Auf dieser Seite wird erläutert, wie die Architektur von Memorystore for Valkey Hochverfügbarkeit (High Availability, HA) unterstützt und bietet. Außerdem werden empfohlene Konfigurationen erläutert, die zu einer besseren Instanzleistung und ‑stabilität beitragen.
Hochverfügbarkeit
Memorystore for Valkey basiert auf einer hochverfügbaren Architektur, in der Ihre Clients direkt auf verwaltete Memorystore for Valkey-Knoten zugreifen. Ihre Clients stellen dazu eine Verbindung zu einzelnen Endpunkten her, wie unter Verbindung zu einer Memorystore for Valkey-Instanz herstellen beschrieben.
Die direkte Verbindung zu Shards bietet folgende Vorteile:
Durch die direkte Verbindung werden Zwischen-Hops vermieden, wodurch die Umlaufzeit (Client-Latenz) zwischen Ihrem Client und dem Valkey-Knoten minimiert wird.
Wenn der Clustermodus aktiviert ist, wird durch die direkte Verbindung ein Single Point of Failure vermieden, da jeder Shard so konzipiert ist, dass er unabhängig ausfällt. Wenn beispielsweise der Traffic von mehreren Clients einen Slot (Keyspace-Chunk) überlastet, wird der Einfluss eines Shard-Fehlers auf den Shard begrenzt, der für die Bereitstellung des Slots verantwortlich ist.
Empfohlene Konfigurationen
Wir empfehlen, hochverfügbare Instanzen mit mehreren Zonen anstelle von Instanzen mit einer einzelnen Zone zu erstellen, da sie eine höhere Zuverlässigkeit bieten. Wenn Sie jedoch eine Instanz ohne Replikate bereitstellen möchten, empfehlen wir, eine Instanz mit einer einzelnen Zone auszuwählen. Weitere Informationen finden Sie unter Instanz mit einer einzelnen Zone auswählen, wenn Ihre Instanz keine Replikate verwendet.
Wenn Sie Hochverfügbarkeit für Ihre Instanz aktivieren möchten, müssen Sie für jeden Shard mindestens einen Replikatknoten bereitstellen. Sie können dies beim Erstellen der Instanz tun oder die Anzahl der Replikate auf mindestens 1 Replikat pro Shard skalieren. Replikate bieten automatisches Failover bei geplanter Wartung und unerwarteten Shard-Fehlern.
Sie sollten Ihren Client gemäß den Best Practices für Clients konfigurieren. Wenn Ihr Kunde die empfohlenen Best Practices anwendet, können die folgenden Elemente für Ihre Instanz automatisch und ohne Ausfallzeiten verarbeitet werden:
Die Rolle (automatische Failovers)
Der Endpunkt (Knotenersetzung)
Änderungen bei der Slotzuweisung im Zusammenhang mit dem aktivierten Clustermodus (Consumer-Scale-out und -in)
Replikate
Eine hochverfügbare Memorystore for Valkey-Instanz ist eine regionale Ressource. Das bedeutet, dass Memorystore for Valkey primäre und Replikatknoten von Shards auf mehrere Zonen verteilt, um sich vor einem Zonenausfall zu schützen. Memorystore for Valkey unterstützt Instanzen mit 0, 1 oder 2 Replikaten pro Knoten.
Mit Replikaten können Sie den Lesedurchsatz erhöhen, was jedoch zu potenziell veralteten Daten führen kann.
- Clustermodus aktiviert:Verwenden Sie den Befehl
READONLY, um eine Verbindung herzustellen, über die Ihr Client Daten aus Replikaten lesen kann. - Clustermodus deaktiviert:Stellen Sie eine Verbindung zum Reader-Endpunkt her, um eine Verbindung zu einem der verfügbaren Replikate herzustellen.
