Halaman ini menjelaskan layanan penemuan data sensitif. Layanan ini membantu Anda menentukan lokasi data sensitif dan berisiko tinggi di organisasi Anda.
Ringkasan
Layanan penemuan memungkinkan Anda melindungi data di seluruh organisasi dengan mengidentifikasi lokasi data sensitif dan berisiko tinggi. Saat Anda membuat konfigurasi pemindaian penemuan, Perlindungan Data Sensitif memindai resource Anda untuk mengidentifikasi data yang tercakup untuk pembuatan profil. Kemudian, Profiler akan membuat profil data Anda. Selama konfigurasi penemuan aktif, Sensitive Data Protection secara otomatis membuat profil data yang Anda tambahkan dan ubah. Anda dapat membuat profil data di seluruh organisasi, folder tertentu, dan project tertentu.
Setiap profil data adalah sekumpulan insight dan metadata yang dikumpulkan layanan penemuan dari pemindaian resource yang didukung. Insight mencakup infoTypes yang diprediksi dan risiko data yang dihitung serta tingkat sensitivitas data Anda. Gunakan insight ini untuk membuat keputusan yang tepat tentang cara Anda melindungi, membagikan, dan menggunakan data Anda.
Profil data dibuat dengan berbagai tingkat detail. Misalnya, saat Anda membuat profil data BigQuery, profil dibuat di tingkat project, tabel, dan kolom.
Gambar berikut menampilkan daftar profil data tingkat kolom. Klik gambar untuk memperbesarnya.

Untuk mengetahui daftar insight dan metadata yang disertakan dalam setiap profil data, lihat Referensi metrik.
Untuk mengetahui informasi selengkapnya tentang hierarki resource Google Cloud , lihat Hierarki resource.
Pembuatan profil data
Untuk mulai membuat profil data, Anda membuat konfigurasi pemindaian penemuan (juga disebut konfigurasi profil data). Konfigurasi pemindaian ini adalah tempat Anda menetapkan cakupan operasi penemuan dan jenis data yang ingin Anda buat profilnya. Dalam konfigurasi pemindaian, Anda dapat menyetel filter untuk menentukan subset data yang ingin Anda buat profilnya atau lewati. Anda juga dapat menyetel jadwal pembuatan profil.
Saat membuat konfigurasi pemindaian, Anda juga menetapkan template pemeriksaan yang akan digunakan. Template pemeriksaan adalah tempat Anda menentukan jenis data sensitif (juga disebut infoTypes) yang harus dipindai oleh Sensitive Data Protection.
Saat membuat profil data, Sensitive Data Protection menganalisis data Anda berdasarkan konfigurasi pemindaian dan template pemeriksaan.
Sensitive Data Protection membuat ulang profil data seperti yang dijelaskan dalam Frekuensi pembuatan profil data. Anda dapat menyesuaikan frekuensi pembuatan profil dalam konfigurasi pemindaian dengan membuat jadwal. Untuk memaksa layanan penemuan membuat ulang profil data Anda, lihat Memaksa operasi pembuatan ulang profil.
Jenis penemuan
Bagian ini menjelaskan jenis operasi penemuan yang dapat Anda lakukan dan resource data yang didukung.
Penemuan untuk BigQuery dan BigLake
Saat Anda membuat profil data BigQuery, profil data dibuat di tingkat project, tabel, dan kolom. Setelah membuat profil tabel BigQuery, Anda dapat menyelidiki lebih lanjut temuan dengan melakukan pemeriksaan mendalam.
Perlindungan Data Sensitif memprofilkan tabel yang didukung oleh BigQuery Storage Read API, termasuk berikut ini:
- Tabel BigQuery standar
- Snapshot tabel
- Tabel BigLake yang disimpan di Cloud Storage
Berikut ini tidak didukung:
- Tabel BigQuery Omni.
- Tabel dengan ukuran data berseri setiap baris melebihi ukuran data berseri maksimum yang didukung BigQuery Storage Read API—128 MB.
- Tabel eksternal non-BigLake, seperti Google Spreadsheet.
Untuk mengetahui informasi tentang cara memprofilkan data BigQuery, lihat artikel berikut:
- Membuat profil data BigQuery dalam satu project
- Membuat profil data BigQuery dalam organisasi atau folder
Untuk mengetahui informasi selengkapnya tentang BigQuery, lihat dokumentasi BigQuery.
Discovery untuk Cloud SQL
Saat Anda membuat profil data Cloud SQL, profil data akan dibuat di tingkat project, tabel, dan kolom. Sebelum penemuan dapat dimulai, Anda harus memberikan detail koneksi untuk setiap instance Cloud SQL yang akan diprofilkan.
Untuk mengetahui informasi tentang cara memprofilkan data Cloud SQL, lihat artikel berikut:
- Membuat profil data Cloud SQL dalam satu project
- Membuat profil data Cloud SQL dalam organisasi atau folder
Untuk mengetahui informasi selengkapnya tentang Cloud SQL, lihat dokumentasi Cloud SQL.
