Cloud TPU v5e 推論コンバータの概要
はじめに
Cloud TPU Inference Converer は、TPU 推論用の TensorFlow 2(TF2)モデルを準備して最適化します。コンバータは、ローカルまたは TPU VM シェルで動作します。 コンバータに必要なコマンドライン ツールがプリインストールされているため、TPU VM シェルをおすすめします。エクスポートされた SavedModel を受け取り、次の手順を実行します。
- TPU 変換: モデルに
TPUPartitionedCallなどの TPU オペレーションを追加して、TPU で提供できるようにします。デフォルトでは、推論用にエクスポートされたモデルにはこのようなオペレーションがないため、TPU でトレーニングされた場合でも TPU で提供できません。 - バッチ処理: グラフ内のバッチ処理を有効にして、スループットを向上させるモデルにバッチ処理演算を追加します。
- BFloat16 変換: モデルのデータ形式を
float32からbfloat16に変換して、計算パフォーマンスを向上させ、TPU の高帯域幅メモリ(HBM)の使用量を低減します。 - IO シェイプの最適化: CPU と TPU の間で転送されるデータのテンソル形状を最適化して、帯域幅使用率を向上させます。
モデルをエクスポートするときに、TPU で実行する関数の関数エイリアスを作成します。これらの関数をコンバータに渡すと、コンバータは関数を TPU に配置して最適化します。
Cloud TPU Inference Converter は Docker イメージとして提供されており、Docker がインストールされている任意の環境で実行できます。
上記の手順を完了するまでの推定所要時間: 約 20 分~ 30 分
前提条件
- モデルは TF2 モデルであり、SavedModel 形式でエクスポートされている必要があります。
- モデルには、TPU 関数の関数エイリアスを設定する必要があります。これを行う方法については、コード例をご覧ください。次の例では、TPU 関数のエイリアスとして
tpu_funcを使用します。 - Tensorflow ライブラリ(Cloud TPU Inference Converter の依存関係)は AVX 命令を使用するようにコンパイルされるため、マシンの CPU が Advanced Vector eXtensions(AVX)命令をサポートしていることを確認してください。ほとんどの CPU が AVX をサポートします。
lscpu | grep avxを実行して、AVX 命令セットがサポートされているかどうかを確認できます。
準備
セットアップを開始する前に、次のことを行います。
新しいプロジェクトを作成する: Google Cloud コンソールの [プロジェクト セレクタ] ページで、Cloud プロジェクトを選択または作成します。
TPU VM を設定する: Google Cloud コンソールまたは
gcloudを使用して新しい TPU VM を作成するか、既存の TPU VM を使用して、TPU VM 上で変換されたモデルで推論を実行します。- TPU VM イメージが TensorFlow ベースであることを確認します。例:
--version=tpu-vm-tf-2.11.0 - 変換されたモデルは、この TPU VM に読み込まれ、提供されます。
- TPU VM イメージが TensorFlow ベースであることを確認します。例:
Cloud TPU Inference Converter の使用に必要なコマンドライン ツールがあることを確認します。Google Cloud SDK と Docker をローカルにインストールするか、このソフトウェアがデフォルトでインストールされている TPU VM を使用できます。これらのツールを使用して、コンバータ イメージを操作します。
次のコマンドを使用して、SSH でインスタンスに接続します。
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
環境設定
TPU VM シェルまたはローカルシェルから環境を設定します。
TPU VM シェル
TPU VM シェルで次のコマンドを実行して、root 以外の Docker の使用を許可します。
sudo usermod -a -G docker ${USER} newgrp docker
Docker 認証ヘルパーを初期化します。
gcloud auth configure-docker \ us-docker.pkg.dev
ローカルシェル
ローカルシェルで、次の手順で環境を設定します。
Inference Converter Docker イメージを pull します。
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
コンバータのイメージ
イメージは 1 回限りのモデル変換用です。モデルパスを設定し、ニーズに合わせてコンバータ オプションを調整します。使用例セクションには、いくつかの一般的なユースケースが用意されています。
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
TPU VM で変換されたモデルによる推論
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
使用例
TPU 関数の関数エイリアスを追加する
- TPU で実行するすべての対象をラップする関数をモデル内で検出または作成します。
