Ce document explique comment configurer la journalisation et la surveillance des composants système dans Google Distributed Cloud (logiciel uniquement) pour VMware.
Par défaut, Cloud Logging, Cloud Monitoring et Google Cloud Managed Service pour Prometheus sont activés.
Pour en savoir plus sur les options, consultez Présentation de la journalisation et de la surveillance.
Ressources surveillées
Les ressources surveillées correspondent à la manière dont Google représente les ressources, telles que les clusters, les nœuds, les pods et les conteneurs. Pour en savoir plus, consultez la documentation Types de ressources surveillées de Cloud Monitoring.
Pour interroger des journaux et des métriques, vous devez au moins connaître les libellés de ressources suivants :
project_id: ID de projet du projet logging-monitoring du cluster. Vous avez fourni cette valeur dans le champstackdriver.projectIDdu fichier de configuration du cluster.location: région Google Cloud où vous souhaitez acheminer et stocker vos métriques Cloud Monitoring. Vous spécifiez la région lors de l'installation dans le champstackdriver.clusterLocationde votre fichier de configuration du cluster. Nous vous recommandons de choisir une région à proximité de votre centre de données sur site.Vous spécifiez l'emplacement de routage et de stockage des journaux Cloud Logging dans la configuration du routeur de journaux. Pour en savoir plus sur le routage des journaux, consultez Présentation du routage et du stockage.
cluster_name: nom du cluster défini lors de la création du cluster.Vous pouvez récupérer la valeur
cluster_namedu cluster d'administrateur ou d'utilisateur en inspectant la ressource personnalisée Stackdriver :kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
Où :
CLUSTER_KUBECONFIGest le chemin d'accès au fichier kubeconfig du cluster d'administrateur ou d'utilisateur pour lequel le nom du cluster est requis.
Routage des journaux et des métriques
L'agent de transfert de journaux Stackdriver (stackdriver-log-forwarder) envoie les journaux de chaque machine de nœud à Cloud Logging. De même, l'agent de métriques GKE (gke-metrics-agent) envoie les métriques de chaque nœud à Cloud Monitoring. Avant l'envoi des journaux et des métriques, l'opérateur Stackdriver (stackdriver-operator) associe la valeur du champ clusterLocation de la ressource personnalisée stackdriver à chaque entrée de journal et métrique avant leur routage vers Google Cloud. De plus, les journaux et les métriques sont associés au projet Google Cloud spécifié dans la spécification de la ressource personnalisée stackdriver (spec.projectID). La ressourcestackdriverobtient les valeurs des champs clusterLocation et projectID à partir des champs stackdriver.clusterLocation et stackdriver.projectID de la section clusterOperations de la ressource Cluster au moment de la création du cluster.
Toutes les métriques et les entrées de journal envoyées par les agents Stackdriver sont acheminées vers un point de terminaison d'ingestion global. De là, les données sont transférées vers le point de terminaison régional Google Cloud le plus proche pour assurer la fiabilité du transport des données.
Une fois que le point de terminaison mondial reçoit la métrique ou l'entrée de journal, la suite dépend du service :
Configuration du routage des journaux : lorsque le point de terminaison de journalisation reçoit un message de journal, Cloud Logging le transmet au routeur de journaux. Les récepteurs et les filtres de la configuration du routeur de journaux déterminent comment acheminer le message. Vous pouvez acheminer les entrées de journal vers des destinations telles que les buckets Logging régionaux, qui stockent l'entrée de journal, ou vers Pub/Sub. Pour en savoir plus sur le fonctionnement du routage des journaux et sur la façon de le configurer, consultez Présentation du routage et du stockage.
