O Mainframe Connector oferece suporte a duas versões do analisador de copybook:
- Analisador de copybook nativo: o analisador de copybook nativo implementa um analisador baseado em ANTLR4, oferece suporte a copybooks COBOL e é a versão recomendada do analisador.
- Analisador de copybook legado: é uma versão mais antiga do analisador que tem suporte a formatos de copybook muito limitados.
É possível definir qual analisador usar com base no seu livro de cópias. Para mais informações sobre como definir o analisador que você quer usar, consulte Definir o analisador de copybook.
Analisador de livro de cópias nativo
O analisador de cópia nativa é a versão mais recente do analisador e é usado por padrão. O analisador de copybook nativo implementa um analisador baseado em ANTLR4 e oferece suporte a copybooks COBOL.
Esta seção lista as tarefas de pré-processamento realizadas pelo analisador de cópias nativo. Ele também descreve os tipos de dados com suporte do analisador de copybook nativo e as restrições para o uso dele.
Pré-processamento
Antes de analisar um livro de cópias, o analisador de livros de cópias nativo pré-processa os dados e executa as seguintes tarefas:
- Remove linhas de comentário.
- Resolve a continuação da linha.
- Deixa em branco as áreas de número de linha e coluna 73.
- Preserva instruções específicas do pré-processador, como
EJECT,SPACEeTITLE. Esses campos são analisados, mas ignorados. Os copybooks que contêm parâmetros de pré-processador que podem ser usados porCOPY REPLACINGnão têm suporte do parser de copybook nativo. Nesses manuais, os identificadores são cercados por dois-pontos (:).
Restrições e tipos de dados aceitos
Confira a seguir os tipos de dados com suporte do analisador de copybook nativo e as restrições para o uso dele:
- Os níveis 66 (ALIAS) ou 77 (STANDALONE) não são compatíveis.
- Use apenas campos PICTURE. Os seguintes campos de IMAGEM são aceitos:
- Pic A, Pic, B, Pic G (DBCS), Pic N (nacional ou DBCS), Pic U (UTF8), Pic X e decimal zoneado (precisão máxima 38, escala máxima 38)
- O ponto flutuante hexadecimal (HFP) do IBM é aceito.
- REDEFINES não são aceitos.
- Use apenas os seguintes campos COMP. Não há suporte para ALIGN e OCCURS.
- COMP
- COMP4
- Binário
- COMP3
- PACKED-DECIMAL
- DATE e TIMESTAMP são aceitos.
- Indicadores nulos são aceitos.
- O campo conjunto de caracteres de dois bytes (DBCS, na sigla em inglês) Pic G e Pic N são
compatíveis e devem ser usados em vez de Pic T, que foi descontinuado. Para
usar o campo Pic N como DBCS sem especificar
USAGE DISPLAY-1, defina a variável de ambienteNSYMBOLcomoDBCS. Por padrão,NSYMBOLé definido comoNATIONAL, que defineUSAGE NATIONALcomo campos Pic N que não têm uma cláusulaUSAGE.NSYMBOLsó pode ser definido comoNATIONALouDBCS. - Strings de caracteres de comprimento variável são aceitas.
- A cláusula SIGN é compatível.
- Você precisa justificar todos os campos e usar um único nível de recuo.
- Comentários são aceitos.
Suporte a campos de data e carimbo de data/hora
O conector de mainframe oferece suporte à transferência de dados de data e carimbo de data/hora para dentro e fora do BigQuery. Para isso, defina variáveis de ambiente que começam
com a palavra SUFFIX no seguinte formato:
SUFFIX_SUFFIX_STRING="command --format FORMAT --timezone TIMEZONE"
A lista a seguir descreve o formato com mais detalhes:
SUFFIX_SUFFIX_STRING: a variável de ambiente que pode ser usada para definir dados de data e carimbo de data/hora. O nome SUFFIX_STRING corresponde aos sufixos-SUFFIX_STRINGou_SUFFIX_STRING, que precisam ser interpretados como uma data ou um carimbo de data/hora quando usados como sufixo de um nome de campo em um modelo. Verifique se o SUFFIX_STRING não contém um hífen ou sublinhado.command: define o decodificador que será usado para analisar o campo. Os comandos aceitos sãodate-converteretimestamp-converter.--format: um parâmetro que define o formato da data ou do carimbo de data/hora. É possível especificar no máximo cinco formatos diferentes separados por vírgulas. Se vários formatos corresponderem a uma determinada entrada, o primeiro formato que corresponder será usado para o carregamento no BigQuery. Se vários formatos forem especificados para exportação, apenas o primeiro será usado. Para mais informações sobre formatos válidos, consulte Formatos de data e carimbo de data/hora aceitos.--timezone: um parâmetro opcional para o tipoTIMESTAMP. Por padrão, o fuso horário é UTC. Para mais informações sobre os formatos de fuso horário compatíveis, consulte Formatos de fuso horário compatíveis.--omitsuffix(opcional): se esse parâmetro for especificado,-SUFFIX_STRINGou_SUFFIX_STRINGserá removido do nome do campo que aparece no BigQuery.