@tf.functionが存在しない場合は追加します。 - モデルを保存するときに、次のように SaveOptions を指定して、
model.tpu_funcにエイリアスfunc_on_tpuを付加します。 - この関数エイリアスをコンバータに渡すことができます。
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
複数の TPU 関数でモデルを変換する
TPU には複数の関数を配置できます。複数の関数エイリアスを作成し、converter_options_string でコンバータに渡します。
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
量子化
量子化は、モデルのパラメータを表すために使用される数値の精度を下げる手法です。この結果、モデルサイズが小さくなり、計算速度が向上します。量子化モデルでは、推論のスループットが向上するだけでなく、メモリ使用量とストレージ サイズも小さくなりますが、そのかわりに精度は低くなります。
TPU を対象とする TensorFlow の新しいトレーニング後の量子化機能は、モバイル デバイスとエッジデバイスを対象とする TensorFlow Lite の同様の既存の機能から開発されています。一般的な量子化の詳細については、TensorFlow Lite のドキュメントをご覧ください。
量子化のコンセプト
このセクションでは、推論コンバータを使用した量子化に関連するコンセプトを定義します。
他の TPU 構成(スライス、ホスト、チップ、TensorCore など)に関連するコンセプトについては、TPU システム アーキテクチャのページをご覧ください。
トレーニング後の量子化(PTQ): PTQ は、精度を大幅に下げることなく、ニューラル ネットワーク モデルのサイズとコンピューティングの複雑さを下げる方法です。PTQ は、トレーニング済みモデルの浮動小数点重みと活性化を 8 ビット整数や 16 ビット整数などの低精度整数に変換することで機能します。これにより、モデルのサイズと推論レイテンシが大幅に低下する一方で、精度はわずかに低下します。
キャリブレーション: 量子化のキャリブレーション ステップは、ニューラル ネットワーク モデルの重みと活性化が取る値の範囲に関する統計情報を収集するプロセスです。この情報は、モデルの量子化パラメータを決定するために使用されます。これは浮動小数点の重みと活性化を整数に変換するために使用される値です。
代表データセット: 量子化の代表データセットは、モデルの実際の入力データを表す小さなデータセットです。量子化のキャリブレーション ステップで、モデルの重みと活性化が取る値の範囲に関する統計情報を収集します。代表的なデータセットは次のプロパティを満たす必要があります。
- 推論中のモデルへの実際の入力を適切に表す必要があります。つまり、モデルが現実に認識する可能性のある値の範囲をカバーする必要があります。
- 存在する場合は、条件の各ブランチ(
tf.condなど)を一緒に通過する必要があります。これは重要です。量子化プロセスでは、代表的なデータセットで明示的に表現されていない場合でも、モデルへのすべての入力を処理できる必要があります。 - 十分な統計情報を収集し、エラーを減らすために十分な大きさである必要があります。目安としては、200 を超える代表サンプルを使用することをおすすめします。
代表データセットは、トレーニング データセットのサブセットにすることも、モデルへの実際の入力を表すように特別に設計された別のデータセットにすることもできます。使用するデータセットの選択は、アプリケーションによって異なります。
静的範囲量子化(SRQ): SRQ では、キャリブレーション ステップ中にニューラル ネットワーク モデルの重みと活性化の値の範囲を 1 回決定します。つまり、モデルへのすべての入力に同じ値の範囲が使用されます。これは、特に広い範囲の入力値を持つモデルの場合、動的範囲の量子化よりも精度が低くなります。ただし、静的範囲量子化では、動的範囲の量子化よりも実行時の計算が少なくなります。
動的範囲量子化(DRQ): DRQ は、各入力のニューラル ネットワーク モデルの重みと活性化の値の範囲を決定します。これにより、入力データの値の範囲にモデルを適応させ、精度を改善できます。ただし、動的範囲量子化には静的範囲量子化よりも実行時の多くの計算が必要です。
機能 静的範囲量子化 動的範囲量子化 値の範囲 キャリブレーション中に 1 回決定 入力ごとに決定 精度 特に入力値の範囲が大きいモデルの場合は、精度が低下する可能性があります。 特に入力値の範囲が大きいモデルの場合は、より正確な値になる可能性があります。 複雑さ シンプルになった 複雑になった 実行時の計算 少ない計算 多い計算 重みのみの量子化: 重みのみの量子化は、ニューラル ネットワーク モデルの重みのみを量子化して、活性化を浮動小数点のままにする量子化の種類です。モデルの精度を維持できるため、精度が重視されるモデルにおすすめのオプションです。
量子化の使用方法
量子化を適用するには、QuantizationOptions を構成してコンバータのオプションに設定します。次のようなオプションがあります。
- タグ: 量子化する
SavedModel内のMetaGraphDefを識別するタグのコレクション。MetaGraphDefが 1 つしかない場合、指定する必要はありません。 - signature_keys: 入力と出力を含む
