Introduzione al convertitore di inferenza Cloud TPU v5e
Introduzione
Il convertitore di inferenza Cloud TPU prepara e ottimizza un modello TensorFlow 2 (TF2) per l'inferenza TPU. Il convertitore viene eseguito in una shell VM locale o TPU. La shell della VM TPU è consigliata perché include gli strumenti a riga di comando necessari per il convertitore. Prende un SavedModel esportato e esegue i seguenti passaggi:
- Conversione TPU: aggiunge
TPUPartitionedCalle altre operazioni TPU al modello per renderlo utilizzabile sulla TPU. Per impostazione predefinita, un modello esportato per l'inferenza non ha queste operazioni e non può essere pubblicato sulla TPU, anche se è stato addestrato sulla TPU. - Raggruppamento: aggiunge operazioni di raggruppamento al modello per abilitare il raggruppamento in-graph per un throughput migliore.
- Conversione BFloat16: consente di convertire il formato dei dati del modello da
float32abfloat16per migliorare le prestazioni di calcolo e ridurre l'utilizzo della memoria ad alta larghezza di banda (HBM) sulla TPU. - Ottimizzazione della forma IO: ottimizza le forme dei tensori per i dati trasferiti tra la CPU e la TPU per migliorare l'utilizzo della larghezza di banda.
Quando esportano un modello, gli utenti creano alias di funzione per tutte le funzioni che vogliono eseguire sulla TPU. Trasmettono queste funzioni al Convertitore, che le posiziona sulla TPU e le ottimizza.
Cloud TPU Inference Converter è disponibile come immagine Docker che può essere eseguita in qualsiasi ambiente in cui è installato Docker.
Tempo stimato per completare i passaggi mostrati sopra: circa 20-30 minuti
Prerequisiti
- Il modello deve essere un modello TF2 ed esportato nel formato SavedModel.
- Il modello deve avere un alias funzione per la funzione TPU. Per sapere come fare, consulta l'esempio di codice. Gli esempi riportati di seguito utilizzano
tpu_funccome alias della funzione TPU. - Assicurati che la CPU della tua macchina supporti le istruzioni AVX (Advanced Vector eXtensions), poiché la libreria Tensorflow (la dipendenza di Cloud TPU Inference Converter) viene compilata per utilizzare le istruzioni AVX.
La maggior parte delle CPU
supporta AVX.
- Puoi eseguire
lscpu | grep avxper verificare se l'insieme di istruzioni AVX è supportato.
- Puoi eseguire
Prima di iniziare
Prima di iniziare la configurazione, segui questi passaggi:
Crea un nuovo progetto: nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Cloud.
Configura una VM TPU: crea una nuova VM TPU utilizzando la console Google Cloud o
gcloudoppure utilizza una VM TPU esistente per eseguire l'inferenza con il modello convertito sulla VM TPU.- Assicurati che l'immagine della VM TPU sia basata su TensorFlow. Ad esempio,
--version=tpu-vm-tf-2.11.0. - Il modello convertito verrà caricato e pubblicato su questa VM TPU.
- Assicurati che l'immagine della VM TPU sia basata su TensorFlow. Ad esempio,
Assicurati di disporre degli strumenti a riga di comando necessari per utilizzare Cloud TPU Inference Converter. Puoi installare Google Cloud SDK e Docker in locale o utilizzare una VM TPU su cui questo software è installato per impostazione predefinita. Utilizza questi strumenti per interagire con l'immagine del convertitore.
Connettiti all'istanza con SSH utilizzando il seguente comando:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Configurazione dell'ambiente
Configura l'ambiente dalla shell della VM TPU o dalla shell locale.
Shell VM TPU
Nella shell della VM TPU, esegui i seguenti comandi per consentire l'utilizzo di Docker non come utente root:
sudo usermod -a -G docker ${USER} newgrp docker
Inizializza gli aiuti per le credenziali Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Shell locale
Nella shell locale, configura l'ambiente seguendo questa procedura:
Installa Cloud SDK, che include lo strumento a riga di comando
gcloud.Installa Docker:
Consenti l'utilizzo di Docker non come utente root:
sudo usermod -a -G docker ${USER} newgrp docker
Accedi al tuo ambiente:
gcloud auth login
Inizializza gli aiuti per le credenziali Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Estrai l'immagine Docker di Inference Converter:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Immagine del convertitore
L'immagine è destinata a conversioni una tantum del modello. Imposta i percorsi dei modelli e modifica le opzioni del convertitore in base alle tue esigenze. La sezione Esempi di utilizzo fornisce diversi casi d'uso comuni.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inferenza con il modello convertito nella VM TPU
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Esempi di utilizzo
Aggiungi un alias di funzione per la funzione TPU
- Trova o crea una funzione nel modello che racchiude tutto ciò che vuoi eseguire sulla TPU. Se
@tf.functionnon esiste, aggiungilo. - Quando salvi il modello, fornisci SaveOptions come indicato di seguito per assegnare
model.tpu_funcun aliasfunc_on_tpu. - Puoi passare questo alias di funzione al convertitore.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Convertire un modello con più funzioni TPU
Puoi inserire più funzioni sulla TPU. Basta creare più alias di funzione e passarli in converter_options_string al convertitore.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Quantizzazione
La quantizzazione è una tecnica che riduce la precisione dei numeri utilizzati per rappresentare i parametri di un modello. Ciò si traduce in dimensioni del modello inferiori e in un calcolo più rapido. Un modello quantizzato offre guadagni in termini di throughput di inferenza, nonché un utilizzo della memoria e dimensioni di archiviazione inferiori, a fronte di piccoli cali di precisione.
