para entrenar el modelo pequeño con una tarea de generación de justificación y una tarea de predicción típica. Esto permite que el modelo pequeño cree un razonamiento intermedio antes de llegar a su predicción final.
En el siguiente diagrama, se muestra cómo la síntesis paso a paso usa instrucciones de COT para extraer lógicas de un modelo de lenguaje grande (LLM). Las justificaciones se usan para entrenar modelos más pequeños de tareas específicas.
Cuota
Cada proyecto de Google Cloud requiere una cuota suficiente para ejecutar un trabajo de ajuste, y un trabajo de ajuste usa 8 GPU. Si tu proyecto no tiene suficiente cuota para un trabajo de ajuste o si deseas ejecutar varios trabajos de ajuste simultáneos en el proyecto, debes solicitar una cuota adicional.
En la siguiente tabla, se muestra el tipo y la cantidad de cuota que se solicitará según la región en la que especificaste el ajuste:
| Región | Cuota de recursos | Cantidad por trabajo simultáneo |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
Precios
Cuando ajustas o sintetizas un modelo de base, pagas el costo para ejecutar la canalización de ajuste o síntesis. Cuando implementas un modelo de base ajustado o sintetizado en un extremo de Vertex AI, no se te cobra por el hosting. En el caso de la entrega de predicciones, pagas el mismo precio que pagas cuando entregas predicciones con un modelo de base no ajustado (para el ajuste) o el modelo de estudiante (para la síntesis). Para saber qué modelos de base se pueden ajustar y sintetizar, consulta Modelos de base. Para obtener detalles sobre los precios, consulta Precios para la IA generativa en Vertex AI.
¿Qué sigue?
- Obtén información para ajustar un modelo de base con el ajuste supervisado.
- Obtén información sobre cómo ajustar un modelo de base con el ajuste RLHF.
- Obtén información sobre cómo ajustar un modelo de base.
- Obtén información para sintetizar un modelo de texto.