k-匿名性は、データセットのレコードの再識別可能性を示すプロパティです。データセット内の各人物の準識別子が、データセット内の少なくとも k - 1 人の他の人物と同一である場合、そのデータセットは k-匿名性を持っています。
k-匿名性の値は、データセットの 1 つ以上の列またはフィールドに基づいて計算できます。このトピックでは、機密データの保護を使用してデータセットの k-匿名性の値を計算する方法について説明します。k-匿名性またはリスク分析の概要については、続行する前に、リスク分析のコンセプトのトピックをご覧ください。
はじめる前に
続行する前に、以下を行ってください。
- Google アカウントにログインします。
- Google Cloud コンソールのプロジェクト セレクタページで、 Google Cloud プロジェクトを選択または作成します。 プロジェクト セレクタに移動
- Google Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトに対して課金が有効になっていることを確認する方法を学習する。
- Sensitive Data Protection を有効にします。 機密データの保護を有効にする
- 分析する BigQuery データセットを選択します。機密データの保護は、BigQuery テーブルをスキャンして k-匿名性指標を計算します。
- データセット内の識別子(該当する場合)と 1 つ以上の準識別子を決定します。詳細については、リスク分析の用語と手法をご覧ください。
k-匿名性の計算
機密データの保護によるリスク分析は、リスク分析ジョブの実行時に行われます。最初に、Google Cloud コンソールを使用するか、DLP API リクエストを送信するか、Sensitive Data Protection クライアント ライブラリを使用してジョブを作成する必要があります。
コンソール
Google Cloud コンソールで、[リスク分析の作成] ページに移動します。
[入力データを選択] セクションで、テーブルを含むプロジェクトのプロジェクト ID、テーブルのデータセット ID、およびテーブルの名前を入力して、スキャンする BigQuery テーブルを指定します。
[計算するプライバシー指標] で [k-匿名性] を選択します。
(省略可)[ジョブ ID] セクションからジョブにカスタム識別子を指定して、機密データの保護がデータを処理するリソースの場所を選択します。完了したら、[続行] をクリックします。
[フィールドの定義] セクションで、k-匿名性リスクジョブの識別子と準識別子を指定します。機密データの保護は、前の手順で指定した BigQuery テーブルのメタデータにアクセスし、フィールドのリストへの入力を試みます。
- 該当するチェックボックスをオンにして、フィールドを識別子(ID)または準識別子(QI)として指定します。0 または 1 つの識別子と、1 つ以上の準識別子を選択する必要があります。
- 機密データの保護でフィールドに入力できない場合は、[フィールド名を入力] をクリックして 1 つ以上のフィールドを手動で入力し、各フィールドを識別子または準識別子として設定します。完了したら、[続行] をクリックします。
