Wenn Sie den Dienst zur Erkennung vertraulicher Daten so konfiguriert haben, dass alle erfolgreich generierten Datenprofile an BigQuery gesendet werden, können Sie diese Datenprofile abfragen, um Informationen zu Ihren Daten zu erhalten. Sie können auch Visualisierungstools wie Looker Studio verwenden, um benutzerdefinierte Berichte zu erstellen, die auf Ihre geschäftlichen Anforderungen zugeschnitten sind. Alternativ können Sie einen vorgefertigten Bericht verwenden, den Sensitive Data Protection bereitstellt, ihn anpassen und nach Bedarf freigeben.
Auf dieser Seite finden Sie Beispiel-SQL-Abfragen, mit denen Sie mehr über Ihre Datenprofile erfahren können. Außerdem wird gezeigt, wie Sie Datenprofile in Looker Studio visualisieren können.
Weitere Informationen zu Datenprofilen finden Sie unter Datenprofile.
Hinweise
Auf dieser Seite wird davon ausgegangen, dass Sie die Profilerstellung auf Organisations-, Ordner- oder Projektebene konfiguriert haben. Achten Sie darauf, dass in Ihrer Konfiguration für den Ermittlungsscan die Aktion Datenprofilkopien in BigQuery speichern aktiviert ist. Weitere Informationen zum Erstellen einer Erkennungsscankonfiguration finden Sie unter Scankonfiguration erstellen.
In diesem Dokument wird die Tabelle, die die exportierten Datenprofile enthält, als Ausgabetabelle bezeichnet.
Halten Sie die Projekt-ID, die Dataset-ID und die Tabellen-ID der Ausgabetabelle bereit. Sie benötigen sie, um die Verfahren auf dieser Seite auszuführen.
Ansicht latest
Wenn Sensitive Data Protection Datenprofile in Ihre Ausgabetabelle exportiert, wird auch die latest-Ansicht erstellt. Diese Ansicht ist eine vorab gefilterte virtuelle Tabelle, die nur die neuesten Snapshots Ihrer Datenprofile enthält. Die Ansicht latest hat dasselbe Schema wie die Ausgabetabelle. Sie können die beiden also in Ihren SQL-Abfragen und Looker Studio-Berichten austauschbar verwenden. Die Ergebnisse können sich unterscheiden, da die Ausgabetabelle ältere Snapshots der Datenprofile enthält.
Die latest-Ansicht wird am selben Ort wie die Ausgabetabelle gespeichert. Der Name hat das folgende Format:
OUTPUT_TABLE_latest_VERSION
Ersetzen Sie Folgendes:
- OUTPUT_TABLE: die ID der Tabelle, die die exportierten Datenprofile enthält.
- VERSION: die Versionsnummer der Ansicht.
Wenn die Ausgabetabelle beispielsweise den Namen table-profile hat, hat die Ansicht latest einen Namen wie table-profile_latest_v1.

Wenn Sie die Ansicht latest in SQL-Abfragen verwenden, geben Sie den vollständigen Namen der Ansicht an, der die Projekt-ID, Dataset-ID, Tabellen-ID und das Suffix enthält, z. B. myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Zwischen der Ausgabetabelle und der latest-Ansicht wählen
Die Ansicht latest enthält nur die neuesten Datenprofil-Snapshots, während die Ausgabetabelle alle Datenprofil-Snapshots enthält, auch veraltete. Eine Abfrage für die Ausgabetabelle kann beispielsweise mehrere Spaltendatenprofile für dieselbe Spalte zurückgeben – eines für jedes Mal, wenn die Spalte profiliert wurde.