Instanz-Shapes mit aktiviertem Clustermodus
Die folgenden Diagramme veranschaulichen Formen für Instanzen mit aktiviertem Clustermodus:
Mit 3 Shards und 0 Replikaten pro Knoten
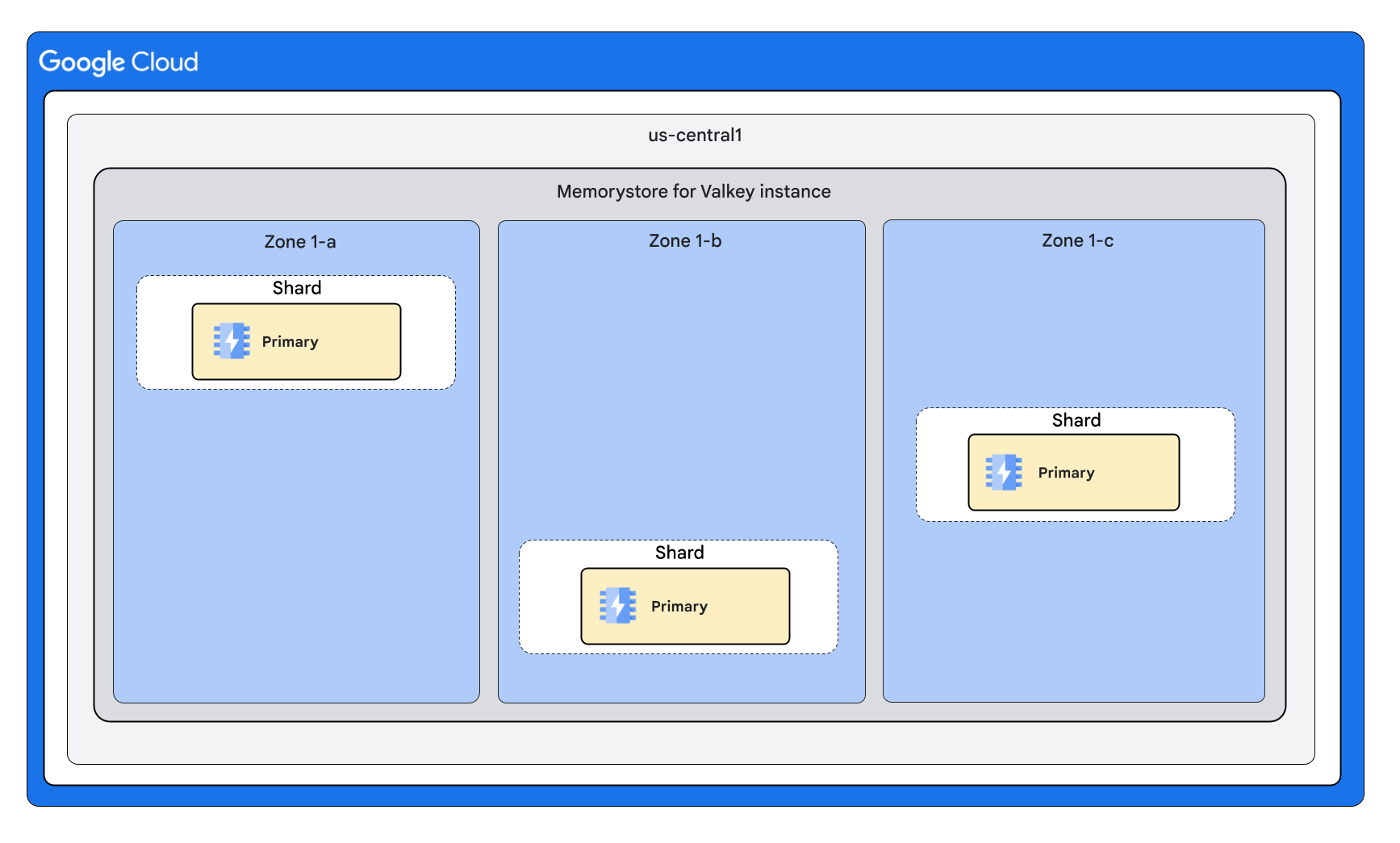
Mit 3 Shards und 1 Replikat pro Knoten
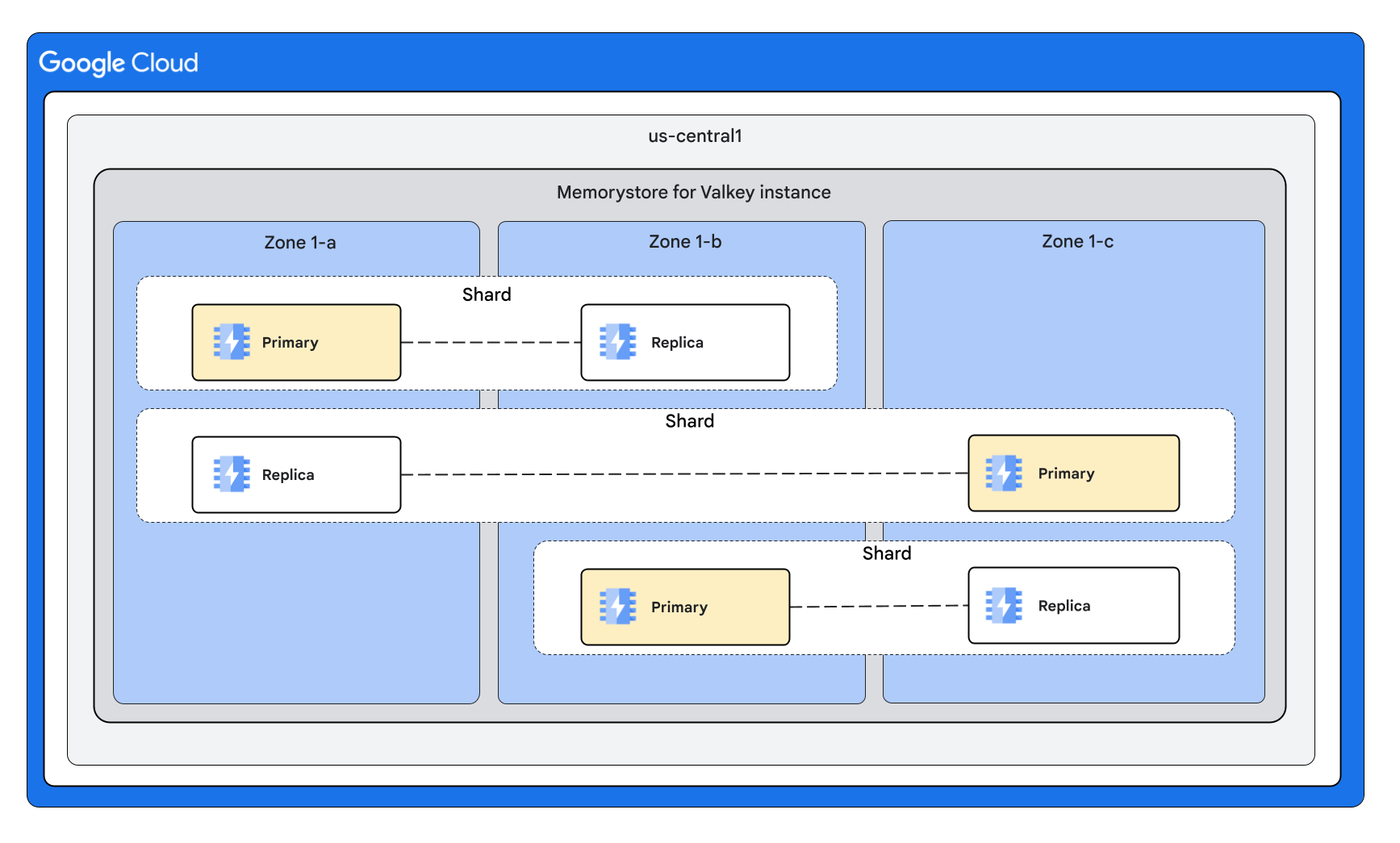
Mit 3 Shards und 2 Replikaten pro Knoten
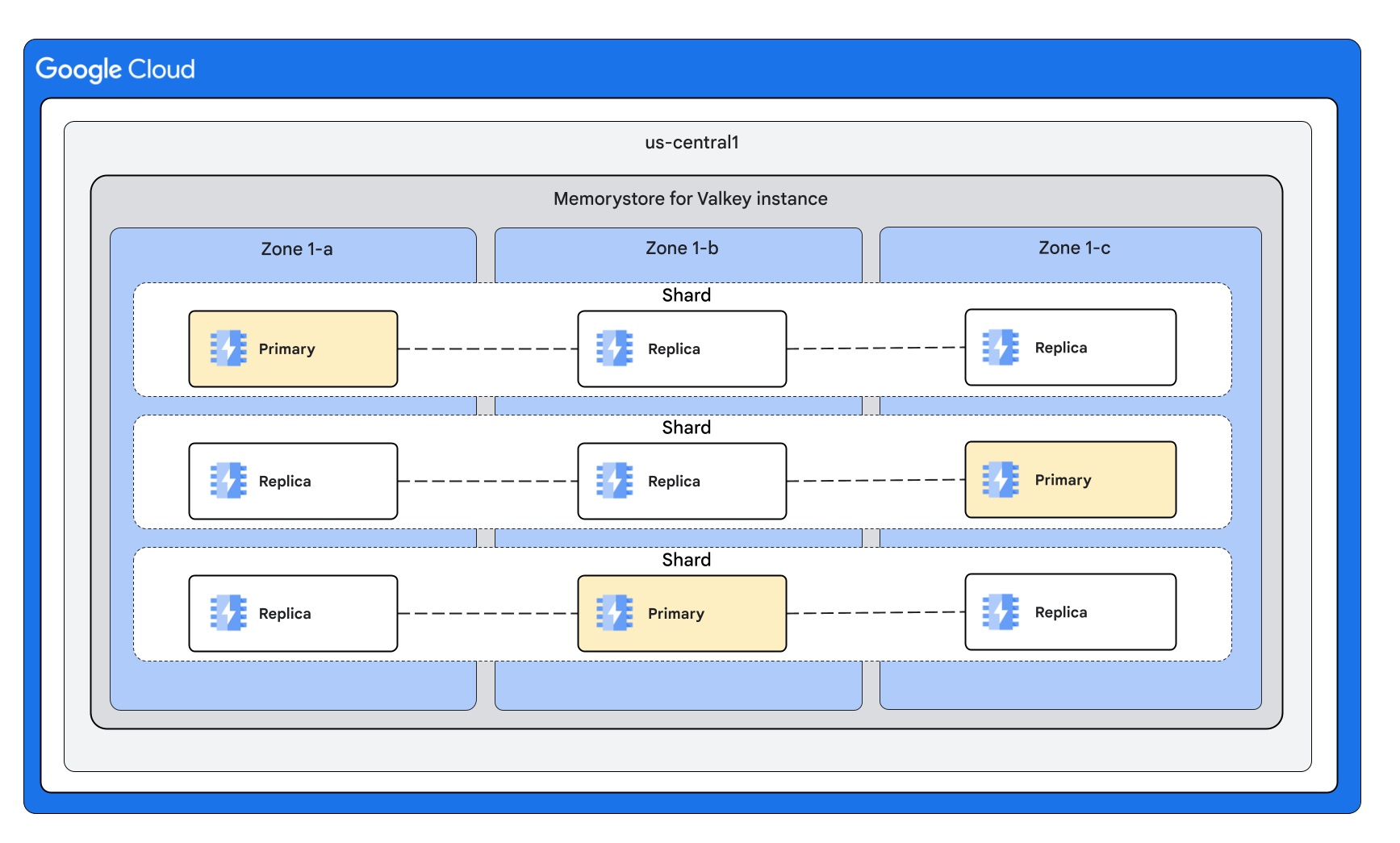
Instanztypen für Instanzen mit deaktiviertem Clustermodus
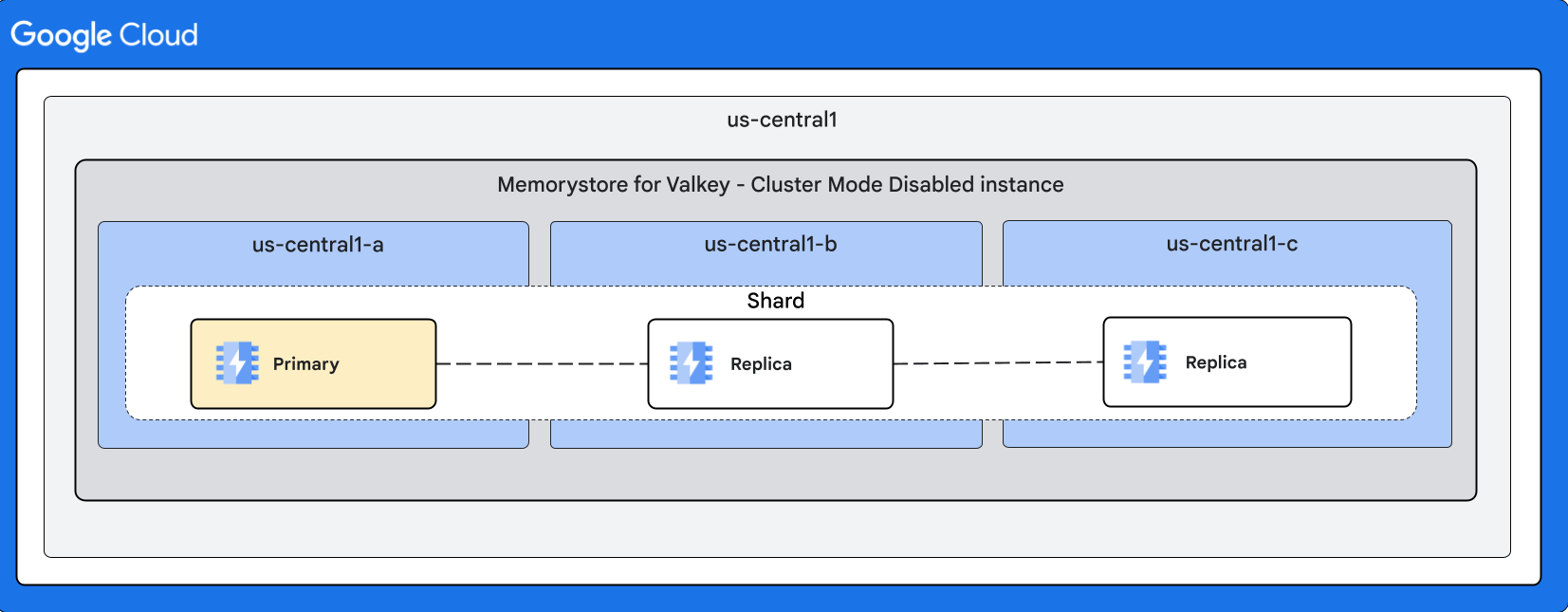