(省略可)[アクションの追加] セクションで、リスクジョブが完了したときに実行するアクションを追加します。使用できるオプションは次のとおりです。
- BigQuery に保存: リスク分析のスキャン結果を BigQuery テーブルに保存します。
Pub/Sub に公開: 通知を Pub/Sub トピックに公開します。
メールで通知: 結果が記載されたメールを送信します。完了したら、[作成] をクリックします。
k-匿名性リスク分析ジョブがすぐに開始されます。
C#
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Go
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Java
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
PHP
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
REST
k-匿名性を計算するための新しいリスク分析ジョブを実行するには、projects.dlpJobs リソースにリクエストを送信します。ここで、PROJECT_ID はプロジェクト識別子を示します。
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
このリクエストには、次の項目で構成される RiskAnalysisJobConfig オブジェクトが含まれます。
PrivacyMetricオブジェクト。ここでKAnonymityConfigオブジェクトを含めることで、k-匿名性を計算することを指定します。BigQueryTableオブジェクト。次のすべてを含めることで、スキャンする BigQuery テーブルを指定します。projectId: テーブルを含むプロジェクトのプロジェクト ID。datasetId: テーブルのデータセット ID。tableId: テーブルの名前。
1 つ以上の
Actionオブジェクトのセット。これは、ジョブの完了時に所定の順序で実行するアクションを表します。各Actionオブジェクトには、次のいずれかのアクションを含めることができます。SaveFindingsオブジェクト: リスク分析のスキャン結果を BigQuery テーブルに保存します。PublishToPubSubオブジェクト: 通知を Pub/Sub トピックに公開します。JobNotificationEmailsオブジェクト: 結果が記載されたメールを送信します。
KAnonymityConfigオブジェクト内で、次の項目を指定します。quasiIds[]: k-匿名性を計算するためにスキャンして使用する、1 つ以上の準識別子(FieldIdオブジェクト)。複数の準識別子を指定すると、単一の複合キーとみなされます。構造体と繰り返しデータ型はサポートされていませんが、ネストされたフィールドは、それ自体が構造体ではなく、繰り返しフィールド内でネストされている限り、サポートされます。entityId: 省略可能な識別子値。これを設定した場合、個々のentityIdに対応する各行をすべてグループにまとめて k-匿名性を計算することを示します。通常、entityIdはお客様 ID やユーザー ID などの一意のユーザーを表す列になります。それぞれ異なる準識別子の値を持つentityIdが複数の行に存在する場合、その行を結合して 1 つのマルチセットが作成され、そのエンティティの準識別子として使用されます。エンティティ ID の詳細については、リスク分析の概念のトピックにあるエンティティ ID と k-匿名性の計算をご覧ください。