SignatureDefを識別するキー シーケンス。指定しない場合、[serving_default] が使用されます。 - quantization_method: 適用する量子化メソッド。指定しない場合は
STATIC_RANGE量子化が適用されます。 - op_set: XLA として保持する必要があります。これは現在、デフォルトのオプションであり、指定する必要はありません。
- representative_datasets: 量子化パラメータの調整に使用するデータセットを指定します。
代表的なデータセットを作成する
代表的なデータセットは、基本的にサンプルのイテラブルです。ここで、サンプルは {input_key: input_value} のマップです。例:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
代表的なデータセットは、tf-nightly pip パッケージ内で現在利用可能な TfRecordRepresentativeDatasetSaver クラスを使用して、TFRecord ファイルとして保存する必要があります。例:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
例
次の例では、serving_default の署名キーと tpu_func の関数エイリアスを使用してモデルを量子化します。
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
バッチ処理を追加する
コンバータを使用すると、モデルにバッチ処理を追加できます。調整可能なバッチ オプションの説明については、バッチ処理オプションの定義をご覧ください。
デフォルトでは、Converter はモデル内のすべての TPU 関数をバッチ処理します。また、ユーザー指定の署名と関数をバッチ処理して、パフォーマンスをさらに向上させることもできます。バッチ化される TPU 関数、ユーザー指定の関数、または署名は、バッチ処理演算の厳密な形状の要件を満たしている必要があります。
コンバータは、既存のバッチ処理オプションを更新することもできます。モデルにバッチ処理を追加する方法の例を次に示します。バッチ処理の詳細については、バッチ処理の詳細をご覧ください。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
bfloat16 と IO の形状の最適化を無効にする
BFloat16 と IO 形状の最適化はデフォルトで有効になっています。モデルで適切に動作しない場合は、無効にできます。
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
変換レポート
この変換レポートは、推論コンバータの実行後にログで確認できます。下記の例をご覧ください。
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
このレポートでは、CPU と TPU での出力モデルの計算コストが推定され、さらに TPU のコストが関数ごとに分類されます。これは、コンバータ オプションで選択した TPU 関数を反映しているはずです。
TPU をより有効に活用するには、モデル構造をテストしてコンバータ オプションを調整することをおすすめします。
よくある質問
TPU に配置する関数
ほとんどのオペレーションは TPU でより高速に実行されるため、モデルのできるだけ多くの部分を TPU に配置することをおすすめします。
モデルに TPU と互換性のない演算、文字列、スパース テンソルが含まれていない場合は、通常、モデル全体を TPU に配置するのが最適な戦略です。これを行うには、モデル全体をラップする関数を検出または作成し、その関数の関数エイリアスを作成して、Converter に渡します。
TPU で動作できない部分(TPU と互換性のない演算、文字列、スパース テンソルなど)がモデルに含まれる場合、TPU 関数は、互換性のない部分がどこにあるかによって異なります。
- 互換性のない部分がモデルの先頭または末尾にある場合、モデルをリファクタリングして CPU で維持できます。例としては、文字列の前処理ステージと後処理ステージがあります。コードを CPU に移動する方法について詳しくは、「モデルの一部を CPU に移動するにはどうすればよいですか?」をご覧ください。 モデルをリファクタリングする一般的な方法を示しています。
- モデルの中間に位置する場合、モデルを 3 つの部分に分割し、中間部分に TPU 互換でない演算をすべて含めて、CPU で実行することをおすすめします。
- スパース テンソルの場合は、CPU で
tf.sparse.to_denseを呼び出し、結果のスパース テンソルをモデルの TPU 部分に渡すことを検討してください。
考慮すべきもう 1 つの要素は、HBM の使用量です。テーブルを埋め込むと、大量の HBM を使用する可能性があります。TPU のハードウェア上限を超える場合は、ルックアップ オペレーションとともに CPU に配置する必要があります。
可能であれば、1 つのシグネチャ内に 1 つの TPU 関数のみを配置してください。 モデルの構造で、受信する推論リクエストごとに複数の TPU 関数を呼び出す必要がある場合は、CPU と TPU 間でテンソルを送信するレイテンシの増加に注意する必要があります。
TPU 関数の選択を評価するには、変換レポートを確認することをおすすめします。TPU に配置された計算の割合と、各 TPU 関数の費用の内訳が表示されます。
モデルの一部を CPU に移動するにはどうすればよいですか?
