モデルをトレーニングした後、AutoML Translation はテストセットの項目を使用して、新しいモデルの品質と精度を評価します。AutoML Translation は、BLEU(Bilingual Evaluation Understudy)スコアを使用してモデルの品質を表現します。このスコアは候補テキストと参照テキストの類似度を示し、値が 1 に近いほどテキストの類似度が高いことを表します。
BLEU スコアによりモデルの品質の全体的な評価が可能です。また、モデル予測を使用してテストセットをエクスポートすることで、特定のデータ項目のモデル出力も評価できます。エクスポートされたデータには、元のデータセットの参照テキストとモデルの候補テキストの両方が含まれます。
このデータを使用して、モデルの準備状況を評価します。品質水準に不満がある場合は、さらに多様な文のペアを使用してトレーニングすることを検討してください。1 つの選択肢として、文のペアをさらに増やす方法があります。タイトルバーの [Add Files] リンクを使用します。ファイルを追加し、[トレーニング] ページの [新しいモデルをトレーニング] ボタンをクリックして新しいモデルをトレーニングします。十分に高い品質水準に達するまで、このプロセスを繰り返します。
モデル評価の取得
ウェブ UI
AutoML Translation コンソールを開き、左側のナビゲーション バーの [モデル] の横にある電球アイコンをクリックします。使用可能なモデルが表示されます。各モデルには、(モデルのトレーニング元になった)データセット、ソース言語、ターゲット言語、(モデルのトレーニングに使用された)ベースモデルの情報が含まれています。
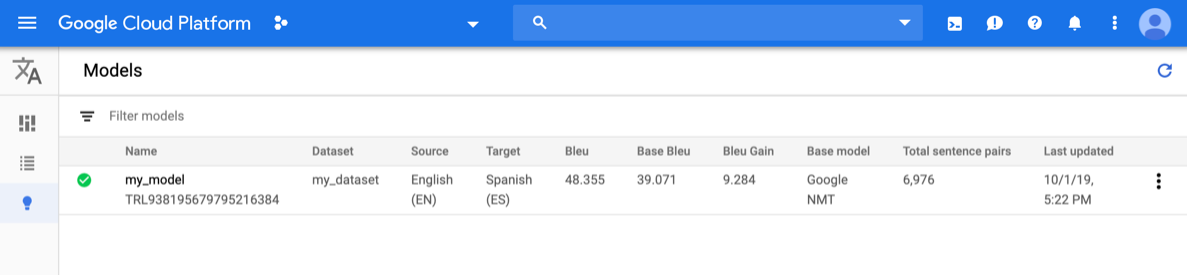
別のプロジェクトのモデルを表示するには、タイトルバーの右上にあるプルダウン リストからプロジェクトを選択します。
評価するモデルの行をクリックします。
[予測] タブが開きます。
ここで、モデルをテストし、カスタムモデルとトレーニングに使用した基本モデルの両方の結果を確認できます。
タイトルバーのすぐ下にある [トレーニング] タブをクリックします。
モデルのトレーニングが完了すると、AutoML Translation によって評価指標が表示されます。
![モデル評価を示す my_dataset の [トレーニング] タブ](https://cloud.google.com/static/translate/automl/docs/images/evaluate.png?authuser=7&hl=ja)
REST
リクエストのデータを使用する前に、次のように置き換えます。
- model-name: モデルの完全な名前。モデルの完全な名前には、プロジェクト名とロケーションが含まれています。モデル名は次の例のようになります。
projects/project-id/locations/us-central1/models/model-id - project-id: Google Cloud Platform プロジェクト ID
HTTP メソッドと URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
リクエストを送信するには、次のいずれかのオプションを開きます。
次のような JSON レスポンスが返されます。
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
AutoML Translation 用のクライアント ライブラリをインストールして使用する方法については、AutoML Translation クライアント ライブラリをご覧ください。詳細については、AutoML Translation Go API のリファレンス ドキュメントをご覧ください。
AutoML Translation で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
AutoML Translation 用のクライアント ライブラリをインストールして使用する方法については、AutoML Translation クライアント ライブラリをご覧ください。詳細については、AutoML Translation Java API のリファレンス ドキュメントをご覧ください。
AutoML Translation で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
AutoML Translation 用のクライアント ライブラリをインストールして使用する方法については、AutoML Translation クライアント ライブラリをご覧ください。詳細については、AutoML Translation Node.js API のリファレンス ドキュメントをご覧ください。
AutoML Translation で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Python
AutoML Translation 用のクライアント ライブラリをインストールして使用する方法については、AutoML Translation クライアント ライブラリをご覧ください。詳細については、AutoML Translation Python API のリファレンス ドキュメントをご覧ください。
AutoML Translation で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Translation リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Translation リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Translation リファレンス ドキュメントをご覧ください。
モデル予測によるテストデータのエクスポート
