Mainframe Connector est compatible avec deux versions de l'analyseur de livrets:
- Analyseur de livret de copie natif: l'analyseur de livret de copie natif implémente un analyseur basé sur ANTLR4, est compatible avec les livres de copie COBOL et est la version recommandée de l'analyseur.
- Ancien analyseur de carnets: ancien analyseur de carnets qui est une version antérieure de l'analyseur et qui est compatible avec un nombre très limité de formats de carnets.
Vous pouvez définir l'analyseur que vous souhaitez utiliser en fonction de votre modèle. Pour en savoir plus sur la définition de l'analyseur que vous souhaitez utiliser, consultez la section Définir l'analyseur de livre de copie.
Analyseur de livret de copie natif
L'analyseur de livret de copie natif est la dernière version de l'analyseur et est utilisé par défaut. L'analyseur de livrets de codes natif implémente un analyseur basé sur ANTLR4 et est compatible avec les livrests de codes COBOL.
Cette section liste les tâches de prétraitement effectuées par l'analyseur de livret de copie natif. Il décrit également les types de données compatibles avec l'analyseur de livre de copie natif et les restrictions d'utilisation.
Preprocessing
Avant d'analyser un livre de copie, l'analyseur de livre de copie natif prétraite les données et effectue les tâches suivantes:
- Supprime les lignes de commentaire.
- Résout la continuation de ligne.
- Il vide les zones de numéro de ligne et de colonne 73.
- Conserve les instructions spécifiques au préprocesseur telles que
EJECT,SPACEetTITLE. Ces champs sont analysés, mais ignorés. Les manuels contenant des paramètres de préprocesseur pouvant être utilisés parCOPY REPLACINGne sont pas compatibles avec l'analyseur de manuels natif. Dans ces cahiers, les identifiants sont entourés d'un deux-points (:).
Types de données compatibles et restrictions
Voici les types de données compatibles avec l'analyseur de livre de copie natif et les restrictions d'utilisation:
- Les niveaux 66 (ALIAS) ou 77 (STANDALONE) ne sont pas acceptés.
- N'utilisez que des champs PICTURE. Les champs PICTURE suivants sont acceptés :
- Pic A, Pic B, Pic G (DBCS), Pic N (national ou DBCS), Pic U (UTF8), Pic X et décimal zoné (précision maximale 38, échelle maximale 38)
- La virgule flottante hexadécimale IBM est prise en charge.
- Les REDEFINES ne sont pas acceptés.
- N'utilisez que les champs COMP suivants. Les éléments ALIGN et OCCURS ne sont pas acceptés.
- COMP
- COMP4
- BINARY
- COMP3
- PACKED-DECIMAL
- Les types DATE et TIMESTAMP sont acceptés.
- Les indicateurs de valeur nulle sont acceptés.
- Les champs Pic G et Pic N du jeu de caractères à deux octets (DBCS) sont compatibles et doivent être utilisés à la place de Pic T, qui est désormais obsolète. Pour utiliser le champ Pic N en tant que DBCS sans spécifier
USAGE DISPLAY-1, vous devez définir la variable d'environnementNSYMBOLsurDBCS. Par défaut,NSYMBOLest défini surNATIONAL, ce qui définitUSAGE NATIONALsur les champs Pic N qui ne comportent pas de clauseUSAGE. Notez queNSYMBOLne peut être défini que surNATIONALouDBCS. - Les chaînes de caractères de longueur variable sont acceptées.
- La clause SIGN est compatible.
- Vous devez justifier tous les champs et utiliser un seul niveau d'indentation.
- Les commentaires sont acceptés.
Prise en charge des champs de date et d'horodatage
Mainframe Connector permet de déplacer des données de date et d'horodatage vers et depuis BigQuery. Pour ce faire, vous devez définir des variables d'environnement commençant par le mot SUFFIX au format suivant:
SUFFIX_SUFFIX_STRING="command --format FORMAT --timezone TIMEZONE"
La liste suivante décrit le format plus en détail:
SUFFIX_SUFFIX_STRING: variable d'environnement que vous pouvez utiliser pour définir des données de date et d'horodatage. Le nom SUFFIX_STRING correspond aux suffixes-SUFFIX_STRINGou_SUFFIX_STRINGqui doivent être interprétés comme une date ou un code temporel lorsqu'ils sont utilisés comme suffixe d'un nom de champ dans un cahier. Assurez-vous que SUFFIX_STRING ne contient pas de trait d'union ni de trait de soulignement.command: définit le décodeur à utiliser pour analyser le champ. Les commandes acceptées sontdate-converterettimestamp-converter.--format: paramètre qui définit le format de la date ou de l'horodatage. Vous pouvez spécifier au maximum cinq formats différents, séparés par des virgules. Si plusieurs formats peuvent correspondre à une entrée donnée, le premier format correspondant est utilisé pour le chargement dans BigQuery. Si plusieurs formats sont spécifiés pour l'exportation, seul le premier est utilisé. Pour en savoir plus sur les formats valides, consultez la section Formats de date et d'horodatage acceptés.--timezone: paramètre facultatif de typeTIMESTAMP. Par défaut, le fuseau horaire est UTC. Pour en savoir plus sur les formats de fuseau horaire acceptés, consultez la section Formats de fuseau horaire acceptés.--omitsuffix(facultatif): si ce paramètre est spécifié,-SUFFIX_STRINGou_SUFFIX_STRINGest supprimé du nom du champ qui s'affiche dans BigQuery.