モデルに TPU で提供できない部分が含まれている場合は、モデルをリファクタリングして CPU に移動する必要があります。以下に、簡単な例を示します。このモデルは、前処理ステージを持つ言語モデルです。簡素化のため、レイヤ定義と関数のコードは省略されています。
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
このモデルは、2 つの理由で TPU で直接提供できません。まず、パラメータが文字列です。2 つ目は、preprocess 関数に多くの文字列オペレーションが含まれている可能性があります。どちらも TPU と互換性がありません。
このモデルをリファクタリングするには、計算負荷の高い bert_layer をホストする tpu_func という別の関数を作成します。次に、tpu_func の関数エイリアスを作成してコンバータに渡します。これにより、tpu_func 内のすべてが TPU で実行され、model_func に残っているすべてが CPU で実行されます。
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
モデルに TPU と互換性のない演算、文字列、スパース テンソルがある場合はどうすればよいですか?
TPU では標準の TensorFlow 演算のほとんどがサポートされていますが、スパース テンソルや文字列などはサポートされていません。コンバータは、TPU と互換性のない演算をチェックしません。したがって、このような演算を含むモデルは変換をパスすることができます。しかし、推論に実行すると、次のようなエラーが発生します。
'tf.StringToNumber' op isn't compilable for TPU device.
モデルに TPU と互換性のない演算がある場合は、それらの演算を TPU 関数の外部に配置する必要があります。さらに、文字列は TPU でサポートされていないデータ形式です。したがって、文字列型の変数は TPU 関数に配置しないでください。また、TPU 関数のパラメータと戻り値も文字列型に設定しないようにする必要があります。同様に、TPU 関数(パラメータや戻り値を含む)にスパース テンソルを配置しないでください。
通常、モデルの互換性のない部分をリファクタリングして CPU に移動することは困難ではありません。ここで例を示します。
モデルでカスタム オペレーションをサポートする方法
モデルでカスタム演算が使用されている場合は、コンバータがカスタム演算を認識できず、モデルの変換に失敗する可能性があります。これは、演算の詳細な定義を含むカスタム演算の演算ライブラリがコンバータにリンクされていないためです。
現在、コンバータ コードはオープンソース化されていないため、カスタム演算でコンバータをビルドすることはできません。
TensorFlow 1 モデルがある場合はどうすればよいですか?
コンバータは TensorFlow 1 モデルをサポートしていません。TensorFlow 1 モデルを TensorFlow 2 に移行する必要があります。
モデルの実行時に MLIR ブリッジを有効にする必要がありますか?
変換されたモデルのほとんどは、新しい TF2XLA MLIR ブリッジまたは元の TF2XLA ブリッジで実行できます。
関数エイリアスなしですでにエクスポートされているモデルを変換するにはどうすればよいですか?