Die folgenden Diagramme veranschaulichen Formen für Instanzen mit deaktiviertem Clustermodus:
Mit 2 Replikaten
Automatische Ausfallsicherung
Automatische Failover innerhalb eines Shards können aufgrund von Wartungsarbeiten oder eines unerwarteten Fehlers des primären Knotens auftreten. Bei einem Failover wird ein Replikat zur primären Instanz hochgestuft. Sie können Replikate explizit konfigurieren. Der Dienst kann während der internen Wartung auch vorübergehend zusätzliche Replikate bereitstellen, um Ausfallzeiten zu vermeiden.
Automatische Failovers verhindern Datenverlust bei Wartungsupdates. Weitere Informationen zum Verhalten beim automatischen Failover während der Wartung finden Sie unter Verhalten beim automatischen Failover während der Wartung.
Dauer von Failover und Knotenreparatur
Automatische Failover können bei ungeplanten Ereignissen wie einem Prozessabsturz des primären Knotens oder einem Hardwarefehler mehrere zehn Sekunden dauern. Während dieser Zeit erkennt das System den Fehler und wählt ein Replikat als neue primäre Instanz aus.
Die Reparatur von Knoten kann einige Minuten dauern, bis der Dienst den ausgefallenen Knoten ersetzt. Dies gilt für alle primären Knoten und Replikatknoten. Bei Instanzen, die nicht hochverfügbar sind (keine Replikate bereitgestellt), dauert die Reparatur eines ausgefallenen primären Knotens ebenfalls einige Minuten.