Wenn Sie sich entscheiden, ob Sie die Ausgabetabelle oder die latest-Ansicht in Ihren SQL-Abfragen oder Looker Studio-Berichten verwenden, sollten Sie Folgendes berücksichtigen:
Die Ansicht
latestist nützlich, wenn Sie Daten-Assets haben, für die ein neues Profil erstellt wurde, und Sie nur die neuesten Profile sehen möchten, nicht die früheren Versionen. Sie möchten also den aktuellen Status Ihrer profilierten Daten sehen.Die Ausgabetabelle ist nützlich, wenn Sie einen historischen Überblick über Ihre profilierten Daten erhalten möchten. Sie möchten beispielsweise feststellen, ob in Ihrer Organisation jemals ein bestimmter infoType gespeichert wurde, oder die Änderungen sehen, die an einem bestimmten Datenprofil vorgenommen wurden.
SQL-Beispielabfragen
Dieser Abschnitt enthält Beispielabfragen, die Sie bei der Analyse von Datenprofilen verwenden können. Informationen zum Ausführen dieser Abfragen finden Sie unter Interaktive Abfragen ausführen.
Ersetzen Sie in den folgenden Beispielen TABLE_OR_VIEW durch einen der folgenden Werte:
- Der Name der Ausgabetabelle, die die exportierten Datenprofile enthält, z. B.
myproject.mydataset.table-profile. - Der Name der
latest-Ansicht der Ausgabetabelle, z. B.myproject.mydataset.table-profile_latest_v1.
In beiden Fällen müssen Sie die Projekt-ID und die Dataset-ID angeben.
Weitere Informationen finden Sie auf dieser Seite unter Zwischen der Ausgabetabelle und der Ansicht latest wählen.
Informationen zur Behebung von Fehlern finden Sie unter Fehlermeldungen.
Alle Spalten mit einem hohen Wert für freien Text und Hinweisen auf andere infoType-Übereinstimmungen auflisten
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Informationen dazu, wie Sie diese Probleme beheben können, finden Sie unter Empfohlene Strategien zur Minimierung des Datenrisikos.
Weitere Informationen zu den Messwerten Freitext-Bewertung und Andere infoTypes finden Sie unter Spaltendatenprofile.
Alle Tabellen auflisten, die eine Spalte mit Kreditkartennummern enthalten
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER ist ein integrierter infoType, der eine Kreditkartennummer darstellt.
Informationen dazu, wie Sie diese Probleme beheben können, finden Sie unter Empfohlene Strategien zur Minimierung des Datenrisikos.
Tabellenprofile auflisten, die Spalten mit Kreditkartennummern, US-Sozialversicherungsnummern und Personennamen enthalten
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
In dieser Abfrage werden die folgenden integrierten infoTypes verwendet:
CREDIT_CARD_NUMBER: steht für eine KreditkartennummerPERSON_NAME: steht für den vollständigen Namen einer PersonUS_SOCIAL_SECURITY_NUMBERsteht für eine US-amerikanische Sozialversicherungsnummer.
Informationen dazu, wie Sie diese Probleme beheben können, finden Sie unter Empfohlene Strategien zur Minimierung des Datenrisikos.
Buckets auflisten, deren Vertraulichkeitswert SENSITIVITY_HIGH ist
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Weitere Informationen finden Sie unter Dateispeicher-Datenprofile.
Liste aller gescannten Bucket-Pfade, Cluster und Dateiendungen auf, bei denen der Vertraulichkeitsscore SENSITIVITY_HIGH ist.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Weitere Informationen finden Sie unter Dateispeicher-Datenprofile.
Alle gescannten Bucket-Pfade, Cluster und Dateiendungen auflisten, in denen Kreditkartennummern erkannt wurden
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER ist ein integrierter infoType, der eine Kreditkartennummer darstellt.
Weitere Informationen finden Sie unter Dateispeicher-Datenprofile.
