En esta página se explica cómo la arquitectura de Memorystore para Valkey admite y proporciona alta disponibilidad (HA). En esta página también se explican las configuraciones recomendadas que contribuyen a mejorar el rendimiento y la estabilidad de las instancias.
Alta disponibilidad
Memorystore for Valkey se basa en una arquitectura de alta disponibilidad en la que los clientes acceden directamente a los nodos gestionados de Memorystore for Valkey. Para ello, tus clientes se conectan a endpoints individuales, tal como se describe en Conectarse a una instancia de Memorystore para Valkey.
Conectarse directamente a las particiones ofrece las siguientes ventajas:
La conexión directa evita los saltos intermedios, lo que minimiza el tiempo de ida y vuelta (latencia del cliente) entre el cliente y el nodo de Valkey.
Si el modo Clúster está habilitado, la conexión directa evita que haya un único punto de fallo, ya que cada fragmento está diseñado para fallar de forma independiente. Por ejemplo, si el tráfico de varios clientes sobrecarga un espacio (fragmento de espacio de claves), el error de fragmentación limita el impacto al fragmento responsable de servir el espacio.
Configuraciones recomendadas
Te recomendamos que crees instancias multizona de alta disponibilidad en lugar de instancias de una sola zona, ya que ofrecen una mayor fiabilidad. Sin embargo, si decides aprovisionar una instancia sin réplicas, te recomendamos que elijas una instancia de una sola zona. Para obtener más información, consulta Elegir una instancia de una sola zona si tu instancia no usa réplicas.
Para habilitar la alta disponibilidad de tu instancia, debes aprovisionar al menos un nodo de réplica por cada fragmento. Puedes hacerlo al crear la instancia o escalar el número de réplicas a al menos una réplica por fragmento. Las réplicas proporcionan conmutación por error automática durante el mantenimiento programado y los fallos inesperados de los fragmentos.
Debes configurar tu cliente de acuerdo con las directrices que se indican en Prácticas recomendadas para clientes. Si tu cliente sigue las prácticas recomendadas, podrá gestionar los siguientes elementos de tu instancia automáticamente y sin tiempo de inactividad:
El rol (conmutaciones por error automáticas)
El endpoint (sustitución de nodos)
Cambios en la asignación de espacios publicitarios relacionados con el modo de clúster activado (escalado horizontal de consumidores)
Réplicas
Una instancia de Memorystore for Valkey de alta disponibilidad es un recurso regional. Esto significa que Memorystore for Valkey distribuye los nodos principales y de réplica de los fragmentos en varias zonas para protegerse frente a las interrupciones zonales. Memorystore for Valkey admite instancias con 0, 1 o 2 réplicas por nodo.
Puedes usar réplicas para aumentar el rendimiento de lectura a costa de la posible obsolescencia de los datos.
- Modo clúster habilitado: usa el comando
READONLYpara establecer una conexión que permita a tu cliente leer de las réplicas. - Modo clúster inhabilitado: conéctate al endpoint de lectura para conectarte a cualquiera de las réplicas disponibles.
Diseños de instancias con el modo de clúster habilitado
En los siguientes diagramas se muestran las formas de las instancias con el modo de clúster habilitado:
Con 3 particiones y 0 réplicas por nodo
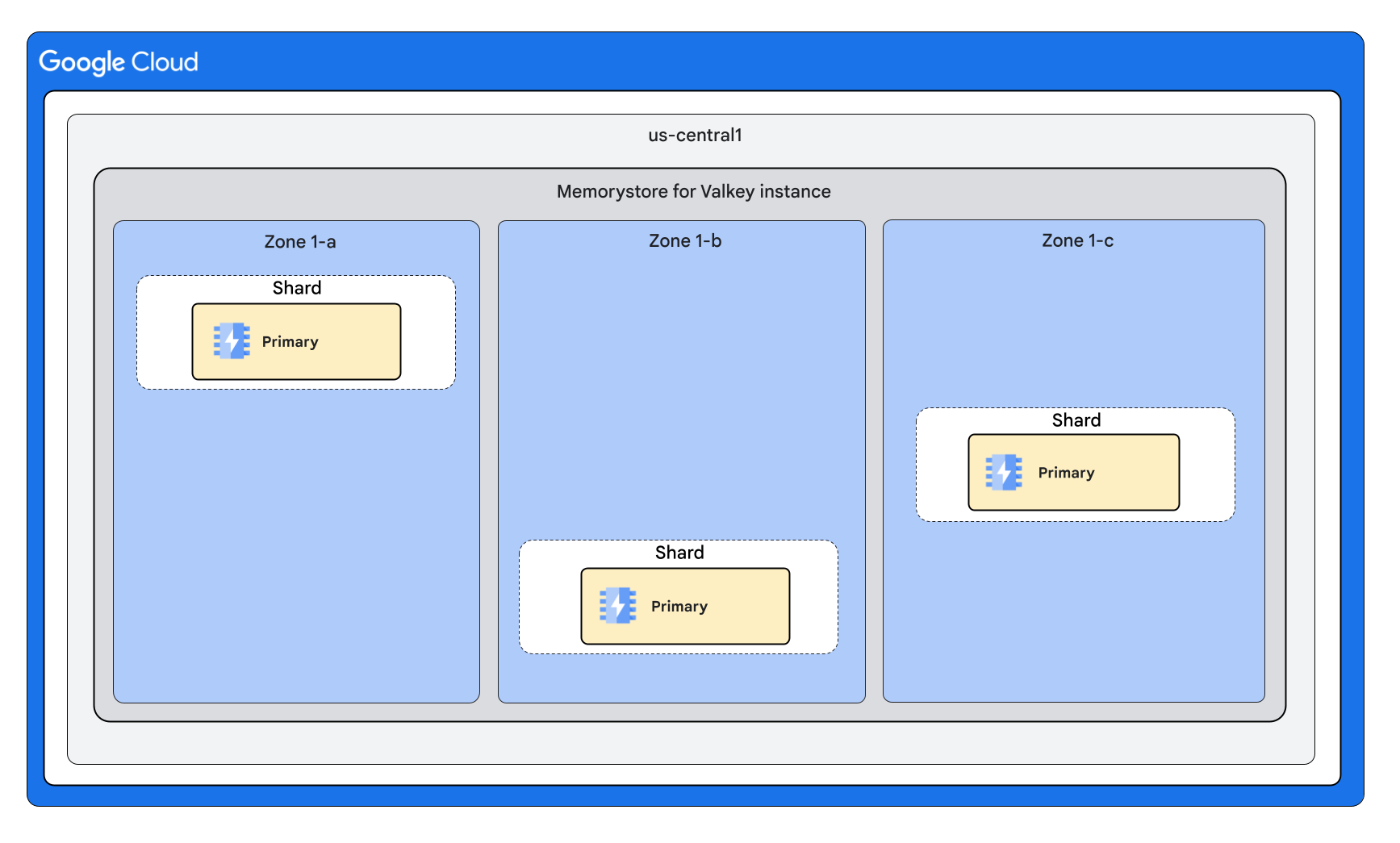
Con 3 particiones y 1 réplica por nodo
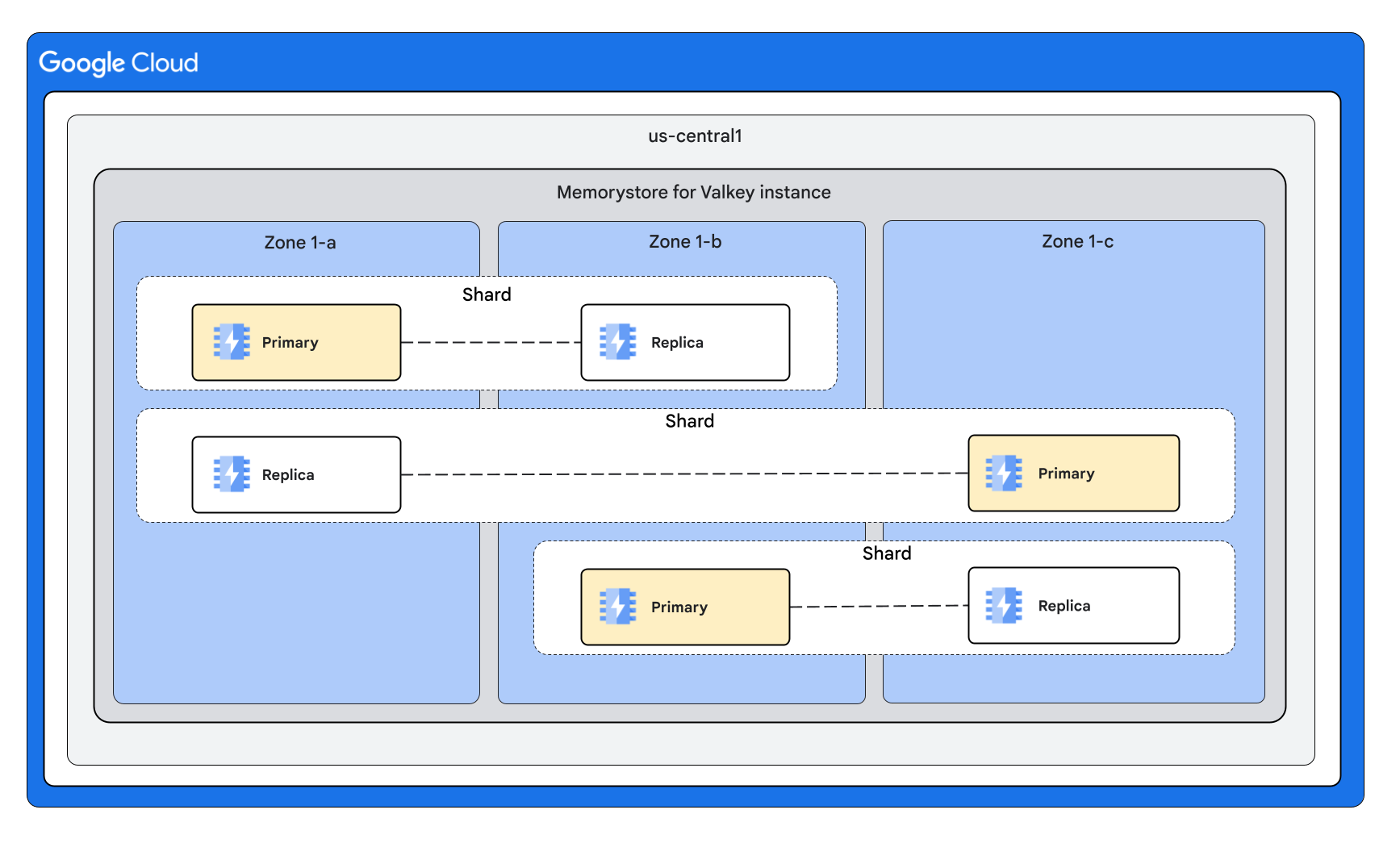
Con 3 particiones y 2 réplicas por nodo
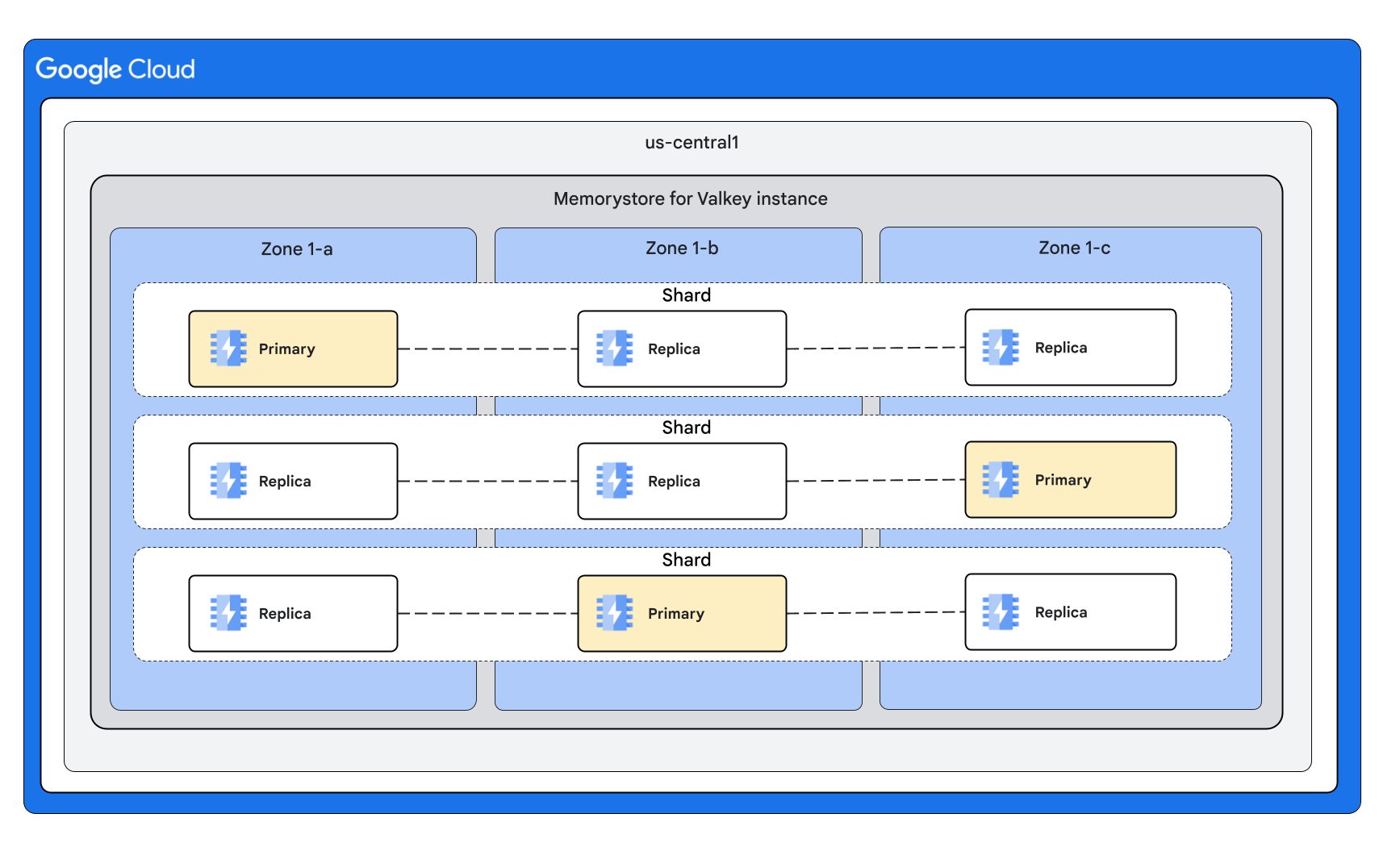
Diseños de instancias con el modo de clúster inhabilitado
En los siguientes diagramas se muestran las formas de las instancias con el modo de clúster inhabilitado:
Con 2 réplicas
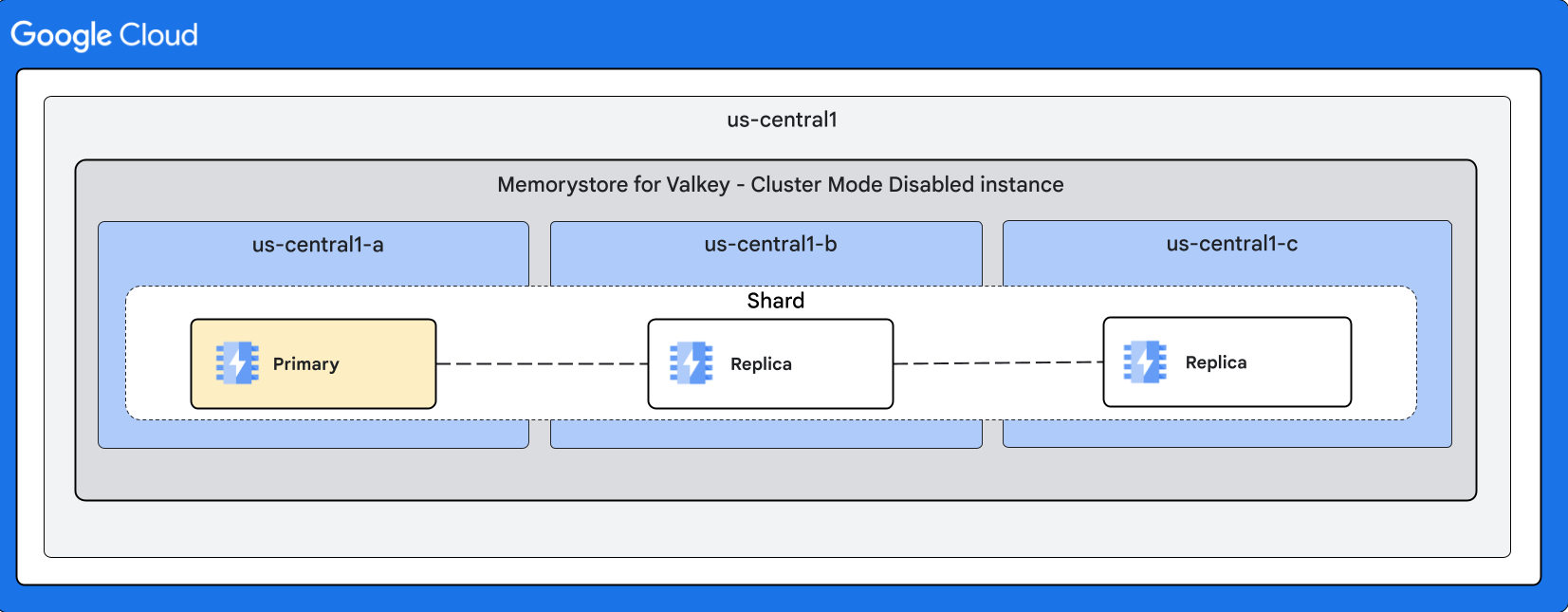
Conmutación por error automática
Las conmutaciones por error automáticas en un fragmento pueden producirse debido a tareas de mantenimiento o a un fallo inesperado del nodo principal. Durante una conmutación por error, una réplica se convierte en la principal. Puedes configurar las réplicas explícitamente. El servicio también puede aprovisionar temporalmente réplicas adicionales durante el mantenimiento interno para evitar tiempos de inactividad.