関数エイリアスを使用せずにモデルがエクスポートされた場合は、そのモデルを再度エクスポートして、関数エイリアスを作成するのが最も簡単な方法です。
再エクスポートできない場合でも、concrete_function_name を指定してモデルを変換できます。ただし、正しい concrete_function_name を特定するには、検出に関連する作業が必要です。
関数エイリアスは、ユーザー定義の文字列から具体的な関数名へのマッピングです。マッピングにより、モデル内の特定の関数を簡単に参照できます。コンバータは、関数エイリアスと未加工の具象関数名の両方を受け入れます。
具体的な関数名は saved_model.pb を調べることで確認できます。
次の例は、__inference_serve_24 という具象関数を TPU に配置する方法を示しています。
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
コンパイル時の定数制約エラーを解決するにはどうすればよいですか?
トレーニングと推論の両方で、XLA では TPU のコンパイル時に、特定の演算への入力が既知の形状である必要があります。つまり、XLA がプログラムの TPU 部分をコンパイルするときに、これらの演算への入力は静的に既知の形状であることが必要です。
この問題を解決するには、2 つの方法があります。
- 最適な方法は、XLA が TPU プログラムをコンパイルするまでに、演算の入力を更新して静的に既知の形状にすることです。このコンパイルは、モデルの TPU 部分が実行される直前に行われます。つまり、
TpuFunctionが実行されるときには、形状が静的に既知である必要があります。 - 別の方法として、問題のある演算が含まれないように
TpuFunctionを変更することもできます。
バッチ処理の形状エラーが表示されるのはなぜですか?
バッチ処理には、受信リクエストを 0 番目のディメンション(バッチ処理ディメンション)に沿ってバッチ化できるようにするための厳密な形状の要件があります。これらの形状要件は TensorFlow バッチ処理演算から取得され、緩和できません。
これらの要件を満たさないと、次のようなエラーが発生します。
- バッチ処理の入力テンソルには少なくとも 1 つのディメンションが必要です。
- 入力のディメンションは一致している必要があります。
- 特定の演算呼び出しで指定されたバッチ入力テンソルは、同じ 0 次元のディメンションサイズである必要があります。
- バッチ化される出力テンソルの 0 番目のディメンションサイズは、入力テンソルの 0 番目のディメンションサイズの合計と等しくありません。
これらの要件を満たすには、バッチに別の関数または署名を指定することを検討してください。また、これらの要件を満たすために既存の関数を変更することも必要になる場合があります。
関数がバッチ化されている場合は、@tf.function の input_signature の形状がすべて、0 番目のディメンションで None になっていることを確認します。署名がバッチ化されている場合は、その入力がすべて、0 番目のディメンションで -1 になっていることを確認します。
これらのエラーが発生する理由とその解決方法については、バッチ処理の詳細をご覧ください。
既知の問題
TPU 関数は別の TPU 関数を間接的に呼び出すことができない
コンバータは、CPU と TPU の境界を越えたほとんどの関数呼び出しシナリオを処理できますが、まれに失敗するエッジケースがあります。これは、TPU 関数が別の TPU 関数を間接的に呼び出す場合です。
これは、Converter が、TPU 関数自体の呼び出しから TPU 呼び出しスタブの呼び出しまで、TPU 関数の直接の呼び出し元を変更するためです。呼び出しスタブには、CPU でのみ実行できる演算が含まれています。TPU 関数が最終的に直接の呼び出し元を呼び出す関数を呼び出すと、それらの CPU 演算が TPU に持ち込まれて実行され、カーネル欠落エラーが発生することがあります。このケースは、別の TPU 関数を直接呼び出す TPU 関数とは異なります。この場合、コンバーターは呼び出しスタブを呼び出すようにどちらの関数も変更しないため、動作します。
コンバータでは、このシナリオの検出を実装しています。次のエラーが表示された場合は、モデルがこのエッジケースに該当していることを意味します。
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