Ni le champ
clusterLocationde la ressource personnaliséestackdriver, ni le champclusterOperations.locationde la spécification du cluster ne sont pris en compte dans ce processus de routage. Pour les journaux,clusterLocationest utilisé pour libeller les entrées de journal uniquement, ce qui peut être utile pour le filtrage dans l'explorateur de journaux.Configuration du routage des métriques : lorsque le point de terminaison des métriques reçoit une entrée de métrique, Cloud Monitoring la route automatiquement vers l'emplacement spécifié par la métrique. L'emplacement de la métrique provenait du champ
clusterLocationde la ressource personnaliséestackdriver.Planifiez votre configuration : lorsque vous configurez Cloud Logging et Cloud Monitoring, configurez le routeur de journaux et spécifiez un
clusterLocationapproprié avec les emplacements qui répondent le mieux à vos besoins. Par exemple, si vous souhaitez que les journaux et les métriques soient envoyés au même emplacement, définissezclusterLocationsur la même région Google Cloud que celle utilisée par le routeur de journaux pour votre projet Google Cloud .Mettez à jour votre configuration si nécessaire : vous pouvez modifier à tout moment les paramètres de destination des journaux et des métriques en fonction des exigences de votre entreprise, comme les plans de reprise après sinistre. Les modifications apportées à la configuration de Log Router dans les champs Google Cloud et
clusterLocationde la ressource personnaliséestackdriverprennent effet rapidement.
Utiliser Cloud Logging
Vous n'avez aucune action à effectuer pour activer Cloud Logging pour un cluster.
Toutefois, vous devez spécifier le projet Google Cloud dans lequel vous souhaitez afficher les journaux. Dans le fichier de configuration du cluster, vous spécifiez le projet Google Cloud dans la section stackdriver.
Vous pouvez accéder aux journaux à l'aide de l'explorateur de journaux de la console Google Cloud . Par exemple, pour accéder aux journaux d'un conteneur, procédez comme suit :
- Dans la console Google Cloud , ouvrez l'explorateur de journaux pour votre projet.
- Recherchez les journaux d'un conteneur comme suit :
- Cliquez sur la boîte déroulante du catalogue de journaux dans l'angle supérieur gauche, puis sélectionnez Conteneur Kubernetes.
- Sélectionnez le nom du cluster, l'espace de noms et un conteneur dans la hiérarchie.
Afficher les journaux des contrôleurs dans le cluster d'amorçage
-
Dans la console Google Cloud , accédez à la page Explorateur de journaux.
Accéder à l'explorateur de journaux
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Logging.
Pour afficher tous les journaux des contrôleurs du cluster d'amorçage, exécutez la requête suivante dans l'éditeur de requête :
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
Pour afficher les journaux d'un pod spécifique, modifiez la requête pour inclure le nom de ce pod :
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Utiliser Cloud Monitoring
Aucune action n'est requise de votre part pour activer Cloud Monitoring pour un cluster.
Toutefois, vous devez spécifier le projet Google Cloud pour lequel vous souhaitez afficher les métriques.
Dans le fichier de configuration du cluster, vous spécifiez le projet Google Cloud dans la section stackdriver.
L'explorateur de métriques vous permet de choisir parmi plus de 1 500 métriques. Pour y accéder, procédez comme suit :
Dans la console Google Cloud , sélectionnez Surveillance ou utilisez le bouton suivant :
Sélectionnez Ressources > Explorateur de métriques.
Vous pouvez également afficher les métriques dans les tableaux de bord de la console Google Cloud . Pour en savoir plus sur la création de tableaux de bord et la consultation des métriques, consultez Créer des tableaux de bord.
Afficher les données de surveillance au niveau du parc
Pour obtenir une vue d'ensemble de l'utilisation des ressources de votre parc à l'aide des données Cloud Monitoring, y compris de vos clusters Google Distributed Cloud, vous pouvez utiliser la présentation Google Kubernetes Engine dans la console Google Cloud . Pour en savoir plus, consultez Gérer des clusters depuis la console Google Cloud .
Limites de quotas Cloud Monitoring par défaut
La surveillance Google Distributed Cloud est limitée par défaut à 6 000 appels d'API par minute pour chaque projet. Si vous dépassez cette limite, il est possible que vos métriques ne s'affichent pas. Si vous avez besoin d'une limite de surveillance plus élevée, faites-en la demande via la console Google Cloud .