Las conmutaciones por error automáticas evitan la pérdida de datos durante las actualizaciones de mantenimiento. Para obtener información sobre el comportamiento de la conmutación por error automática durante el mantenimiento, consulta Comportamiento de la conmutación por error automática durante el mantenimiento.
Duración de la conmutación por error y la reparación de nodos
Las conmutaciones por error automáticas pueden tardar decenas de segundos en el caso de eventos imprevistos, como un fallo en el proceso del nodo principal o un fallo de hardware. Durante este tiempo, el sistema detecta el fallo y elige una réplica para que sea la nueva principal.
La reparación de nodos puede llevar varios minutos hasta que el servicio sustituya el nodo que ha fallado. Esto se aplica a todos los nodos principales y de réplica. En las instancias que no son de alta disponibilidad (no se han aprovisionado réplicas), la reparación de un nodo principal con errores también lleva unos minutos.
Comportamiento del cliente durante una conmutación por error no planificada
Es probable que las conexiones de cliente se restablezcan en función de la naturaleza del fallo. Después de la recuperación automática, las conexiones se deben reintentar con retroceso exponencial para evitar sobrecargar los nodos principales y de réplica.
Los clientes que usen réplicas para el rendimiento de lectura deben prepararse para una degradación temporal de la capacidad hasta que el nodo con errores se sustituya automáticamente.
Escrituras perdidas
Durante una conmutación por error provocada por un fallo inesperado, es posible que se pierdan las escrituras confirmadas debido a la naturaleza asíncrona del protocolo de replicación de Valkey.
Las aplicaciones cliente pueden usar el comando WAIT de Valkey para mejorar la seguridad de los datos en situaciones reales.
Impacto en el espacio de claves de una interrupción de servicio en una sola zona
En esta sección se describe el impacto de una interrupción en una sola zona en una instancia de Memorystore for Valkey.
Instancias multizona
Instancias de alta disponibilidad: si una zona sufre una interrupción, todo el espacio de claves estará disponible para lecturas y escrituras, pero, como algunas réplicas de lectura no estarán disponibles, la capacidad de lectura se reducirá. Te recomendamos que aprovisiones en exceso la capacidad del clúster para que la instancia tenga suficiente capacidad de lectura en el caso poco probable de que se produzca una interrupción en una sola zona. Una vez que se haya solucionado la interrupción, se restaurarán las réplicas de la zona afectada y la capacidad de lectura del clúster volverá al valor configurado. Para obtener más información, consulta Patrones para aplicaciones escalables y fiables.
Instancias sin alta disponibilidad (sin réplicas): si una zona sufre una interrupción, la parte del espacio de claves aprovisionada en la zona afectada experimenta un vaciado de datos y no está disponible para lecturas ni escrituras durante la interrupción. Una vez que se haya solucionado la interrupción, se restaurarán los primarios de la zona afectada y la capacidad del clúster volverá al valor configurado.
Instancias de una sola zona
- Instancias de alta disponibilidad y sin alta disponibilidad: si la zona en la que se aprovisiona la instancia sufre una interrupción, el clúster no estará disponible y los datos se borrarán. Si se produce una interrupción en otra zona, el clúster seguirá atendiendo las solicitudes de lectura y escritura.
Prácticas recomendadas
En esta sección se describen las prácticas recomendadas para la alta disponibilidad y las réplicas.
Añadir una réplica
Para añadir una réplica, se necesita una instantánea de RDB. Las copias de seguridad de RDB usan una bifurcación de procesos y un mecanismo de copia al escribir para crear una copia de seguridad de los datos de los nodos. En función del patrón de escritura en los nodos, la memoria utilizada de los nodos aumenta a medida que se copian las páginas afectadas por las escrituras. La huella de memoria puede ser hasta el doble del tamaño de los datos del nodo.
Para asegurarte de que los nodos tengan suficiente memoria para completar la instantánea, mantén o define maxmemory en el 80% de la capacidad del nodo para que el 20% se reserve para la sobrecarga. Esta sobrecarga de memoria, además de las instantáneas de monitorización, te ayuda a gestionar tu carga de trabajo para que las instantáneas se creen correctamente. Además, cuando añadas réplicas, reduce el tráfico de escritura tanto como sea posible. Para obtener más información, consulta Monitorizar el uso de memoria de una instancia.