La nuova funzionalità di quantizzazione post-addestramento in TensorFlow che ha come target la TPU è stata sviluppata a partire dalla funzionalità esistente simile in TensorFlow Lite che viene utilizzata per scegliere come target i dispositivi mobili e edge. Per scoprire di più sulla quantizzazione in generale, puoi consultare la documentazione di TensorFlow Lite.
Concetti di quantizzazione
Questa sezione definisce i concetti specifici relativi alla quantizzazione con il convertitore di inferenza.
I concetti relativi ad altre configurazioni TPU (ad esempio, slice, host, chip e TensorCore) sono descritti nella pagina Architettura del sistema TPU.
Quantizzazione post-addestramento (PTQ): la quantizzazione post-addestramento è una tecnica che riduce le dimensioni e la complessità computazionale di un modello di rete neurale senza influire in modo significativo sulla sua accuratezza. PTQ funziona convertendo i pesi e le attivazioni in virgola mobile di un modello addestrato in numeri interi di precisione inferiore, come numeri interi a 8 o 16 bit. Ciò può causare una significativa riduzione delle dimensioni del modello e della latenza di inferenza, con solo una piccola perdita di accuratezza.
Taratura: il passaggio di calibrazione per la quantizzazione è il processo di raccolta delle statistiche sull'intervallo di valori assunti dai pesi e dalle attivazioni di un modello di rete neurale. Queste informazioni vengono utilizzate per determinare i parametri di quantizzazione del modello, ovvero i valori che verranno utilizzati per convertire le attivazioni e i pesi in virgola mobile in interi.
Set di dati rappresentativo: un set di dati rappresentativo per la quantizzazione è un piccolo set di dati che rappresenta i dati di input effettivi per il modello. Viene utilizzato durante il passaggio di calibrazione della quantizzazione per raccogliere statistiche sull'intervallo di valori che assumeranno i pesi e le attivazioni del modello. Il set di dati rappresentativo deve soddisfare le seguenti proprietà:
- Deve rappresentare correttamente gli input effettivi del modello durante la deduzione. Ciò significa che deve coprire l'intervallo di valori che il modello è probabile che riscontri nel mondo reale.
- Dovrebbe scorrere collettivamente in ogni ramo delle condizioni
(ad esempio
tf.cond), se presenti. Questo è importante perché la procedura di quantizzazione deve essere in grado di gestire tutti i possibili input al modello, anche se non sono rappresentati esplicitamente nel set di dati rappresentativo. - Deve essere sufficientemente grande da raccogliere statistiche sufficienti e ridurre gli errori. Come regola generale, ti consigliamo di utilizzare più di 200 campioni rappresentativi.
Il set di dati rappresentativo può essere un sottoinsieme del set di dati di addestramento o un set di dati separato progettato specificamente per essere rappresentativo degli input reali del modello. La scelta del set di dati da utilizzare dipende dall'applicazione specifica.
Quantizzazione dell'intervallo statico (SRQ): la quantizzazione dell'intervallo statico determina una volta sola l'intervallo di valori per le ponderazioni e le attivazioni di un modello di rete neurale, durante il passaggio di calibrazione. Ciò significa che viene utilizzato lo stesso intervallo di valori per tutti gli input del modello. Questo può essere meno preciso della quantizzazione dinamica, in particolare per i modelli con un'ampia gamma di valori di input. Tuttavia, la quantizzazione dell'intervallo statico richiede meno calcoli in fase di esecuzione rispetto alla quantizzazione dell'intervallo dinamico.