Para adicionar um alias a um SUFFIX_SUFFIX_STRING, defina
uma variável de ambiente SUFFIX_SUFFIX_ALIAS=$SUFFIX_SUFFIX_STRING.
Exemplos:
- Se você definir uma variável de ambiente como
SUFFIX_DT8="date-converter --format yyyyMMdd", um campo com sufixo-DT8ou_DT8será um campo do tipoDATEno BigQuery, e o padrão seráyyyyMMdd. - Se você definir uma variável de ambiente como
SUFFIX_DT10="date-converter --format MM-dd-yyyy", um campo com sufixo-DT10ou_DT10será um campo do tipoDATEno BigQuery, e o padrão seráMM-dd-yyyy. - Se você definir uma variável de ambiente como
SUFFIX_DT="date-converter --format 'MM-dd-yyyy,MM/dd/yyyy'", um campo com o sufixo-DTou_DTserá um campo do tipoDATEno BigQuery, e o padrão seráMM-dd-yyyyouMM/dd/yyyy. - Se você definir duas variáveis de ambiente como
SUFFIX_TIMESTAMP="timestamp-converter --format yyyy-MM-dd SUFFIX_TIMESTAMP=timestamp-converter --format 'yyyy-MM-dd HH.mm.ss.SSSSSS' --timezone America/New_York"eSUFFIX_TS=$SUFFIX_TIMESTAMP, um campo com um dos seguintes sufixos:-TIMESTAMP,_TIMESTAMP,-TSou_TSserá um campo do tipoTIMESTAMPno BigQuery, e o padrão seráyyyy-MM-dd HH:mm:ss.SSSSSScom fuso horárioAmerica/New_York.
Suporte a indicadores nulos
O Conector de mainframe oferece suporte a indicadores nulos a partir da versão
5.13.0. Para usar indicadores nulos, é necessário definir variáveis de ambiente que começam
com a palavra SUFFIX no seguinte formato:
SUFFIX_NULL_INDICATOR_NAME="command --null-value NULL_VALUE --not-null-value NOT_NULL_VALUE"
NULL_INDICATOR_NAME corresponde aos sufixos
-NULL_INDICATOR_NAME ou _NULL_INDICATOR_NAME que são
interpretados como um indicador nulo quando usados como sufixo de um nome de campo em um
cópia-livro.
A lista a seguir descreve os parâmetros que você pode usar com essas variáveis de ambiente:
command: o valor precisa sernull-indicator.–null-value: o valornull indicatorindica que o campo referenciado é nulo. O valor de--null-valueprecisa ser uma string ou um número decimal.–not-null-value: (opcional) Quando especificado, o valornull indicatorindica que o campo referenciado não é nulo. Se esse parâmetro não estiver definido, qualquer valor que não seja–value-nullserá aceito. O valor de–not-null-valueprecisa ser uma string ou um número decimal.–keep: (opcional) quando especificado, o camponull-indicatoré mantido como uma coluna no formato de arquivo ORC (Optimized Row Columnar). Por padrão, esse campo não é mantido no formato ORC.-force-type: (opcional) oferece suporte a duas opções:bytesebinary, que forçam um campo a ser decodificado como bytes ou binário, respectivamente. Para bytes, os valores denullenot-nullsão expressos comoHEX(por exemplo,FA3AB5). As constantesHIGHeLOWestão disponíveis e são equivalentes a todos osFFou todos os00. Para binários, os valores são números inteiros regulares.
Se o null-indicator não tiver um campo referenciado,
o Mainframe Connector vai mostrar uma mensagem de erro e vai parar de processar os
arquivos.
