Mainframe Connector는 qsam 명령어를 사용하여 큐에 추가된 순차 액세스 메서드 (QSAM) 일반 파일을 Google Cloud 호환 형식으로 트랜스코딩하고 그 반대로도 트랜스코딩합니다. Mainframe Connector는 vsam decode 명령어를 사용하여 가상 저장소 액세스 방법 (VSAM) 파일을 Google Cloud호환 형식으로 트랜스코딩하는 것도 지원합니다. qsam 및 vsam 명령어는 다음 트랜스코딩 작업을 실행합니다.
qsam decode명령어는 QSAM 플랫 파일을 Google Cloud 호환 형식으로 디코딩합니다.qsam encode명령어는 Google Cloud 데이터를 메인프레임에 인코딩합니다.vsam decode명령어는 VSAM 파일을 Google Cloud 호환 형식으로 디코딩합니다.
이러한 작업은 대칭 변환을 실행합니다. 즉, 동일한 데이터를 Google Cloud로 이동하고 Google Cloud에서 이동합니다. COBOL 데이터 구조 정의를 사용하여 카피북 파일에서 QSAM 또는 VSAM 파일의 구조를 정의할 수 있습니다. Mainframe Connector 트랜스코더 구성 파일을 사용하여 고급 변환을 정의할 수도 있습니다. 다음 다이어그램에서는 이러한 작업을 자세히 설명합니다.
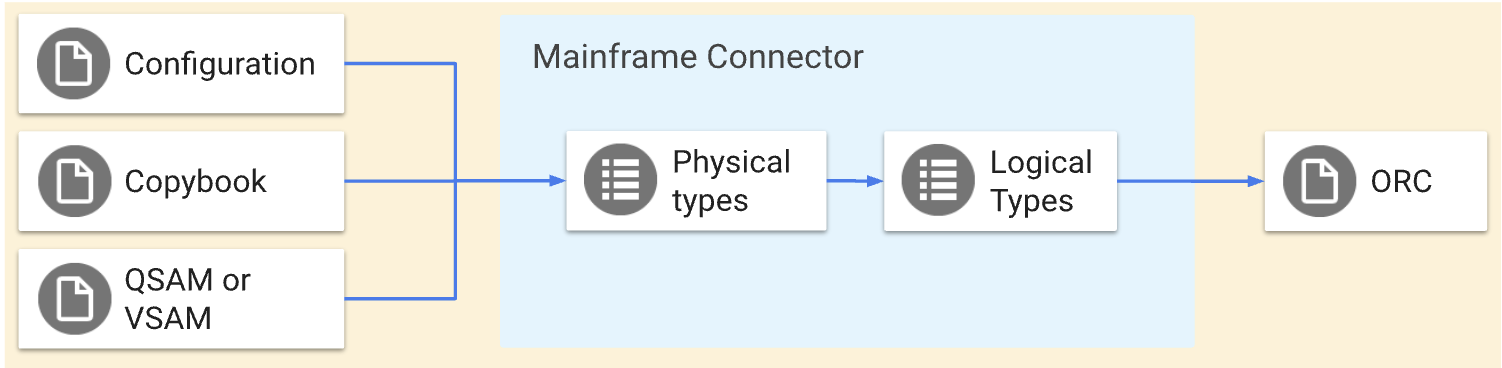

이 페이지에서는 qsam decode, qsam encode, vsam decode 명령어를 사용한 트랜스코딩 프로세스, 메인프레임 데이터의 물리적 유형과 논리적 유형, 최적화된 행 열 형식 (ORC) 및 BigQuery 유형 매핑을 간략하게 설명합니다.
물리적 유형
물리적 유형은 필드 데이터가 디스크에 배치되는 방식을 정의합니다. 물리적 유형은 메인프레임 커넥터 논리 유형으로 변환되며, 이 유형은 데이터베이스 유형 (ORC 또는 BigQuery)에 매핑될 수 있습니다.
영숫자 필드
영숫자 필드는 영숫자 문자열을 처리하는 데 사용됩니다. 데이터는 일련의 문자로 처리되며 확장 바이너리 코딩 십진수 교환 코드 (EBCDIC)와 같은 특정 인코딩을 사용하여 문자열로 저장됩니다.
