De nombreux clients Looker souhaitent permettre à leurs utilisateurs d'aller au-delà de la création de rapports sur les données de leur entrepôt de données, et de pouvoir écrire dans cet entrepôt de données et le mettre à jour.
Grâce à son API Actions, Looker prend en charge ce cas d'utilisation pour n'importe quel entrepôt de données ou destination. Cette page de documentation explique aux clients qui utilisent l'infrastructure Google Cloud comment déployer une solution sur les fonctions Cloud Run pour écrire dans BigQuery. Cette page aborde les sujets suivants :
Points à prendre en compte pour la solution
Utilisez cette liste de points à prendre en compte pour vérifier que cette solution répond à vos besoins.
- Cloud Run Functions
- Pourquoi utiliser Cloud Run Functions ? En tant qu'offre "sans serveur" de Google, Cloud Run Functions est un excellent choix pour faciliter les opérations et la maintenance. Il faut tenir compte du fait que la latence, en particulier pour les invocations à froid, peut être plus longue qu'avec une solution qui repose sur un serveur dédié.
- Langage et environnement d'exécution : les fonctions Cloud Run sont compatibles avec plusieurs langages et environnements d'exécution. Cette page de documentation se concentre sur un exemple en JavaScript et Node.js. Toutefois, les concepts sont directement transposables aux autres langages et environnements d'exécution compatibles.
- BigQuery
- Pourquoi BigQuery ? Bien que cette page de documentation suppose que vous utilisez déjà BigQuery, BigQuery est un excellent choix pour un entrepôt de données en général. Tenez compte des points suivants :
- API BigQuery Storage Write : BigQuery propose plusieurs interfaces pour mettre à jour les données de votre entrepôt de données, y compris, par exemple, les instructions du langage de manipulation de données (LMD) dans les jobs basés sur SQL. Toutefois, la meilleure option pour les écritures à volume élevé est l'API BigQuery Storage Write.
- Ajouter plutôt que mettre à jour : même si cette solution ne fait qu'ajouter des lignes et non les mettre à jour, vous pouvez toujours dériver des tables d'état actuel au moment de la requête à partir d'un journal en mode ajout uniquement, simulant ainsi des mises à jour.
- Pourquoi BigQuery ? Bien que cette page de documentation suppose que vous utilisez déjà BigQuery, BigQuery est un excellent choix pour un entrepôt de données en général. Tenez compte des points suivants :
- Services d'assistance
- Secret Manager : Secret Manager contient des valeurs secrètes pour s'assurer qu'elles ne sont pas stockées dans des endroits trop accessibles, comme directement dans la configuration de la fonction.
- Identity and Access Management (IAM) : IAM autorise la fonction à accéder au secret nécessaire au moment de l'exécution et à écrire dans la table BigQuery prévue.
- Cloud Build : bien que Cloud Build ne soit pas abordé en détail sur cette page, Cloud Run Functions l'utilise en arrière-plan. Vous pouvez utiliser Cloud Build pour automatiser les mises à jour déployées en continu de vos fonctions à partir des modifications apportées à votre code source dans un dépôt Git.
- Authentification de l'action et de l'utilisateur
- Compte de service Cloud Run : le moyen le plus simple et le plus courant d'utiliser les actions Looker pour l'intégration aux ressources et aux assets first party de votre organisation consiste à authentifier les requêtes comme provenant de votre instance Looker à l'aide du mécanisme d'authentification basé sur les jetons de l'API Looker Action, puis à autoriser la fonction à mettre à jour les données dans BigQuery à l'aide d'un compte de service.
- OAuth : une autre option, non abordée sur cette page, consiste à utiliser la fonctionnalité OAuth de l'API Looker Actions. Cette approche est plus complexe et généralement inutile, mais elle peut être utilisée si vous devez définir l'accès des utilisateurs finaux à l'écriture dans la table à l'aide d'IAM, plutôt que d'utiliser leur accès dans Looker ou une logique ad hoc dans le code de votre fonction.
Tutoriel du code de démonstration
Nous avons un seul fichier contenant toute la logique de notre action de démonstration disponible sur GitHub. Dans cette section, nous allons parcourir les éléments clés du code.