Quantizzazione dinamica dell'intervallo (DRQ): la DRQ determina l'intervallo di valori per i pesi e le attivazioni di un modello di rete neurale per ogni input. In questo modo, il modello può adattarsi all'intervallo di valori dei dati di input, il che può migliorare l'accuratezza. Tuttavia, la quantizzazione dinamica richiede più calcoli in fase di esecuzione rispetto alla quantizzazione statica.
Funzionalità Quantizzazione dell'intervallo statico Quantizzazione dinamica dell'intervallo Intervallo di valori Determinato una volta durante la calibrazione Determinato per ogni input Accuratezza Può essere meno preciso, soprattutto per i modelli con un'ampia gamma di valori di input Può essere più preciso, in particolare per i modelli con una vasta gamma di valori di input complessità Più semplice Più complesse Calcolo in fase di esecuzione Meno calcoli Maggiore calcolo Quantizzazione solo dei pesi: la quantizzazione solo dei pesi è un tipo di quantizzazione che esegue la quantizzazione solo dei pesi di un modello di rete neurale, lasciando le attivazioni in virgola mobile. Questa può essere una buona opzione per i modelli sensibili all'accuratezza, in quanto può contribuire a preservare l'accuratezza del modello.
Come utilizzare la quantizzazione
La quantizzazione può essere applicata configurando e impostando QuantizationOptions nelle opzioni del convertitore. Le opzioni più importanti sono:
- tags: raccolta di tag che identificano i
MetaGraphDefall'interno delSavedModelda quantizzare. Non è necessario specificare se hai un soloMetaGraphDef. - signature_keys: sequenza di chiavi che identificano
SignatureDefcontenente input e output. Se non specificato, viene utilizzato ["serving_default"]. - quantization_method: il metodo di quantizzazione da applicare. Se non specificato, verrà applicata la quantizzazione
STATIC_RANGE. - op_set: deve essere mantenuto come XLA. Al momento è l'opzione predefinita, non è necessario specificarla.
- representative_datasets: specifica il set di dati utilizzato per la calibrazione dei parametri di quantizzazione.
Creazione del set di dati rappresentativo
Un insieme di dati rappresentativo è essenzialmente un insieme di campioni.
Dove un campione è una mappa di: {input_key: input_value}. Ad esempio:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
I set di dati rappresentativi devono essere salvati come file TFRecord
utilizzando la classe TfRecordRepresentativeDatasetSaver
attualmente disponibile nel pacchetto pip tf-nightly. Ad esempio:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Esempi
L'esempio seguente esegue la quantizzazione del modello con la chiave di firma
serving_default e l'alias funzione tpu_func:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Aggiungi il raggruppamento
Il convertitore può essere utilizzato per aggiungere il raggruppamento a un modello. Per una descrizione delle opzioni di raggruppamento che possono essere ottimizzate, consulta Definizione delle opzioni di raggruppamento.
Per impostazione predefinita, il convertitore eseguirà il batch di tutte le funzioni TPU nel modello. Inoltre, può elaborare in batch le firme e le funzioni fornite dall'utente, il che può migliorare ulteriormente il rendimento. Qualsiasi funzione TPU, funzione fornita dall'utente o firma raggruppata deve soddisfare i rigorosi requisiti di forma dell'operazione di raggruppamento.
Il convertitore può anche aggiornare le opzioni di raggruppamento esistenti. Di seguito è riportato un esempio di come aggiungere il raggruppamento a un modello. Per ulteriori informazioni sul batching, consulta Approfondimento sul batching.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Disattivare le ottimizzazioni di bfloat16 e della forma IO
Le ottimizzazioni BFloat16 e della forma IO sono attive per impostazione predefinita. Se non funzionano bene con il tuo modello, possono essere disattivati.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Report sulle conversioni
Puoi trovare questo report sulle conversioni nel log dopo aver eseguito il Converter inferenziale. Di seguito è riportato un esempio.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
Questo report stima il costo computazionale del modello di output su CPU e TPU e suddivide ulteriormente il costo della TPU per ogni funzione, che dovrebbe riflettere la tua selezione delle funzioni TPU nelle opzioni del convertitore.
Se vuoi utilizzare meglio la TPU, ti consigliamo di fare esperimenti con la struttura del modello e di modificare le opzioni del convertitore.
Domande frequenti
Quali funzioni devo inserire nella TPU?
È meglio inserire il maggior numero possibile di operazioni del modello sulla TPU, perché la maggior parte delle operazioni viene eseguita più velocemente sulla TPU.
Se il modello non contiene operazioni, stringhe o tensori sparsi incompatibili con le TPU, in genere la strategia migliore è eseguire l'intero modello sulla TPU. Puoi farlo trovando o creando una funzione che ingloba l'intero modello, creando un alias di funzione e passandolo al convertitore.
