Halaman ini menjelaskan cara arsitektur Memorystore for Valkey mendukung dan menyediakan ketersediaan tinggi (HA). Halaman ini juga menjelaskan konfigurasi yang direkomendasikan yang berkontribusi pada peningkatan performa dan stabilitas instance.
Ketersediaan tinggi
Memorystore for Valkey dibangun di atas arsitektur dengan ketersediaan tinggi tempat klien Anda mengakses node Memorystore for Valkey terkelola secara langsung. Klien Anda melakukannya dengan terhubung ke setiap endpoint, seperti yang dijelaskan dalam Menghubungkan ke instance Memorystore untuk Valkey.
Menghubungkan ke shard secara langsung memberikan manfaat berikut:
Koneksi langsung menghindari hop perantara, yang meminimalkan waktu round-trip (latensi klien) antara klien Anda dan node Valkey.
Jika Cluster Mode Enabled, koneksi langsung menghindari titik tunggal kegagalan karena setiap shard dirancang agar gagal secara independen. Misalnya, jika traffic dari beberapa klien membebani slot (chunk keyspace), kegagalan shard membatasi dampak pada shard yang bertanggung jawab untuk melayani slot.
Konfigurasi yang direkomendasikan
Sebaiknya buat instance multi-zona yang sangat tersedia, bukan instance zona tunggal karena keandalan yang lebih baik yang mereka berikan. Namun, jika Anda memilih untuk menyediakan instance tanpa replika, sebaiknya pilih instance zona tunggal. Untuk mengetahui informasi selengkapnya, lihat Memilih instance zona tunggal jika instance Anda tidak menggunakan replika.
Untuk mengaktifkan ketersediaan tinggi bagi instance Anda, Anda harus menyediakan minimal 1 node replika untuk setiap shard. Anda dapat melakukannya saat Membuat instance, atau Anda dapat Menskalakan jumlah replika menjadi setidaknya 1 replika per shard. Replika menyediakan Failover otomatis selama pemeliharaan terencana dan kegagalan shard yang tidak terduga.
Anda harus mengonfigurasi klien sesuai dengan panduan di Praktik terbaik klien. Dengan menggunakan praktik terbaik yang direkomendasikan, klien Anda dapat menangani item berikut untuk instance Anda secara otomatis dan tanpa periode nonaktif:
Peran (failover otomatis)
Endpoint (penggantian node)
Perubahan penetapan slot terkait Cluster Mode Enabled (penskalaan keluar dan masuk konsumen)
Replika
Instance Memorystore for Valkey yang sangat tersedia adalah resource regional. Artinya, Memorystore untuk Valkey mendistribusikan node primer dan replika shard di beberapa zona untuk melindungi dari pemadaman layanan zonal. Memorystore for Valkey mendukung instance dengan 0, 1, atau 2 replika per node.
Anda dapat menggunakan replika untuk meningkatkan throughput baca dengan mengorbankan potensi keusangan data.
- Mode Cluster Diaktifkan: Gunakan perintah
READONLYuntuk membuat koneksi yang memungkinkan klien Anda membaca dari replika. - Cluster Mode Disabled: Hubungkan ke endpoint pembaca untuk terhubung ke salah satu replika yang tersedia.