Pour ajouter un alias à un SUFFIX_SUFFIX_STRING, vous pouvez définir une variable d'environnement SUFFIX_SUFFIX_ALIAS=$SUFFIX_SUFFIX_STRING.
Exemples :
- Si vous définissez une variable d'environnement sur
SUFFIX_DT8="date-converter --format yyyyMMdd", un champ avec le suffixe-DT8ou_DT8sera un champ de typeDATEdans BigQuery, et son format serayyyyMMdd. - Si vous définissez une variable d'environnement sur
SUFFIX_DT10="date-converter --format MM-dd-yyyy", un champ avec le suffixe-DT10ou_DT10sera un champ de typeDATEdans BigQuery, et son format seraMM-dd-yyyy. - Si vous définissez une variable d'environnement sur
SUFFIX_DT="date-converter --format 'MM-dd-yyyy,MM/dd/yyyy'", un champ avec le suffixe-DTou_DTsera un champ de typeDATEdans BigQuery, et son format seraMM-dd-yyyyouMM/dd/yyyy. - Si vous définissez deux variables d'environnement sur
SUFFIX_TIMESTAMP="timestamp-converter --format yyyy-MM-dd SUFFIX_TIMESTAMP=timestamp-converter --format 'yyyy-MM-dd HH.mm.ss.SSSSSS' --timezone America/New_York"etSUFFIX_TS=$SUFFIX_TIMESTAMP, un champ avec l'un des suffixes suivants:-TIMESTAMP,_TIMESTAMP,-TSou_TSsera un champ de typeTIMESTAMPdans BigQuery, et son format serayyyy-MM-dd HH:mm:ss.SSSSSSavec le fuseau horaireAmerica/New_York.
Prise en charge des indicateurs nuls
Mainframe Connector est compatible avec les indicateurs nuls à partir de la version 5.13.0. Pour utiliser des indicateurs nuls, vous devez définir des variables d'environnement commençant par le mot SUFFIX au format suivant:
SUFFIX_NULL_INDICATOR_NAME="command --null-value NULL_VALUE --not-null-value NOT_NULL_VALUE"
NULL_INDICATOR_NAME correspond aux suffixes -NULL_INDICATOR_NAME ou _NULL_INDICATOR_NAME qui sont interprétés comme un indicateur nul lorsqu'ils sont utilisés comme suffixe d'un nom de champ dans un cahier.
La liste suivante décrit les paramètres que vous pouvez utiliser avec ces variables d'environnement:
command: la valeur doit êtrenull-indicator.–null-value: la valeurnull indicatorindique que le champ référencé est nul. La valeur de--null-valuedoit être une chaîne ou un nombre décimal.–not-null-value: (facultatif) Lorsque spécifiée, la valeurnull indicatorindique que le champ référencé n'est pas nul. Si ce paramètre n'est pas défini, toute valeur autre que–value-nullest acceptée. La valeur de–not-null-valuedoit être une chaîne ou un nombre décimal.–keep: (facultatif) Lorsque spécifié, le champnull-indicatorest conservé en tant que colonne dans le format de fichier ORC (Optimized Row Columnar). Par défaut, ce champ n'est pas conservé au format ORC.-force-type(facultatif) : prend en charge deux options :bytesetbinary, qui forcent un champ à être décodé en octets ou en binaire, respectivement. Pour les octets, les valeurs denulletnot-nullsont exprimées sous la formeHEX(par exemple,FA3AB5). Des constantesHIGHetLOWsont disponibles, qui sont équivalentes à toutes lesFFou toutes les00. Pour le format binaire, les valeurs sont des entiers standards.
Si null-indicator ne comporte pas de champ référencé, Mainframe Connector affiche un message d'erreur et arrête de traiter les fichiers.