Utiliser Managed Service pour Prometheus
Google Cloud Managed Service pour Prometheus fait partie de Cloud Monitoring et est disponible par défaut. Voici quelques avantages de Managed Service pour Prometheus :
Vous pouvez continuer à utiliser votre surveillance existante basée sur Prometheus sans modifier vos alertes ni vos tableaux de bord Grafana.
Si vous utilisez à la fois GKE et Google Distributed Cloud, vous pouvez utiliser le même PromQL pour les métriques de tous vos clusters. Vous pouvez également utiliser l'onglet PROMQL de l'explorateur de métriques dans la console Google Cloud .
Activer et désactiver Managed Service pour Prometheus
À partir de la version 1.30.0-gke.1930 de Google Distributed Cloud, Managed Service pour Prometheus est toujours activé. Dans les versions antérieures, vous pouvez modifier la ressource Stackdriver, stackdriver, pour activer ou désactiver Managed Service pour Prometheus. Pour désactiver Managed Service pour Prometheus pour les versions de cluster antérieures à 1.30.0-gke.1930, définissez spec.featureGates.enableGMPForSystemMetrics sur false dans la ressource stackdriver.
Afficher les données de métriques
Lorsque Managed Service pour Prometheus est activé, les métriques des composants suivants ont un format différent pour la manière dont elles sont stockées et interrogées dans Cloud Monitoring :
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet and cadvisor
- Métriques des kube-state
- node-exporter
Dans le nouveau format, vous pouvez interroger les métriques précédentes à l'aide du langage de requête Prometheus (PromQL).
Exemple d'utilisation de PromQL :
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Configurer des tableaux de bord Grafana avec Managed Service pour Prometheus
Pour utiliser Grafana avec les données de métriques de Managed Service pour Prometheus, suivez les étapes décrites dans Interroger à l'aide de Grafana pour vous authentifier et configurer une source de données Grafana afin d'interroger les données de Managed Service pour Prometheus.
Un ensemble d'exemples de tableaux de bord Grafana est fourni dans le dépôt anthos-samples sur GitHub. Pour installer les exemples de tableaux de bord, procédez comme suit :
Téléchargez les exemples de fichiers
.json:git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Si votre source de données Grafana a été créée avec un nom différent de
