메인프레임에서 로컬로 데이터를 트랜스코딩하는 것은 CPU 집약적인 프로세스이므로 MIPS(초당 백만 명령) 소비량이 높아집니다. 이를 방지하려면 Cloud Run을 사용하여Google Cloud에서 원격으로 메인프레임 데이터를 이동하고 트랜스코딩할 수 있습니다. 이렇게 하면 비즈니스에 중요한 작업을 위한 메인프레임이 확보되고 MIPS 소비가 줄어듭니다.
메인프레임에서 Google Cloud로 대량의 데이터 (하루 약 500GB 이상)를 이동하고 이러한 작업에 메인프레임을 사용하지 않으려면 클라우드 사용 설정된 가상 테이프 라이브러리 (VTL) 솔루션을 사용하여 데이터를 Cloud Storage 버킷으로 전송할 수 있습니다. 그런 다음 Cloud Run을 사용하여 버킷에 있는 데이터를 트랜스코딩하고 BigQuery로 이동할 수 있습니다.
이 페이지에서는 Cloud Storage 버킷에 복사된 메인프레임 데이터를 읽고, 확장 바이너리 코딩 십진수 교환 코드(EBCDIC) 데이터 세트에서 UTF-8 형식의 ORC 형식으로 트랜스코딩하고, 해당 데이터 세트를 BigQuery 테이블에 로드하는 방법을 설명합니다.
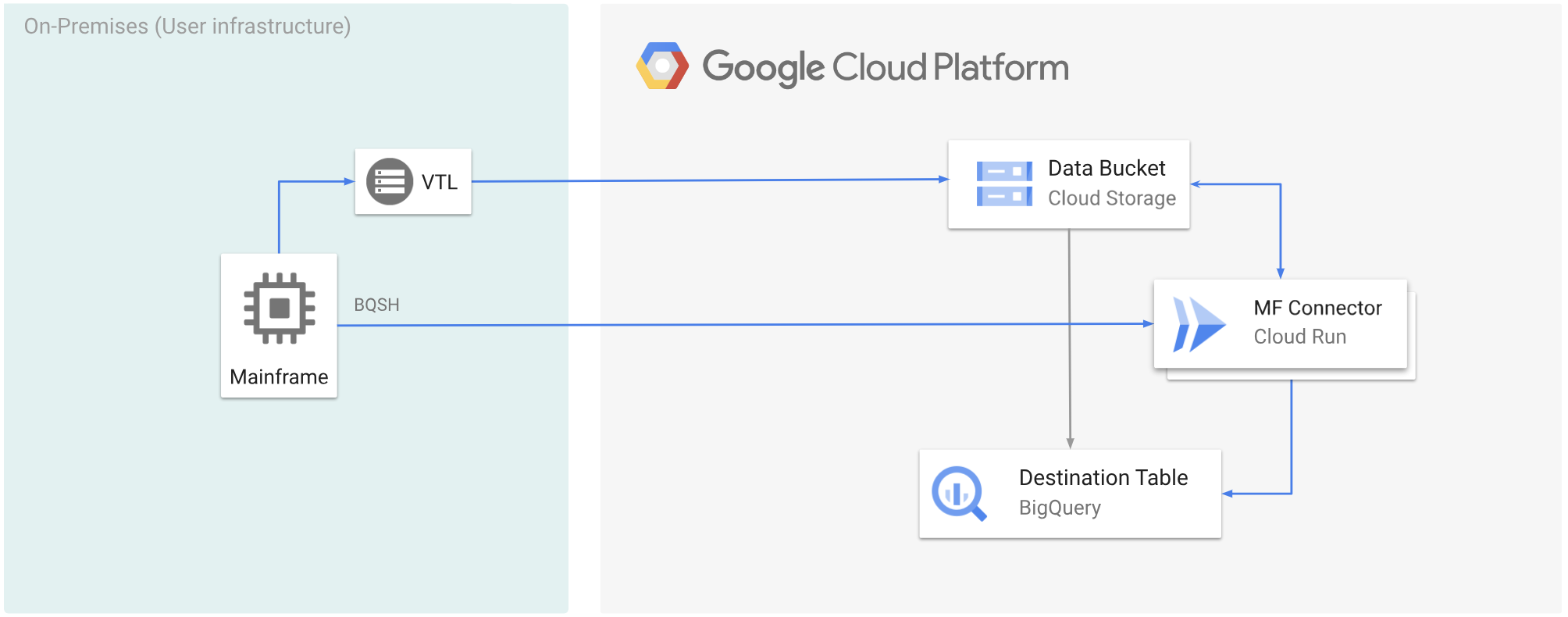
다음 다이어그램은 VTL 솔루션을 사용하여 메인프레임 데이터를 Cloud Storage 버킷으로 이동하고, Cloud Run을 사용하여 데이터를 ORC 형식으로 트랜스코딩한 후 콘텐츠를 BigQuery로 이동하는 방법을 보여줍니다.