Se il modello contiene parti che non possono funzionare sulla TPU (ad es. operazioni, stringhe o tensori sparsi non compatibili con la TPU), la scelta delle funzioni TPU dipende dalla posizione della parte incompatibile.
- Se si trova all'inizio o alla fine del modello, puoi eseguire il refactoring del modello per mantenerlo sulla CPU. Alcuni esempi sono le fasi di pre- e post-elaborazione delle stringhe. Per ulteriori informazioni sul trasferimento del codice alla CPU, consulta "Come faccio a spostare una parte del modello sulla CPU?" Mostra un modo tipico per eseguire il refactoring del modello.
- Se si trova al centro del modello, è meglio dividere il modello in tre parti e includere tutte le operazioni incompatibili con TPU nella parte centrale, in modo da eseguirle sulla CPU.
- Se si tratta di un tensore sparso, ti consigliamo di chiamare
tf.sparse.to_densesulla CPU e di passare il tensore denso risultante alla parte TPU del modello.
Un altro fattore da considerare è l'utilizzo dell'HBM. L'inserimento di tabelle può utilizzare molto HBM. Se superano la limitazione hardware della TPU, devono essere inseriti sulla CPU, insieme alle operazioni di ricerca.
Se possibile, deve esistere una sola funzione TPU sotto una firma. Se la struttura del modello richiede la chiamata di più funzioni TPU per ogni richiesta di inferenza in entrata, devi tenere presente la latenza aggiuntiva dell'invio di tensori tra CPU e TPU.
Un buon modo per valutare la selezione delle funzioni TPU è controllare il report sulle conversioni. Mostra la percentuale di calcolo eseguita sulla TPU e una suddivisione del costo di ogni funzione TPU.
Come faccio a spostare una parte del modello sulla CPU?
Se il modello contiene parti che non possono essere eseguite sulla TPU, devi eseguire il refactoring del modello per spostarle sulla CPU. Ecco un esempio di giocattolo. Il modello è un modello linguistico con una fase di pre-elaborazione. Per semplicità, il codice per le definizioni e le funzioni dei livelli è omesso.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Questo modello non può essere pubblicato direttamente sulla TPU per due motivi. Innanzitutto, il parametro è una stringa. In secondo luogo, la funzione preprocess può contenere molte operazioni sulle stringhe. Entrambi non sono compatibili con le TPU.
Per eseguire il refactoring di questo modello, puoi creare un'altra funzione denominata tpu_func per ospitare bert_layer ad alta intensità di calcolo. Quindi, crea un alias di funzione per tpu_func e passalo al convertitore. In questo modo, tutto ciò che si trova all'interno di tpu_func verrà eseguito sulla TPU e tutto ciò che rimane in model_func verrà eseguito sulla CPU.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
Cosa devo fare se il modello contiene operazioni, stringhe o tensori sparsi incompatibili con TPU?
La maggior parte delle operazioni TensorFlow standard è supportata su TPU, ma alcune, tra cui tensori e stringhe sparse, non sono supportate. Il convertitore non controlla la presenza di operazioni incompatibili con TPU. Pertanto, un modello contenente queste operazioni può passare la conversione. Tuttavia, quando viene eseguito per l'inferenza, si verificano errori come quelli riportati di seguito.
'tf.StringToNumber' op isn't compilable for TPU device.
Se il modello contiene operazioni incompatibili con TPU, queste devono essere posizionate al di fuori della funzione TPU. Inoltre, la stringa è un formato di dati non supportato sulla TPU. Pertanto, le variabili di tipo stringa non devono essere inserite nella funzione TPU. Inoltre, anche i parametri e i valori restituiti della funzione TPU non devono essere di tipo stringa. Analogamente, evita di inserire tensori sparsi nella funzione TPU, inclusi i suoi parametri e valori restituiti.
In genere non è difficile eseguire il refactoring della parte incompatibile del modello e trasferirla sulla CPU. Ecco un esempio.
Come supportare le operazioni personalizzate nel modello?
Se nel modello vengono utilizzate operazioni personalizzate, il Convertitore potrebbe non riconoscerle e non riuscire a convertire il modello. Questo accade perché la libreria dell'operatore personalizzato, che contiene la definizione completa dell'operatore, non è collegata al convertitore.
Poiché al momento il codice del convertitore non è ancora open source, non è possibile compilarlo con l'operatore personalizzato.
Cosa devo fare se ho un modello TensorFlow 1?
Il convertitore non supporta i modelli TensorFlow 1. È necessario eseguire la migrazione dei modelli TensorFlow 1 a TensorFlow 2.
Devo attivare il bridge MLIR quando eseguo il mio modello?