Exemplos:
Snippet de livro
10 COL1-NID1 PIC S9(4) USAGE COMP.
10 COL1 PIC S9(6) USAGE COMP.
10 FIELD PIC X(10).
10 FIELD-NID2 PIC X(1).
10 COL2 PIC X(10).
10 COL2-NULL PIC X(1).
Definição das variáveis de ambiente
SUFFIX_NID1="null-indicator --null-value -1 --not-null-value 0"
# Copybook fields with NID1 suffix null indicator configuration.
SUFFIX_NID2="null-indicator --null-value '?'"
# Copybook fields with NID2 suffix null indicator configuration.
SUFFIX_NULL="null-indicator --null-value '?' --keep"
# Copybook fields with NULL suffix null indicator configuration.
Suporte a campos DBCS
Ao usar campos DBCS, confira o seguinte:
- Ao usar campos PIC G ou Pic N DBCS, forneça uma das seguintes
codificações válidas de conjunto de caracteres multibyte (MBCS, na sigla em inglês) na opção
encodingou na variável de ambienteENCODINGao usar os comandosgsutil cpoubq export:- x-IBM930
- x-IBM933
- x-IBM935
- x-IBM937
- x-IBM939
- x-IBM942
- x-IBM942C
- x-IBM943
- x-IBM943C
- x-IBM949
- x-IBM949C
- x-IBM950
- x-IBM964
- x-IBM970
- x-IBM1364
- Quando um campo de cópia de programa contém apenas bytes DBCS, mas esses bytes não são
cercados por shift-out (0x0E) e shift-in (0x0F), é necessário adicionar o sufixo
_DBCSao nome do campo para garantir que esses bytes sejam decodificados como bytes DBCS.
Por exemplo, se os dados correspondentes ao campo de cópia
03 FLD01 PIC N USAGE DISPLAY-1 contiverem bytes 0x43 e
0xC5 na codificação x-IBM930 que não estejam cercados por 0x0E e
0x0F, renomeie o nome do campo de cópia para
03 FLD01-DBCS PIC N USAGE DISPLAY-1 para decodificar corretamente
os dados DBCS.
Suporte a strings de caracteres de comprimento variável
O analisador de modelo nativo oferece suporte aos seguintes
campos struct:
- 10 var
- 15 var-LEN PIC 9(4) USAGE COMP
- 15 var-TEXT PIC X(n)
O primeiro campo em struct é o comprimento do segundo campo, o campo de string. Talvez seja necessário adicionar algum padding ao final do
registro com base no comprimento do registro, conforme mostrado na figura a seguir.
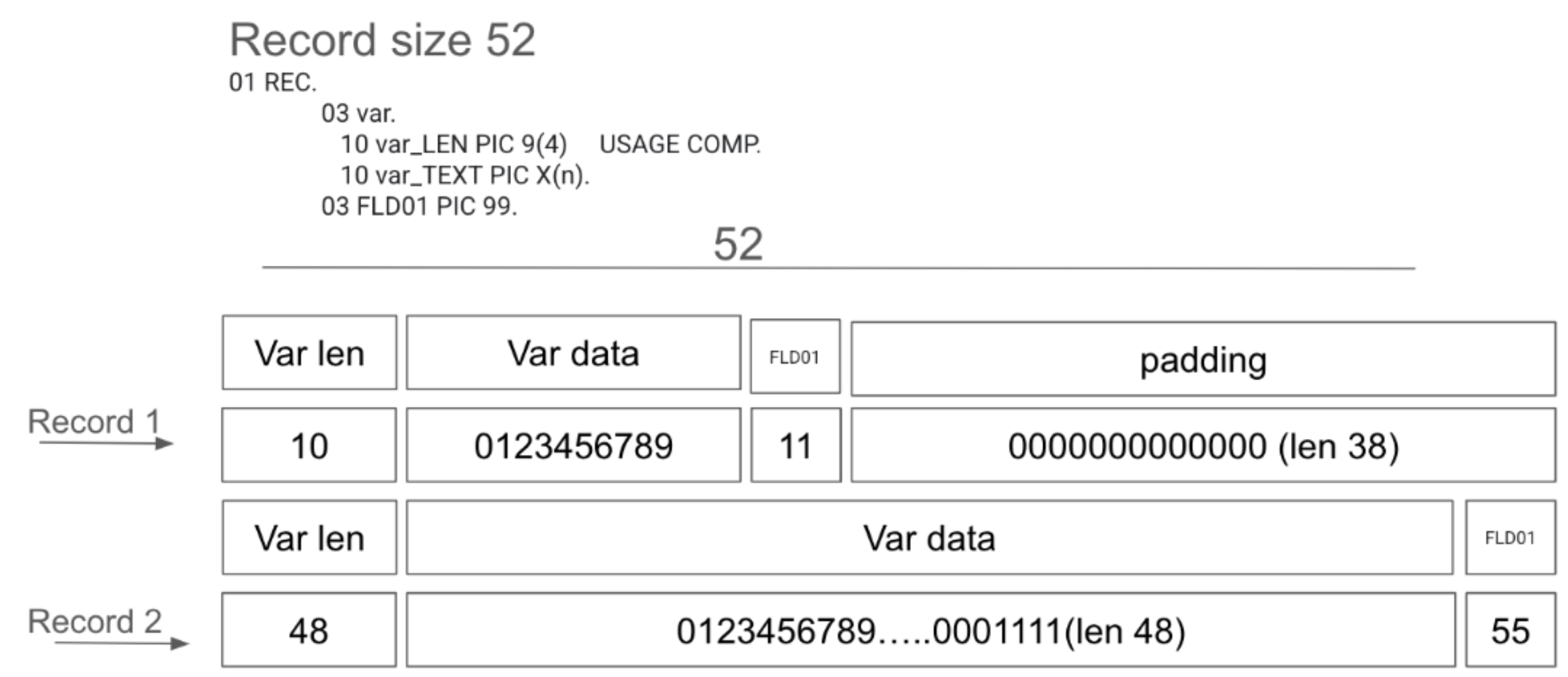
O conector de mainframe remove o sufixo do nome da variável antes de salvar os dados no BigQuery. Neste exemplo, o nome da variável será