Exemples :
Extrait du cahier
10 COL1-NID1 PIC S9(4) USAGE COMP.
10 COL1 PIC S9(6) USAGE COMP.
10 FIELD PIC X(10).
10 FIELD-NID2 PIC X(1).
10 COL2 PIC X(10).
10 COL2-NULL PIC X(1).
Définition des variables d'environnement
SUFFIX_NID1="null-indicator --null-value -1 --not-null-value 0"
# Copybook fields with NID1 suffix null indicator configuration.
SUFFIX_NID2="null-indicator --null-value '?'"
# Copybook fields with NID2 suffix null indicator configuration.
SUFFIX_NULL="null-indicator --null-value '?' --keep"
# Copybook fields with NULL suffix null indicator configuration.
Prise en charge des champs DBCS
Assurez-vous de respecter les points suivants lorsque vous utilisez des champs DBCS:
- Lorsque vous utilisez des champs DBCS PIC G ou PIC N, vous devez fournir l'un des encodages de jeu de caractères multioctets (MBCS) valides suivants dans l'option
encodingou dans la variable d'environnementENCODINGlorsque vous utilisez les commandesgsutil cpoubq export:- x-IBM930
- x-IBM933
- x-IBM935
- x-IBM937
- x-IBM939
- x-IBM942
- x-IBM942C
- x-IBM943
- x-IBM943C
- x-IBM949
- x-IBM949C
- x-IBM950
- x-IBM964
- x-IBM970
- x-IBM1364
- Lorsqu'un champ de livre de copie ne contient que des octets DBCS, mais que ces octets ne sont pas entourés de caractères de décalage de sortie (0x0E) et de décalage de saisie (0x0F), vous devez ajouter le suffixe
_DBCSau nom du champ pour vous assurer que ces octets sont décodés en tant qu'octets DBCS.
Par exemple, si vos données correspondant au champ de livre de copie 03 FLD01 PIC N USAGE DISPLAY-1 contiennent les octets 0x43 et 0xC5 encodés en x-IBM930 qui ne sont pas entourés de 0x0E et 0x0F, vous devez renommer le nom du champ de livre de copie en 03 FLD01-DBCS PIC N USAGE DISPLAY-1 afin de décoder correctement les données DBCS.
Compatibilité avec les chaînes de caractères de longueur variable
L'analyseur de livre de copie natif accepte les champs struct suivants:
- 10 var
- 15 var-LEN PIC 9(4) USAGE COMP
- 15 var-TEXT PIC X(n)
Le premier champ du champ struct correspond à la longueur du deuxième champ, le champ de chaîne. Vous devrez peut-être ajouter une marge intérieure à la fin de l'enregistrement en fonction de sa longueur, comme illustré dans la figure suivante.
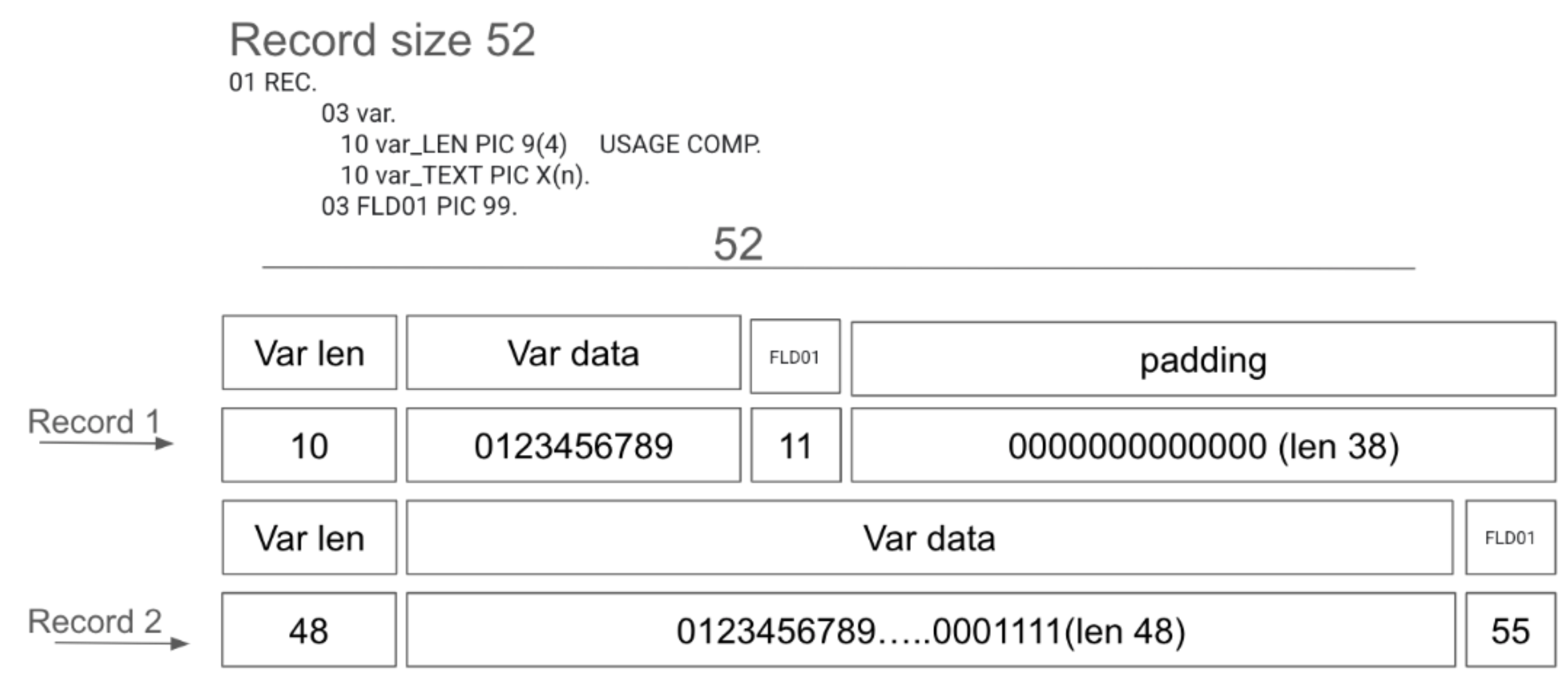
Mainframe Connector supprime le suffixe du nom de la variable avant d'enregistrer les données dans BigQuery. Dans cet exemple, le nom de la variable sera var.