La maggior parte dei modelli convertiti può essere eseguita con il bridge MLIR TF2XLA più recente o con il bridge TF2XLA originale.
Come faccio a convertire un modello già esportato senza un alias di funzione?
Se un modello è stato esportato senza un alias di funzione, il modo più semplice è esportarlo di nuovo e creare un alias di funzione.
Se la reesportazione non è un'opzione, è comunque possibile convertire il modello fornendo un concrete_function_name. Tuttavia, identificare il valore corretto di concrete_function_name richiede un po' di lavoro investigativo.
Gli alias di funzione sono una mappatura da una stringa definita dall'utente a un nome di funzione concreto. Semplificano il riferimento a una funzione specifica nel modello. Il convertitore accetta sia gli alias di funzione sia i nomi di funzioni concrete non elaborati.
I nomi delle funzioni specifiche sono disponibili esaminando saved_model.pb.
L'esempio seguente mostra come inserire una funzione concreta chiamata
__inference_serve_24 sulla TPU.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
Come faccio a risolvere un errore di vincolo costante in fase di compilazione?
Sia per l'addestramento che per l'inferenza, XLA richiede che gli input di determinate operazioni abbiano una forma nota al momento della compilazione TPU. Ciò significa che quando XLA compila la parte del programma relativa alla TPU, gli input di queste operazioni devono avere una forma nota in modo statico.
Esistono due modi per risolvere il problema.
- L'opzione migliore è aggiornare gli input dell'operazione in modo che abbiano una forma nota in modo statico al momento della compilazione del programma TPU da parte di XLA. Questa compilazione avviene
appena prima dell'esecuzione della parte TPU del modello. Ciò significa che la forma deve essere nota in modo statico al momento dell'esecuzione di
TpuFunction. - Un'altra opzione è modificare
TpuFunctionin modo da non includere più l'operazione problematica.
Perché ricevo un errore relativo alla forma del batching?
Il raggruppamento ha requisiti rigorosi per la forma che consentono di raggruppare le richieste in arrivo in base alla dimensione 0 (ovvero la dimensione di raggruppamento). Questi requisiti relativi alla forma provengono dall'operazione di accumulo di TensorFlow e non possono essere allentati.
Il mancato rispetto di questi requisiti comporterà errori come:
- I tensori di input per il raggruppamento devono avere almeno una dimensione.
- Le dimensioni degli input devono corrispondere.
- I tensori di input per il raggruppamento forniti in una determinata chiamata all'operatore devono avere dimensioni uguali per la dimensione 0.
- La dimensione 0 del tensore di output raggruppato non corrisponde alla somma delle dimensioni 0 del tensore di input.
Per soddisfare questi requisiti, ti consigliamo di fornire un'altra funzione o firma al batch. Potrebbe anche essere necessario modificare le funzioni esistenti per soddisfare questi requisiti.
Se una funzione viene eseguita in batch, assicurati che tutte le forme della firma di input di @tf.function abbiano None nella dimensione 0. Se una firma viene raggruppata, assicurati che tutti i relativi input abbiano -1 nella dimensione 0.
Per una spiegazione completa del motivo per cui si verificano questi errori e su come risolverli, consulta Approfondimento sul batching.
Problemi noti
La funzione TPU non può chiamare indirettamente un'altra funzione TPU
Sebbene il convertitore possa gestire la maggior parte degli scenari di chiamata di funzioni oltre il confine tra CPU e TPU, esiste un caso limite raro in cui non riesce. Si verifica quando una funzione TPU chiama indirettamente un'altra funzione TPU.
Questo perché il convertitore modifica il chiamante diretto di una funzione TPU in modo che chiami la funzione TPU stessa anziché uno stub di chiamata TPU. Lo stub di chiamata contiene operazioni che possono funzionare solo sulla CPU. Quando una funzione TPU chiama qualsiasi funzione che alla fine chiama il chiamante diretto, queste operazioni della CPU potrebbero essere eseguite sulla TPU, generando errori del kernel mancanti. Tieni presente che questo caso è diverso da una funzione TPU che chiama direttamente un'altra funzione TPU. In questo caso, il convertitore non modifica nessuna funzione per chiamare lo stub di chiamata, quindi può funzionare.
In Converter abbiamo implementato il rilevamento di questo scenario. Se visualizzi il seguente errore, significa che il tuo modello ha raggiunto questo caso limite:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
La soluzione generale è eseguire il refactoring del modello per evitare questo scenario di chiamata di funzione. Se non riesci a farlo, contatta il team di assistenza Google per ulteriori informazioni.