영숫자 필드의 인코딩 또는 디코딩 중에 오류가 발생해도 트랜스코딩 프로세스가 종료되지 않습니다. 대신 인코딩의 SUB 문자가 오류가 발생한 위치에 배치되고 트랜스코딩 프로세스가 계속됩니다.
| 사진 기호 | 사진 속성 | 논리 유형 |
|---|---|---|
| A, B, G, N, U, X, 9 | DISPLAY, DISPLAY-1, NATIONAL, UTF-8 | 문자열 |
예시
01 REC 02 STR PIC X(10) 02 NATIONAL PIC N(10) 02 UTF8 PIC U(1) USAGE UTF-8
인코딩 형식
영숫자 필드는 다음과 같이 인코딩됩니다.
- X 필드는 기본적으로 EBCDIC 인코딩으로 설정됩니다.
- 국가 (N) 필드는 기본적으로 유니코드 변환 형식 16비트(UTF-16 BE) 인코딩을 사용합니다.
- UTF8 필드는 기본적으로 유니코드 변환 형식-8 (UTF-8) 인코딩을 사용합니다.
Mainframe Connector는 대부분의 싱글바이트 문자 세트(SBCS), 더블바이트 문자 세트 (DBCS) 인코딩을 지원합니다. 필요한 경우 자체 맞춤 SBCS 인코딩을 정의할 수도 있습니다.
이진 필드 (COMPUTATIONAL)
바이너리 필드는 부호 있는 또는 부호 없는 big-endian 정수로 저장됩니다. Mainframe Connector는 항상 바이너리 필드를 논리적으로 부호 있는 64비트 정수로 저장합니다. 따라서 부호 없는 긴 입력은 하위 63비트만 사용해야 합니다. 그렇지 않으면 트랜스코딩 프로세스가 실패합니다.
| 사진 기호 | 사진 속성 | 논리 유형 |
|---|---|---|
| S, 9 | COMP, COMPUTATIONAL | Long (부호 있는 64비트 정수) |
예시
01 REC 02 INT PIC S9(8) COMP
16진수 부동 소수점 필드 (COMP-1, COMP-2)
16진수 부동 소수점 (HFP) 필드가 완전히 지원됩니다. Mainframe Connector는 HFP 필드에 단정밀도 형식과 배정밀도 형식을 모두 사용합니다.
| 사진 기호 | 사진 속성 | 논리 유형 |
|---|---|---|
| COMP-1, COMP-2 | Double (64비트 부호 있는 부동 소수점) |
예시
01 REC 03 HFP-SINGLE COMP-1. 03 HFP-DOUBLE COMP-2.
패킹된 십진수 필드 (COMP-3)
패킹된 십진수 필드는 완전히 지원됩니다. 트랜스코딩 프로세스 중에 Mainframe Connector는 지정된 정밀도와 스케일을 기반으로 가장 성능이 좋은 논리적 유형을 선택합니다.
| 사진 기호 | 사진 속성 | 논리 유형 |
|---|---|---|
| S, 9, V | COMP-3 | Long (부호 있는 64비트 정수), BigInteger, Decimal64, BigDecimal |
예시
01 REC 02 DEC PIC S9(2)V9(8) COMP-3
구역화된 십진수 필드 (DISPLAY)
영역화된 십진수 필드는 완전히 지원됩니다. 트랜스코딩 프로세스 중에 Mainframe Connector는 지정된 정밀도와 스케일을 기반으로 가장 성능이 좋은 논리적 유형을 선택합니다.
| 사진 기호 | 사진 속성 | 논리 유형 |
|---|---|---|
| S, 9, V | 디스플레이 | Long (부호 있는 64비트 정수), BigInteger, Decimal64, BigDecimal |
예시
01 REC 02 DEC PIC S9(2)V9(8) DISPLAY
목록 (OCCURS)
목록은 동일한 유형의 요소로 구성된 정렬된 컬렉션입니다. Mainframe Connector는 다음과 같은 유형의 목록을 지원합니다.