Penemuan untuk Cloud Storage
Saat Anda membuat profil data Cloud Storage, profil data akan dibuat di tingkat bucket. Sensitive Data Protection mengelompokkan file yang terdeteksi ke dalam cluster file dan memberikan ringkasan untuk setiap cluster.
Untuk mengetahui informasi tentang cara membuat profil data Cloud Storage, lihat berikut ini:
- Membuat profil data Cloud Storage dalam satu project
- Membuat profil data Cloud Storage dalam organisasi atau folder
Untuk mengetahui informasi selengkapnya tentang Cloud Storage, lihat dokumentasi Cloud Storage.
Discovery untuk Vertex AI
Saat Anda membuat profil set data Vertex AI, Perlindungan Data Sensitif akan membuat profil data penyimpanan file atau profil data tabel, bergantung pada tempat data pelatihan Anda disimpan: Cloud Storage atau BigQuery.
Untuk informasi selengkapnya, lihat referensi berikut:
- Penemuan data sensitif untuk Vertex AI
- Membuat profil data Vertex AI dalam satu project
- Membuat profil data Vertex AI dalam organisasi atau folder
Untuk mengetahui informasi selengkapnya tentang Vertex AI, lihat dokumentasi Vertex AI.
Penemuan untuk penyedia cloud lain
Saat Anda membuat profil data S3, profil data akan dibuat di tingkat bucket. Saat Anda membuat profil data Azure Blob Storage, profil data dibuat di tingkat kontainer.
Dalam kedua kasus tersebut, Sensitive Data Protection mengelompokkan file yang terdeteksi ke dalam cluster file dan memberikan ringkasan untuk setiap cluster.
Untuk informasi selengkapnya, lihat referensi berikut:
Variabel lingkungan Cloud Run
Layanan penemuan dapat mendeteksi keberadaan secret dalam fungsi Cloud Run dan variabel lingkungan revisi layanan Cloud Run, serta mengirimkan temuan apa pun ke Security Command Center. Tidak ada profil data yang dibuat.
Untuk mengetahui informasi selengkapnya, lihat Melaporkan secret dalam variabel lingkungan ke Security Command Center.
Peran yang diperlukan untuk mengonfigurasi dan melihat profil data
Bagian berikut mencantumkan peran pengguna yang diperlukan, yang dikategorikan menurut tujuannya. Bergantung pada cara penyiapan organisasi Anda, Anda dapat memutuskan untuk menugaskan orang yang berbeda untuk melakukan tugas yang berbeda. Misalnya, orang yang mengonfigurasi profil data mungkin berbeda dengan orang yang memantaunya secara rutin.
Peran yang diperlukan untuk menggunakan profil data di tingkat organisasi atau folder
Dengan peran ini, Anda dapat mengonfigurasi dan melihat profil data di tingkat organisasi atau folder.
Pastikan peran ini diberikan kepada orang yang tepat di tingkat organisasi. Atau, administrator Google Cloud Anda dapat membuat peran khusus yang hanya memiliki izin yang relevan.
| Tujuan | Peran bawaan | Izin yang relevan |
|---|---|---|
| Membuat konfigurasi pemindaian penemuan dan melihat profil data | DLP Administrator (roles/dlp.admin)
|
|
| Buat project yang akan digunakan sebagai container agen layanan1 | Project Creator (roles/resourcemanager.projectCreator) |
|
| Memberikan akses penemuan2 | Salah satu dari berikut ini:
|
|
| Melihat profil data (hanya baca) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
DLP Reader (roles/dlp.reader) |
|
1 Jika tidak memiliki peran Project
Creator (roles/resourcemanager.projectCreator), Anda tetap dapat membuat konfigurasi
pemindaian, tetapi penampung agen layanan yang Anda gunakan harus berupa project yang sudah ada.
2 Jika Anda tidak memiliki peran Administrator Organisasi (roles/resourcemanager.organizationAdmin) atau Admin Keamanan (roles/iam.securityAdmin), Anda tetap dapat membuat konfigurasi pemindaian. Setelah Anda
membuat konfigurasi pemindaian, seseorang di organisasi Anda yang memiliki salah satu peran ini harus memberikan akses penemuan ke
agen layanan.
Peran yang diperlukan untuk menggunakan profil data di tingkat project
Peran ini memungkinkan Anda mengonfigurasi dan melihat profil data di tingkat project.