Code de configuration
La première section contient quelques constantes de démonstration qui identifient la table dans laquelle l'action écrira. Dans la section Guide de déploiement plus loin sur cette page, vous serez invité à remplacer l'ID du projet par le vôtre. Il s'agira de la seule modification nécessaire à apporter au code.
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
La section suivante déclare et initialise quelques dépendances de code que votre action utilisera. Nous fournissons un exemple qui accède à Secret Manager "dans le code" en utilisant le module Secret Manager Node.js. Toutefois, vous pouvez également éliminer cette dépendance de code en utilisant la fonctionnalité intégrée des fonctions Cloud Run pour récupérer un secret pour vous lors de son initialisation.
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
Notez que les dépendances @google-cloud référencées sont également déclarées dans notre fichier package.json pour permettre aux dépendances d'être préchargées et disponibles pour notre environnement d'exécution Node.js. crypto est un module Node.js intégré et n'est pas déclaré dans package.json.
Gestion et routage des requêtes HTTP
L'interface principale que votre code expose à l'environnement d'exécution des fonctions Cloud Run est une fonction JavaScript exportée qui suit les conventions du serveur Web Node.js Express. Plus précisément, votre fonction reçoit deux arguments : le premier représente la requête HTTP, à partir de laquelle vous pouvez lire différents paramètres et valeurs de requête ; le second représente un objet de réponse, auquel vous envoyez vos données de réponse. Vous pouvez attribuer le nom de votre choix à la fonction, mais vous devrez le fournir à Cloud Run Functions ultérieurement, comme indiqué dans la section Guide de déploiement.
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
La première section de la fonction httpHandler déclare les différentes routes que notre action reconnaîtra. Elle reflète fidèlement les points de terminaison requis de l'API Actions pour une seule action, ainsi que les fonctions qui géreront chaque route, définies plus loin dans le fichier.
Alors que certains exemples d'actions + Cloud Run Functions déploient une fonction distincte pour chaque route afin de s'aligner sur le routage par défaut de Cloud Run Functions, les fonctions sont capables d'appliquer un "sous-routage" supplémentaire dans leur code, comme illustré ici. Il s'agit en fin de compte d'une question de préférence, mais effectuer ce routage supplémentaire dans le code minimise le nombre de fonctions que nous devons déployer et nous aide à maintenir un état de code unique et cohérent sur tous les points de terminaison des actions.
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
Le reste de la fonction de gestionnaire HTTP implémente la gestion de la requête HTTP par rapport aux déclarations de route précédentes et connecte les valeurs renvoyées par ces gestionnaires à l'objet de réponse.
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
Maintenant que nous avons vu le gestionnaire HTTP et les déclarations de route, nous allons nous pencher sur les trois principaux points de terminaison d'action que nous devons implémenter :
- Point de terminaison de la liste des actions
- Point de terminaison du formulaire d'action
- Point de terminaison d'exécution de l'action
Point de terminaison de la liste des actions
Lorsqu'un administrateur Looker connecte une instance Looker à un serveur d'actions pour la première fois, Looker appelle l'URL fournie, appelée point de terminaison de la liste des actions, pour obtenir des informations sur les actions disponibles via le serveur.
Dans les déclarations de route que nous avons montrées précédemment, nous avons rendu ce point de terminaison disponible au niveau du chemin racine (/) sous l'URL de notre fonction, et nous avons indiqué qu'il serait géré par la fonction hubListing.
Comme vous pouvez le voir dans la définition de fonction suivante, il n'y a pas beaucoup de "code" : elle renvoie simplement les mêmes données JSON à chaque fois. Notez qu'il inclut dynamiquement sa "propre" URL dans certains champs, ce qui permet à l'instance Looker de renvoyer ultérieurement des requêtes à la même fonction.
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
Pour les besoins de la démonstration, notre code n'a pas nécessité d'authentification pour récupérer cette fiche. Toutefois, si vous considérez que les métadonnées de votre action sont sensibles, vous pouvez également exiger une authentification pour cette route, comme indiqué dans la section suivante.