Clientverhalten bei einem ungeplanten Failover
Clientverbindungen werden je nach Art des Fehlers wahrscheinlich zurückgesetzt. Nach der automatischen Wiederherstellung sollten Verbindungen mit exponentiellem Backoff wiederholt werden, um eine Überlastung der primären und Replikatknoten zu vermeiden.
Clients, die Replikate für den Lesedurchsatz verwenden, sollten sich auf eine vorübergehende Verringerung der Kapazität einstellen, bis der ausgefallene Knoten automatisch ersetzt wird.
Verlorene Schreibvorgänge
Bei einem Failover aufgrund eines unerwarteten Fehlers können bestätigte Schreibvorgänge aufgrund der asynchronen Natur des Replikationsprotokolls von Valkey verloren gehen.
Clientanwendungen können den WAIT-Befehl von Valkey nutzen, um die Datensicherheit in der Praxis zu verbessern.
Auswirkungen eines einzelnen Zonenausfalls auf den Keyspace
In diesem Abschnitt wird beschrieben, welche Auswirkungen ein Ausfall einer einzelnen Zone auf eine Memorystore for Valkey-Instanz hat.
Instanzen in mehreren Zonen
HA-Instanzen:Wenn es in einer Zone zu einem Ausfall kommt, ist der gesamte Keyspace für Lese- und Schreibvorgänge verfügbar. Da jedoch einige Lesereplikate nicht verfügbar sind, ist die Lesekapazität reduziert. Wir empfehlen dringend, die Clusterkapazität zu überdimensionieren, damit die Instanz im seltenen Fall eines Ausfalls einer einzelnen Zone über genügend Lesekapazität verfügt. Sobald der Ausfall behoben ist, werden die Replikate in der betroffenen Zone wiederhergestellt und die Lesekapazität des Clusters kehrt zum konfigurierten Wert zurück. Weitere Informationen finden Sie unter Muster für skalierbare und zuverlässige Anwendungen.
Nicht-HA-Instanzen (keine Replikate): Wenn es in einer Zone zu einem Ausfall kommt, werden die Daten des Teils des Schlüsselbereichs, der in der betroffenen Zone bereitgestellt wird, geleert. Während des Ausfalls ist dieser Teil des Schlüsselbereichs nicht für Schreib- oder Lesevorgänge verfügbar. Sobald der Ausfall behoben ist, werden die primären Instanzen in der betroffenen Zone wiederhergestellt und die Kapazität des Clusters kehrt zum konfigurierten Wert zurück.
Single-Zone-Instanzen
- Instanzen mit und ohne Hochverfügbarkeit:Wenn die Zone, in der die Instanz bereitgestellt wird, ausfällt, ist der Cluster nicht verfügbar und die Daten werden geleert. Wenn eine andere Zone ausfällt, verarbeitet der Cluster weiterhin Lese- und Schreibanfragen.
Best Practices
In diesem Abschnitt werden Best Practices für Hochverfügbarkeit und Replikate beschrieben.
Replikat hinzufügen
Zum Hinzufügen eines Replikats ist ein RDB-Snapshot erforderlich. Bei RDB-Snapshots wird ein Prozess-Fork und ein Copy-on-Write-Mechanismus verwendet, um einen Snapshot der Knotendaten zu erstellen. Je nach Muster der Schreibvorgänge für Knoten wächst der verwendete Arbeitsspeicher der Knoten, da Seiten, die von den Schreibvorgängen betroffen sind, kopiert werden. Der Speicherbedarf kann bis zu doppelt so groß sein wie die Daten auf dem Knoten.
Damit Knoten genügend Arbeitsspeicher für den Snapshot haben, sollte maxmemory bei 80% der Knotenkapazität liegen, sodass 20% für den Overhead reserviert sind. Dieser zusätzliche Arbeitsspeicher hilft Ihnen zusammen mit der Überwachung von Snapshots, Ihre Arbeitslast so zu verwalten, dass Snapshots erfolgreich erstellt werden. Wenn Sie Replikate hinzufügen, sollten Sie außerdem den Schreibtraffic so weit wie möglich reduzieren. Weitere Informationen finden Sie unter Arbeitsspeichernutzung einer Instanz überwachen.