構成可能な安全フィルタ
安全性属性の信頼性スコアと重大度スコア
Vertex AI PaLM API で処理されたコンテンツは、「有害なカテゴリ」や機密情報とみなされるトピックなど、安全性属性のリストと照らし合わせて評価されます。
各安全性属性には、入力またはレスポンスが特定のカテゴリに属する可能性を示す信頼スコア(0.0~1.0、小数点第 2 位を四捨五入)が関連付けられています。
これらの安全性属性(ハラスメント、ヘイトスピーチ、危険なコンテンツ、露骨な性的表現)の 4 つには、安全評価(重大度)と、小数点以下 1 桁に四捨五入された重大度スコア(0.0~1.0)が割り当てられます。これらの評価とスコアは、特定のカテゴリに属するコンテンツの予測される重大度を反映しています。
レスポンスの例
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
注: スコアが 0.0 に丸められたカテゴリは、レスポンスで省略されます。このレスポンスの例は、例示のみを目的としたものです。
ブロックした場合のレスポンスの例
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
安全性属性の説明
| 安全性属性 | 説明 |
|---|---|
| 中傷 | ID や保護されている属性をターゲットとする否定的なコメントや有害なコメント。 |
| 有害 | 粗暴、無礼、または冒とく的なコンテンツ。 |
| 性的 | 性行為やわいせつな内容に関する情報が含まれるコンテンツ。 |
| 暴力的なコンテンツ | 個人やグループに対する暴力を描写したシナリオ、または残虐行為の一般的な説明についての記述。 |
| 侮辱 | 個人またはグループに対する不快、挑発的、または否定的なコメント。 |
| 冒とく | 呪いなどの非常識または乱暴な言葉。 |
| 死、害、悲劇 | 人の死、悲劇、事故、災害、自傷行為。 |
| 銃、武器 | ナイフ、銃、個人用武器、および弾薬、ホルスターなどのアクセサリーについて言及するコンテンツ。 |
| 公共の安全 | 安心感を与え、公共の安全を維持するサービスや組織。 |
| 健康 | 人間の健康(健康状態、病気、障害を含む)、医学的治療、投薬、ワクチン接種、医療慣行、回復のためのリソース(サポート グループを含む)。 |
| 宗教、信仰 | 超自然的な法則や存在の可能性を扱う信条システム。宗教、信条、信仰、精神修行、教会、宗教施設。占星術や神秘学を含む。 |
| 違法ドラッグ | 危険ドラッグと違法な薬物。麻薬道具、麻薬栽培、麻薬吸引関係の道具などを扱っている店など。一般的に娯楽として使用される薬物(例: マリファナ)の薬事使用を含む。 |
| 戦争、紛争 | 戦争、軍事衝突、多数の人が関与する大規模な物理的衝突。戦争や紛争と直接関係ない場合でも、軍務に関する議論を含む。 |
| 財務 | 消費者および企業向け金融サービス(銀行、ローン、クレジット、投資、保険など)。 |
| 政治 | 政治関連のニュースとメディア。地域や国の公共政策に関する議論。 |
| 法務 | 法律に関連するコンテンツ(法律事務所、法的情報、主要な法的資料、パラリーガル サービス、法律関連出版物とテクノロジー、鑑定人、訴訟コンサルタント、その他の法的サービス プロバイダなど) |
安全評価を含む安全性属性
| 安全性属性 | 定義 | レベル |
|---|---|---|
| ヘイトスピーチ | ID や保護されている属性をターゲットとする否定的なコメントや有害なコメント。 | 高、中、低、最小 |
| 嫌がらせ | 他人をターゲットにした悪口、威圧表現、いじめ、虐待的な内容を含むコメント | 高、中、低、最小 |
| 露骨な性表現 | 性行為やわいせつな内容に関する情報が含まれるコンテンツ。 | 高、中、低、最小 |
| 危険なコンテンツ | 有害な商品、サービス、アクティビティへのアクセスを促進または可能にするコンテンツ。 | 高、中、低、最小 |
安全性のしきい値
以下の安全性属性に対して安全性しきい値が定められています。
- ヘイトスピーチ
- 嫌がらせ
- 露骨な性表現
- 危険なコンテンツ
Google は、これらの安全性属性に対して指定された重大度スコアを超えるモデルのレスポンスをブロックします。安全性のしきい値を変更可能にすることをリクエストするには、 Google Cloud アカウント チームにお問い合わせください。
信頼性と重大度のしきい値のテスト
Google の安全性フィルタをテストし、ビジネスに適した信頼度のしきい値を定義できます。これらのしきい値を使用することで、Google の利用ポリシーや利用規約に違反するコンテンツを検出し、適切な措置を取ることができます。
信頼スコアは予測にすぎないため、信頼性や精度については信頼スコアを過信しないでください。Google は、これらのスコアの解釈または使用をビジネス上の意思決定に使用することに対して責任を負いません。
重要: 確率と重大度
安全評価付きの 4 つの安全性属性を除き、PaLM API 安全フィルタの信頼スコアは、コンテンツが重大度ではなく安全でない確率に基づいています。コンテンツによっては、危害の重大度が高くても、安全でない確率が低くなるものもあるため、この点を考慮することが重要です。たとえば、次の文を比較します。
- ロボットが私をパンチした。
- ロボットが私を切り付けた。
安全でない確率は最初の文章の方が高くなりますが、2 つめの文章は暴力の観点で重大度が高いとみなすことができます。