Notez également que notre fonction Cloud Run peut exposer et gérer plusieurs actions, ce qui explique notre convention de routage /action-X/.... Toutefois, notre fonction Cloud Run de démonstration n'implémentera qu'une seule action.
Point de terminaison du formulaire d'action
Bien que tous les cas d'utilisation ne nécessitent pas de formulaire, en avoir un est tout à fait adapté au cas d'utilisation des réécritures dans la base de données. En effet, les utilisateurs peuvent inspecter les données dans Looker, puis fournir les valeurs à insérer dans la base de données. Étant donné que notre liste d'actions fournissait un paramètre form_url, Looker appellera ce point de terminaison du formulaire d'action lorsqu'un utilisateur commencera à interagir avec votre action, afin de déterminer quelles données supplémentaires capturer auprès de l'utilisateur.
Dans nos déclarations de route, nous avons rendu ce point de terminaison disponible sous le chemin d'accès /action-0/form et lui avons associé deux gestionnaires : requireInstanceAuth et action0Form.
Nous configurons nos déclarations de route pour autoriser plusieurs gestionnaires de cette manière, car une partie de la logique peut être réutilisée pour plusieurs points de terminaison.
Par exemple, nous pouvons voir que requireInstanceAuth est utilisé pour plusieurs routes. Nous utilisons ce gestionnaire chaque fois que nous voulons exiger qu'une requête provienne de notre instance Looker. Le gestionnaire récupère la valeur du jeton secret attendue à partir de Secret Manager et rejette toutes les requêtes qui ne contiennent pas cette valeur.
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
Notez que nous utilisons une implémentation timingSafeEqual plutôt que la vérification d'égalité standard (==) pour éviter de divulguer des informations de timing de canal auxiliaire qui permettraient à un pirate informatique de déterminer rapidement la valeur de notre secret.
En supposant qu'une requête passe le contrôle d'authentification de l'instance, elle est ensuite traitée par le gestionnaire action0Form.
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
Bien que notre exemple de démonstration soit très statique, le code du formulaire peut être plus interactif pour certains cas d'utilisation. Par exemple, en fonction de la sélection d'un utilisateur dans un menu déroulant initial, différents champs peuvent s'afficher.
Point de terminaison d'exécution de l'action
Le point de terminaison Action Execute est l'endroit où réside la majeure partie de la logique d'une action, et où nous aborderons la logique spécifique au cas d'utilisation de l'insertion BigQuery.
Dans nos déclarations de route, nous avons rendu ce point de terminaison disponible sous le chemin d'accès /action-0/execute et lui avons associé trois gestionnaires : requireInstanceAuth, processRequestBody et action0Execute.
Nous avons déjà abordé requireInstanceAuth. Le gestionnaire processRequestBody fournit un prétraitement peu intéressant pour convertir certains champs peu pratiques du corps de la requête Looker dans un format plus pratique. Vous pouvez toutefois vous y référer dans le fichier de code complet.
La fonction action0Execute commence par montrer des exemples d'extraction d'informations utiles à partir de plusieurs parties de la requête d'action. En pratique, notez que les éléments de requête auxquels notre code fait référence en tant que formParams et actionParams peuvent contenir différents champs, selon ce que vous déclarez dans vos points de terminaison Listing et Form.
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
Le code passe ensuite à du code BigQuery standard pour insérer les données. Notez que les API BigQuery Storage Write proposent d'autres variantes plus complexes qui sont mieux adaptées à une connexion de streaming persistante ou à des insertions groupées de nombreux enregistrements. Toutefois, pour répondre aux interactions individuelles des utilisateurs dans le contexte d'une fonction Cloud Run, il s'agit de la variante la plus directe.
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
Le code de démonstration inclut également un point de terminaison "status" à des fins de dépannage, mais ce point de terminaison n'est pas requis pour l'intégration de l'API Actions.
Guide de déploiement
Enfin, nous vous fournirons un guide détaillé pour déployer la démo vous-même, en abordant les prérequis, le déploiement de la fonction Cloud Run, la configuration de BigQuery et la configuration de Looker.
