はじめに
数十億の時系列に対する予測と異常検出では、多くのコンピューティング負荷が高くなります。既存のほとんどのシステムは、予測と異常検出をバッチジョブとして実行します(リスク パイプライン、トラフィック予測、需要計画など)。このため、一連のイベント ディメンション全体の急激な増加または減少に基づくアラートの決定など、オンラインで実行できる分析の種類が大幅に制限されます。
Timeseries Insights API の主な目標は次のとおりです。
- クエリ パラメータに基づいて、未加工のイベントとそれらのプロパティから動的に構築される数十億の時系列にスケーリングします。
- リアルタイムの予測と異常検出の結果を提供します。つまり、数秒以内にすべての時系列のトレンドと季節性を検出し、スライスが予期せず急激に上昇または減少しているかどうかを判断します。
API の機能
- データセットを管理する
- Cloud Storage に保存されている複数のデータソースで構成されたデータセットをインデックスに登録して読み込みます。ストリーミング方式で新しいイベントを追加できるようにします。
- 不要になったデータセットをアンロードします。
- データセットの処理ステータスを確認します。
- データセットのクエリ実行
- 指定されたプロパティ値に一致する時系列を取得します。時系列は、指定したタイム ホライズンまでの予測です。時系列は異常についても評価されます。
- 異常なプロパティ値の組み合わせを自動的に検出します。
- データセットの更新
- 最近発生した新しいイベントを準リアルタイムで(数秒から数分の遅延で)取り込み、インデックスに組み込みます。
障害復旧
Timeseries Insights API は、Cloud Storage のバックアップとして機能したり、未加工のストリーミング アップデートを返したりしません。クライアントは、データを別々に保存し、バックアップする必要があります。
リージョンが停止すると、サービスはベスト エフォートの復元を実行します。停止の開始から 24 時間以内に更新されたメタデータ(データセットとオペレーション ステータスに関する情報)とストリーミングされたユーザーデータは復元されないことがあります。