Riferimento
Opzioni del convertitore in formato Protobuf
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Approfondimento sul batching
Il raggruppamento viene utilizzato per migliorare il throughput e l'utilizzo delle TPU. Consente di elaborare più richieste contemporaneamente. Durante l'addestramento, il batching può essere eseguito utilizzando tf.data. Durante l'inferenza, in genere viene eseguita aggiungendo un op nel grafico che raggruppa le richieste in arrivo. L'operazione attende di ricevere richieste sufficienti o il raggiungimento di un timeout prima di generare un batch di grandi dimensioni dalle singole richieste. Consulta la sezione Definizione delle opzioni di raggruppamento per ulteriori informazioni sulle diverse opzioni di raggruppamento che possono essere ottimizzate, inclusi i timeout e le dimensioni dei batch.
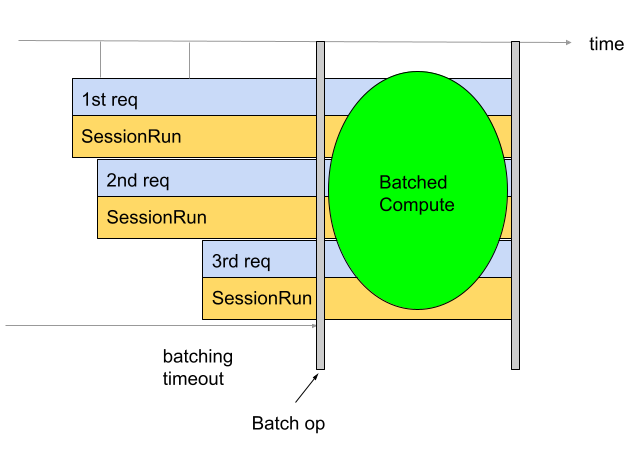
Per impostazione predefinita, il convertitore inserisce l'operazione di raggruppamento direttamente prima del calcolo TPU. Avvolge le funzioni TPU fornite dall'utente e qualsiasi calcolo TPU preesistente nel modello con operazioni di raggruppamento. È possibile ignorare questo comportamento predefinito indicando al convertitore quali funzioni e/o firme devono essere raggruppate.
L'esempio seguente mostra come aggiungere il raggruppamento predefinito.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Raggruppamento delle firme
Il raggruppamento delle firme raggruppa l'intero modello a partire dagli input della firma e fino alle uscite della firma. A differenza del comportamento predefinito del Converter, il raggruppamento delle firme raggruppa sia il calcolo della TPU sia il calcolo della CPU. Ciò consente di ottenere un aumento del rendimento del 10-20% durante l'inferenza su alcuni modelli.
Come per tutti i batch, il batching delle firme ha requisiti rigidi per le forme.
Per garantire il rispetto di questi requisiti relativi alla forma, gli input della firma devono avere forme con almeno due dimensioni. La prima dimensione è la dimensione del batch
e deve avere una dimensione pari a -1. Ad esempio, (-1, 4), (-1) o (-1,
128, 4, 10) sono tutte forme di input valide. Se non è possibile, valuta la possibilità di utilizzare il comportamento di raggruppamento predefinito o il raggruppamento delle funzioni.
Per utilizzare il raggruppamento delle firme, fornisci i nomi delle firme come signature_name(s)
utilizzando BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Raggruppamento di funzioni
Il raggruppamento delle funzioni può essere utilizzato per indicare al Convertitore quali funzioni devono essere raggruppate. Per impostazione predefinita, il convertitore eseguirà il batch di tutte le funzioni TPU. Il Grouping funzioni sostituisce questo comportamento predefinito.
Il raggruppamento delle funzioni può essere utilizzato per raggruppare i calcoli della CPU. Molti modelli registrano un miglioramento del rendimento quando il calcolo della CPU viene eseguito in batch. Il modo migliore per eseguire il calcolo della CPU in batch è utilizzare il raggruppamento delle firme, ma potrebbe non funzionare per alcuni modelli. In questi casi, il batching delle funzioni può essere utilizzato per eseguire il batch di parte del calcolo della CPU oltre a quello della TPU. Tieni presente che l'operazione di raggruppamento non può essere eseguita sulla TPU, pertanto qualsiasi funzione di raggruppamento fornita deve essere chiamata sulla CPU.
Il raggruppamento delle funzioni può essere utilizzato anche per soddisfare i rigorosi requisiti di forma imposti dall'operazione di raggruppamento. Nei casi in cui le funzioni TPU non soddisfino i requisiti di forma dell'operazione di raggruppamento, il raggruppamento delle funzioni può essere utilizzato per indicare al convertitore di raggruppare funzioni diverse.