Alle gescannten Bucket-Pfade, Cluster und Dateiendungen auflisten, in denen eine Kreditkartennummer, ein Personenname oder eine US-Sozialversicherungsnummer erkannt wurde
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
In dieser Abfrage werden die folgenden integrierten infoTypes verwendet:
CREDIT_CARD_NUMBER: steht für eine KreditkartennummerPERSON_NAME: steht für den vollständigen Namen einer PersonUS_SOCIAL_SECURITY_NUMBERsteht für eine US-amerikanische Sozialversicherungsnummer.
Weitere Informationen finden Sie unter Dateispeicher-Datenprofile.
Mit Datenprofilen in Looker Studio arbeiten
Wenn Sie Ihre Datenprofile in Looker Studio visualisieren möchten, können Sie einen vorkonfigurierten Bericht verwenden oder einen eigenen erstellen.
Vorgefertigten Bericht verwenden
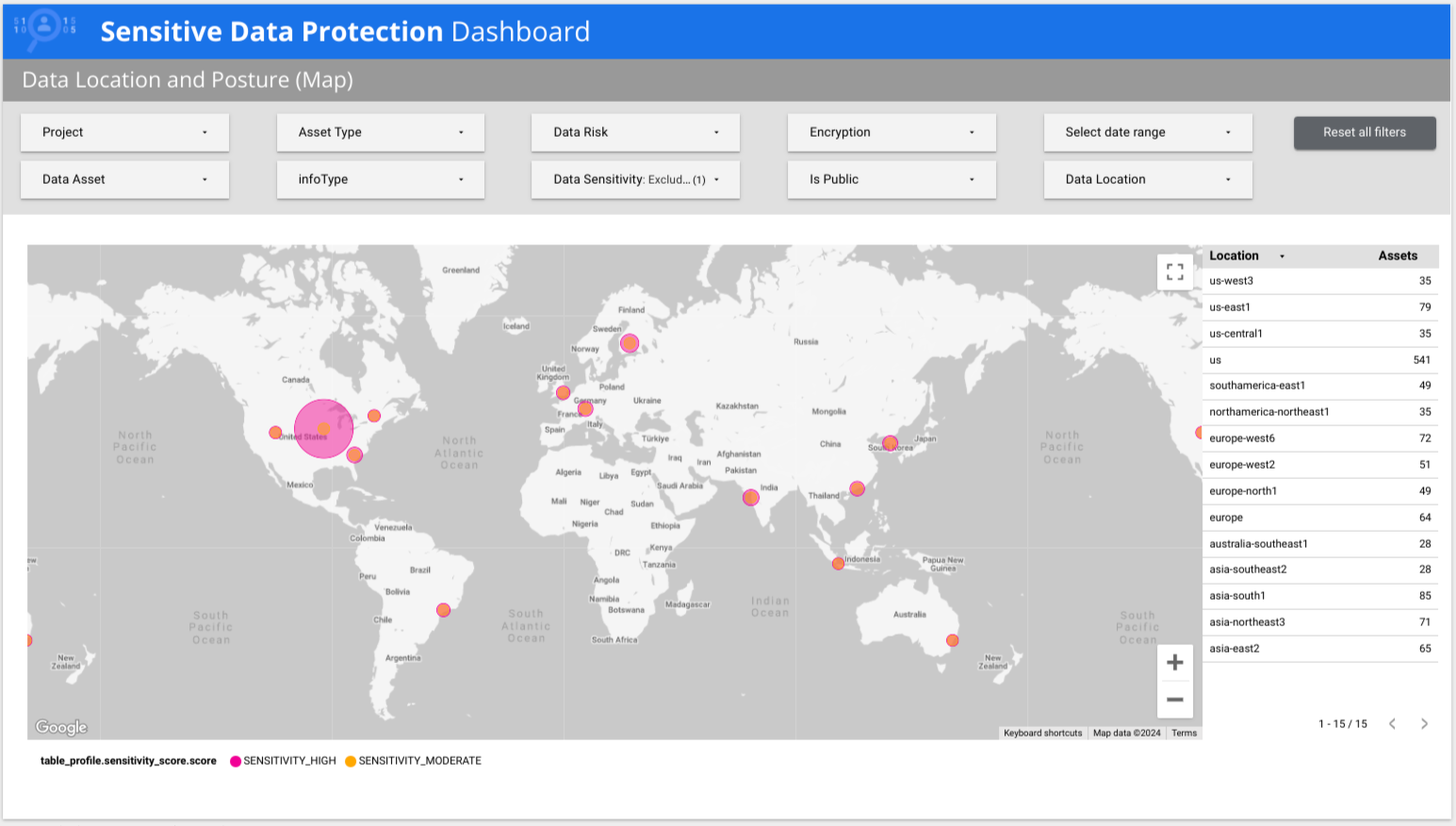
Sensitive Data Protection bietet einen vorkonfigurierten Looker Studio-Bericht, in dem die umfassenden Statistiken von Datenprofilen hervorgehoben werden. Das Sensitive Data Protection-Dashboard ist ein mehrseitiger Bericht, der Ihnen einen schnellen Überblick über Ihre Datenprofile bietet, einschließlich Aufschlüsselungen nach Risiko, infoType und Speicherort. Auf den anderen Tabs finden Sie Ansichten nach geografischer Region und Haltungsrisiko. Sie können auch bestimmte Messwerte aufrufen. Sie können diesen vordefinierten Bericht unverändert verwenden oder nach Bedarf anpassen. Dies ist die empfohlene Version des vorgefertigten Berichts.
Wenn Sie den vorgefertigten Bericht mit Ihren Daten aufrufen möchten, geben Sie die erforderlichen Werte in die folgende URL ein. Kopieren Sie dann die resultierende URL in Ihren Browser.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Ersetzen Sie Folgendes:
- PROJECT_ID: Das Projekt, das die Ausgabetabelle enthält.
- DATASET_ID: Das Dataset, das die Ausgabetabelle enthält.
TABLE_OR_VIEW: eine der folgenden Optionen:
- Der Name der Ausgabetabelle, die die exportierten Datenprofile enthält,z. B.
myproject.mydataset.table-profile. - Der Name der
latest-Ansicht der Ausgabetabelle, z. B.myproject.mydataset.table-profile_latest_v1.
Weitere Informationen finden Sie auf dieser Seite unter Zwischen Ausgabetabelle und
latest-Ansicht wählen.- Der Name der Ausgabetabelle, die die exportierten Datenprofile enthält,z. B.
Es kann einige Minuten dauern, bis der Bericht mit Ihren Daten in Looker Studio geladen wird. Wenn Fehler auftreten oder der Bericht nicht geladen wird, lesen Sie den Abschnitt Fehler im Zusammenhang mit dem vorgefertigten Bericht beheben auf dieser Seite.
Im folgenden Beispiel ist zu sehen, dass Daten mit niedriger und hoher Sensibilität in mehreren Ländern weltweit vorhanden sind.
Frühere Version des vorgefertigten Berichts
Die erste Version des vorgefertigten Berichts ist weiterhin unter der folgenden Adresse verfügbar:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Bericht erstellen
Mit Looker Studio können Sie interaktive Berichte erstellen. In diesem Abschnitt erstellen Sie einen einfachen tabellarischen Bericht in Looker Studio, der auf den Datenprofilen basiert, die in Ihre Ausgabetabelle in BigQuery exportiert wurden.
Halten Sie die Projekt-ID, die Dataset-ID und die Tabellen-ID der Ausgabetabelle oder der latest-Ansicht bereit. Sie benötigen sie, um diesen Vorgang auszuführen.
In diesem Beispiel wird gezeigt, wie Sie einen Bericht mit einer Tabelle erstellen, in der jeder infoType, der in Ihren Datenprofilen gemeldet wird, und die entsprechende Häufigkeit angezeigt werden.