Pastikan peran ini diberikan kepada orang yang tepat di tingkat project. Atau, administrator Google Cloud Anda dapat membuat peran khusus yang hanya memiliki izin yang relevan.
| Tujuan | Peran bawaan | Izin yang relevan |
|---|---|---|
| Mengonfigurasi dan melihat profil data | DLP Administrator (roles/dlp.admin)
|
|
| Melihat profil data (hanya baca) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
DLP Reader (roles/dlp.reader) |
|
Konfigurasi pemindaian penemuan
Konfigurasi pemindaian penemuan (terkadang disebut konfigurasi penemuan atau konfigurasi pemindaian) menentukan cara Perlindungan Data Sensitif harus memprofilkan data Anda. Setelan ini mencakup setelan berikut:
- Cakupan (organisasi, folder, atau project) operasi penemuan
- Jenis resource yang akan diprofilkan
- Template inspeksi yang dapat digunakan
- Frekuensi pemindaian
- Subkumpulan data tertentu yang harus disertakan dalam atau dikecualikan dari penemuan
- Tindakan yang Anda inginkan dilakukan oleh Sensitive Data Protection setelah penemuan—misalnya, layanan mana yang akan dipublikasikan profilnya Google Cloud
- Agen layanan yang akan digunakan untuk operasi penemuan
Untuk mengetahui informasi tentang cara membuat konfigurasi pemindaian penemuan, lihat halaman berikut:
Penemuan untuk data BigQuery
Penemuan data untuk Cloud SQL
Penemuan data Cloud Storage
Penemuan data untuk Vertex AI
Melaporkan rahasia dalam variabel lingkungan Cloud Run ke Security Command Center (tidak ada profil yang dibuat)
Cakupan konfigurasi pemindaian
Anda dapat membuat konfigurasi pemindaian di tingkat berikut:
- Organisasi
- Folder
- Project
- Satu resource data
Di tingkat organisasi dan folder, jika dua konfigurasi pemindaian aktif atau lebih memiliki project yang sama dalam cakupannya, Perlindungan Data Sensitif akan menentukan konfigurasi pemindaian mana yang dapat membuat profil untuk project tersebut. Untuk mengetahui informasi selengkapnya, lihat Mengganti konfigurasi pemindaian di halaman ini.
Konfigurasi pemindaian tingkat project selalu dapat memprofilkan project target dan tidak bersaing dengan konfigurasi lain di tingkat folder induk atau organisasi.
Konfigurasi pemindaian satu resource dimaksudkan untuk membantu Anda menjelajahi dan menguji pembuatan profil pada satu resource data.
Lokasi konfigurasi pemindaian
Saat pertama kali membuat konfigurasi pemindaian, Anda menentukan tempat yang Anda inginkan agar Perlindungan Data Sensitif menyimpannya. Semua konfigurasi pemindaian berikutnya yang Anda buat disimpan di region yang sama.
Misalnya, jika Anda membuat konfigurasi pemindaian untuk Folder A dan menyimpannya di region us-west1, maka konfigurasi pemindaian yang Anda buat untuk resource lain juga akan disimpan di region tersebut.
Metadata tentang data yang akan diprofilkan disalin ke region yang sama dengan konfigurasi pemindaian Anda, tetapi data itu sendiri tidak dipindahkan atau disalin. Untuk mengetahui informasi selengkapnya, lihat Pertimbangan residensi data.
Template inspeksi
Template pemeriksaan menentukan jenis informasi (atau infoType) yang dicari oleh Sensitive Data Protection saat memindai data Anda. Di sini, Anda memberikan kombinasi infoType bawaan dan infoType kustom opsional.
Anda juga dapat memberikan tingkat kemungkinan untuk mempersempit apa yang dianggap sebagai kecocokan oleh Sensitive Data Protection. Anda dapat menambahkan set aturan untuk mengecualikan temuan yang tidak diinginkan atau menyertakan temuan tambahan.
Secara default, jika Anda mengubah template pemeriksaan yang digunakan konfigurasi pemindaian, perubahan hanya diterapkan pada pemindaian mendatang. Tindakan Anda tidak menyebabkan operasi pembuatan ulang profil pada data Anda.
Jika Anda ingin perubahan template pemeriksaan memicu operasi pembuatan ulang profil pada data yang terpengaruh, tambahkan atau perbarui jadwal dalam konfigurasi pemindaian Anda, dan aktifkan opsi untuk membuat ulang profil data saat template pemeriksaan berubah. Untuk mengetahui informasi selengkapnya, lihat Frekuensi pembuatan profil data.
Anda harus memiliki template inspeksi di setiap region tempat Anda memiliki data yang akan
diprofilkan. Jika ingin menggunakan satu template untuk beberapa region, Anda dapat menggunakan template yang disimpan di region global. Jika kebijakan organisasi mencegah Anda membuat template inspeksi di region global, Anda harus menetapkan template inspeksi khusus untuk setiap region. Untuk mengetahui informasi selengkapnya, lihat Pertimbangan residensi data.
Template inspeksi adalah komponen inti dari platform Perlindungan Data Sensitif. Profil data menggunakan template pemeriksaan yang sama yang dapat Anda gunakan di semua layanan Perlindungan Data Sensitif. Untuk mengetahui informasi selengkapnya tentang template pemeriksaan, lihat Template.