Per utilizzarlo, genera un function_alias per la funzione da eseguire in batch. Per farlo, puoi trovare o creare nel modello una funzione che includa tutto ciò che vuoi raggruppare. Assicurati che questa funzione soddisfi i requisiti rigorosi per le forme imposti dall'operazione di raggruppamento. Aggiungi @tf.function se non ne ha già uno.
È importante fornire il input_signature al @tf.function. La dimensione 0 deve essere None perché è la dimensione del batch, pertanto non può avere dimensioni fisse. Ad esempio, [None, 4], [None] o [None, 128, 4, 10] sono tutte forme di input valide. Quando salvi il modello, fornisci SaveOptions come quelli mostrati
di seguito per assegnare a model.batch_func un alias "batch_func". Quindi puoi passare questo
alias di funzione al convertitore.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
A questo punto, passa i function_alias utilizzando BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Definizione delle opzioni di raggruppamento
num_batch_threads: (intero) Numero di thread di pianificazione per l'elaborazione di batch di lavoro. Determina il numero di batch elaborati in parallelo. Dovrebbe essere all'incirca in linea con il numero di core TPU disponibili.max_batch_size: (numero intero) Dimensione massima del batch consentita. Può essere maggiore diallowed_batch_sizesper utilizzare la suddivisione in batch di grandi dimensioni.batch_timeout_micros: (intero) Numero massimo di microsecondi da attendere prima di generare un batch incompleto.allowed_batch_sizes: (elenco di numeri interi) se l'elenco non è vuoto, i batch verranno aumentati fino alla dimensione più vicina nell'elenco. L'elenco deve essere in aumento monotono e l'elemento finale deve essere inferiore o uguale amax_batch_size.max_enqueued_batches: (numero intero) Numero massimo di batch in coda per l'elaborazione prima che le richieste non vengano completate rapidamente.
Aggiornamento delle opzioni di raggruppamento esistenti
Puoi aggiungere o aggiornare le opzioni di raggruppamento eseguendo l'immagine Docker specificando
batch_options e impostando disable_default_optimizations su true utilizzando il
--converter_options_string flag. Le opzioni batch verranno applicate a ogni funzione TPU o operazione di raggruppamento preesistente.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Requisiti per la forma del batching
I batch vengono creati concatenando i tensori di input tra le richieste lungo la dimensione del batch (0). I tensori di output vengono suddivisi in base alla dimensione 0. Per eseguire queste operazioni, l'operazione di raggruppamento ha requisiti rigorosi per le forme degli input e degli output.
Procedura dettagliata
Per comprendere questi requisiti, è utile prima capire come viene eseguito il raggruppamento. Nell'esempio seguente, raggruppiamo un'operazione tf.matmul semplice.
def my_func(A, B) return tf.matmul(A, B)
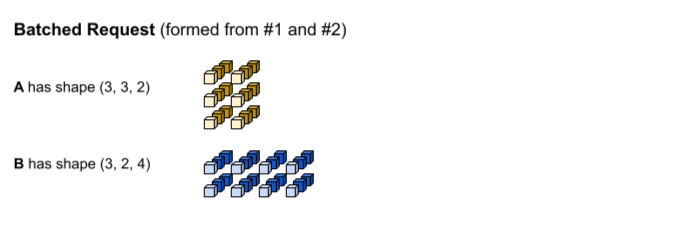
La prima richiesta di inferenza produce gli input A e B con le forme (1, 3,
2) e (1, 2, 4) rispettivamente. La seconda richiesta di inferenza produce gli input A e B con le forme (2, 3, 2) e (2, 2, 4).

È stato raggiunto il timeout per l'elaborazione collettiva. Il modello supporta una dimensione batch di 3, quindi le richieste di inferenza 1 e 2 vengono raggruppate insieme senza spaziatura. I vettori con aggregazione vengono formati concatenando le richieste 1 e 2 lungo la dimensione del batch (0). Poiché A di riga 1 ha una forma (1, 3, 2) e A di riga 2 ha una forma
(2, 3, 2), quando vengono concatenati lungo la dimensione del batch (0), la
forma risultante è (3, 3, 2).
tf.matmul viene eseguito e produce un output con la forma (3, 3,
4).

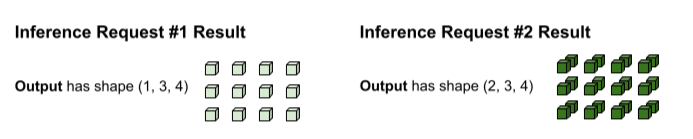
L'output di tf.matmul è raggruppato, pertanto deve essere suddiviso nuovamente in richieste separate. L'operazione di raggruppamento esegue questa operazione dividendo in base alla dimensione del batch (0) di ogni tensore di output. Decide come suddividere la dimensione 0 in base alla forma degli input originali. Poiché le forme della richiesta 1 hanno una dimensione 0 di 1, l'output ha una dimensione 0 di 1 per una forma di (1, 3, 4).