DLP API にリクエストを送信するとすぐに、リスク分析ジョブが開始されます。
計算済みのリスク分析ジョブを一覧表示する
現在のプロジェクトで実行済みのリスク分析ジョブを一覧表示できます。
コンソール
Google Cloud コンソールで実行中および実行済みのリスク分析ジョブを一覧表示するには:
Google Cloud コンソールで、Sensitive Data Protection を開きます。
ページ上部の [ジョブとジョブトリガー] タブをクリックします。
[リスクジョブ] タブをクリックします。
リスクジョブの一覧が表示されます。
プロトコル
実行中および実行済みのリスク分析ジョブを一覧表示するには、GET リクエストを projects.dlpJobs リソースに送信します。ジョブタイプ フィルタ(?type=RISK_ANALYSIS_JOB)を追加すれば、リスク分析ジョブのみにレスポンスを絞り込むことができます。
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
受信するレスポンスには、現在および以前のすべてのリスク分析ジョブの JSON 表現が含まれます。
k-匿名性ジョブの結果を表示する
Google Cloud コンソールの機密データの保護には、完了した k-匿名性ジョブを可視化できる機能が組み込まれています。前のセクションの指示に沿って、リスク分析ジョブの一覧から、結果を表示するジョブを選択します。ジョブが正常に実行されると、[リスク分析の詳細] ページの上部が以下のようになります。
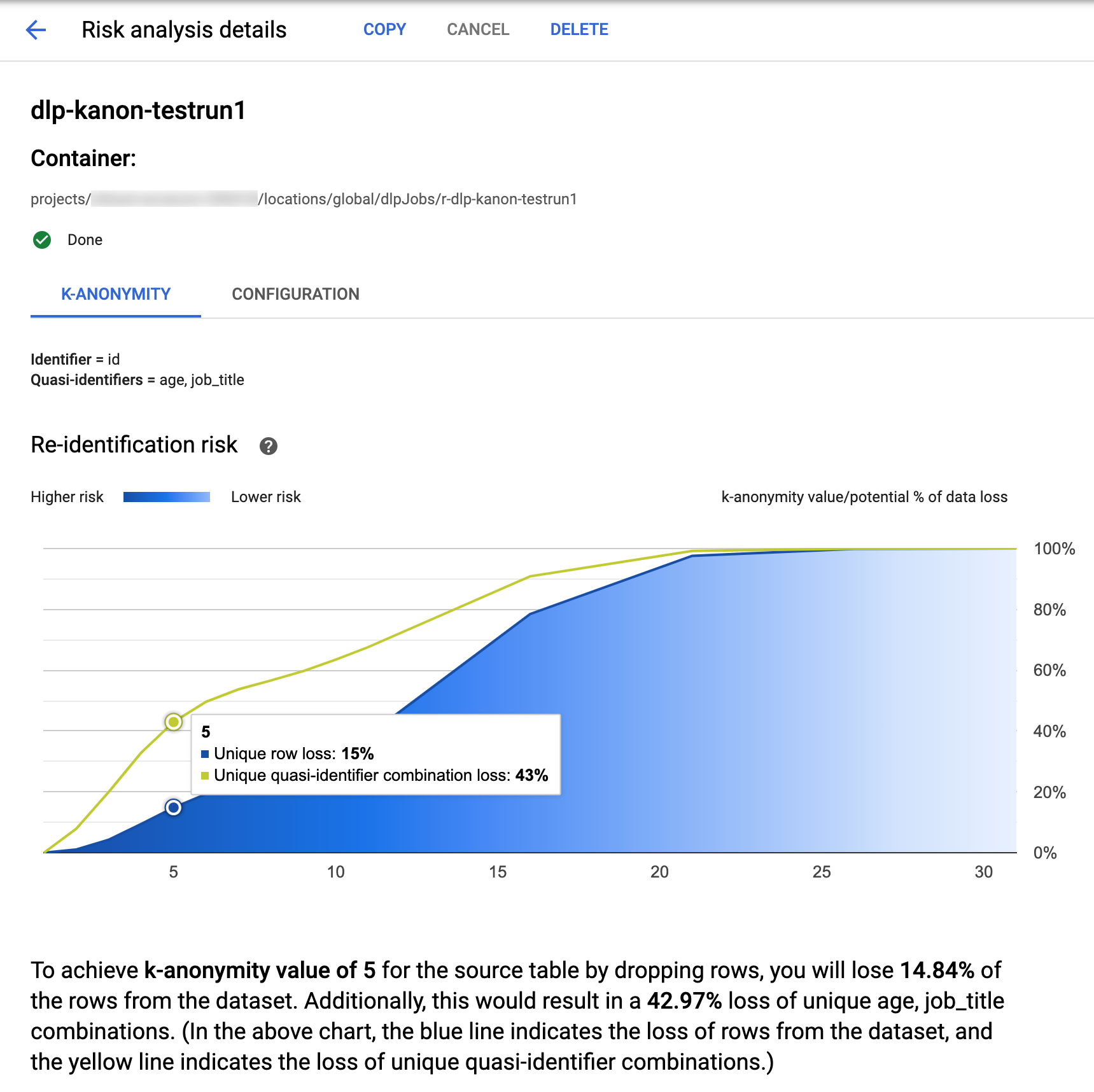
ページの上部には、k-匿名性リスクジョブに関する情報があります。これには、ジョブ ID とコンテナの下のリソースの場所が含まれます。
k-匿名性の計算結果を表示するには、[K-匿名性] タブをクリックします。リスク分析ジョブの構成を表示するには、[構成] タブをクリックします。
[K-匿名性] タブには、最初にエンティティ ID(ある場合)と k-匿名性の計算に使用される準識別子が一覧表示されます。
リスク チャート
再識別リスクチャートは、特定の行と準識別子の組み合わせでデータが失われる可能性(%)を y 軸とし、k-匿名性の値を x 軸としてプロットしたグラフです。グラフの色はリスクの高さを示しています。濃い青色はリスクが高いことを示し、薄い青色はリスクが低いことを示しています。
k-匿名性の値が高いほど、再識別リスクは低くなります。ただし、より高い k-匿名性の値を実現するためには、行や一意の準識別子の組み合わせをより多く削除する必要があり、これによりデータの有用性が低下する可能性があります。グラフにカーソルを合わせると、その k-匿名性の値に対応するデータ損失の可能性(%)の具体的な値を確認できます。スクリーンショットに示されているように、ツールチップがグラフに表示されます。
