機密データの保護は、インフラストラクチャ内に存在する機密データの検出、理解、管理を支援します。機密データの保護でコンテンツから機密データをスキャンしたら、そのデータ インテリジェンスをどのように使用するかについていくつかのオプションがあります。このトピックでは、BigQuery、Cloud SQL、Looker Studio などの他の機能を使用して、次のことを行う方法を説明します。 Google Cloud
- 機密データの保護のスキャン結果を BigQuery に直接保存する。
- インフラストラクチャ内で機密データが存在する場所をレポートで報告する。
- 高度な SQL 分析を行い、機密データの種類と保存場所を特定する。
- 調査結果に基づいて、アラートまたはトリガーするアクションを自動化する。
このトピックでは、サンプルを示しながら、機密データの保護と他の Google Cloud 機能を組み合わせてこれらの作業を行う方法を説明します。
ストレージ バケットをスキャンする
まず、データをスキャンします。機密データの保護を使用してストレージ リポジトリをスキャンする方法について、基本的な情報を次に示します。クライアント ライブラリの使用を含む、ストレージ リポジトリのスキャンの手順については、ストレージとデータベースに含まれる機密データの検査をご覧ください。
Google Cloud ストレージ リポジトリでスキャン オペレーションを実行するため、次の構成オブジェクトを含む JSON オブジェクトを作成します。
InspectJobConfig: 機密データの保護のスキャンジョブを構成します。次の項目が含まれています。StorageConfig: スキャンするストレージ リポジトリ。InspectConfig: スキャンの方法と対象。検査テンプレートを使用して検査構成を定義することもできます。Action: ジョブの完了時に実行されるタスク。結果を BigQuery テーブルに保存する、通知を Pub/Sub に公開するといったタスクがあります。
この例では、Cloud Storage バケットで人名、電話番号、米国社会保障番号、メールアドレスをスキャンし、調査結果を機密データの保護の出力専用の BigQuery テーブルに送信します。次の JSON では、ファイルへ保存するか、DlpJob 機密データの保護リソースの create メソッドに直接送信できます。
JSON 入力:
POST https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs
{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"includeQuote":true
},
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
スキャンを再帰的に行うため、Cloud Storage のバケット アドレス(gs://[BUCKET_NAME]/**)の後にアスタリスク(**)を 2 個付けています。アスタリスクを 1 個(*)付けると、ジョブは指定されたディレクトリ レベルのみをスキャンし、それ以上はスキャンしません。
出力は、所定のデータセットとプロジェクト内の、指定されたテーブルに保存されます。所定のテーブル ID を指定する後続のジョブは、結果を同じテーブルに追加します。スキャンが実行されるたびに新しいテーブルを作成するように機密データの保護に指示する場合は、"tableId" キーを省略することもできます。
この JSON を含むリクエストを、指定された URL 経由で projects.dlpJobs.create メソッドに送信した後、次のレスポンスが返されます。
JSON 出力:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"PENDING",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
},
"createTime":"2018-11-19T21:09:07.926Z"
}
ジョブが完了すると、結果は所定の BigQuery テーブルに保存されます。
ジョブのステータスを取得するには、projects.dlpJobs.get メソッドを呼び出すか、次の URL に GET リクエストを送信します。[PROJECT_ID] はプロジェクト ID で置き換え、[JOB_ID] はジョブ作成リクエストに対する Cloud Data Loss Prevention API のレスポンス(ジョブ識別子の前に「i-」が付く)で指定された識別子に置き換えます。