Kontainer agen layanan dan agen layanan
Saat Anda membuat konfigurasi pemindaian untuk organisasi atau folder, Perlindungan Data Sensitif mengharuskan Anda menyediakan penampung agen layanan. Kontainer agen layanan adalah project Google Cloud yang digunakan Sensitive Data Protection untuk melacak biaya yang ditagih terkait operasi pembuatan profil tingkat organisasi dan folder.
Container agen layanan berisi agen layanan, yang digunakan Perlindungan Data Sensitif untuk membuat profil data atas nama Anda. Anda memerlukan agen layanan untuk mengautentikasi Sensitive Data Protection dan API lainnya. Agen layanan Anda harus memiliki semua izin yang diperlukan untuk mengakses dan membuat profil data Anda. ID agen layanan dalam format berikut:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
Di sini, PROJECT_NUMBER adalah ID numerik penampung agen layanan.
Saat menyetel penampung agen layanan, Anda dapat memilih project yang ada. Jika project yang Anda pilih berisi agen layanan, Sensitive Data Protection akan memberikan izin IAM yang diperlukan kepada agen layanan tersebut. Jika project tidak memiliki agen layanan, Sensitive Data Protection akan membuatnya dan otomatis memberikan izin pembuatan profil data kepadanya.
Atau, Anda dapat memilih agar Perlindungan Data Sensitif membuat container agen layanan dan agen layanan secara otomatis. Sensitive Data Protection otomatis memberikan izin pembuatan profil data kepada agen layanan.
Dalam kedua kasus tersebut, jika Sensitive Data Protection gagal memberikan akses pembuatan profil data ke agen layanan Anda, error akan ditampilkan saat Anda melihat detail konfigurasi pemindaian.
Untuk konfigurasi pemindaian tingkat project, Anda tidak memerlukan penampung agen layanan. Project yang Anda buat profilnya memenuhi tujuan penampung agen layanan. Untuk menjalankan operasi pembuatan profil, Sensitive Data Protection menggunakan agen layanan project tersebut.
Akses pembuatan profil data di tingkat organisasi atau folder
Saat Anda mengonfigurasi pembuatan profil di tingkat organisasi atau folder, Sensitive Data Protection akan mencoba memberikan akses pembuatan profil data secara otomatis kepada agen layanan Anda. Namun, jika Anda tidak memiliki izin untuk memberikan peran IAM, Perlindungan Data Sensitif tidak dapat melakukan tindakan ini atas nama Anda. Seseorang dengan izin tersebut di organisasi Anda, seperti administrator, harus memberikan akses pembuatan profil data kepada agen layanan Anda. Google Cloud
Frekuensi pembuatan profil data
Setelah Anda membuat konfigurasi pemindaian penemuan untuk resource tertentu, Sensitive Data Protection akan melakukan pemindaian awal, memprofilkan data dalam cakupan konfigurasi pemindaian Anda.
Setelah pemindaian awal, Sensitive Data Protection terus memantau resource yang diprofilkan. Data yang ditambahkan di resource akan otomatis diprofilkan segera setelah ditambahkan.
Frekuensi pembuatan profil ulang default
Frekuensi pembuatan profil ulang default berbeda-beda, bergantung pada jenis penemuan konfigurasi pemindaian Anda:
- Pembuatan profil BigQuery: untuk setiap tabel, tunggu 30 hari, lalu buat ulang profil tabel jika ada perubahan pada skema, baris tabel, atau template inspeksi.
- Pembuatan profil Cloud SQL: untuk setiap tabel, tunggu 30 hari, lalu buat ulang profil tabel jika ada perubahan pada skema atau template inspeksi.
- Pembuatan profil Vertex AI: untuk setiap set data, tunggu 30 hari, lalu buat ulang profil set data jika template inspeksi telah berubah.
Pembuatan profil penyimpanan file: untuk setiap penyimpanan file di Google Cloud atau di cloud lain, tunggu 30 hari, lalu buat ulang profil penyimpanan file jika template inspeksi memiliki perubahan.
Sensitive Data Protection menggunakan istilah penyimpanan file untuk merujuk ke bucket atau penampung penyimpanan file.
Menyesuaikan frekuensi pembuatan profil ulang
Dalam konfigurasi pemindaian, Anda dapat menyesuaikan frekuensi pembuatan profil ulang dengan membuat satu atau beberapa jadwal untuk berbagai subset data Anda.
Frekuensi pembuatan profil ulang berikut tersedia:
- Jangan membuat ulang profil: Jangan pernah membuat ulang profil setelah profil awal dibuat.
- Membuat ulang profil harian: Tunggu 24 jam sebelum membuat ulang profil.
- Membuat ulang profil mingguan: Tunggu 7 hari sebelum membuat ulang profil.
- Membuat ulang profil bulanan: Tunggu 30 hari sebelum membuat ulang profil.