Conditions préalables concernant le projet et le service
Avant de commencer à configurer des éléments spécifiques, consultez cette liste pour comprendre les services et les règles dont la solution aura besoin :
- Un nouveau projet : vous aurez besoin d'un nouveau projet pour héberger les ressources de notre exemple.
- Services : lorsque vous utilisez les fonctions BigQuery et Cloud Run pour la première fois dans l'interface utilisateur de la console Cloud, vous êtes invité à activer les API requises pour les services nécessaires, y compris BigQuery, Artifact Registry, Cloud Build, Cloud Functions, Cloud Logging, Pub/Sub, Cloud Run Admin et Secret Manager.
- Règles pour les appels non authentifiés : ce cas d'utilisation nous oblige à déployer des fonctions Cloud Run qui autorisent les appels non authentifiés, car nous gérerons l'authentification des requêtes entrantes dans notre code conformément à l'API Actions, plutôt que d'utiliser IAM. Bien que cela soit autorisé par défaut, les règles d'administration restreignent souvent cette utilisation. Plus précisément, la stratégie
constraints/iam.allowedPolicyMemberDomainslimite les personnes auxquelles des autorisations IAM peuvent être accordées. Vous devrez peut-être l'ajuster pour autoriser le compte principalallUserspour l'accès non authentifié. Si vous ne parvenez pas à autoriser les appels non authentifiés, consultez le guide Créer des services Cloud Run publics lorsque le partage restreint de domaine est appliqué pour en savoir plus. - Autres règles : n'oubliez pas que d'autres Google Cloud contraintes de règles d'administration peuvent également empêcher le déploiement de services qui sont normalement autorisés par défaut.
Déployer la fonction Cloud Run
Une fois que vous avez créé un projet, suivez ces étapes pour déployer la fonction Cloud Run.
- Dans Fonctions Cloud Run, cliquez sur Créer une fonction.
- Choisissez un nom pour votre fonction (par exemple, "demo-bq-insert-action").
- Sous les paramètres Déclencheur :
- Le type de déclencheur doit déjà être "HTTPS".
- Définissez Authentification sur Autoriser les appels non authentifiés.
- Copiez la valeur de l'URL dans le presse-papiers.
- Dans les paramètres Environnement d'exécution > Variables d'environnement d'exécution :
- Cliquez sur Ajouter une variable.
- Définissez le nom de la variable sur
CALLBACK_URL_PREFIX. - Collez l'URL de l'étape précédente en tant que valeur.
- Cliquez sur Suivant.
- Cliquez sur le fichier
package.json, puis collez-y le contenu. - Cliquez sur le fichier
index.js, puis collez-y le contenu. - Attribuez la variable
projectIden haut du fichier à votre propre ID de projet. - Définissez le point d'entrée sur
httpHandler. - Cliquez sur Déployer.
- Accordez les autorisations demandées (le cas échéant) au compte de service de compilation.
- Attendez la fin du déploiement.
- Si, lors d'une étape ultérieure, vous recevez un message d'erreur vous invitant à consulter les journaux Google Cloud , sachez que vous pouvez accéder aux journaux de cette fonction depuis l'onglet Journaux de cette page.
- Avant de quitter la page de votre fonction Cloud Run, sous l'onglet Détails, recherchez et notez le compte de service associé à la fonction. Nous l'utiliserons lors des étapes suivantes pour nous assurer que la fonction dispose des autorisations nécessaires.
- Testez le déploiement de votre fonction directement dans votre navigateur en accédant à l'URL. Vous devriez obtenir une réponse JSON contenant la fiche de votre intégration.
- Si vous recevez une erreur 403, il est possible que votre tentative de définition de l'option Autoriser les appels non authentifiés ait échoué en raison d'une règle d'administration. Vérifiez si votre fonction autorise les appels non authentifiés, examinez le paramètre de la règle d'administration de votre organisation, puis essayez de le modifier.
Accès à la table de destination BigQuery
En pratique, la table de destination dans laquelle insérer les données peut résider dans un autre projet Google Cloud . Toutefois, à des fins de démonstration, nous allons créer une table de destination dans notre projet. Dans les deux cas, vous devrez vous assurer que le compte de service de votre fonction Cloud Run dispose des autorisations nécessaires pour écrire dans la table.