시작하기 전에
- 요구사항에 맞는 VTL 솔루션을 선택하고 메인프레임 데이터를 Cloud Storage 버킷으로 이동하여
.dat로 저장합니다. 업로드된.dat파일에x-goog-meta-lrecl라는 메타데이터 키를 추가하고 메타데이터 키 길이가 원본 파일의 레코드 길이(예: 80)와 동일한지 확인합니다. - Cloud Run에 Mainframe Connector를 배포합니다.
- 메인프레임에서
GCSDSNURI환경 변수를 Cloud Storage 버킷의 메인프레임 데이터에 사용한 프리픽스로 설정합니다.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: Cloud Storage 버킷의 이름입니다.
- PREFIX: 버킷에서 사용할 프리픽스입니다.
- 서비스 계정을 만들거나 Mainframe Connector에 사용할 기존 서비스 계정을 식별합니다. 이 서비스 계정에는 Cloud Storage 버킷, BigQuery 데이터 세트, 사용하려는 기타 모든 Google Cloud 리소스에 액세스할 수 있는 권한이 있어야 합니다.
- 만든 서비스 계정에 Cloud Run 호출자 역할이 할당되어 있는지 확인합니다.
Cloud Storage 버킷에 업로드된 메인프레임 데이터 트랜스코딩
VTL을 사용하여 메인프레임 데이터를 Google Cloud 로 이동하고 원격으로 트랜스코딩하려면 다음 작업을 수행해야 합니다.
- Cloud Storage 버킷에 있는 데이터를 읽고 ORC 형식으로 트랜스코딩합니다. 트랜스코딩 작업은 메인프레임 EBCDIC 데이터 세트를 UTF-8의 ORC 형식으로 변환합니다.
- 데이터 세트를 BigQuery 테이블에 로드합니다.
- (선택사항) BigQuery 테이블에서 SQL 쿼리를 실행합니다.
- (선택사항) BigQuery의 데이터를 Cloud Storage의 바이너리 파일로 내보냅니다.
이 태스크를 수행하려면 다음 단계를 따르세요.
메인프레임에서 Cloud Storage 버킷의
.dat파일에서 데이터를 읽고 다음과 같이 ORC 형식으로 트랜스코딩하는 작업을 만듭니다.Mainframe Connector에서 지원하는 환경 변수의 전체 목록은 환경 변수를 참조하세요.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*다음을 바꿉니다.
PROJECT_NAME: 쿼리를 실행할 프로젝트의 이름입니다.INPUT_FILENAME: Cloud Storage 버킷에 업로드한.dat파일의 이름입니다.
이 프로세스 중에 실행된 명령어를 로깅하려면 로드 통계를 사용 설정하면 됩니다.
(선택사항) QUERY DD 파일에서 SQL 읽기를 실행하는 BigQuery 쿼리 작업을 만들고 제출합니다. 일반적으로 쿼리는 BigQuery 테이블을 변환하는
MERGE또는SELECT INTO DML문이 됩니다. Mainframe Connector는 작업 측정항목을 로깅하지만 쿼리 결과를 파일에 쓰지는 않습니다.DD를 사용하는 별도의 데이터세트 또는 DSN을 사용하는 별도의 데이터세트를 사용하는 등 다양한 방법으로 BigQuery를 인라인으로 쿼리할 수 있습니다.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*다음을 바꿉니다.
PROJECT_NAME: 쿼리를 실행할 프로젝트의 이름입니다.LOCATION: 쿼리가 실행될 위치입니다. 데이터와 가까운 위치에서 쿼리를 실행하는 것이 좋습니다.
(선택사항) QUERY DD 파일에서 SQL 읽기를 실행하는 내보내기 작업을 만들어 제출하고 결과 데이터 세트를 Cloud Storage에 바이너리 파일로 내보냅니다.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*다음을 바꿉니다.
PROJECT_NAME: 쿼리를 실행할 프로젝트의 이름입니다.DATASET_ID: 내보내려는 테이블이 포함된 BigQuery 데이터 세트 ID입니다.DESTINATION_TABLE: 내보내려는 BigQuery 테이블입니다.BUCKET: 출력 바이너리 파일이 포함될 Cloud Storage 버킷입니다.