Bentuk Instance dengan Mode Cluster Diaktifkan
Diagram berikut menggambarkan bentuk untuk instance dengan Mode Cluster Diaktifkan:
Dengan 3 shard dan 0 replika per node
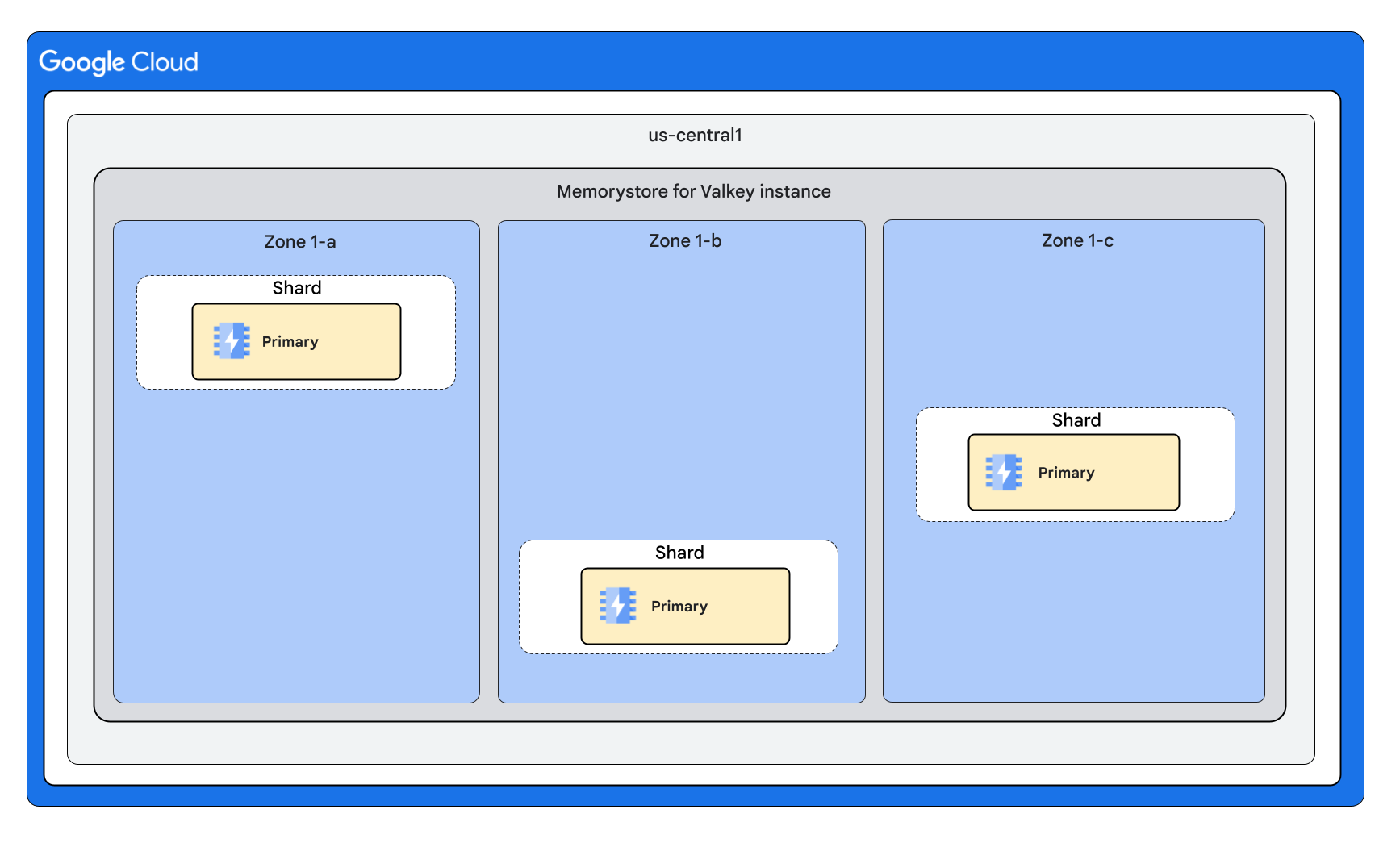
Dengan 3 shard dan 1 replika per node
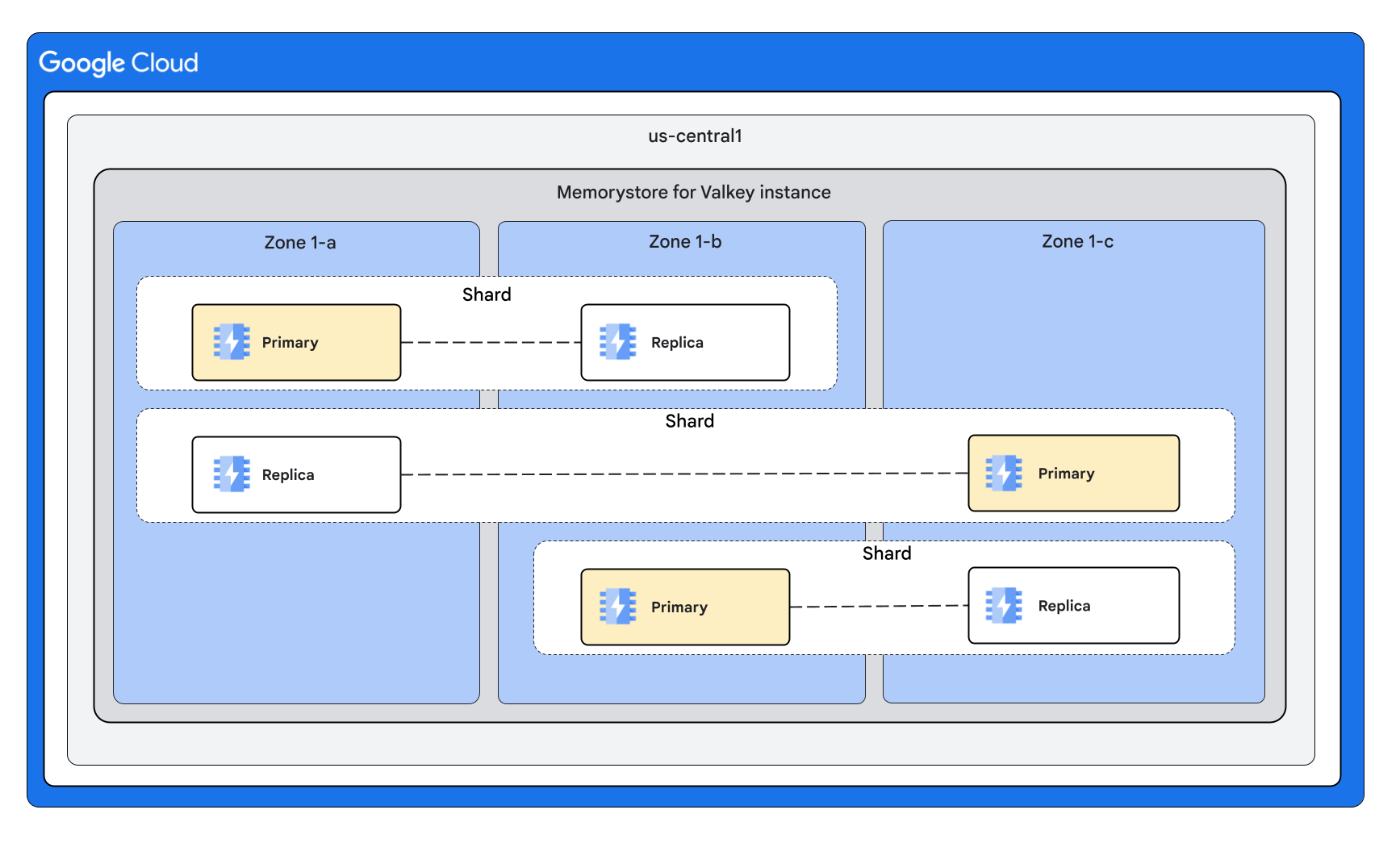
Dengan 3 shard dan 2 replika per node
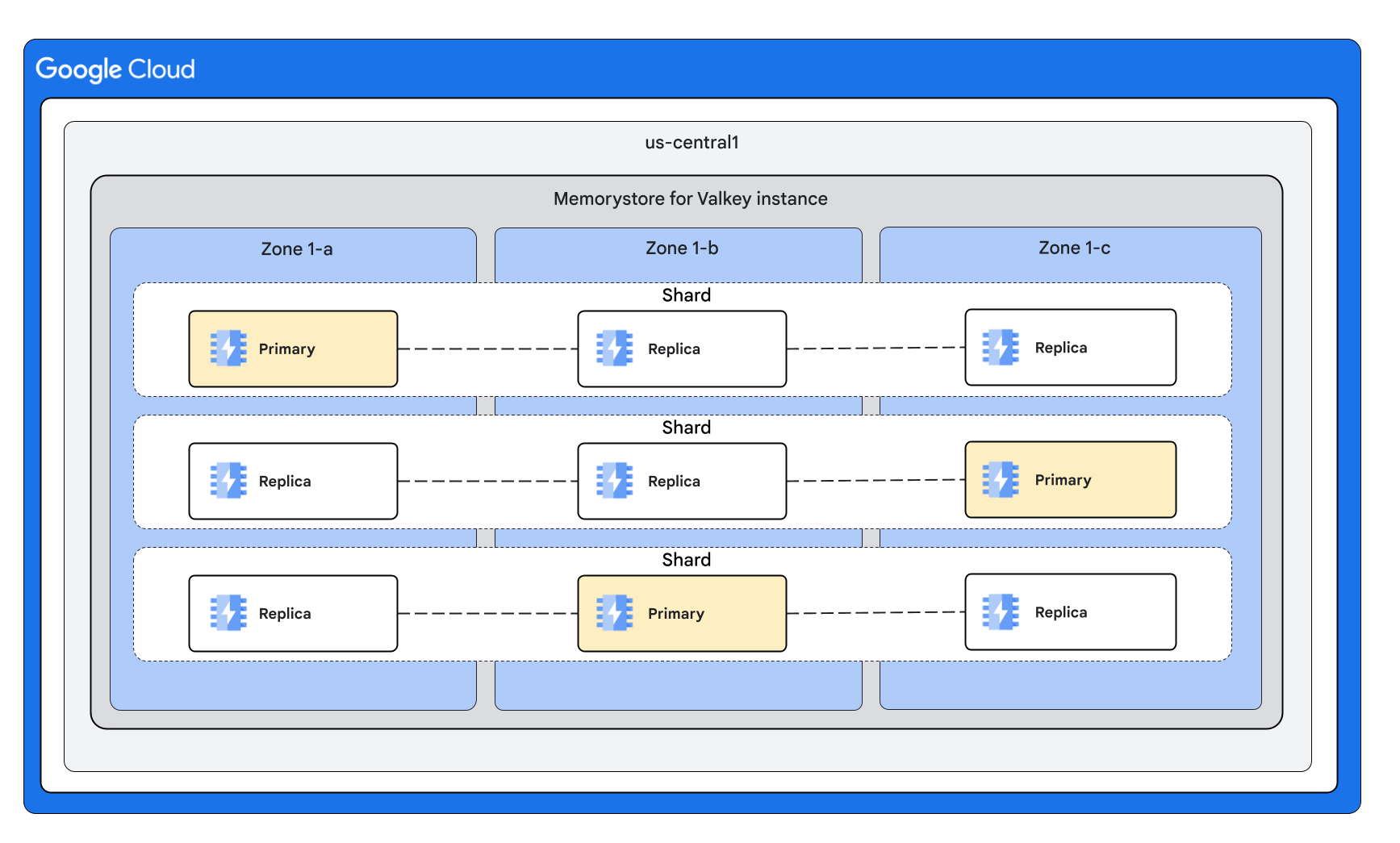