고정 목록
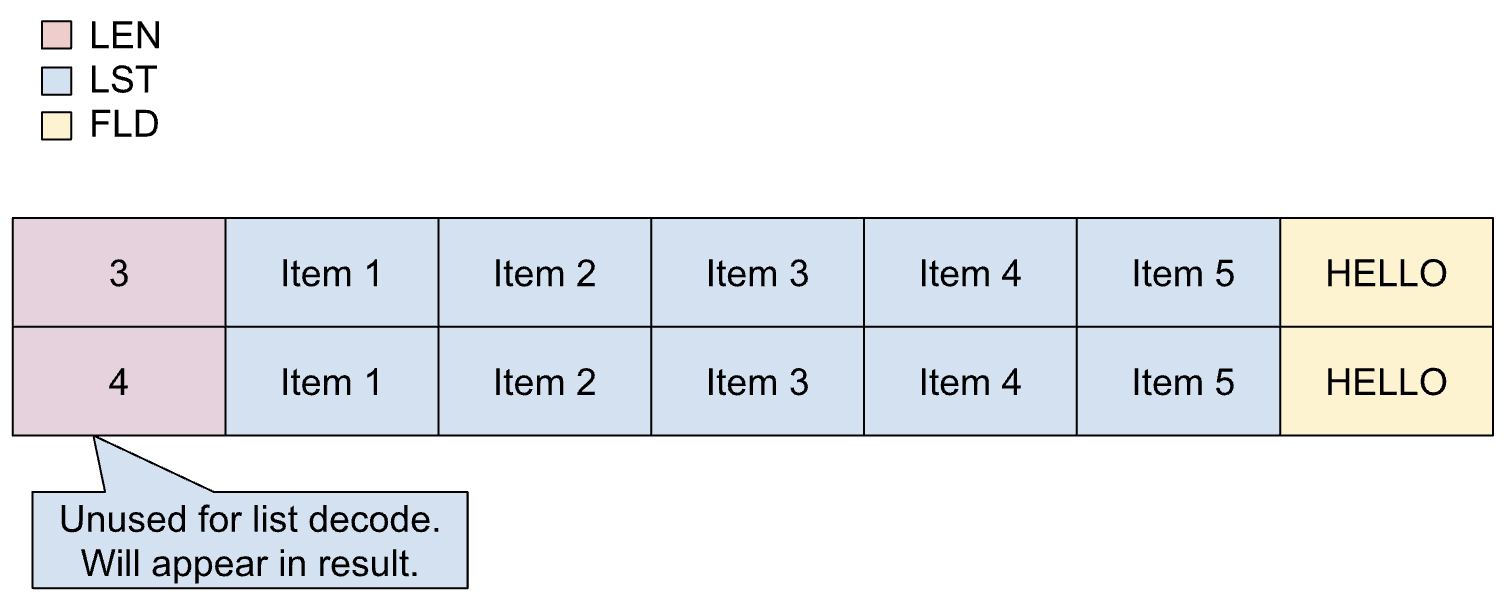
고정 목록은 목록에 포함될 항목의 정확한 수 (항목 수)를 미리 알고 있으며 이 수가 항상 동일하게 유지되는 경우에 사용됩니다. 고정 목록의 항목은 크기가 다양할 수 있습니다.
고정 목록은 카피북에서 다음과 같이 정의됩니다.
01 REC.
02 LIST OCCURS 5 TIMES PIC X(1).
02 FLD PIC X(5).
다음 이미지는 항목 수가 5인 고정 목록의 레이아웃을 보여줍니다.