Managed Service for Prometheus, modifiez le champdatasourcedans tous les fichiers.json:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Remplacez [DATASOURCE_NAME] par le nom de la source de données dans votre Grafana qui pointait vers le service Prometheus
frontend.Accédez à l'interface utilisateur de Grafana depuis votre navigateur, puis sélectionnez + Import (Importer) dans le menu Dashboards (Tableaux de bord).
Importez le fichier
.json, ou copiez et collez son contenu, puis sélectionnez Charger. Une fois le contenu du fichier chargé, sélectionnez Importer. Vous pouvez également modifier le nom et l'UID du tableau de bord avant de l'importer.
Le tableau de bord importé devrait se charger correctement si votre Google Distributed Cloud et la source de données sont correctement configurés. Par exemple, la capture d'écran suivante montre le tableau de bord configuré par
cluster-capacity.json.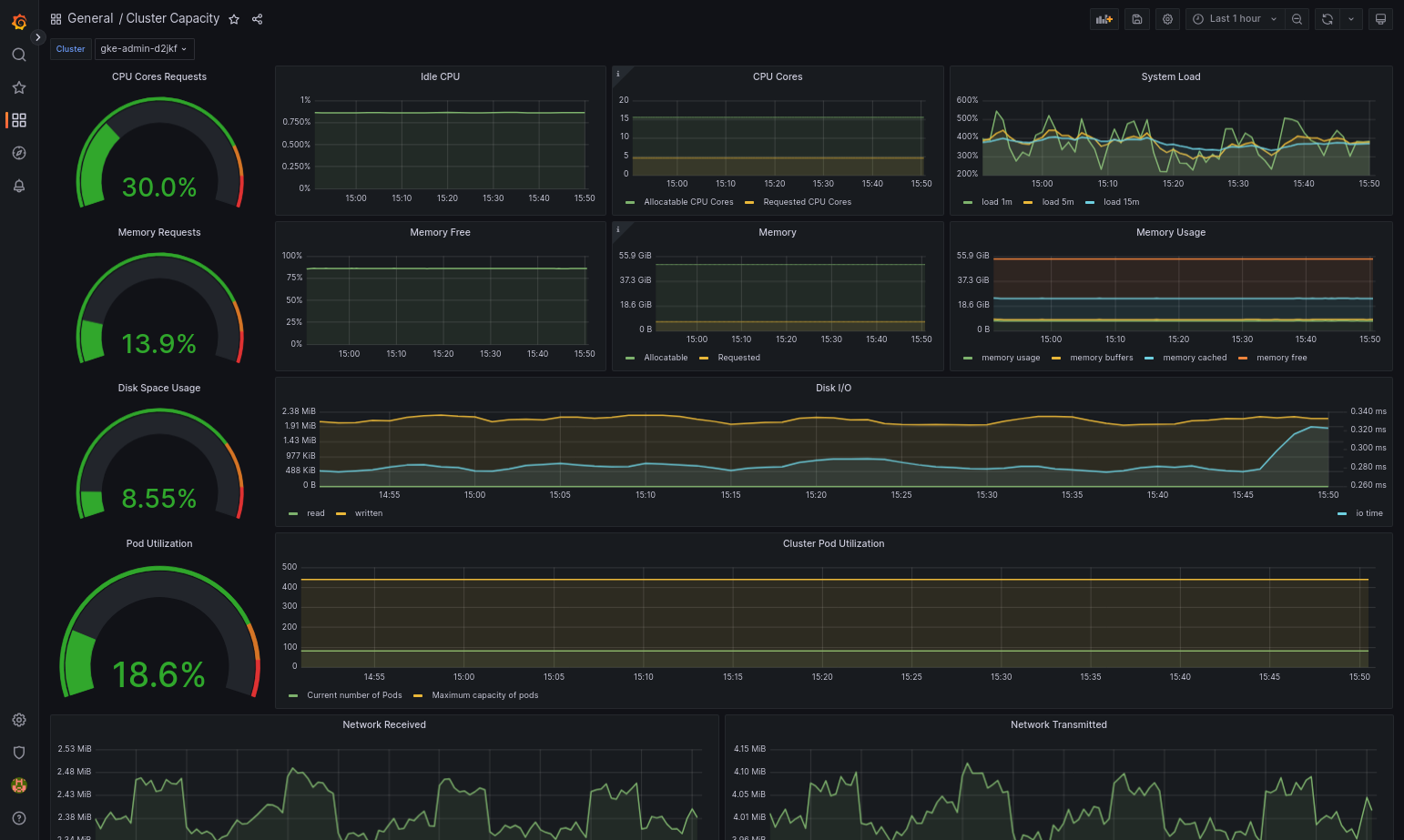
Autres ressources
Pour en savoir plus sur Managed Service pour Prometheus, consultez les ressources suivantes :
Utiliser Prometheus et Grafana
À partir de la version 1.16, Prometheus et Grafana ne sont pas disponibles dans les clusters nouvellement créés. Nous vous recommandons d'utiliser Managed Service pour Prometheus en remplacement de la surveillance dans le cluster.
Si vous mettez à niveau un cluster en version 1.15 sur lequel la version 1.16 de Prometheus et Grafana est activée, Prometheus et Grafana continuent à fonctionner, mais ils ne seront pas mis à jour ni ne se verront appliquer des correctifs de sécurité spécifiques.
Si vous souhaitez supprimer toutes les ressources Prometheus et Grafana après la mise à niveau vers la version 1.16, exécutez la commande suivante :
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
Au lieu d'utiliser les composants Prometheus et Grafana inclus dans les versions précédentes de Google Distributed Cloud, vous pouvez passer à une version communautaire Open Source de Prometheus et Grafana :
Problème connu
Lors de la mise à niveau des clusters d'utilisateur, Prometheus et Grafana sont automatiquement désactivés. Cependant, les données de configuration et de métriques sont conservées.
Pour contourner ce problème, ouvrez l'objet monitoring-sample après la mise à niveau pour y apporter des modifications, puis définissez enablePrometheus sur true.