モデルをトレーニングした後、AutoML Translation はテストセットの項目を使用して、新しいモデルの品質と精度を評価します。AutoML Translation コンソールからテストセットをエクスポートすると、モデル出力と元のデータセットの参照テキストとの比較を確認できます。AutoML Translation では、TSV ファイルを Google Cloud Storage バケットに保存します。各行の形式は次のとおりです。
Source sentence タブ Reference translation タブ Model candidate translation
ウェブ UI
AutoML Translation コンソールを開き、左側のナビゲーション バーにある [モデル] の左側にある電球アイコンをクリックし、使用可能なモデルを表示します。
別のプロジェクトのモデルを表示するには、タイトルバーの右上にあるプルダウン リストからプロジェクトを選択します。
モデルを選択します。
タイトルバーの [データのエクスポート] ボタンをクリックします。
エクスポートした .tsv ファイルを保存する Google Cloud Storage バケットへのフルパスを入力します。
現在のプロジェクトに関連付けられたバケットを使用する必要があります。
TEST データをエクスポートするモデルを選択します。
[Testing set with model predictions] プルダウン リストには、同じ入力データセットを使用してトレーニングされたモデルが一覧表示されます。
[エクスポート] をクリックします。
AutoML Translation は、指定した Google Cloud Storage バケットに model-name
_evaluated.tsvという名前のファイルを書き込みます。
新しいテストセットを使用したモデルの評価と比較
AutoML Translation コンソールから、新しいテストデータを使用して既存のモデルを再評価できます。1 回で最大 5 つの異なるモデルを評価して、それらを比較できます。
テストデータをタブ区切り形式(.tsv)ファイルまたは Translation Memory eXchange(.tmx)ファイルとして Cloud Storage にアップロードします。
AutoML Translation では、テストセットに対してモデルを評価し、評価スコアを生成します。必要に応じて、各モデルの結果を .tsv ファイルとして Cloud Storage バケットに保存できます。各行の形式は次のとおりです。
Source sentence tab Model candidate translation tab Reference translation
ウェブ UI
AutoML Translation コンソールを開き、左側のナビゲーション パネルで [モデル] をクリックして、使用可能なモデルを表示します。
別のプロジェクトのモデルを表示するには、タイトルバーの右上にあるプルダウン リストからプロジェクトを選択します。
評価するモデルのいずれかを選択します。
タイトルバーのすぐ下にある [評価] タブをクリックします。
![my_dataset データセットの [評価] タブ](https://cloud.google.com/static/translate/automl/docs/images/evaluate_model.png?authuser=7&hl=ja)
[評価] タブで、[新しい評価] をクリックします。
![my_model モデルの [新しい評価] タブ](https://cloud.google.com/static/translate/automl/docs/images/new_evaluation.png?authuser=7&hl=ja)
- 評価、比較するモデルを選択します。現在のモデルを選択する必要があります。デフォルトでは Google NMT が選択されていますが、これは選択を解除できます。
- 他の評価と区別しやすいようにテストセット名を指定して、Cloud Storage から新しいテストセットを選択します。
- テストセットに基づく予測をエクスポートする場合は、結果を保存する Cloud Storage バケットを指定します(文字数あたりの標準料金が適用されます)。
[完了] をクリックします。
評価が完了すると、AutoML Translation はコンソールにテーブル形式で評価スコアを表示します。評価は一度に 1 つしか実行できません。予測結果を格納するバケットを指定した場合、AutoML Translation は model-name_test-set-name
.tsvという名前のファイルをバケットに書き込みます。
BLEU スコアの解釈
BLEU(BiLingual Evaluation Understudy)は、機械翻訳されたテキストを自動的に評価するための指標です。BLEU スコアは、機械翻訳されたテキストと高品質な参照訳の類似度を測定する 0 から 1 までの数値です。値が 0 の場合、機械翻訳の出力に参照訳と一致する部分がない(品質が低い)ことを意味します。値が 1 の場合は、参照訳と完全に一致している(品質が高い)ことを意味します。
BLEU スコアは、人が翻訳品質に関して下す判断とよく相関することがわかっています。人が翻訳しても、1.0 という完全なスコアには達しません。
AutoML では、BLEU スコアを 0 から 1 の小数ではなく割合で表します。
解釈
異なるコーパス間や言語間で BLEU スコアを比較することは推奨されません。同じコーパスについて BLEU スコアを比較しても、参照訳の数が異なっていれば、紛らわしくなる可能性があります。
ただし、大まかなガイドラインとして、次に示す BLEU スコアの解釈が参考になります(BLEU スコアは、小数ではなく割合として表しています)。
| BLEU スコア | 解釈 |
|---|---|