Poiché le forme della richiesta 2 hanno una dimensione 0 pari a 2, l'output ha una dimensione 0 pari a 2 per una forma (2, 3, 4).
Requisiti relativi alla forma
Per eseguire l'operazione di concatenazione dell'input e la suddivisione dell'output descritta sopra, l'operazione di raggruppamento ha i seguenti requisiti di forma:
Gli input per il raggruppamento non possono essere scalari. Per concatenare lungo la dimensione 0, i tensori devono avere almeno due dimensioni.
Nella procedura dettagliata riportata sopra. Né A né B sono scalari.
La mancata soddisfazione di questo requisito causerà un errore come:
Batching input tensors must have at least one dimension. Una semplice correzione per questo errore è trasformare lo scalare in un vettore.In diverse richieste di inferenza (ad esempio, diverse invocazioni di Esecuzione sessione), i tensori di input con lo stesso nome hanno le stesse dimensioni per ogni dimensione, tranne per la dimensione 0. In questo modo, gli input possono essere concatenati in modo pulito lungo la loro dimensione 0.
Nella procedura dettagliata riportata sopra, la richiesta 1 ha la forma
(1, 3, 2). Ciò significa che qualsiasi richiesta futura deve produrre una forma con il pattern(X, 3, 2). La richiesta 2 soddisfa questo requisito con(2, 3, 2). Analogamente, il parametro B della richiesta 1 ha la forma(1, 2, 4), pertanto tutte le richieste future devono produrre una forma con il pattern(X, 2, 4).La mancata soddisfazione di questo requisito causerà un errore come:
Dimensions of inputs should match.Per una determinata richiesta di inferenza, tutti gli input devono avere la stessa dimensione della dimensione 0. Se diversi tensori di input all'operazione di raggruppamento hanno dimensioni diverse per la dimensione 0, l'operazione di raggruppamento non sa come suddividere i tensori di output.
Nella procedura dettagliata precedente, i tensori della richiesta 1 hanno tutti una dimensione 0 di dimensione 1. In questo modo, l'operazione di raggruppamento sa che l'output deve avere una dimensione di 0 di dimensione pari a 1. Analogamente, i tensori della richiesta 2 hanno una dimensione 0 di dimensione 2, quindi l'output avrà una dimensione 0 di dimensione 2. Quando l'operazione di raggruppamento suddivide la forma finale di
(3, 3, 4), produce(1, 3, 4)per la richiesta 1 e(2, 3, 4)per la richiesta 2.La mancata soddisfazione di questo requisito comporterà errori come:
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size.La dimensione della dimensione 0 della forma di ogni tensore di output deve essere la somma di tutte le dimensioni della dimensione 0 dei tensori di input (più eventuali spaziature introdotte dall'operazione di raggruppamento per soddisfare la dimensione
allowed_batch_sizesuccessiva più grande). In questo modo, l'operazione di raggruppamento può suddividere i tensori di output in base alla dimensione 0 in base alla dimensione 0 dei tensori di input.Nella procedura dettagliata riportata sopra, i tensori di input hanno una dimensione 0 pari a 1 dalla richiesta 1 e 2 dalla richiesta 2. Pertanto, ogni tensore di output deve avere una dimensione 0 pari a 3 perché 1 + 2=3. Il tensore di output
(3, 3, 4)soddisfa questo requisito. Se 3 non fosse stata una dimensione del batch valida, ma 4 sì, l'operazione di raggruppamento avrebbe dovuto aggiungere elementi alla dimensione 0 degli input da 3 a 4. In questo caso, ogni tensore di output deve avere una dimensione 0 di 4.La mancata soddisfazione di questo requisito comporterà un errore simile al seguente:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors.
Risolvere gli errori relativi ai requisiti delle forme
Per soddisfare questi requisiti, ti consigliamo di fornire un'altra funzione o firma al batch. Potrebbe anche essere necessario modificare le funzioni esistenti per soddisfare questi requisiti.
Se una
funzione
viene eseguita in batch, assicurati che tutte le forme della firma di input di @tf.function
abbiano None nella dimensione 0 (ovvero la dimensione batch). Se viene eseguito il raggruppamento di una
firma, assicurati che tutti i relativi input abbiano -1 nella dimensione 0.
L'operatore BatchFunction non supporta SparseTensors come input o output.
Internamente, ogni tensore sparso è rappresentato come tre tensori distinti che possono avere dimensioni diverse per la dimensione 0.