동적 목록
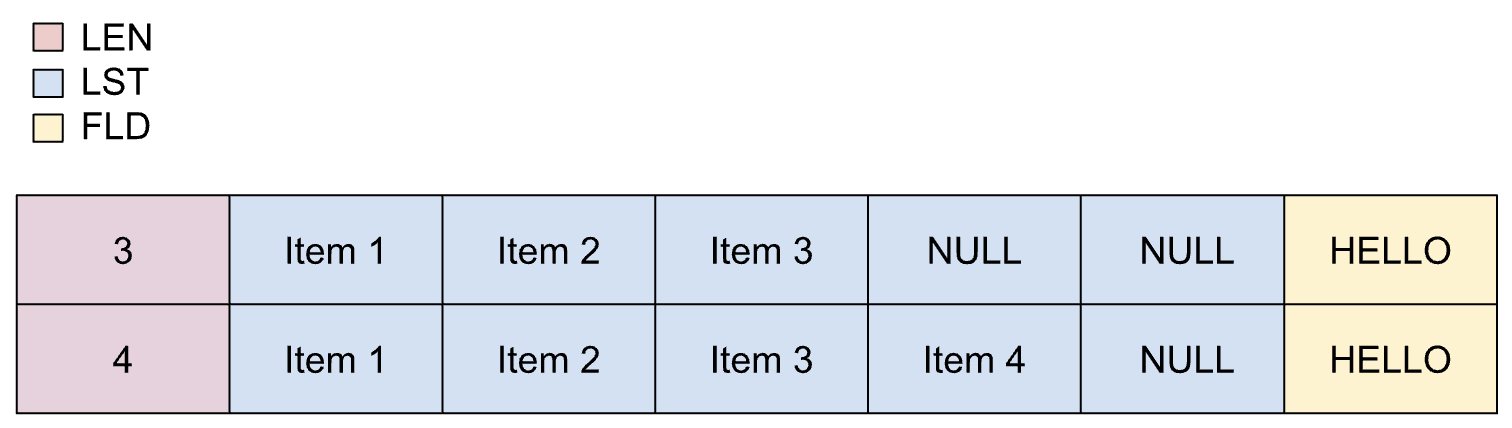
동적 목록은 목록에 포함될 최대 항목 수를 미리 알 때 사용됩니다. 하지만 실제 항목 수는 알 수 없으며 다른 필드에 따라 달라집니다. 동적 목록의 항목은 크기가 다양할 수 있습니다.
동적 목록의 속성은 다음과 같습니다.
- 길이 필드는 정밀도 손실 없이 정수로 변환할 수 있습니다.
- 길이 필드는 범위에 있어야 합니다.
- 트랜스코딩 프로세스 중에는 최소 항목 수가 적용되지 않습니다.
동적 목록은 카피북에서 다음과 같이 정의됩니다.
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS 1 TO 5 TIMES
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
다음 이미지는 항목 수가 최대 5개인 동적 목록의 레이아웃을 보여줍니다.
패키지된 동적 목록
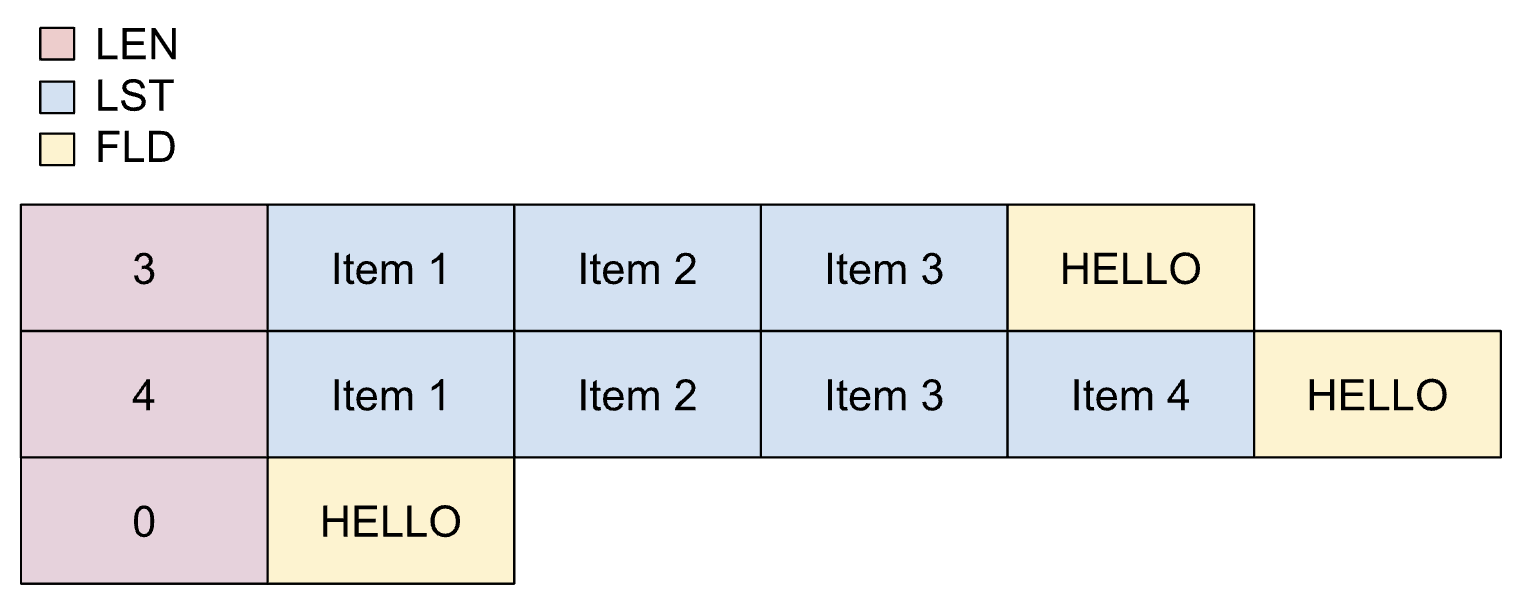
패킹된 동적 목록은 목록에 포함될 최대 항목 수가 다른 필드에 따라 달라지고 항목이 패킹될 때 사용됩니다.