復元中は、データセットへのクエリとストリーミング アップデートを行うことができない場合があります。
入力データ
数値データとカテゴリデータが時間の経過とともに収集されることは一般的です。たとえば、次の図は、一定期間における 1 分ごとのデータセンターで実行中の単一のジョブの CPU 使用率、メモリ使用量、ステータスを示しています。CPU 使用率とメモリ使用量は数値であり、ステータスはカテゴリ値です。
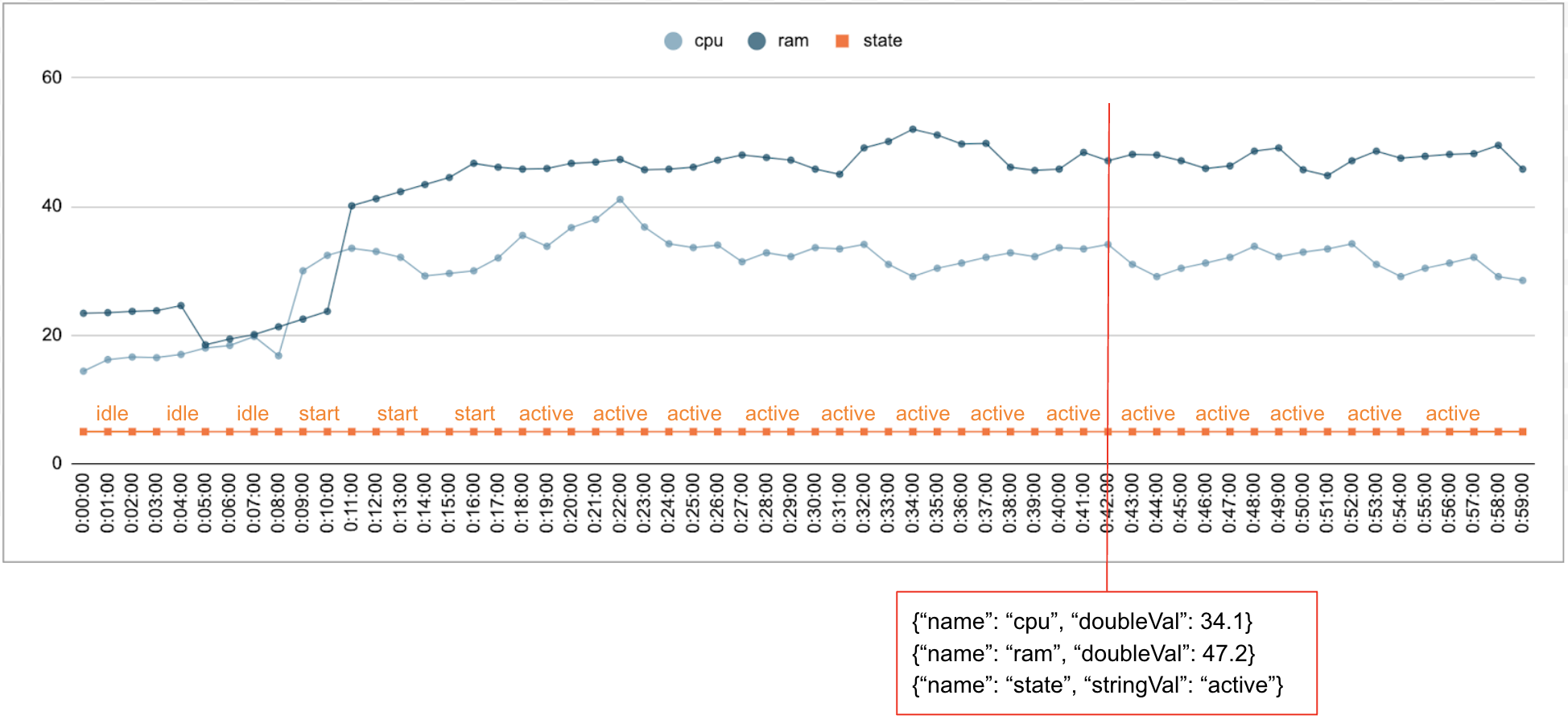
イベント
Timeseries Insights API では、イベントが基本データ入力として使用されます。各イベントには、タイムスタンプとディメンションのコレクション(キーがディメンション名である Key-Value ペア)があります。このシンプルな表現により、数兆規模のデータを処理できます。たとえば、単一のイベントを完全に表すために、データセンター、ユーザー、ジョブ名、タスク番号が含まれています。上の図は、単一のジョブに対して記録された一連のイベントを示しており、ディメンションのサブセットを示しています。
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
DataSetはイベントの集合です。クエリは同じデータセット内で実行されます。 各プロジェクトで複数のデータセットを使用できます。
データセットは、バッチデータとストリーミング データから構築されます。バッチデータ ビルドは、複数の Cloud Storage URI をデータソースとして読み取ります。バッチビルドが完了すると、データセットをストリーミング データで更新できます。過去のデータにバッチビルドを使用すると、システムはコールド スタートの問題を回避できます。