GET https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs/[JOB_ID]
先ほど作成したジョブの場合、このリクエストによって次の JSON が返されます。スキャン結果は検査の概要の後に返されています。スキャンがまだ完了していない場合、"state" キーは "RUNNING" を示します。
JSON 出力:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
},
"result":{
"processedBytes":"536734051",
"totalEstimatedBytes":"536734051",
"infoTypeStats":[
{
"infoType":{
"name":"PERSON_NAME"
},
"count":"269679"
},
{
"infoType":{
"name":"EMAIL_ADDRESS"
},
"count":"256"
},
{
"infoType":{
"name":"PHONE_NUMBER"
},
"count":"7"
}
]
}
},
"createTime":"2018-11-19T21:09:07.926Z",
"startTime":"2018-11-19T21:10:20.660Z",
"endTime":"2018-11-19T22:07:39.725Z"
}
BigQuery で分析を行う
これで機密データの保護のスキャン結果を含む新しい BigQuery テーブルが作成されました。では、このテーブルに対して分析を行ってみましょう。
Google Cloud コンソールの左側の [ビッグデータ] の下にある [BigQuery] をクリックします。プロジェクトとデータセットを開き、作成された新しいテーブルを確認します。
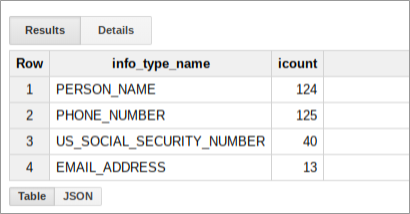
このテーブルに SQL クエリを実行して、機密データの保護がデータバケットで検出した内容を詳しく調べます。たとえば、次のクエリを実行して、infoType 別のスキャン結果数を確認します。プレースホルダは実際の値に置き換えます。
SELECT
info_type.name,
COUNT(*) AS iCount
FROM
`[PROJECT_ID].[DATASET_ID].[TABLE_ID]`
GROUP BY
info_type.name
このクエリを実行すると、次のようにバケットの調査結果の概要が表示されます。
Looker Studio でレポートを作成する
Looker Studio を使用すると、BigQuery テーブルに基づいてカスタム レポートを作成できます。このセクションでは、BigQuery に保存されている機密データの検出結果に基づいて、Looker Studio で簡単なテーブル レポートを作成します。
- Looker Studio を開き、新しいレポートを作成します。
- [新しいデータソースを作成] をクリックします。
- コネクタのリストから [BigQuery] をクリックします。必要に応じて、[承認] をクリックして、Looker Studio から BigQuery プロジェクトへの接続を承認します。
- 検索するテーブルを選択し、プロジェクトが存在する場所に応じて [マイ プロジェクト] または [共有プロジェクト] をクリックします。ページに表示されたリストで、プロジェクト、データセット、テーブルを探します。
- [接続] をクリックして、レポートを実行します。
- [レポートに追加] をクリックします。
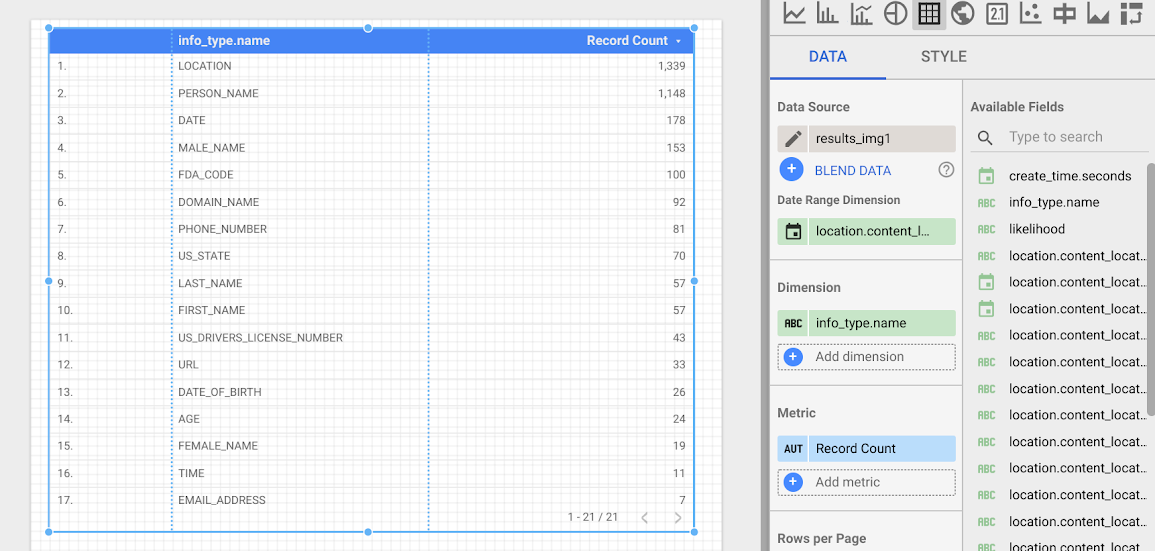
次に、各 infoType の頻度を表すテーブルを作成します。[ディメンション] として info_type.name フィールドを選択します。結果の表は次のようになります。
次のステップ
これは、Looker Studio と機密データの保護の出力を使用して可視化できることの 1 つにすぎません。他のチャート要素やドリルダウン フィルタを追加して、ダッシュボードとレポートを作成できます。Looker Studio で使用できる機能の詳細については、Looker Studio サービスの概要をご覧ください。