| < 10 | ほとんど役に立たない |
| 10~19 | 主旨を理解するのが困難である |
| 20~29 | 主旨は明白であるが、文法上の重大なエラーがある |
| 30~40 | 理解できる、適度な品質の翻訳 |
| 40~50 | 高品質な翻訳 |
| 50~60 | 非常に高品質で、適切かつ流暢な翻訳 |
| > 60 | 人が翻訳した場合よりも高品質であることが多い |
次のカラー グラデーションは、BLEU スコアの解釈の一般的な尺度として使用できます。

数学的な詳細
数学的には、BLEU スコアは次のように定義されます。
以下を使用
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
ここで
- \(m_{cand}^i\hphantom{xi}\) は、参照訳と一致する候補訳内の i グラムのカウントです。
- \(m_{ref}^i\hphantom{xxx}\) は、参照訳内の i グラムのカウントです。
- \(w_t^i\hphantom{m_{max}}\) は、候補訳内の i グラムの総数です。
数式は、Brevity Penalty(短さのペナルティ)と n グラム適合率の 2 つの部分で構成されます。
Brevity Penalty
Brevity Penalty は、最も近い参照訳の長さと比較して、生成された翻訳が短すぎる場合に指数関数的減衰を使用してペナルティを課します。Brevity Penalty は、BLEU スコアに再現率の項がないという事実を補正します。n グラム適合率
n グラム適合率は、1 グラム、2 グラム、3 グラム、4 グラム(i=1,...,4)が参照訳内の対応する n グラムと一致する数をカウントします。この項は、精度の指標として機能します。ユニグラムは適切さを評価し、それよりも長い n グラムは翻訳の流暢さを評価します。オーバーカウントを回避するために、n グラムのカウントは、参照訳に出現する n グラムの最大カウント(\(m_{ref}^n\))に切り詰められます。
例
計算中 \(precision_1\)
次のような参照文と候補訳について考えてみましょう。
参照文: the cat is on the mat
候補訳: the the the cat mat
最初のステップでは、参照文と候補訳における各 1 グラムの出現回数をカウントします。BLEU 指標では大文字と小文字が区別されます。
| ユニグラム | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
候補(\(w_t^1\))内の 1 グラムの総数は 5 であるため、 \(precision_1\) = (2 + 1 + 1) ÷ 5 = 0.8 となります。
BLEU スコアの計算
参照文:
The NASA Opportunity rover is battling a massive dust storm on Mars .
候補訳 1:
The Opportunity rover is combating a big sandstorm on Mars .
候補訳 2:
A NASA rover is fighting a massive storm on Mars .
上記の例は、1 つの参照文と 2 つの候補訳で構成されています。これらの文は、前に示したように BLEU スコアを計算する前にトークン化されます。たとえば、最後のピリオドは別個のトークンとしてカウントされます。
各翻訳の BLEU スコアを計算するために、次の統計を計算します。
- n グラム適合率
次の表に、両方の候補訳に対する n グラム適合率を示します。 - Brevity-Penalty
候補訳 1 も候補訳 2 も 11 個のトークンで構成されているので、Brevity Penalty は両方の文で同じです。 - BLEU スコア
BLEU スコアが 0 より大きくなるには、一致する 4 グラムが少なくとも 1 つ必要です。候補訳 1 には一致する 4 グラムがないので、BLEU スコアは 0 です。
| 指標 | 候補訳 1 | 候補訳 2 |
|---|---|---|
| \(precision_1\) (1 グラム) | 8/11 | 9/11 |
| \(precision_2\) (2 グラム) | 4/10 | 5/10 |
| \(precision_3\) (3 グラム) | 2/9 | 2/9 |
| \(precision_4\) (4 グラム) | 0/8 | 1/8 |
| Brevity Penalty | 0.83 | 0.83 |
| BLEU スコア | 0.0 | 0.27 |
特性
BLEU はコーパスベースの指標である
BLEU 指標を個々の文の評価に使用した場合は、うまく機能しません。たとえば、例の 2 つの文はほとんどの意味をとらえていますが、どちらの BLEU スコアも低くなっています。個々の文の n グラム統計はあまり意味がないので、BLEU はコーパスベースの指標として設計されています。つまり、スコアを計算する際には、コーパス全体で統計が収集されます。上記で定義した BLEU 指標は個々の文に対して因数分解できません。内容語と機能語の区別がない
BLEU 指標では、内容語と機能語が区別されません。つまり、「a」のような機能語が抜けている語句の場合、「NASA」という名前が誤って「ESA」に置換された場合と同じペナルティが課せられます。文の意味や文法の正しさまでは十分に評価できない
「not」のような単語が 1 つ抜けると、文の意味が正反対になる場合があります。また、n が 4 以下の n グラムのみを考慮すると、長い範囲の依存性が無視されるため、BLEU は、文法に合わない文に小さいペナルティしか課さないことがよくあります。正規化とトークン化
BLEU スコアを計算する前に、参照訳と候補訳の両方が正規化され、トークン化されます。正規化とトークン化の手順の選択は、最終的な BLEU スコアに大きな影響を与えます。