패킹된 동적 목록의 속성은 다음과 같습니다.
- 길이 필드는 정밀도 손실 없이 정수로 변환할 수 있습니다.
- 길이 필드는 범위에 있어야 합니다.
- 트랜스코딩 프로세스 중에는 최소 항목 수가 적용되지 않습니다.
패킹된 동적 목록은 카피북에서 다음과 같이 정의됩니다.
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS UNBOUNDED
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
다음 이미지는 패킹된 동적 목록의 레이아웃을 보여줍니다.
재정의 (REDEFINES)
재정의는 동일한 데이터에 여러 디코딩 가능성이 있도록 하는 COBOL 기능입니다. 디코딩 프로세스 중에 재정의가 결과 테이블에 추가 열로 표시되고 데이터가 여러 번 디코딩됩니다.
재정의의 속성은 다음과 같습니다.
- 동일한 기본 데이터에 대한 재정의는 형제 필드가 아니므로 서로의 범위에 속하지 않습니다.
- 재정의된 필드는 선언될 때가 아니라 기본 필드가 디코딩될 때 디코딩됩니다. 기본 필드는 재정의된 필드의 범위도 결정합니다.
- 재정의된 모든 필드의 크기는 동일해야 하며 고정 크기여야 합니다. 즉, 재정의된 필드에서 가변 길이 텍스트 필드와 패킹된 동적 목록을 사용할 수 없습니다.
재정의는 카피북에서 다음과 같이 정의됩니다.
01 Rec.
05 Field-1 PIC X(100).
05 Group-1 REDEFINES Field-1.
10 Field-2 PIC 9(5) comp-3.
10 Field-3 PIC X(96).
05 Group-2 REDEFINES Field-1.
10 Field-4 PIC 9(4) comp-4.
10 Field-5 PIC X(50).
10 Field-6 PIC X(46).
다음 이미지는 재정의된 필드의 레이아웃을 보여줍니다.