特定の k-匿名性の値の詳細を表示するには、対応するデータポイントをクリックします。グラフの下に詳細な説明が表示され、ページの下にサンプル データテーブルが表示されます。
リスクのサンプル データテーブル
リスクジョブの結果ページの 2 番目のコンポーネントは、サンプル データテーブルです。これは、k-匿名性のターゲット値の準識別子の組み合わせを表示します。
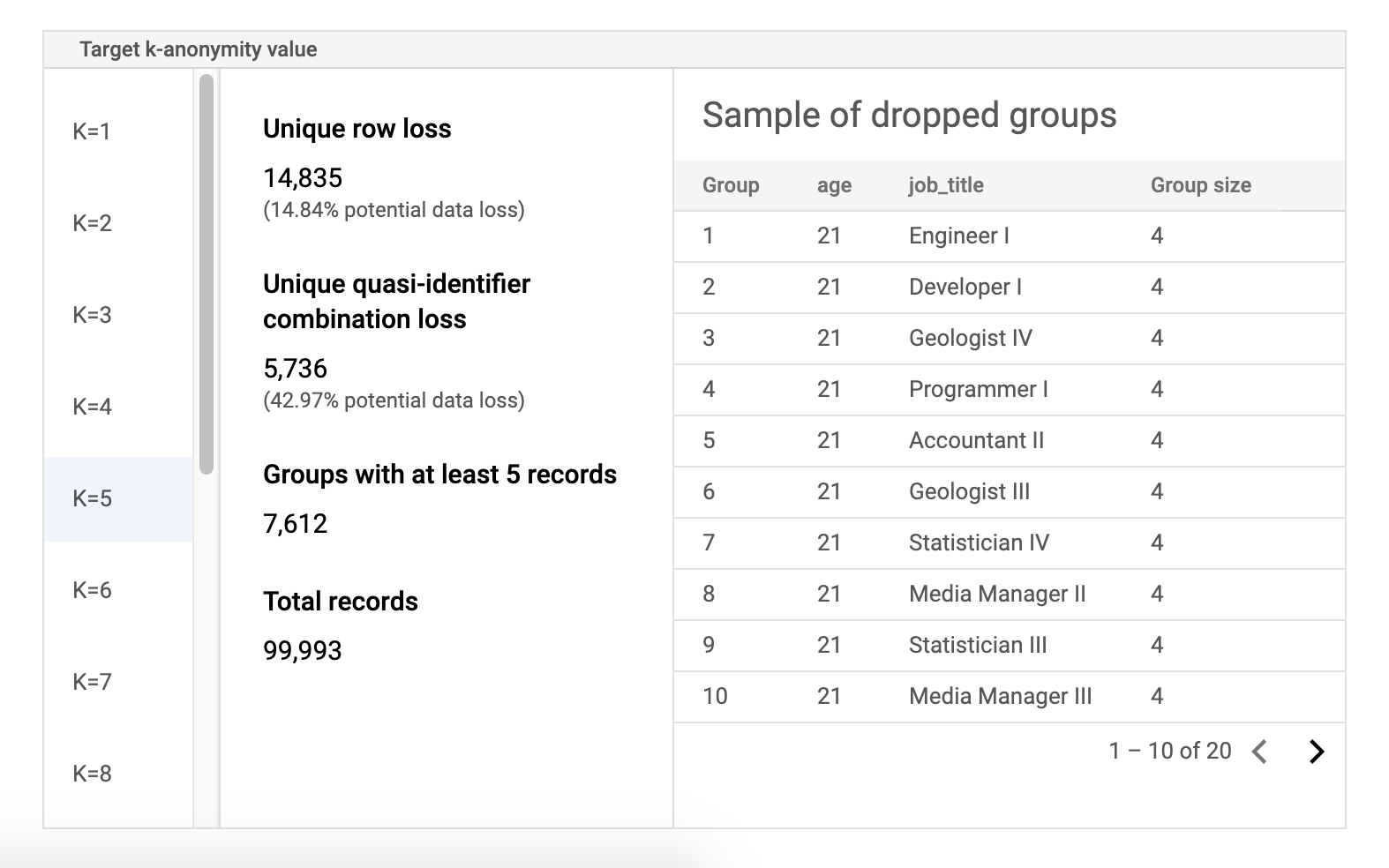
テーブルの最初の列には、k-匿名性の値が一覧表示されます。k-匿名性の値をクリックすると、その値を達成するために破棄する必要がある、対応するサンプルデータが表示されます。
2 番目の列には、特定の行と準識別子の組み合わせにおけるデータ損失の可能性、少なくとも k 個のレコードを持つグループの数、レコードの合計数が表示されます。
最後の列には、準識別子の組み合わせを共有するグループのサンプルと、その組み合わせで存在するレコードの数が表示されます。
REST を使用してジョブの詳細を取得する
REST API を使用して k-匿名性のリスク分析ジョブの結果を取得するには、次の GET リクエストを projects.dlpJobs リソースに送信します。PROJECT_ID はプロジェクト ID に、JOB_ID は結果を取得するジョブの識別子に置き換えます。ジョブ ID は、ジョブの開始時に返されています。また、すべてのジョブの一覧表示して取得することもできます。
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
リクエストは、ジョブのインスタンスを含む JSON オブジェクトを返します。分析結果は、AnalyzeDataSourceRiskDetails オブジェクトの "riskDetails" キーにあります。詳細については、DlpJob の API リファレンスをご覧ください。
コードサンプル: エンティティ ID を使用して k-匿名性を計算する
この例では、エンティティ ID を使用して k-匿名性を計算するリスク分析ジョブを作成します。
エンティティ ID の詳細については、エンティティ ID と k-匿名性の計算をご覧ください。
C#
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Go
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Java
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
PHP
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
機密データの保護用のクライアント ライブラリをインストールして使用する方法については、機密データの保護のクライアント ライブラリをご覧ください。
機密データの保護のために認証するには、アプリケーションのデフォルト認証情報を設定します。 詳細については、ローカル開発環境の認証の設定をご覧ください。