Accéder aux métriques de surveillance à partir des tableaux de bord Grafana
Grafana affiche les métriques collectées à partir de vos clusters. Pour les consulter, vous devez accéder aux tableaux de bord de Grafana :
Obtenez le nom du pod Grafana qui s'exécute dans l'espace de noms
kube-systemd'un cluster d'utilisateur :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
où [USER_CLUSTER_KUBECONFIG] est le fichier kubeconfig du cluster d'utilisateur.
Le pod Grafana dispose d'un serveur HTTP qui écoute sur le port TCP 3000. Transférez un port local vers le port 3000 du pod afin de pouvoir afficher les tableaux de bord de Grafana depuis un navigateur Web.
Par exemple, supposons que le nom du pod soit
grafana-0. Pour transférer le port 50000 vers le port 3000 du pod, saisissez la commande suivante :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
Dans votre navigateur Web, accédez à la page
http://localhost:50000.Sur la page de connexion, saisissez
admincomme nom d'utilisateur et comme mot de passe.Si la connexion aboutit, un message vous invite à modifier le mot de passe. Une fois que vous avez modifié le mot de passe par défaut, le tableau de bord de la page d'accueil Grafana du cluster d'utilisateur apparaît.
Pour accéder à d'autres tableaux de bord, cliquez sur le menu déroulant Home (Accueil) dans l'angle supérieur gauche de la page.
Pour obtenir un exemple d'utilisation de Grafana, consultez Créer un tableau de bord Grafana.
Accéder aux alertes
Prometheus Alertmanager collecte les alertes du serveur Prometheus. Vous pouvez afficher ces alertes dans un tableau de bord Grafana. Pour ce faire, vous devez accéder au tableau de bord :
Le conteneur du pod
alertmanager-0écoute sur le port TCP 9093. Transférez un port local vers le port 9093 du pod :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
Dans votre navigateur Web, accédez à la page
http://localhost:50001.
Modifier la configuration de Prometheus Alertmanager
Vous pouvez modifier la configuration par défaut de Prometheus Alertmanager en modifiant le fichier monitoring.yaml de votre cluster d'utilisateur. Vous devez effectuer cette opération si vous souhaitez diriger les alertes vers une destination spécifique au lieu de les conserver dans le tableau de bord. Pour apprendre à configurer Alertmanager, consultez la documentation sur la configuration de Prometheus.
Pour modifier la configuration d'Alertmanager, procédez comme suit :
Créez une copie du fichier manifeste
monitoring.yamldu cluster d'utilisateur :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Pour configurer Alertmanager, modifiez les champs sous
spec.alertmanager.yml. Lorsque vous avez terminé, enregistrez le fichier manifeste modifié.Appliquez le fichier manifeste à votre cluster :
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Créer un tableau de bord Grafana
Vous avez déployé une application qui expose une métrique et vérifié que celle-ci est exposée et que Prometheus l'extrait. Vous pouvez désormais ajouter la métrique au niveau de l'application dans un tableau de bord Grafana personnalisé.
Pour créer un tableau de bord Grafana, procédez comme suit :
- Si nécessaire, accédez à Grafana.
- Dans le tableau de bord de la page d'accueil, cliquez sur le menu déroulant Home (Accueil) dans l'angle supérieur gauche de la page.
- Dans le menu de droite, cliquez sur New dashboard (Nouveau tableau de bord).
- Dans la section New panel (Nouveau panneau), cliquez sur Graph (Graphique). Un tableau de bord de graphique vide s'affiche.
- Cliquez sur Panel title (Titre du panneau), puis sur Edit (Modifier). Le panneau Graph (Graphique) du bas s'ouvre dans l'onglet Metrics (Métriques).
- Dans le menu déroulant Data Source (Source de données), sélectionnez user (utilisateur). Cliquez sur Add query (Ajouter une requête), puis saisissez
foodans le champ search (recherche). - Cliquez sur le bouton Back to dashboard (Revenir au tableau de bord) dans l'angle supérieur droit de l'écran. Votre tableau de bord s'affiche.