一般的な解決策は、このような関数呼び出しのシナリオを回避するためにモデルをリファクタリングすることです。難しい場合は、Google サポートチームにお問い合わせください。
リファレンス
コンバータ オプション(Protobuf 形式)
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
バッチ処理の詳細
バッチ処理は、スループットと TPU 使用率を改善するために使用されます。これにより、複数のリクエストを同時に処理できます。トレーニング中に、tf.data を使用してバッチ処理を行うことができます。推論中は、通常、受信リクエストをバッチ処理する演算をグラフに追加することで行われます。この演算は、十分な数のリクエストがあるかタイムアウトに達するまで待機してから、個々のリクエストから大きなバッチを生成します。バッチサイズやタイムアウトなど、調整できるさまざまなバッチ処理オプションの詳細については、バッチ処理オプションの定義をご覧ください。
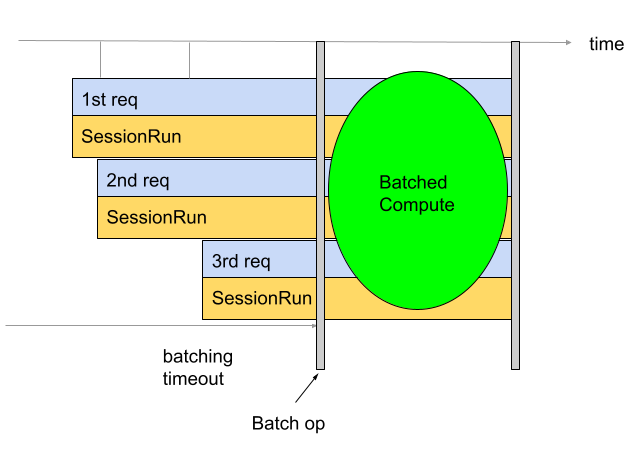
デフォルトでは、Converter は TPU の計算の直前にバッチ処理演算を挿入します。ユーザー指定の TPU 関数と、モデル内の既存の TPU 計算をバッチ処理演算でラップします。このデフォルトの動作は、コンバータにどの関数や署名をバッチ化するかを指示することでオーバーライドできます。
次の例は、デフォルトのバッチ処理を追加する方法を示しています。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
署名のバッチ処理
署名のバッチ処理では、モデルの入力全体を署名の入力から署名の出力へとバッチ処理します。Converter のデフォルトのバッチ処理動作とは異なり、署名のバッチ処理では、TPU の計算と CPU の計算の両方がバッチ処理されます。これにより、一部のモデルの推論時のパフォーマンスが 10~20% 向上します。
すべてのバッチ処理と同様に、署名のバッチ処理には厳密な形状の要件があります。
これらの形状要件を満たすには、署名入力に 2 つ以上のディメンションを持つ形状が必要です。最初のディメンションはバッチサイズで、サイズは -1 にする必要があります。たとえば、(-1, 4)、(-1)、(-1,
128, 4, 10) はすべて有効な入力形状です。これが可能でない場合は、デフォルトのバッチ処理または関数のバッチ処理の使用を検討してください。
署名のバッチ処理を使用するには、BatchOptions を使用して署名名を signature_name として指定します。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
関数のバッチ処理
関数のバッチ処理は、バッチ化する関数を Converter に指示するために使用できます。デフォルトでは、コンバータはすべての TPU 関数をバッチ処理します。関数バッチ処理は、このデフォルトの動作をオーバーライドします。
関数のバッチ処理は、CPU 計算のバッチ処理に使用できます。多くのモデルでは、CPU 計算がバッチ化されるとパフォーマンスが向上します。CPU 計算をバッチ処理する最善の方法は、署名のバッチ処理を使用することですが、モデルによっては機能しない場合があります。このような場合、関数のバッチ処理を使用して、TPU 計算に加えて CPU 計算の一部をバッチ処理できます。バッチ処理演算は TPU では実行できないため、提供されたバッチ処理関数は CPU で呼び出す必要があります。
関数のバッチ処理は、バッチ処理演算によって課される厳密な形状の要件を満たすためにも使用できます。TPU 関数がバッチ処理演算の形状要件を満たさない場合、関数のバッチ処理を使用して、異なる関数をバッチ処理するようコンバータに指示できます。
これを使用するには、バッチ化する関数の function_alias を生成します。これを行うには、バッチ化するすべてのものをラップする関数をモデル内で検出または作成します。この関数が、バッチ処理演算によって課される厳密な形状の要件を満たしていることを確認します。@tf.function をまだ追加していない場合は、追加します。@tf.function に input_signature を指定することが重要です。0 番目のディメンションは、None である必要があります。これはバッチ ディメンションであり、固定サイズにできないためです。たとえば、[None, 4]、[None]、[None, 128, 4, 10] はすべて有効な入力形状です。モデルを保存するときに、次に示すような SaveOptions を指定して、model.batch_func にエイリアス「batch_func」を指定します。その後、この関数エイリアスをコンバーターに渡すことができます。