データセットのクエリや更新を行う前に、構築するかインデックスに登録しておく必要があります。インデックスへの登録はデータセットが作成されると始まり、データの量に応じて通常数分から数時間かかります。具体的には、データソースは最初のインデックス登録中に 1 回スキャンされます。最初のインデックス登録が完了した後に Cloud Storage URI の内容が変更された場合、再スキャンは行われません。追加データにはストリーミング アップデートを使用します。ストリーミング更新は、準リアルタイムで継続的にインデックスに登録されます。
時系列と異常検出
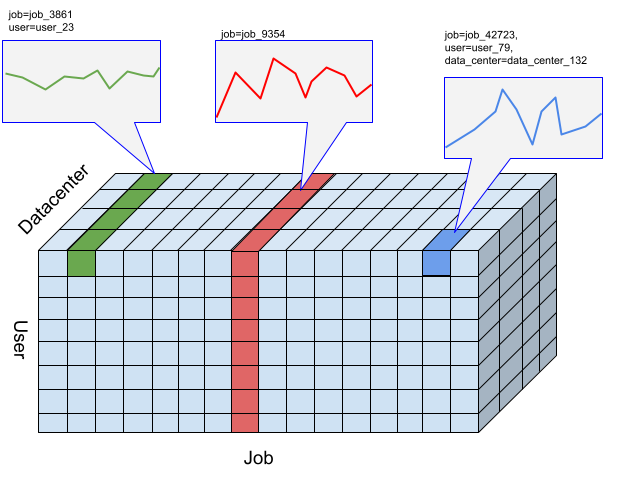
Timeseries Insights API の場合、スライスは、ディメンション値の特定の組み合わせを持つイベントの集合です。時間の経過とともにこれらのスライスに分類されるイベントの測定値に注目します。
特定のスライスについて、イベントは、ユーザーが指定した時間間隔の分解ごとに数値に集約されます。これは異常を検出する時系列です。上の図は、ディメンション「user」、「job」、「data_center」の異なる組み合わせから返されるスライスのさまざまな選択を示しています。
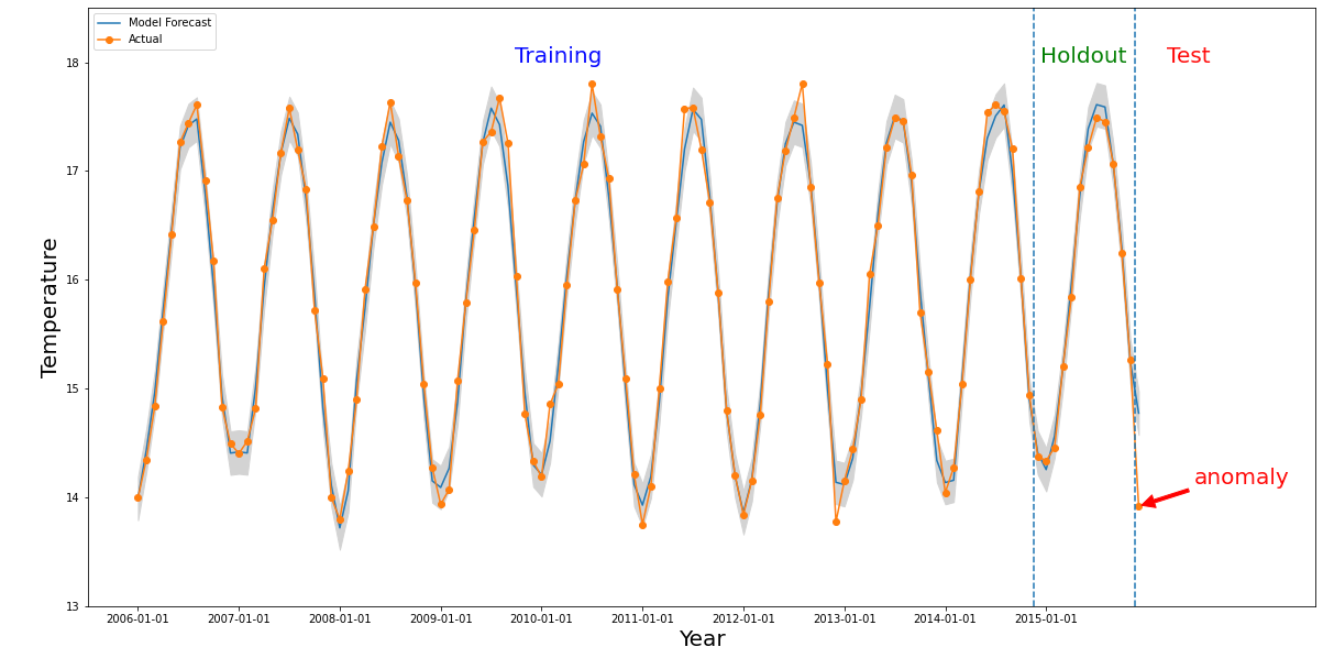
目的の時間間隔の数値が過去の値と大幅に異なる場合、特定のスライスで異常が発生します。上の図は、10 年間にわたって世界中で測定された気温に基づく時系列を示しています。2015 年の最後の月が異常な状態であるかどうかに関心があるとします。システムへのクエリでは、対象となる時刻 detectionTime を「2015/12/01」に、granularity を「1 か月」に指定しています。detectionTime より前に取得された時系列は、前のトレーニング期間と、その後のホールドアウト期間にパーティショニングされます。システムはトレーニング期間のデータを使用してモデルをトレーニングし、ホールドアウト期間を使用してモデルが次の値について信頼性のある予測を行えることを確認します。この例では、ホールドアウト期間は 1 年です。この図は、上限と下限のあるモデルの実際のデータと予測値を示しています。実際の値が予測範囲外であるため、2015/12 の気温は異常値としてマークされています。