Im Allgemeinen fallen Kosten für die BigQuery-Nutzung an, wenn Sie über Looker Studio auf BigQuery zugreifen. Weitere Informationen finden Sie unter BigQuery-Daten mit Looker Studio visualisieren.
So erstellen Sie einen Bericht:
- Öffnen Sie Looker Studio und melden Sie sich an.
- Klicken Sie auf Leerer Bericht.
- Klicken Sie auf dem Tab Datenverbindung herstellen auf die Karte BigQuery.
- Autorisieren Sie Looker Studio für den Zugriff auf Ihre BigQuery-Projekte, wenn Sie dazu aufgefordert werden.
So stellen Sie eine Verbindung zu Ihren BigQuery-Daten her:
- Wählen Sie unter Projekt das Projekt aus, das die Ausgabetabelle enthält. Sie können auf den Tabs Letzte Projekte, Meine Projekte und Freigegebene Projekte nach dem Projekt suchen.
- Wählen Sie unter Dataset das Dataset aus, das die Ausgabetabelle enthält.
Wählen Sie für Tabelle entweder die Ausgabetabelle oder die
latest-Ansicht der Ausgabetabelle aus.Weitere Informationen finden Sie auf dieser Seite unter Zwischen Ausgabetabelle und
latest-Ansicht wählen.Klicken Sie auf Hinzufügen.
Klicken Sie im angezeigten Dialogfeld auf Zum Bericht hinzufügen.
So fügen Sie eine Tabelle hinzu, in der jeder gemeldete infoType und die entsprechende Häufigkeit (Anzahl der Datensätze) angezeigt wird:
- Klicken Sie auf Diagramm hinzufügen.
- Wählen Sie einen Tabellenstil aus.
Klicken Sie auf den Bereich, in dem Sie das Diagramm positionieren möchten.
Das Diagramm wird in Tabellenform angezeigt.
Passen Sie die Größe der Tabelle nach Bedarf an.
Solange die Tabelle ausgewählt ist, werden ihre Eigenschaften im Bereich Diagramm angezeigt.
Entfernen Sie im Bereich Diagramm auf dem Tab Einrichtung alle vorausgewählten Dimensionen und Messwerte.
Fügen Sie für Dimension
column_profile.column_info_type.info_type.nameoderfile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.namehinzu.Diese Beispiele enthalten Daten auf Spalten- und Dateiclusterebene. Sie können auch andere Dimensionen ausprobieren. Sie können beispielsweise Dimensionen auf Tabellen- und Bucket-Ebene verwenden.
Fügen Sie als Messwert Datensatzanzahl hinzu.
Die resultierende Tabelle sieht etwa so aus:

Weitere Informationen zu Tabellen in Looker Studio
Fehler mit dem vorgefertigten Bericht beheben
Wenn beim Laden des vorgefertigten Berichts Fehler, fehlende Steuerelemente oder fehlende Diagramme angezeigt werden, prüfen Sie, ob im vorgefertigten Bericht die neuesten Felder verwendet werden:
Wenn Ihr vorgefertigter Bericht mit der Ausgabetabelle verbunden ist, prüfen Sie, ob diese Tabelle an eine aktive Konfiguration für den Discovery-Scan angehängt ist. Informationen zum Aufrufen der Einstellungen Ihrer Scankonfigurationen finden Sie unter Scankonfiguration aufrufen.
Wenn Ihr vorgefertigter Bericht mit der Ansicht
latestverbunden ist, prüfen Sie, ob diese Ansicht noch in BigQuery vorhanden ist. Wenn sie vorhanden ist, versuchen Sie, die Ansicht zu ändern. Alternativ können Sie eine Kopie der Ansicht erstellen und den vorgefertigten Bericht mit dieser Kopie verknüpfen. Weitere Informationen zur Ansichtlatestfinden Sie auf dieser Seite unter Die Ansichtlatest.
Wenn nach diesen Schritten weiterhin Fehler auftreten, wenden Sie sich an den Cloud-Kundenservice.