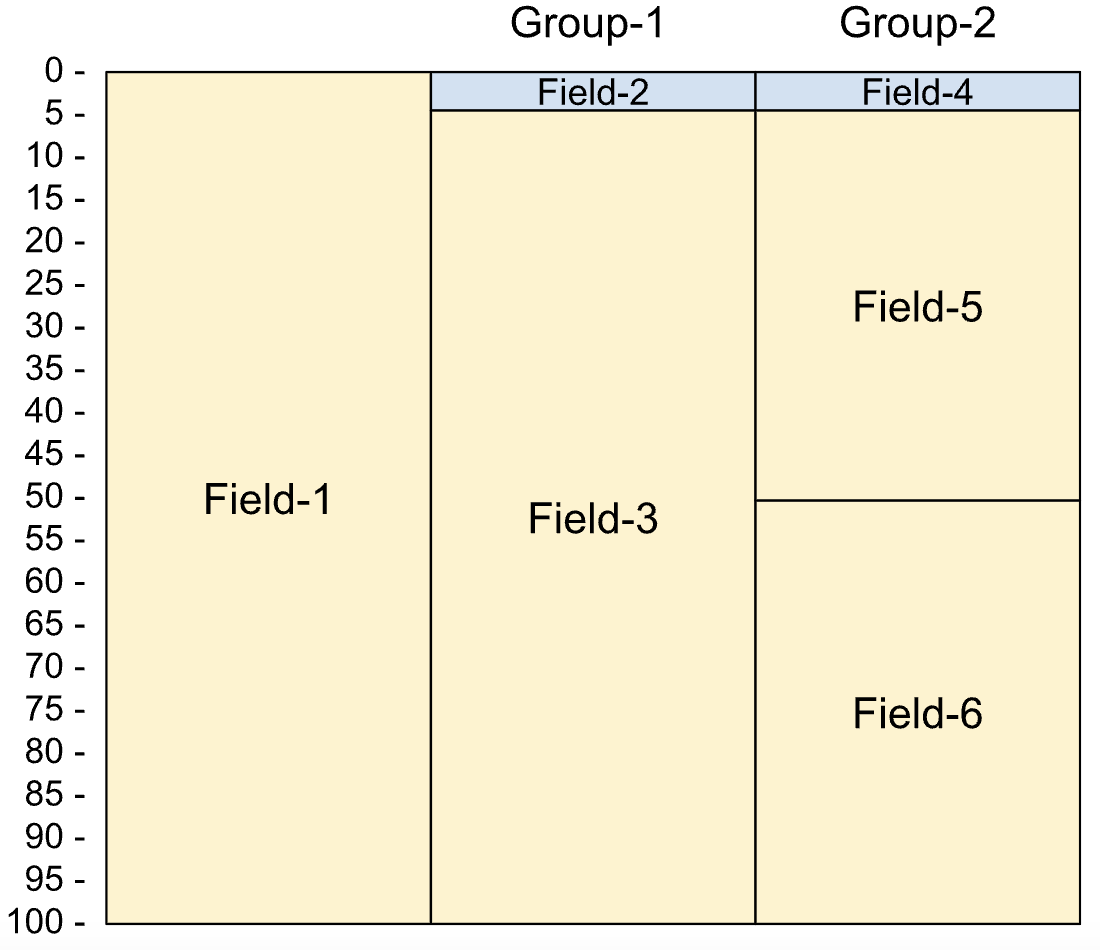
다음과 같은 가장 일반적인 방법을 비롯해 다양한 방법으로 재정의를 사용할 수 있습니다.
동일한 데이터를 두 가지 다른 방식으로 보기: 이는 재정의가 사용되는 가장 일반적인 방법입니다. 인코딩 프로세스 중에 데이터가 채워지는 순서는 정의되지 않으므로 내보낼 때 BigQuery의 데이터가 무결성을 유지해야 합니다.
예시
01 REC. 02 FULL-NAME PIC X(12). 02 NAME REDEFINES FULL-NAME. 05 FIRST-NAME PIC X(6). 05 LAST-NAME PIC X(6).태그가 지정된 공용체 사용: 태그가 지정된 공용체는 필드에 따라 레코드의 데이터 해석 중 하나만 필요한 경우 재정의를 사용하는 일반적인 방법입니다. null 표시기를 사용하여 불필요한 해석을 null로 표시할 수 있습니다. 또한 null 표시기에 지연 평가가 있으므로 파싱되지 않습니다. 태그된 공용체의 속성은 다음과 같습니다.
- 재정의가 두 개 이상 정의되면 인코딩 프로세스가 실패합니다.
- 동등성 및 비동등성 검사만 구현됩니다.
예시
01 REC. 05 TYPE PIC X(5). 05 DATA PIC X(100). 05 VARIANT-1 REDEFINES DATA. 10 Field-2 PIC 9(4) comp-3. 10 Field-3 PIC X(96). 05 VARIANT-2 REDEFINES DATA. 10 Field-4 PIC 9(4) comp-5. 10 Field-5 PIC X(50). 10 Field-6 PIC X(46).다음 예시를 사용하여 태그가 지정된 공용체를 구현할 수 있습니다.