- Accédez à la console BigQuery.
Créez la table de démonstration :
- Dans la barre "Explorateur", utilisez le menu à trois points à côté de votre projet, puis sélectionnez Créer un ensemble de données.
- Donnez à votre ensemble de données l'ID
demo_dataset, puis cliquez sur Créer un ensemble de données. - Utilisez le menu à trois points sur l'ensemble de données que vous venez de créer, puis sélectionnez Créer une table.
- Donnez à votre tableau le nom
demo_table. Sous Schéma, sélectionnez Modifier sous forme de texte, utilisez le schéma suivant, puis cliquez sur Créer une table.
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
Attribuez des autorisations :
- Dans la barre Explorateur, cliquez sur votre ensemble de données.
- Sur la page Ensemble de données, cliquez sur Partage > Autorisations.
- Cliquez sur Ajouter un compte principal.
- Définissez le nouveau compte principal sur le compte de service de votre fonction, indiqué plus haut sur cette page.
- Attribuez le rôle Éditeur de données BigQuery.
- Cliquez sur Enregistrer.
Se connecter à Looker
Maintenant que votre fonction est déployée, nous allons connecter Looker à celle-ci.
- Nous aurons besoin d'un secret partagé pour que votre action puisse authentifier les demandes provenant de votre instance Looker. Générez une longue chaîne aléatoire et conservez-la à un emplacement sécurisé. Nous l'utiliserons dans les étapes suivantes comme valeur Looker secret.
- Dans la console Cloud, accédez à Secret Manager.
- Cliquez sur Créer un secret.
- Définissez le paramètre Nom sur
LOOKER_SECRET. (Ce nom est codé en dur dans le code de cette démo, mais vous pouvez choisir n'importe quel nom lorsque vous travaillez avec votre propre code.) - Définissez la valeur du code secret sur la valeur du code secret que vous avez générée.
- Cliquez sur Créer un secret.
- Sur la page Secret, cliquez sur l'onglet Autorisations.
- Cliquez sur Accorder l'accès.
- Définissez Nouveaux comptes principaux sur le compte de service de votre fonction, noté précédemment.
- Attribuez le rôle Accesseur de secrets Secret Manager.
- Cliquez sur Enregistrer.
- Vous pouvez vérifier que votre fonction accède bien au secret en accédant à la route
/statusajoutée à l'URL de votre fonction.
- Dans votre instance Looker :
- Accédez à Admin > Plate-forme > Actions.
- En bas de la page, cliquez sur Ajouter un hub d'actions.
- Indiquez l'URL de votre fonction (par exemple, https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action), puis cliquez sur Ajouter à Action Hub pour confirmer.
- Une nouvelle entrée Action Hub devrait s'afficher, avec une action nommée Demo BigQuery Insert.
- Dans l'entrée "Action Hub", cliquez sur Configurer l'autorisation.
- Saisissez votre secret Looker généré dans le champ Jeton d'autorisation, puis cliquez sur Mettre à jour le jeton.
- Dans l'action Demo BigQuery Insert, cliquez sur Enable (Activer).
- Basculez le bouton Activé sur l'état activé.
- Un test de l'action doit s'exécuter automatiquement pour confirmer que votre fonction accepte la requête de Looker et répond correctement au point de terminaison du formulaire.
- Cliquez sur Enregistrer.