Pour utiliser des champs struct, définissez la variable d'environnement BQSH_FEATURE_VARIABLE_LENGTH_ENABLED sur yes ou true.
Lorsque vous utilisez des champs struct, assurez-vous de respecter les points suivants:
- Le suffixe du premier paramètre dans
structest-LEN. Si vous souhaitez utiliser un suffixe différent, vous devez définir la variable d'environnementBQSH_FEATURE_VARIABLE_LENGTH_LEN_SUFFIXsur le suffixe que vous souhaitez utiliser. - Le suffixe du deuxième paramètre dans
structest-TEXT. Si vous souhaitez utiliser un suffixe différent, vous devez définir la variable d'environnementBQSH_FEATURE_VARIABLE_LENGTH_DATA_SUFFIXsur le suffixe que vous souhaitez utiliser.
Champs et constructions non compatibles
Les sections suivantes décrivent les champs et les constructions qui ne sont pas compatibles avec
Constructions COBOL
constructions COBOL, même si elles ne sont pas compatibles. Si vous utilisez ces constructions dans votre livre de copie, le connecteur Mainframe affiche une erreur.
dataAlignedClausedataBlankWhenZeroClausedataCommonOwnLocalClausedataIntegerStringClausedataJustifiedClausedataOccursClausedataReceivedByClausedataRecordAreaClausedataRenamesClausedataSignClausedataSynchronizedClausedataThreadLocalClausedataTypeClausedataTypeDefClausedataUsingClause
Types de données
Les types de données COBOL tels que COMP-1 et COMP-2 sont acceptés.
Analyseur de l'ancien carnet
L'ancien analyseur de livret de copie est une ancienne version de l'analyseur compatible avec les fonctionnalités autres que COBOL. Si vous utilisez un cahier basé sur le DSL, l'ancien analyseur peut être plus adapté, car l'analyseur de cahier natif peut provoquer des erreurs.
Vous pouvez utiliser le journal des commandes avec les restrictions suivantes:
- Les niveaux 66 (ALIAS) ou 77 (STANDALONE) ne sont pas acceptés.
- Les REDEFINES ne sont pas acceptés.
- Les lignes de commentaire ne sont pas acceptées.
- Les champs de 10 caractères dont le nom se termine par DATE ou DT sont des dates. Le décodage est différent pour ces champs.
- N'utilisez que les champs COMP suivants. Les éléments ALIGN et OCCURS ne sont pas acceptés.
- COMP
- COMP4
- BINARY
- COMP3
- PACKED-DECIMAL
- N'utilisez que des champs PICTURE. Définissez les champs PICTURE sur la même ligne, directement après le nom du champ.
- Vous devez justifier tous les champs et utiliser un seul niveau. Les commentaires ne sont pas acceptés.
- Assurez-vous que les colonnes 1 à 6 sont toujours vides.