La transcodificación de datos de forma local en un mainframe es un proceso que requiere mucha CPU y que conlleva un alto consumo de millones de instrucciones por segundo (MIPS). Para evitarlo, puedes usar Cloud Run para mover y transcodificar datos de mainframe de forma remota enGoogle Cloud al formato de columnas de filas optimizado (ORC) y, a continuación, mover los datos a Cloud Storage. De esta forma, tu mainframe puede centrarse en las tareas empresariales críticas y también se reduce el consumo de MIPS.
En la siguiente figura se describe cómo puede mover los datos de su mainframe aGoogle Cloud y transcodificarlos de forma remota al formato ORC mediante Cloud Run. A continuación, puede mover el contenido a BigQuery.
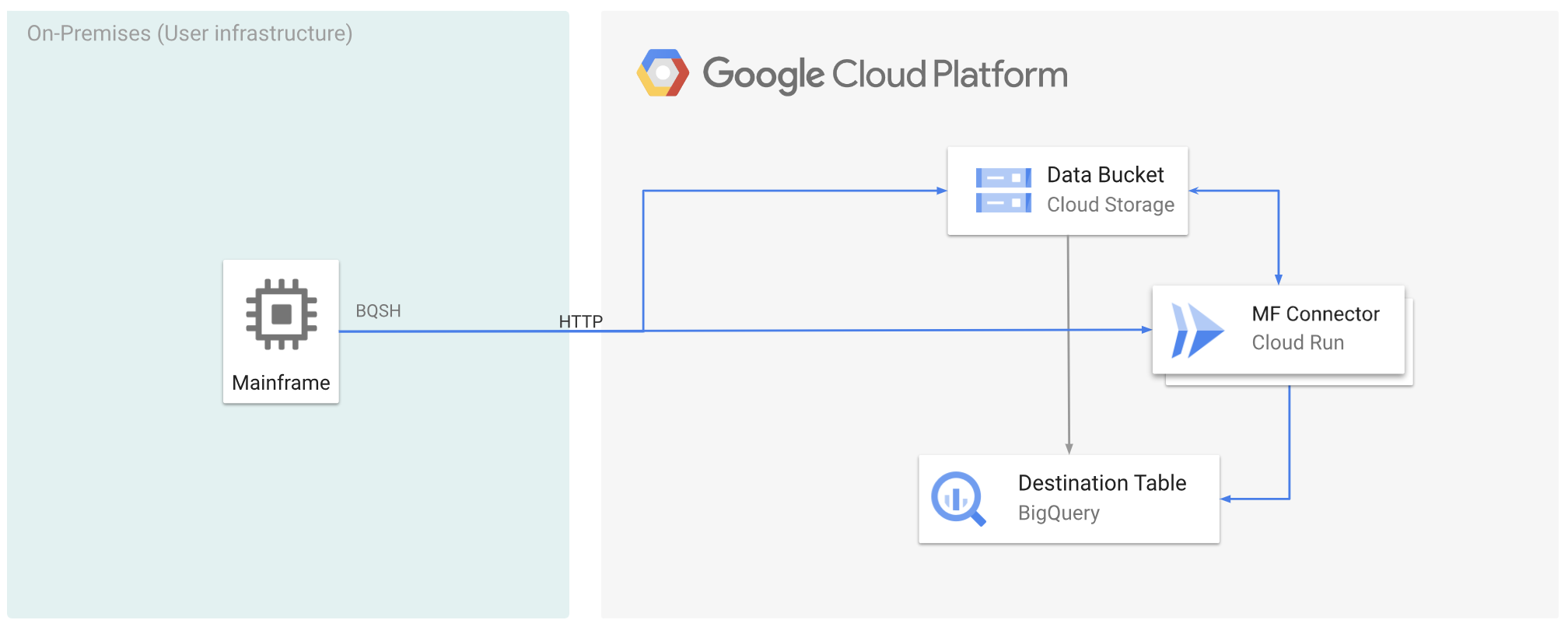
Antes de empezar
- Despliega Mainframe Connector en Cloud Run.
- Crea una cuenta de servicio o identifica una cuenta de servicio que ya tengas para usarla con Mainframe Connector. Esta cuenta de servicio debe tener permisos para acceder a los cubos de Cloud Storage, los conjuntos de datos de BigQuery y cualquier otro Google Cloud recurso que quieras usar.
- Comprueba que la cuenta de servicio que has creado tenga asignado el rol Invocador de Cloud Run.
Mover datos de mainframe a Google Cloud y transcodificarlos de forma remota con Cloud Run
Para mover los datos de tu mainframe a Google Cloud y transcodificarlos de forma remota con Cloud Run, debes realizar las siguientes tareas:
- Leer y transcodificar un conjunto de datos en un mainframe, y subirlo a Cloud Storage en formato ORC. La transcodificación se realiza durante la operación
gsutil cp, en la que un conjunto de datos de código de intercambio decimal codificado en binario extendido de mainframe (EBCDIC) se convierte al formato ORC en UTF-8 durante la copia en un segmento de Cloud Storage. - Carga el conjunto de datos en una tabla de BigQuery.
- Opcional: Ejecuta una consulta de SQL en la tabla de BigQuery.
- Opcional: Exporta datos de BigQuery a un archivo binario en Cloud Storage.
Para llevar a cabo estas tareas, sigue estos pasos:
En tu mainframe, crea un trabajo para leer el conjunto de datos de tu mainframe y transcodificarlo al formato ORC, tal como se indica a continuación. Lee los datos del conjunto de datos INFILE y el diseño de registro del COPYBOOK DD. El conjunto de datos de entrada debe ser un archivo de método de acceso secuencial en cola (QSAM) con una longitud de registro fija o variable.
Para ver la lista completa de variables de entorno admitidas por Mainframe Connector, consulta Variables de entorno.
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Si quieres registrar los comandos ejecutados durante este proceso, puedes habilitar las estadísticas de carga.
Opcional: Crea y envía un trabajo de consulta de BigQuery que ejecute una lectura de SQL desde el archivo DD de QUERY. Normalmente, la consulta será una instrucción
MERGEoSELECT INTO DMLque dé como resultado la transformación de una tabla de BigQuery. Ten en cuenta que Mainframe Connector registra las métricas de los trabajos, pero no escribe los resultados de las consultas en un archivo.Puede consultar BigQuery de varias formas: de forma insertada, con un conjunto de datos independiente mediante DD o con un conjunto de datos independiente mediante DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*Además, debes definir la variable de entorno
BQ_QUERY_REMOTE_EXECUTION=true.Haz los cambios siguientes:
PROJECT_NAME: el nombre del proyecto en el que quieres ejecutar la consulta.LOCATION: la ubicación en la que se ejecutará la consulta. Te recomendamos que ejecutes la consulta en una ubicación cercana a los datos.
Opcional: Crea y envía una tarea de exportación que ejecute una lectura de SQL desde el archivo QUERY DD y exporte el conjunto de datos resultante a Cloud Storage como un archivo binario.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Haz los cambios siguientes:
PROJECT_NAME: el nombre del proyecto en el que quieres ejecutar la consulta.DATASET_ID: ID del conjunto de datos de BigQuery que contiene la tabla que quiere exportar.DESTINATION_TABLE: la tabla de BigQuery que quiere exportar.BUCKET: el segmento de Cloud Storage que contendrá el archivo binario de salida.
Siguientes pasos
- Mover datos de mainframe transcodificados localmente a Google Cloud
- Transcodificar datos de mainframe de forma remota en Google Cloud
- Transcodificar datos de mainframe transferidos a Google Cloud mediante una biblioteca de cintas virtuales