Bentuk Instance dengan Mode Cluster Dinonaktifkan
Diagram berikut menggambarkan bentuk untuk instance dengan Mode Cluster Dinonaktifkan:
Dengan 2 replika
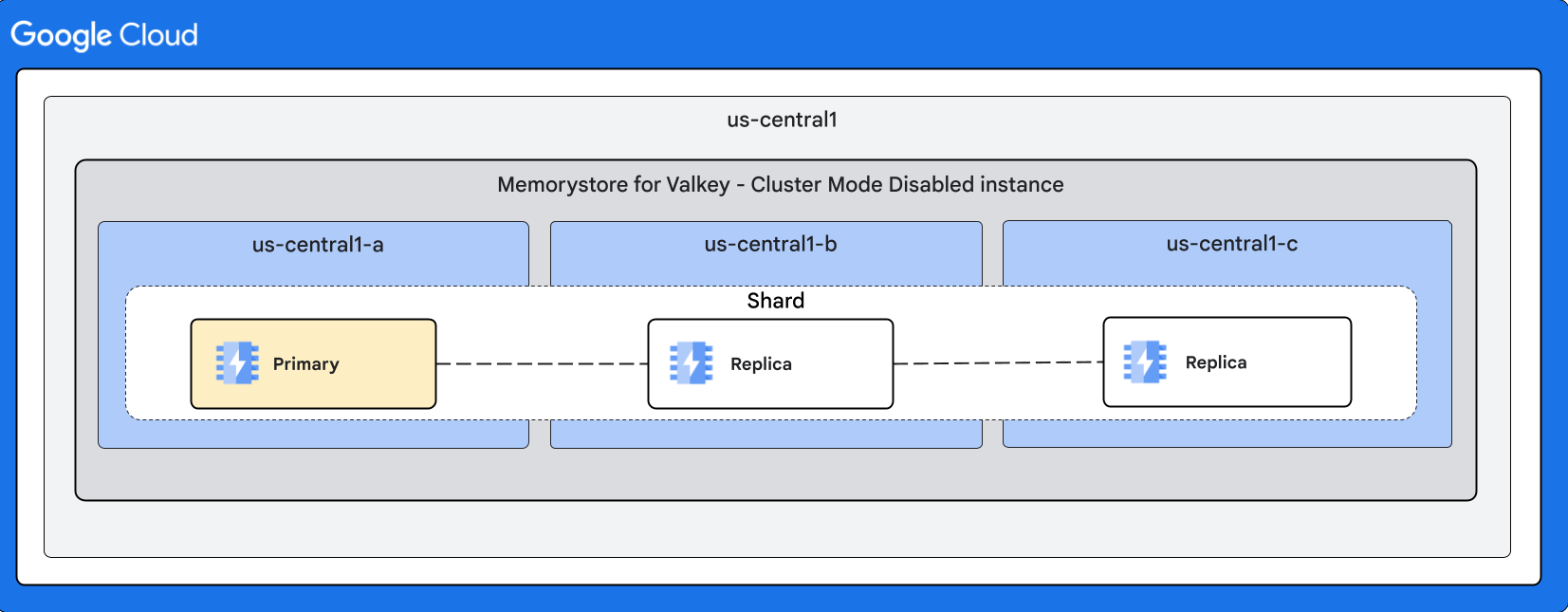
Failover otomatis
Pengalihan otomatis dalam shard dapat terjadi karena pemeliharaan atau kegagalan tak terduga pada node utama. Selama failover, replika dipromosikan menjadi yang utama. Anda dapat mengonfigurasi replika secara eksplisit. Layanan ini juga dapat menyediakan replika tambahan untuk sementara selama pemeliharaan internal untuk menghindari periode nonaktif.
Pengalihan otomatis mencegah kehilangan data selama update pemeliharaan. Untuk mengetahui detail tentang perilaku failover otomatis selama pemeliharaan, lihat Perilaku failover otomatis selama pemeliharaan.
Durasi failover dan perbaikan node
Pengalihan otomatis dapat memerlukan waktu hingga puluhan detik untuk peristiwa yang tidak direncanakan seperti crash proses node utama, atau kegagalan hardware. Selama waktu ini, sistem mendeteksi kegagalan, dan memilih replika untuk menjadi replika utama yang baru.