したがって、エンドユーザーへの悪影響を最小限に抑えながら主要なユースケースをサポートするために必要となる、適切なレベルのブロックを慎重にテストし、検討することが重要です。
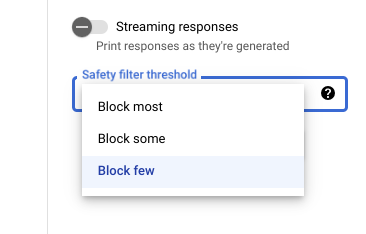
Vertex AI Studio の安全性設定
調整可能な安全フィルタのしきい値を使用すると、有害な可能性があるレスポンスが表示される可能性を調整できます。モデルのレスポンスは、ハラスメント、ヘイトスピーチ、危険なコンテンツ、性的描写が露骨なコンテンツが含まれている可能性に基づいてブロックされます。安全フィルタの設定は、Vertex AI Studio のプロンプト フィールドの右側にあります。block most、block some、block few の 3 つのオプションから選択できます。
引用フィルタ
Google の生成コード機能は、オリジナルのコンテンツを生成することを目的としており、既存のコンテンツを詳細に複製することは目的にしていません。Google のシステムは、このような問題が発生する可能性を抑えるように設計されており、今後もこれらのシステムの動作は改善されます。あるウェブページのさまざまな部分をこれらの機能が直接参照している場合、そのページを引用していることになります。
同じコンテンツが複数のウェブページで見つかった場合、Google は一般的なソースを指し示すことがあります。コード リポジトリを引用する場合は、該当するオープンソース ライセンスへの参照も追加されることがあります。ライセンス要件は、ご自身の責任で遵守していただく必要があります。
引用フィルタのメタデータについては、Citation API リファレンスをご覧ください。
安全性エラー
安全性エラーコードは、プロンプトまたはレスポンスがブロックされた理由を表す 3 桁のコードです。最初の数字は、コードがプロンプトまたはレスポンスのどちらに適用されるかを示す接頭辞で、残りの数字はプロンプトまたはレスポンスがブロックされた理由を表します。たとえば、エラーコード 251 は、モデルからのレスポンスに含まれるヘイトスピーチ コンテンツの問題によりレスポンスがブロックされたことを示します。
1 件のレスポンスで複数のエラーコードが返される場合があります。
モデル内のレスポンスのコンテンツをブロックするエラーが発生した場合(接頭辞 = 2、例: 250)、リクエストの temperature 設定を調整します。これにより、ブロックされる確率を減らした別のレスポンス セットを生成できます。
エラーコードの接頭辞
エラーコードの接頭辞は、エラーコードの最初の数字です。
| 1 | エラーコードは、モデルに送信されるプロンプトに適用されます。 |
| 2 | エラーコードは、モデルからのレスポンスに適用されます。 |
エラーコードの理由
エラーコードの理由は、エラーコードの 2 桁目と 3 桁目に示されます。
エラーコード 3 または 4 で始まるエラーコードは、安全性属性違反の信頼しきい値が満たされたため、プロンプトまたはレスポンスがブロックされたことを示します。
5 で始まるエラーコードの理由は、安全でないコンテンツが見つかったプロンプトまたはレスポンスを示します。
| 10 | 品質の問題または引用メタデータに影響するパラメータの設定が原因で、レスポンスがブロックされました。これは、モデルからのレスポンスにのみ適用されます。つまり、 引用チェッカーは、品質問題、またはパラメータ設定に起因する問題を特定します。 詳細については、引用フィルタをご覧ください。 |
| 20 | 指定した言語または返された言語がサポートされていません。サポートされる言語の一覧については、言語サポートをご覧ください。 |
| 30 | 有害なコンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。キーワードが用語のブロックリストに含まれています。プロンプトを言い換えてください。 |
| 31 | コンテンツに個人を特定できる機密情報(SPII)が含まれている可能性があります。プロンプトを言い換えてください。 |
| 40 | 有害なコンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。コンテンツがセーフサーチ設定に違反しています。プロンプトを言い換えてください。 |
| 50 | 性的描写が露骨なコンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。プロンプトを言い換えてください。 |
| 51 | ヘイトスピーチ コンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。プロンプトを言い換えてください。 |
| 52 | ハラスメント コンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。プロンプトを言い換えてください。 |
| 53 | 危険なコンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。プロンプトを言い換えてください。 |
| 54 | 有害なコンテンツが含まれている可能性があるため、プロンプトまたはレスポンスがブロックされました。プロンプトを言い換えてください。 |
| 00 | 理由は不明です。プロンプトを言い換えてください。 |