Membuat ulang profil sesuai jadwal
Dalam konfigurasi pemindaian, Anda dapat menentukan apakah subset data harus diprofil ulang secara rutin, terlepas dari apakah data mengalami perubahan atau tidak. Frekuensi yang Anda tetapkan menentukan berapa banyak waktu yang harus berlalu di antara operasi pembuatan profil. Misalnya, jika Anda menetapkan frekuensi ke mingguan, Perlindungan Data Sensitif akan membuat profil resource data tujuh hari setelah terakhir kali dibuat profilnya.
Membuat ulang profil saat update
Dalam konfigurasi pemindaian, Anda dapat menentukan peristiwa yang dapat memicu operasi pembuatan ulang profil. Contoh peristiwa tersebut adalah update template inspeksi.
Saat Anda memilih peristiwa ini, jadwal yang Anda tetapkan akan menentukan waktu terlama yang dibutuhkan Sensitive Data Protection untuk menunggu pengumpulan pembaruan sebelum memprofilkan ulang data Anda. Jika tidak ada perubahan yang berlaku—seperti perubahan skema atau perubahan template pemeriksaan—dalam jangka waktu yang Anda tentukan, tidak ada data yang diprofilkan ulang. Saat perubahan berikutnya yang berlaku terjadi, data yang terpengaruh akan diprofilkan ulang pada kesempatan berikutnya, yang ditentukan oleh berbagai faktor (seperti kapasitas mesin yang tersedia atau unit langganan yang dibeli). Kemudian, Sensitive Data Protection akan mulai menunggu pembaruan terakumulasi lagi sesuai dengan jadwal yang Anda tetapkan.
Misalnya, konfigurasi pemindaian Anda disetel untuk membuat ulang profil setiap bulan saat terjadi perubahan skema. Profil data pertama kali dibuat pada hari ke-0. Tidak ada perubahan skema yang terjadi pada hari ke-30, sehingga tidak ada data yang diprofilkan ulang. Pada hari ke-35, perubahan skema pertama terjadi. Sensitive Data Protection akan membuat ulang profil data yang diperbarui pada kesempatan berikutnya. Kemudian, sistem akan menunggu 30 hari lagi agar update skema terakumulasi sebelum memprofilkan ulang data yang diperbarui.
Sejak pembuatan profil ulang dimulai, diperlukan waktu hingga 24 jam agar operasi selesai. Jika penundaan berlangsung lebih dari 24 jam dan Anda berada dalam mode harga langganan, konfirmasi apakah Anda memiliki kapasitas yang tersisa untuk bulan tersebut.
Untuk contoh skenario, lihat Contoh penghitungan harga pembuatan profil data.
Untuk memaksa layanan penemuan membuat ulang profil data Anda, lihat Memaksa operasi pembuatan ulang profil.
Membuat profil performa
Waktu yang diperlukan untuk membuat profil data Anda bervariasi bergantung pada beberapa faktor, termasuk, tetapi tidak terbatas pada, hal berikut:
- Jumlah resource data yang sedang diprofilkan
- Ukuran aset data
- Untuk tabel, jumlah kolom
- Untuk tabel, jenis data di kolom
Oleh karena itu, performa Perlindungan Data Sensitif dalam tugas pemeriksaan atau pembuatan profil sebelumnya tidak menunjukkan performanya dalam tugas pembuatan profil di masa mendatang.
Retensi profil data
Sensitive Data Protection menyimpan versi terbaru profil data selama 13 bulan. Saat membuat ulang profil resource data, sistem Perlindungan Data Sensitif akan mengganti profil resource data yang ada dengan profil baru.
Dalam contoh skenario berikut, asumsikan bahwa frekuensi pembuatan profil default untuk BigQuery berlaku:
Pada 1 Januari, Sensitive Data Protection membuat profil Tabel A. Tabel A tidak berubah selama lebih dari setahun, sehingga tidak diprofilkan lagi. Dalam hal ini, Sensitive Data Protection menyimpan profil data untuk Tabel A selama 13 bulan sebelum menghapusnya.
Pada 1 Januari, Sensitive Data Protection membuat profil Tabel A. Dalam bulan tersebut, seseorang di organisasi Anda memperbarui skema tabel tersebut. Karena perubahan ini, bulan berikutnya, Perlindungan Data Sensitif akan otomatis membuat ulang profil Tabel A. Profil data yang baru dibuat akan menggantikan profil yang dibuat pada bulan Januari.
Untuk mengetahui informasi tentang cara Perlindungan Data Sensitif menagih biaya data pembuatan profil, lihat Harga penemuan.
Jika Anda ingin menyimpan profil data tanpa batas waktu atau menyimpan catatan perubahan yang dialaminya, pertimbangkan untuk menyimpan profil data ke BigQuery saat Anda mengonfigurasi pembuatan profil. Anda memilih set data BigQuery tempat profil akan disimpan, dan Anda mengontrol kebijakan masa berlaku tabel untuk set data tersebut.