var.
Para usar campos struct, defina a variável de ambiente
BQSH_FEATURE_VARIABLE_LENGTH_ENABLED como yes ou
true.
Ao usar campos struct, confira o seguinte:
- O sufixo do primeiro parâmetro em
structé-LEN. Se você quiser usar um sufixo diferente, defina a variável de ambienteBQSH_FEATURE_VARIABLE_LENGTH_LEN_SUFFIXpara o sufixo que você quer usar. - O sufixo do segundo parâmetro em
structé-TEXT. Se você quiser usar um sufixo diferente, defina a variável de ambienteBQSH_FEATURE_VARIABLE_LENGTH_DATA_SUFFIXpara o sufixo que você quer usar.
Campos e construções sem suporte
As seções a seguir descrevem campos e construções que não têm suporte para o
Construções COBOL
construções COBOL, mesmo que não haja suporte a elas; Se você usar esses conceitos no seu copybook, o Mainframe Connector vai mostrar um erro.
dataAlignedClausedataBlankWhenZeroClausedataCommonOwnLocalClausedataIntegerStringClausedataJustifiedClausedataOccursClausedataReceivedByClausedataRecordAreaClausedataRenamesClausedataSignClausedataSynchronizedClausedataThreadLocalClausedataTypeClausedataTypeDefClausedataUsingClause
Tipos de dados
Os tipos de dados COBOL, como COMP-1 e COMP-2, são aceitos.
Parser de cópia legada
O analisador de copybook legado é uma versão mais antiga do analisador que oferece suporte a recursos não COBOL. Se você estiver usando um copybook baseado em DSL, o analisador legado pode ser mais adequado, já que o analisador de copybook nativo pode causar erros.
É possível usar o DD de cópia com as seguintes restrições:
- Os níveis 66 (ALIAS) ou 77 (STANDALONE) não são compatíveis.
- REDEFINES não são aceitos.
- Não é possível usar linhas de comentário.
- Campos de comprimento 10 cujo nome termina com DATE ou DT são datas. A decodificação é diferente para esses campos.
- Use apenas os seguintes campos COMP. Não há suporte para ALIGN e OCCURS.
- COMP
- COMP4
- Binário
- COMP3
- PACKED-DECIMAL
- Use apenas campos PICTURE. Defina os campos PICTURE na mesma linha, diretamente após o nome do campo.
- Você precisa justificar todos os campos e usar um único nível. Não é possível usar comentários.
- Verifique se as colunas 1 a 6 sempre têm espaços em branco.