- Pour enregistrer le tableau de bord, cliquez sur Save dashboard (Enregistrer le tableau de bord) dans l'angle supérieur droit de l'écran. Choisissez un nom pour le tableau de bord, puis cliquez sur Save (Enregistrer).
Désactiver Prometheus et Grafana
À partir de la version 1.16, Prometheus et Grafana ne sont plus contrôlés par le champ enablePrometheus de l'objet monitoring-sample.
Pour en savoir plus, consultez Utiliser Prometheus et Grafana.
Exemple : Ajouter des métriques au niveau de l'application dans un tableau de bord Grafana
Les sections suivantes vous expliquent comment ajouter des métriques pour une application. Dans cette section, vous allez effectuer les tâches suivantes :
- Déployer un exemple d'application qui expose une métrique nommée
foo - Vérifier que Prometheus expose et extrait la métrique
- Créer un tableau de bord Grafana personnalisé
Déployer l'exemple d'application
L'exemple d'application s'exécute dans un seul pod. Le conteneur du pod affiche une métrique, foo, avec une valeur constante de 40.
Créez le fichier manifeste de pod suivant, pro-pod.yaml :
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Appliquez ensuite le fichier manifeste du pod à votre cluster d'utilisateur :
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Vérifier que la métrique est exposée et extraite
Le conteneur du pod
prometheus-exampleécoute sur le port TCP 8080. Transférez un port local vers le port 8080 du pod :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
Pour vérifier que l'application expose la métrique, exécutez la commande suivante :
curl localhost:50002/metrics | grep fooLa commande renvoie le résultat suivant :
# HELP foo Custom metric # TYPE foo gauge foo 40
Le conteneur du pod
prometheus-0écoute sur le port TCP 9090. Transférez un port local vers le port 9090 du pod :kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Pour vérifier que Prometheus extrait la métrique, accédez à la page http://localhost:50003/targets, qui doit vous rediriger vers le pod
prometheus-0du groupe cibleprometheus-io-pods.Pour afficher les métriques dans Prometheus, accédez à la page http://localhost:50003/graph. Dans le champ recherche, saisissez
foo, puis cliquez sur Exécuter. La page doit afficher la métrique.
Configurer la ressource personnalisée Stackdriver
Lorsque vous créez un cluster, Google Distributed Cloud crée automatiquement une ressource personnalisée Stackdriver. Vous pouvez modifier la spécification de la ressource personnalisée pour remplacer les valeurs par défaut des demandes et limites de processeurs et de mémoire d'un composant Stackdriver, et modifier séparément la taille de l'espace de stockage et la classe de stockage par défaut.
Remplacer les valeurs par défaut des demandes et limites de processeur et de mémoire
Pour remplacer ces valeurs par défaut, procédez comme suit :
Ouvrez votre ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
où KUBECONFIG représente le chemin d'accès au fichier kubeconfig du cluster. Il peut s'agir d'un cluster d'administrateur ou d'un cluster d'utilisateur.
Dans la ressource personnalisée Stackdriver, ajoutez le champ
resourceAttrOverridesous la sectionspec:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYNotez que la section
resourceAttrOverrideremplace toutes les limites et demandes par défaut du composant spécifié. Les composants suivants sont compatibles avecresourceAttrOverride:- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
Voici un exemple de fichier :
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5GiEnregistrez les modifications et quittez l'éditeur de ligne de commande.
Vérifiez l'état des pods :
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
Par exemple, un pod opérationnel se présente comme suit :
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
Vérifiez la spécification du pod du composant pour vous assurer que les ressources sont définies correctement.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
où
POD_NAMEest le nom du pod que vous venez de modifier. Par exemple,stackdriver-prometheus-k8s-0.La réponse se présente comme suit :
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Remplacer les valeurs par défaut de la taille de l'espace de stockage
Pour remplacer ces valeurs par défaut, procédez comme suit :
Ouvrez votre ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Ajoutez le champ
storageSizeOverridesous la sectionspec. Vous pouvez utiliser le composantstackdriver-prometheus-k8soustackdriver-prometheus-app. Cette section est au format suivant :storageSizeOverride: STATEFULSET_NAME: SIZE
Cet exemple utilise l'ensemble avec état
stackdriver-prometheus-k8set la taille120Gi.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiEnregistrez les modifications, puis quittez l'éditeur de ligne de commande.