Mengganti konfigurasi pemindaian
Anda hanya dapat membuat satu konfigurasi pemindaian untuk setiap kombinasi cakupan dan jenis penemuan. Misalnya, Anda hanya dapat membuat satu konfigurasi pemindaian tingkat organisasi untuk pembuatan profil data BigQuery dan satu konfigurasi pemindaian tingkat organisasi untuk penemuan rahasia. Demikian pula, Anda hanya dapat membuat satu konfigurasi pemindaian tingkat project untuk pembuatan profil data BigQuery dan satu konfigurasi pemindaian tingkat project untuk penemuan rahasia.
Jika dua atau lebih konfigurasi pemindaian aktif memiliki project dan jenis penemuan yang sama dalam cakupannya, aturan berikut berlaku:
- Di antara konfigurasi pemindaian tingkat organisasi dan tingkat folder, konfigurasi yang paling dekat dengan project akan dapat menjalankan penemuan untuk project tersebut. Aturan ini berlaku meskipun konfigurasi pemindaian tingkat project dengan jenis penemuan yang sama juga ada.
- Sensitive Data Protection memperlakukan konfigurasi pemindaian tingkat project secara terpisah dari konfigurasi tingkat organisasi dan tingkat folder. Konfigurasi pemindaian yang Anda buat di level project tidak dapat menggantikan konfigurasi yang Anda buat untuk folder induk atau organisasi.
Pertimbangkan contoh berikut, yang memiliki tiga konfigurasi pemindaian aktif. Anggaplah semua konfigurasi pemindaian ini adalah untuk pembuatan profil data BigQuery.
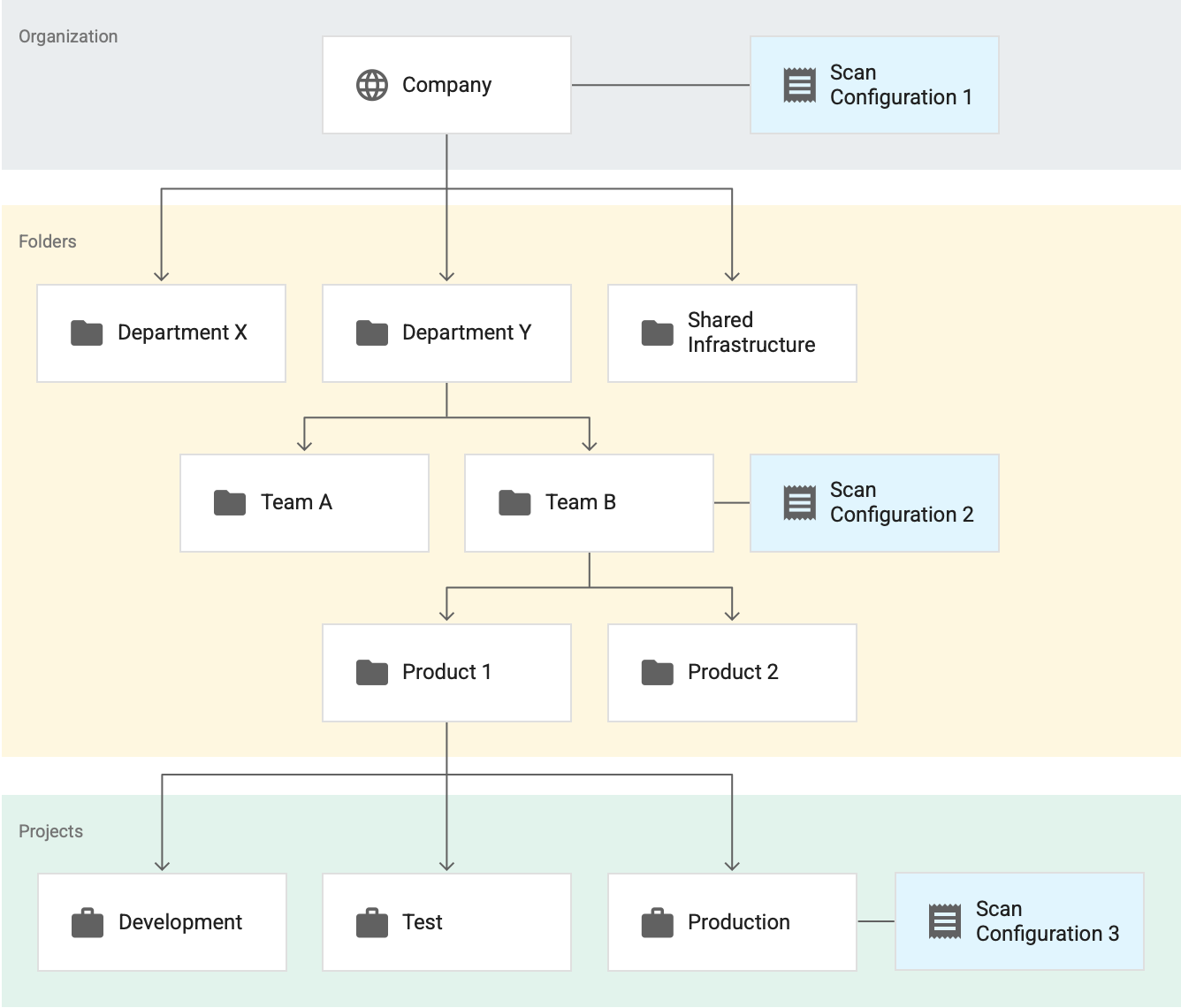
Di sini, Konfigurasi pemindaian 1 berlaku untuk seluruh organisasi, Konfigurasi pemindaian 2 berlaku untuk folder Tim B, dan Konfigurasi pemindaian 3 berlaku untuk project Produksi. Dalam contoh ini:
- Perlindungan Data Sensitif membuat profil semua tabel dalam project yang tidak ada di folder Team B sesuai dengan Konfigurasi pemindaian 1.