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
次に、BatchOptions を使用して function_alias を渡します。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
バッチ処理オプションの定義
num_batch_threads:(整数)作業バッチを処理するためのスケジューリング スレッドの数。並列で処理されるバッチの数を決定します。これは、使用可能な TPU コアの数とほぼ一致している必要があります。max_batch_size:(整数)許可される最大バッチサイズ。大規模なバッチ分割を利用するために、allowed_batch_sizesより大きくすることができます。batch_timeout_micros:(整数)不完全なバッチを出力する前に待機する最大マイクロ秒数。allowed_batch_sizes:(整数のリスト)リストが空でない場合、リスト内の最も近いサイズまでバッチがパディングされます。リストは単調増加で、最後の要素はmax_batch_size以下にする必要があります。max_enqueued_batches:(整数)リクエストが失敗する前に処理するためにキューに格納されたバッチの最大数。
既存のバッチ処理オプションの更新
バッチ処理オプションを追加または更新するには、batch_options を指定して Docker イメージを実行し、--converter_options_string フラグを使用して disable_default_optimizations を true に設定します。バッチ オプションは、すべての TPU 関数または既存のバッチ処理演算に適用されます。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
バッチ処理の形状の要件
バッチは、バッチ(0 番目)ディメンションに沿ってリクエスト間で入力テンソルを連結することによって作成されます。出力テンソルは 0 番目のディメンションに沿って分割されます。これらの演算を実行するために、バッチ処理演算には入力と出力の厳格な形状要件があります。
チュートリアル
これらの要件を理解するには、最初にバッチ処理がどのように行われるかを理解しておくことが役立ちます。次の例では、単純な tf.matmul 演算をバッチ処理しています。
def my_func(A, B) return tf.matmul(A, B)
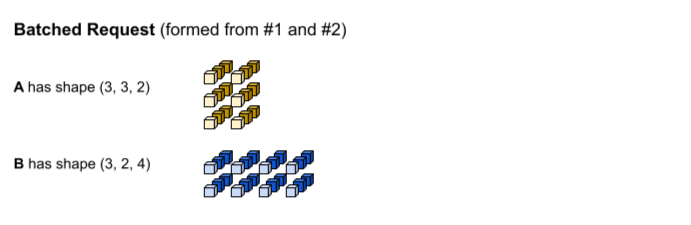
最初の推論リクエストは、(1, 3,
2) と (1, 2, 4) の形状でそれぞれ入力 A と B を生成します。2 番目の推論リクエストは、(2, 3, 2) と (2, 2, 4) の形状で入力 A と B を生成します。

バッチ処理のタイムアウトに達しました。このモデルはバッチサイズ 3 をサポートしているため、推論リクエスト #1 と #2 はパディングなしで一緒にバッチ化されます。バッチ テンソルは、バッチ(0 番目)ディメンションに沿ってリクエスト #1 と #2 を連結することで形成されます。#1 の A の形状は (1, 3, 2)、#2 の A の形状は (2, 3, 2) であるため、これらがバッチ(0 番目)ディメンションに沿って連結されると、最終的な形状は (3, 3, 2) になります。
tf.matmul が実行され、(3, 3,
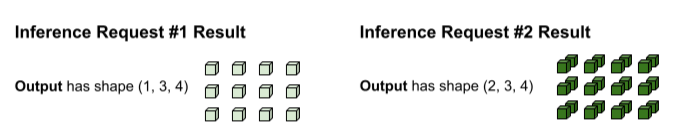
4) の形状で出力が生成されます。

tf.matmul の出力はバッチ化されているため、個別のリクエストに分割する必要があります。バッチ処理演算では、各出力テンソルのバッチ(0 番目)ディメンションに沿って分割します。元の入力の形状に基づいて 0 番目のディメンションを分割する方法を決定します。リクエスト #1 の形状は 0 番目のディメンションが 1 であるため、出力は、(1, 3, 4) の形状の 0 番目のディメンション 1 になります。リクエスト #2 の形状は 0 番目のディメンションが 2 であるため、出力は、(2, 3, 4) の形状の 0 番目のディメンション 2 になります。
形状の要件
上記の入力連結と出力分割を実行するには、バッチ処理オペレーションに次の形状に関する要件があります。
