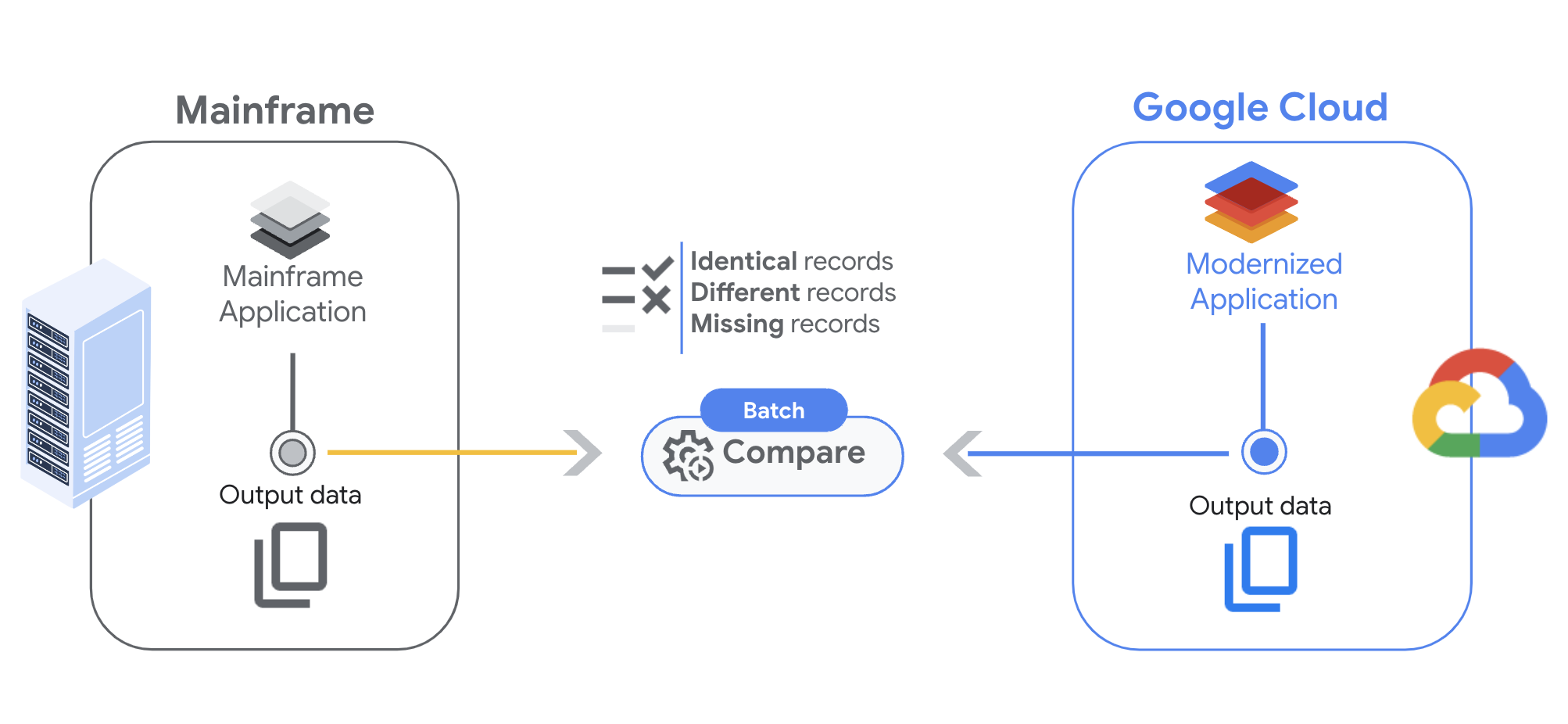
This page describes Dual Run File Comparison, which is designed to help you compare the outputs of batch workloads. With this feature, you can ensure that the batch jobs running on the mainframe and on Google Cloud generate identical outputs for the same given inputs.
How file comparisons work
Dual Run's file comparison feature lets you analyze files by first configuring the comparison settings, then setting up the triggers to start the process, and finally reviewing the results.
Learn how file comparison works in the following sections.
File transfer from the mainframe
Before you can run a file comparison, the first step is to transfer files from the mainframe to a Cloud Storage bucket in Google Cloud.
You can transfer files from the mainframe in two ways:
- with FTP/HTTPS transfers
- with the Mainframe Connector.
In both cases, Dual Run can read EBCDIC formats, and supports
UNLOAD output without the need for any additional transformation.
Comparison configuration
Dual Run provides you with full flexibility on how to compare your mainframe and modernized files. For each file, you specify which fields to compare, and their expected formats.
Dual Run file comparison supports advanced configurable options, such as data obfuscation, tolerance settings, field merging, custom labels, and filtering for precise and flexible file analysis.
- Obfuscate specific fields when you perform the file comparison. This is useful for hiding sensitive data that shouldn't appear in the reports or in the dashboards as clearly visible content.
- Allow for tolerance when comparing numeric values of specific fields. This is useful when comparing floating point numbers originating from different systems.
- Allow tolerance when comparing timestamp values of specific fields. This is useful when comparing timestamps originating from different systems.
- Merge multiple fields together with an optional joining string, and treat them as a single field during the comparison.
- Configure custom labels to categorize your comparison jobs. Labels are key-value pairs that you can use to tag your comparison jobs, and to differentiate them between different functional or business objectives.
- Ignore leading and trailing whitespaces in specific fields.
- Ignore letter case in strings.
- Apply filters to ignore records during the comparison, allowing multiple filters to be applied at the same time.
Automated configuration generation
Dual Run provides you with automated tools to help configure File Comparison. These tools create the required configuration files based on your mainframe copybooks, or based on sample JSON and CSV files that you provide.
Comparison results
When comparing two files, Dual Run returns three possible results:
- Full match: the record is present in both files, and the fields content matches within your specified constraints.
- Partial match: the record is present in both files, but some of the fields don't match. You can check the differences in the results output.
- Missing record: the record is present only in the actual or expected files.
In case of a mismatch between the compared files, you can configure Dual Run to show all the compared records within the files, and not just the mismatched records, for easier troubleshooting.
Dual Run offers a feature called deferred comparisons to address situations where data might be temporarily missing. This is particularly useful for iterative comparisons, like those performed on daily database snapshots. If a field is absent in one iteration but appears in the next, Dual Run stores and compares it later, ensuring that no data discrepancies are created. This provides a more robust and accurate comparison process, especially for dynamic datasets.
Supported files
Dual Run supports the following files for comparison:
- z/OS fixed block sequential files
- JSON array files
- JSON Lines (JSONL) files
- CSV files
Supported z/OS data types
Dual Run supports the following z/OS data types, both in EBCDIC and ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
Supported JSON files
Dual Run supports the following JSON formats:
- JSONL: in this file, each line contains a single JSON object. No newlines are present within the object.
- JSON array: in this file, two types of files are supported:
- A JSON array where the entire array and elements are in a single line. There are no newlines at all in this file.
- A JSON array with a newline separating the elements in the array. Each JSON object can contain newlines as well.
Supported CSV files
Dual Run supports CSV files that follow the RFC 4180 standard. You can configure how Dual Run parses the file, including delimiters, headers, escape characters, and multiline.
What's next
Learn how to install and start using Dual Run.