- Perlindungan Data Sensitif membuat profil semua tabel dalam project di folder Team B, termasuk tabel dalam project Production, sesuai dengan Konfigurasi pemindaian 2.
- Sensitive Data Protection membuat profil semua tabel dalam project Production sesuai dengan Konfigurasi pemindaian 3.
Dalam contoh ini, Perlindungan Data Sensitif menghasilkan dua set profil untuk project Production—satu set untuk setiap konfigurasi pemindaian berikut:
- Konfigurasi pemindaian 2
- Konfigurasi pemindaian 3
Namun, meskipun ada dua set profil untuk project yang sama, Anda tidak melihat semuanya bersama-sama di dasbor. Anda hanya melihat profil yang dibuat di resource—organisasi, folder, atau project—dan wilayah yang Anda lihat.
Untuk mengetahui informasi selengkapnya tentang hierarki resource Google Cloud', lihat Hierarki resource.
Snapshot profil data
Setiap profil data mencakup snapshot konfigurasi pemindaian dan template pemeriksaan yang digunakan untuk membuatnya. Anda dapat menggunakan snapshot ini untuk memeriksa setelan yang Anda gunakan untuk membuat profil data tertentu.
Pertimbangan residensi data
Pertimbangan residensi data berbeda-beda, bergantung pada apakah Anda memindaiGoogle Cloud data atau data dari penyedia cloud lain.
Pertimbangan residensi data untuk Google Cloud data
Bagian ini hanya berlaku untuk penemuan data sensitif untuk Google Cloud resource. Untuk pertimbangan residensi data yang terkait dengan resource dari penyedia cloud lain, lihat Pertimbangan residensi data untuk data dari penyedia cloud lain di halaman ini.
Sensitive Data Protection dirancang untuk mendukung residensi data. Jika Anda harus mematuhi persyaratan residensi data, pertimbangkan poin-poin berikut:
Template inspeksi regional
Bagian ini hanya berlaku untuk penemuan data sensitif untuk Google Cloud resource. Untuk pertimbangan residensi data yang terkait dengan resource dari penyedia cloud lain, lihat Pertimbangan residensi data untuk data dari penyedia cloud lain di halaman ini.
Sensitive Data Protection memproses data Anda di region yang sama dengan tempat data tersebut disimpan. Artinya, data Anda tidak akan keluar dari regionnya saat ini.
Selain itu, template inspeksi hanya dapat digunakan untuk membuat profil data yang berada di region yang sama dengan template tersebut. Misalnya, jika Anda mengonfigurasi penemuan untuk menggunakan template inspeksi yang disimpan di region us-west1, Sensitive Data Protection hanya dapat membuat profil data di region tersebut.
Anda dapat
menetapkan template inspeksi khusus
untuk setiap wilayah tempat Anda memiliki data.
Jika Anda memberikan template pemeriksaan yang disimpan di region global, Sensitive Data Protection akan menggunakan template tersebut untuk data di region yang tidak memiliki template pemeriksaan khusus.
Tabel berikut memberikan contoh skenario:
| Skenario | Dukungan |
|---|---|
Pindai data di region us menggunakan template inspeksi dari
region us. |
Didukung |
Memindai data di region global menggunakan template pemeriksaan
dari region us. |
Tidak didukung |
Pindai data di region us menggunakan template inspeksi dari region global. |
Didukung |
Pindai data di region us menggunakan template pemeriksaan dari
region us-east1. |
Tidak didukung |
Memindai data di region us-east1 menggunakan template pemeriksaan
dari region us. |
Tidak didukung |
Pindai data di region us menggunakan template inspeksi dari region asia. |
Tidak didukung |
Konfigurasi profil data
Bagian ini hanya berlaku untuk penemuan data sensitif untuk Google Cloud resource. Untuk pertimbangan residensi data yang terkait dengan resource dari penyedia cloud lain, lihat Pertimbangan residensi data untuk data dari penyedia cloud lain di halaman ini.