バッチ処理への入力をスカラーにすることはできません。0 番目のディメンションに沿って連結するには、テンソルに少なくとも 2 つのディメンションが必要です。
上のチュートリアルでは、A も B もスカラーではありません。
この要件を満たさないと、次のようなエラーが発生します:
Batching input tensors must have at least one dimension。このエラーを簡単に修正するには、スカラーをベクトルに変換します。異なる推論リクエスト(異なるセッション実行呼び出しなど)間で、同じ名前の入力テンソルは、0 番目のディメンションを除き、各ディメンションに対して同じサイズになります。これにより、入力を 0 番目のディメンションに沿ってスムーズに連結できます。
上述のチュートリアルでは、リクエスト #1 の A の形状が
(1, 3, 2)になっています。 つまり、今後のリクエストでは、(X, 3, 2)のパターンを持つ形状を生成する必要があります。リクエスト #2 は(2, 3, 2)でこの要件を満たしています。同様に、リクエスト #1 の B の形状は(1, 2, 4)であるため、将来のすべてのリクエストで(X, 2, 4)のパターンを持つ形状を生成する必要があります。この要件を満たさないと、次のようなエラーが発生します:
Dimensions of inputs should match。特定の推論リクエストの場合、すべての入力の 0 番目のディメンションサイズが同じである必要があります。バッチ処理演算への異なる入力テンソルの 0 番目のディメンションが異なる場合、バッチ処理演算では、出力テンソルの分割方法がわかりません。
上記のチュートリアルでは、リクエスト #1 のテンソルの 0 番目のディメンションサイズはすべて 1 になっています。これにより、バッチ処理では、出力の 0 番目のディメンションサイズが 1 になることがわかります。同様に、リクエスト #2 のテンソルの 0 番目のディメンションサイズは 2 であるため、出力の 0 番目のディメンションサイズは 2 になります。バッチ処演算で
(3, 3, 4)の最終形状が分割されると、リクエスト #1 には(1, 3, 4)、リクエスト #2 には(2, 3, 4)が生成されます。この要件を満たさないと、次のようなエラーが発生します:
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size。各出力テンソルの形状の 0 番目のディメンションサイズは、すべての入力テンソルの 0 番目のディメンションサイズの合計(および、次に大きい
allowed_batch_sizeを満たすためにバッチ処理オペレーションによって導入されたパディングの合計)でなければなりません。これにより、バッチ処理演算では、入力テンソルの 0 番目のディメンションに基づいて、出力テンソルが 0 番目のディメンションに沿って分割されます。上記のチュートリアルでは、入力テンソルにはリクエスト #1 の 0 番目のディメンション 1 と、リクエスト #2 の 0 番目のディメンション 2 があります。したがって、1+2=3 であるため、各出力テンソルの 0 番目のディメンションは 3 である必要があります。出力テンソル
(3, 3, 4)は、この要件を満たしています。3 が有効なバッチサイズではなく 4 であった場合、バッチ処理演算では、入力の 0 番目を 3 から 4 までパディングする必要があります。この場合、各出力テンソルの 0 番目のディメンションサイズは 4 である必要があります。この要件を満たさないと、次のようなエラーが発生します:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors。
形状の要件に関するエラーの解決
これらの要件を満たすには、バッチに別の関数または署名を指定することを検討してください。また、これらの要件を満たすために既存の関数を変更することも必要になる場合があります。
関数がバッチ化されている場合は、その @tf.function の input_signature の形状がすべて 0 番目のディメンション(バッチ ディメンション)で None になっていることを確認します。署名がバッチ化されている場合は、その入力がすべて、0 番目のディメンションで -1 になっていることを確認します。
BatchFunction 演算は、SparseTensors を入力または出力としてサポートしません。
内部では、それぞれのスパース テンソルは、異なる 0 番目のディメンションサイズを持つことができる 3 つの別個のテンソルとして表されます。