Test de bout en bout
Nous devrions maintenant pouvoir utiliser notre nouvelle action. Cette action est configurée pour fonctionner avec n'importe quelle requête. Choisissez donc n'importe quelle exploration (par exemple, une exploration de l'activité système intégrée), ajoutez des champs à une nouvelle requête, exécutez-la, puis sélectionnez Envoyer dans le menu en forme de roue dentée. L'action devrait s'afficher comme l'une des destinations disponibles. Vous devriez être invité à saisir des valeurs dans certains champs :
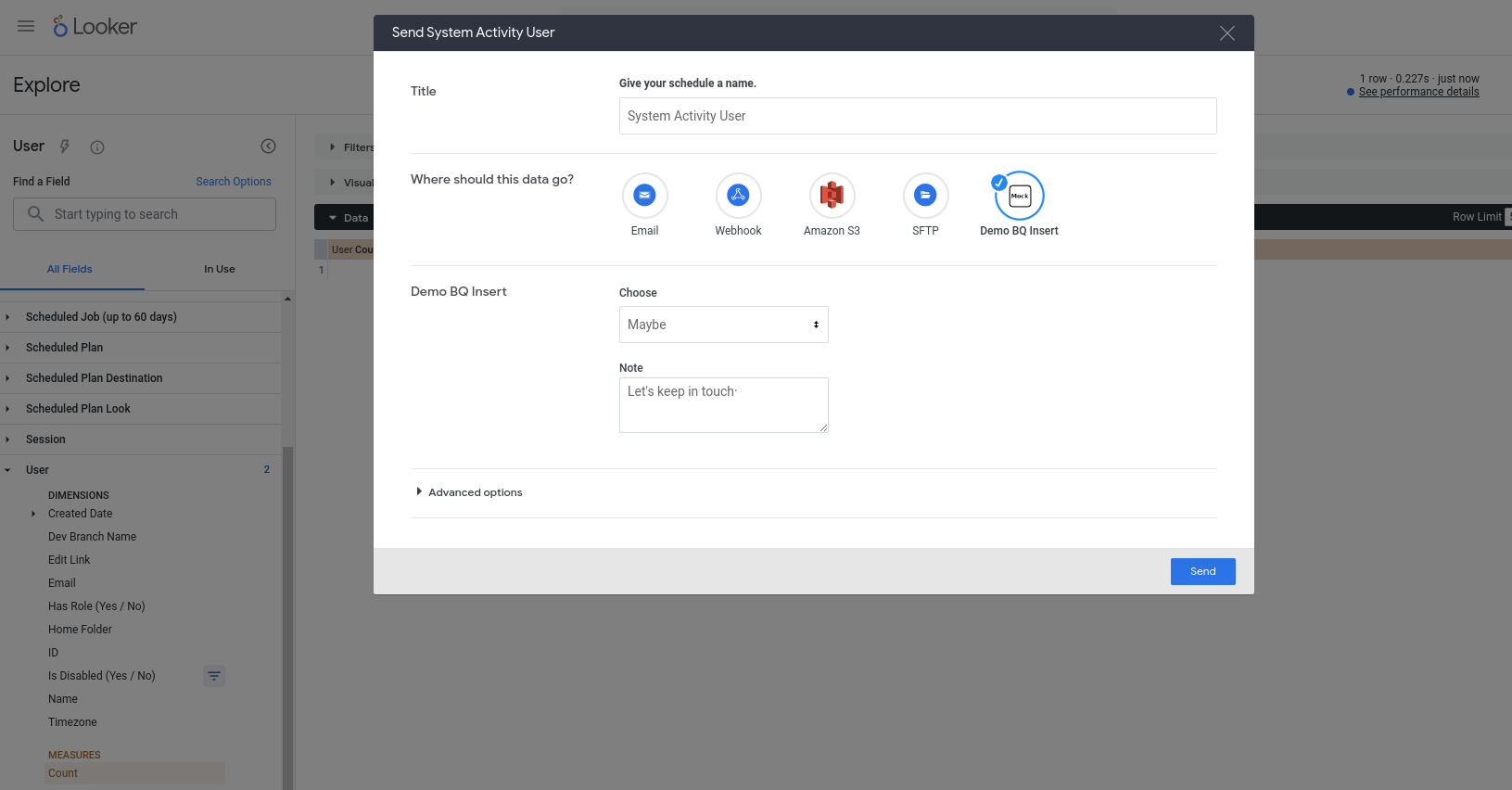
Après avoir cliqué sur Envoyer, une nouvelle ligne devrait être insérée dans votre table BigQuery (et l'adresse e-mail de votre compte utilisateur Looker devrait être identifiée dans la colonne invoked_by).