Vérifiez l'état des pods :
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Vérifiez la spécification du pod du composant pour vous assurer que la taille de l'espace de stockage a bien été remplacée.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
La réponse se présente comme suit :
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Remplacer les valeurs par défaut des classes de stockage
Conditions préalables
Vous devez d'abord créer une ressource StorageClass à utiliser.
Pour remplacer la classe de stockage par défaut des volumes persistants revendiqués par les composants Logging et Monitoring, procédez comme suit :
Ouvrez votre ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
où KUBECONFIG représente le chemin d'accès au fichier kubeconfig du cluster. Il peut s'agir d'un cluster d'administrateur ou d'un cluster d'utilisateur.
Ajoutez le champ
storageClassNamesous la sectionspec:storageClassName: STORAGECLASS_NAME
Notez que le champ
storageClassNameremplace la classe de stockage par défaut et s'applique à tous les composants Logging et Monitoring avec des volumes persistants revendiqués. Voici un exemple de fichier :apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Enregistrez les modifications.
Vérifiez l'état des pods :
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Par exemple, un pod opérationnel se présente comme suit :
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Vérifiez la spécification de pod d'un composant pour vous assurer que la classe de stockage est correctement définie.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Par exemple, en utilisant l'ensemble avec état
stackdriver-prometheus-k8s, la réponse se présente comme suit :Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Désactiver les métriques optimisées
Par défaut, les agents de métriques exécutés dans le cluster collectent et transmettent à Stackdriver un ensemble optimisé de métriques de conteneurs, de kubelets et d'état Kube. Si vous avez besoin de métriques supplémentaires, nous vous recommandons de trouver un remplacement dans la liste des métriques Google Distributed Cloud.
Voici quelques exemples de remplacements que vous pouvez utiliser :
| Métrique désactivée | Remplacements |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Pour désactiver le paramètre par défaut des métriques d'état Kube optimisées (non recommandé), procédez comme suit :
Ouvrez votre ressource personnalisée Stackdriver dans un éditeur de ligne de commande :
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
où KUBECONFIG représente le chemin d'accès au fichier kubeconfig du cluster. Il peut s'agir d'un cluster d'administrateur ou d'un cluster d'utilisateur.
Définissez le champ
optimizedMetricssurfalse.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class Enregistrez les modifications et quittez l'éditeur de ligne de commande.
Problème connu : condition d'erreur Cloud Monitoring
(ID du problème 159761921)
Dans certaines conditions, le pod Cloud Monitoring par défaut, déployé par défaut dans chaque nouveau cluster, peut ne plus répondre.
Lors de la mise à niveau des clusters, par exemple, les données de stockage peuvent être corrompues lorsque des pods de statefulset/prometheus-stackdriver-k8s sont redémarrés.
Plus précisément, le pod de surveillance stackdriver-prometheus-k8s-0 peut tourner en boucle lorsque des données corrompues empêchent l'écriture de prometheus-stackdriver-sidecar sur l'espace de stockage du cluster PersistentVolume.
Vous pouvez diagnostiquer et récupérer manuellement l'erreur en suivant les étapes ci-dessous.
Diagnostiquer l'échec de Cloud Monitoring
Lorsque le pod de surveillance a échoué, les journaux indiquent les éléments suivants :
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Procéder à la récupération après l'erreur Cloud Monitoring
Pour récupérer Cloud Monitoring manuellement :
Arrêtez la surveillance du cluster. Réduisez la capacité de l'opérateur
stackdriverpour empêcher la réconciliation de la surveillance :kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Supprimez les charges de travail du pipeline de surveillance :
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Supprimez les PersistentVolumeClaims (PVC) du pipeline de surveillance :
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Redémarrez la surveillance du cluster. Augmenter la capacité de l'opérateur Stackdriver pour réinstaller un nouveau pipeline de surveillance et reprendre la réconciliation :
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1