Saat membuat profil data, Perlindungan Data Sensitif mengambil snapshot konfigurasi pemindaian dan template pemeriksaan Anda, lalu menyimpannya di setiap profil data tabel atau profil data penyimpanan file.
Jika Anda mengonfigurasi penemuan untuk menggunakan template inspeksi dari region global, maka Perlindungan Data Sensitif akan menyalin template tersebut ke region mana pun yang memiliki data untuk diprofilkan. Demikian pula, konfigurasi pemindaian akan disalin ke region tersebut.
Pertimbangkan contoh ini: Project A berisi Tabel 1. Tabel 1 berada di region us-west1; konfigurasi pemindaian berada di region us-west2; dan template pemeriksaan berada di region global.
Saat memindai Project A, Sensitive Data Protection membuat profil data untuk
Tabel 1 dan menyimpannya di region us-west1. Profil data tabel 1
berisi salinan konfigurasi pemindaian dan template pemeriksaan yang digunakan dalam
operasi pembuatan profil.
Jika Anda tidak ingin template inspeksi Anda disalin ke wilayah lain, jangan konfigurasi Perlindungan Data Sensitif untuk memindai data di wilayah tersebut.
Penyimpanan profil data regional
Bagian ini hanya berlaku untuk penemuan data sensitif untuk Google Cloud resource. Untuk pertimbangan residensi data yang terkait dengan resource dari penyedia cloud lain, lihat Pertimbangan residensi data untuk data dari penyedia cloud lain di halaman ini.
Sensitive Data Protection memproses data Anda di region atau multi-region tempat data tersebut berada dan menyimpan profil data yang dihasilkan di region atau multi-region yang sama.
Untuk melihat profil data di konsol Google Cloud , Anda harus memilih region tempat profil data berada terlebih dahulu. Jika Anda memiliki data di beberapa region, Anda harus beralih region untuk melihat setiap set profil.
Wilayah yang tidak didukung
Bagian ini hanya berlaku untuk penemuan data sensitif untuk Google Cloud resource. Untuk pertimbangan residensi data yang terkait dengan resource dari penyedia cloud lain, lihat Pertimbangan residensi data untuk data dari penyedia cloud lain di halaman ini.
Jika Anda memiliki data di region yang tidak didukung oleh Sensitive Data Protection, layanan penemuan akan melewati resource data tersebut dan menampilkan error saat Anda melihat profil data.
Multi-region
Sensitive Data Protection memperlakukan multi-region sebagai satu region, bukan kumpulan region. Misalnya, multi-region us dan region us-west1 diperlakukan sebagai dua region terpisah sejauh menyangkut residensi data.
Resource zona
Sensitive Data Protection adalah layanan regional dan multi-regional; layanan ini tidak membedakan antara zona. Untuk resource zonal yang didukung seperti instance Cloud SQL, data diproses di region saat ini, tetapi tidak harus di zona saat ini. Misalnya, jika instance Cloud SQL
disimpan di zona us-central1-a, Perlindungan Data Sensitif
memproses dan menyimpan profil data di region us-central1.
Untuk informasi umum tentang Google Cloud lokasi, lihat Geografi dan wilayah.
Pertimbangan residensi data untuk data dari penyedia cloud lain
Pertimbangkan hal berikut saat Anda berencana membuat profil data dari penyedia cloud lain:
- Profil data disimpan bersama konfigurasi pemindaian penemuan. Sebaliknya, saat Anda membuat profil Google Cloud data, profil disimpan di region yang sama dengan data yang akan dibuat profilnya.
- Jika Anda menyimpan template inspeksi di region
global, salinan template dalam memori tersebut akan dibaca di region tempat Anda menyimpan konfigurasi pemindaian penemuan. - Data Anda tidak diubah. Salinan data dalam memori Anda dibaca di region tempat Anda menyimpan konfigurasi pemindaian penemuan. Namun, Perlindungan Data Sensitif tidak memberikan jaminan tentang tempat data melewati setelah mencapai internet publik. Data dienkripsi dengan SSL.
Kepatuhan
Untuk mengetahui informasi tentang cara Perlindungan Data Sensitif menangani data Anda dan membantu Anda memenuhi persyaratan kepatuhan, lihat Keamanan data.
Langkah berikutnya
Baca postingan blog Identity & Security Pengelolaan risiko data otomatis untuk BigQuery menggunakan Perlindungan Data Sensitif.
Pelajari cara memperkirakan biaya pembuatan profil data.
Pelajari cara membuat profil data di tingkat organisasi, folder, atau project.
Pelajari cara Perlindungan Data Sensitif menghitung risiko data dan tingkat sensitivitas saat membuat profil data Anda.
Pelajari cara memperbaiki temuan penemuan.
Pelajari cara memecahkan masalah terkait profiler data.