Perbaikan node dapat memerlukan waktu beberapa menit agar layanan dapat mengganti node yang gagal. Hal ini berlaku untuk semua node utama dan replika. Untuk instance yang tidak memiliki ketersediaan tinggi (tidak ada replika yang disediakan), memperbaiki node utama yang gagal juga memerlukan waktu beberapa menit.
Perilaku klien selama failover yang tidak direncanakan
Koneksi klien kemungkinan akan direset, bergantung pada sifat kegagalan. Setelah pemulihan otomatis, koneksi harus dicoba lagi dengan backoff eksponensial untuk menghindari kelebihan beban pada node utama dan replika.
Klien yang menggunakan replika untuk throughput baca harus siap menghadapi penurunan kapasitas sementara hingga node yang gagal diganti secara otomatis.
Operasi tulis yang hilang
Selama failover yang diakibatkan oleh kegagalan yang tidak terduga, penulisan yang dikonfirmasi dapat hilang karena sifat asinkron protokol replikasi Valkey.
Aplikasi klien dapat memanfaatkan perintah Valkey WAIT untuk meningkatkan keamanan data di dunia nyata.
Dampak keyspace dari pemadaman layanan satu zona
Bagian ini menjelaskan dampak pemadaman layanan satu zona pada instance Memorystore for Valkey.
Instance multi-zona
Instance HA: Jika zona mengalami pemadaman layanan, seluruh keyspace tersedia untuk operasi baca dan tulis, tetapi karena beberapa replika baca tidak tersedia, kapasitas baca akan berkurang. Sebaiknya sediakan kapasitas cluster secara berlebih agar instance memiliki kapasitas baca yang cukup, jika terjadi pemadaman layanan satu zona yang jarang terjadi. Setelah pemadaman layanan berakhir, replika di zona yang terpengaruh akan dipulihkan dan kapasitas baca cluster akan kembali ke nilai yang dikonfigurasi. Untuk mengetahui informasi selengkapnya, lihat Pola untuk aplikasi yang skalabel dan andal.
Instance non-HA (tanpa replika): Jika terjadi pemadaman layanan di zona, bagian keyspace yang disediakan di zona yang terpengaruh akan mengalami penghapusan data, dan tidak tersedia untuk operasi tulis atau baca selama pemadaman layanan. Setelah pemadaman layanan berakhir, server utama di zona yang terpengaruh akan dipulihkan dan kapasitas cluster akan kembali ke nilai yang dikonfigurasi.
Instance zona tunggal
- Instance HA dan Non-HA: Jika zona tempat instance disediakan mengalami pemadaman layanan, cluster tidak tersedia dan data akan dihapus. Jika zona lain mengalami pemadaman, cluster akan terus melayani permintaan baca dan tulis.
Praktik terbaik
Bagian ini menjelaskan praktik terbaik untuk ketersediaan tinggi dan replika.
Menambahkan replika
Menambahkan replika memerlukan snapshot RDB. Snapshot RDB menggunakan fork proses dan mekanisme'copy-on-write' untuk mengambil snapshot data node. Bergantung pada pola penulisan ke node, memori yang digunakan node bertambah saat halaman yang disentuh oleh penulisan disalin. Jejak memori dapat mencapai dua kali ukuran data di node.
Untuk memastikan node memiliki memori yang cukup untuk menyelesaikan snapshot, pertahankan atau
tetapkan maxmemory pada 80% dari
kapasitas node sehingga 20% dicadangkan untuk overhead. Overhead memori ini, selain snapshot pemantauan, membantu Anda mengelola workload agar memiliki snapshot yang berhasil. Selain itu, saat menambahkan replika, kurangi traffic tulis sebanyak
mungkin. Untuk mengetahui informasi selengkapnya, lihat Memantau penggunaan memori untuk instance.