{ "field_override": [ { "field": "VARIANT-1", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR1" } } }, { "field": "VARIANT-2", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR2" } } } ], "transformations": [ { "field": "DATA", "transformation": { "exclude": {}} } ] }
논리 유형
데이터를 여러 형식으로 트랜스코딩하기 위해 Mainframe Connector는 모든 데이터를 논리적 유형을 기반으로 하는 중간 표현 (IR)으로 변환합니다. 입력 및 출력 형식은 데이터가 논리 유형으로 또는 논리 유형에서 변환되는 방식을 정의합니다. 다음 표에는 Mainframe Connector에서 지원하는 모든 논리 유형이 나와 있습니다.
| 논리 유형 | 설명 |
|---|---|
| BigDecimal | 모든 스케일과 정밀도의 십진수를 나타냅니다. |
| BigInteger | 모든 크기의 정수를 나타냅니다. |
| 바이트 | 다양한 크기의 바이트 배열을 나타냅니다. |
| 날짜 | 특정 시간대와 무관한 날짜를 나타냅니다. |
| Decimal64 | 모든 스케일의 64비트 부호 있는 정수에 맞출 수 있는 범위를 갖는 십진수를 나타냅니다. |
| Double | IEEE 표준 부동 소수점 산술 (IEEE 754)에 설명된 대로 배정밀도 부동 소수점 수를 나타냅니다. |
| 목록 | 특정 유형의 항목 목록을 나타냅니다. 목록에는 임의 개수의 항목이 포함될 수 있습니다. |
| 길이 | 부호 있는 64비트 숫자를 나타냅니다. |
| 녹화 | 다양한 유형의 고정된 필드 시리즈를 나타냅니다. |
| 문자열 | 특정 인코딩과 관련이 없는 유니코드 문자열을 나타냅니다. 유효한 유니코드 코드 포인트는 모두 표현할 수 있습니다. 하지만 일부 문자는 모든 인코딩 프로세스에서 인코딩되지 않을 수 있습니다. 논리 문자열은 가변 길이입니다. |
| 타임스탬프 | 특정 시간대와 무관한 타임스탬프를 나타냅니다. |
ORC 유형 매핑
다음 표에서는 Mainframe Connector 논리 유형과 ORC 유형 간의 매핑을 보여줍니다.
| 논리 유형 | ORC 유형 |
|---|---|
| BigDecimal | 십진수 |
| BigInteger | 십진수 |
| 바이트 | 바이너리 blob |
| 날짜 | 날짜 |
| Decimal64 | decimal64 |
| Double | float64 |
| 목록 | list |
| 길이 | 64비트 정수 (bigint) |
| 녹화 | 구조체 |
| 문자열 | UTF-8로 인코딩된 문자열 |
| 타임스탬프 | 타임스탬프 (현지 시간대 제외) |
BigQuery 유형 매핑
다음 표에서는 Mainframe Connector 논리 유형과 BigQuery 데이터 유형 간의 매핑을 보여줍니다.
| 논리 유형 | BigQuery 데이터 유형 | 댓글 |
|---|---|---|
| BigDecimal | 숫자 형식 | |
| BigInteger | 숫자 형식 | |
| 바이트 | BYTES | |
| 날짜 | DATE | |
| Decimal64 | 숫자 형식 | |
| Double | FLOAT64 | |
| 목록 | ARRAY | 중첩 목록과 map 목록은 지원되지 않습니다. |
| 길이 | INT64 | |
| 녹화 | STRUCT | union에 변형이 하나뿐이라면 NULLABLE 필드로 변환됩니다.
그렇지 않으면 union은 NULLABLE 필드의 목록이 있는 RECORD로 변환됩니다.
NULLABLE 필드에는 field_0, field_1과 같은 서픽스가 있습니다. 데이터를 읽을 때는 이러한 필드 중 하나에만 값이 할당됩니다. |
| 문자열 | 문자열 | |
| 타임스탬프 | TIMESTAMP |
필드 범위
필드가 다음 중 하나인 경우 다른 필드의 범위 내에 있는 것으로 간주됩니다.
- 필요한 필드 앞에 정의된 형제 필드입니다.
- 필요한 필드보다 먼저 정의된 상위 레코드의 필드입니다.