Questa pagina descrive le opzioni di alta disponibilità in Google Distributed Cloud (solo software) per VMware.
Funzionalità di base
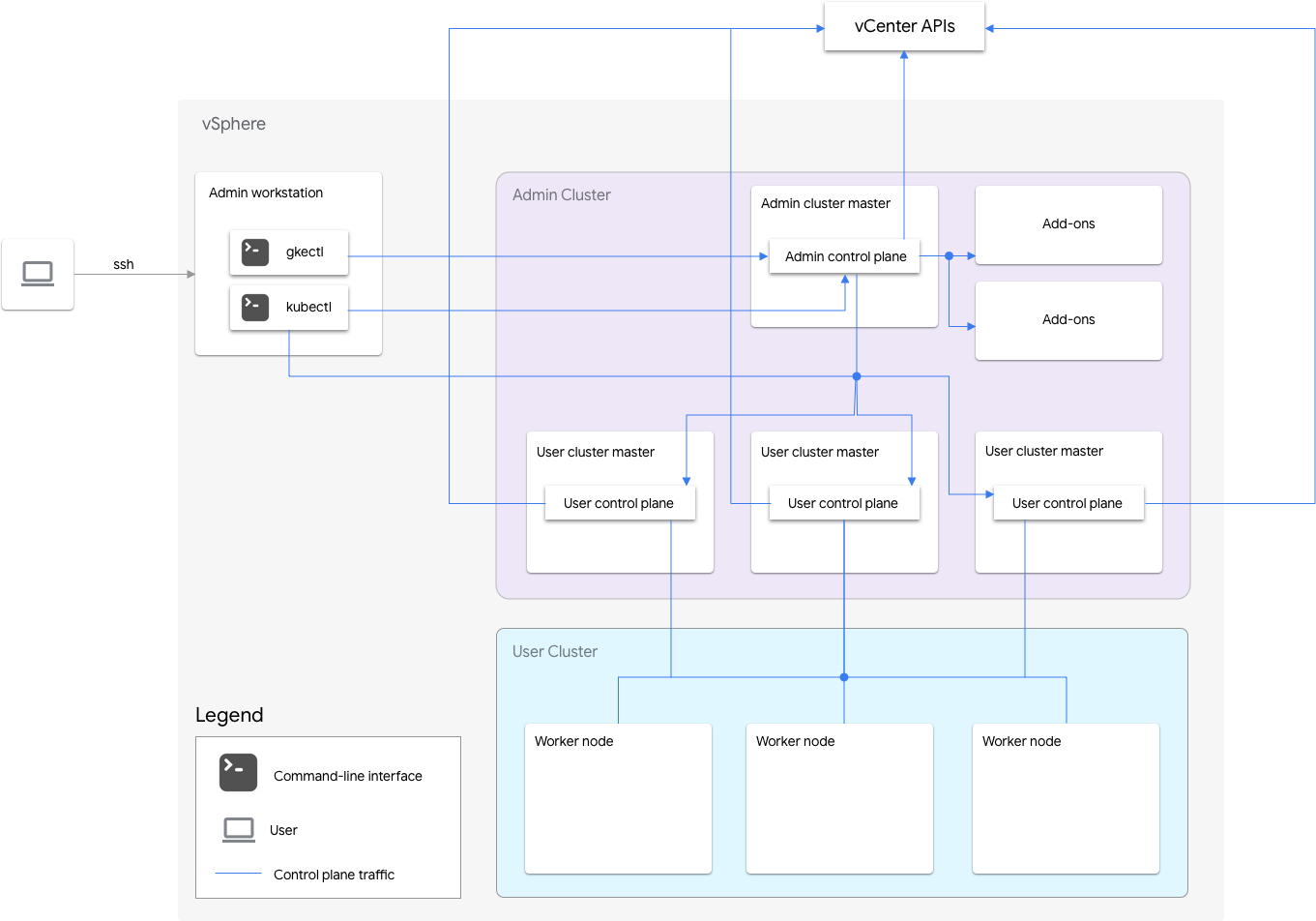
Un'installazione solo software di Google Distributed Cloud per VMware include un cluster di amministrazione e uno o più cluster utente.
Il cluster di amministrazione gestisce il ciclo di vita dei cluster utente, inclusi creazione, aggiornamenti, upgrade ed eliminazione. Nel cluster di amministrazione, il master di amministrazione gestisce i nodi worker di amministrazione, che includono i master utente (nodi che eseguono il control plane dei cluster utente gestiti) e i nodi dei componenti aggiuntivi (nodi che eseguono i componenti aggiuntivi che supportano la funzionalità del cluster di amministrazione).
Per ogni cluster utente, il cluster di amministrazione ha un nodo non ad alta disponibilità o tre nodi ad alta disponibilità che eseguono il control plane. Il control plane include il server API Kubernetes, lo scheduler Kubernetes, il gestore dei controller Kubernetes e diversi controller critici per il cluster utente.
La disponibilità del control plane del cluster utente è fondamentale per le operazioni del workload come la creazione, lo scale up e lo scale down e la terminazione del workload. In altre parole, un'interruzione del control plane non interferisce con i workload in esecuzione, ma i workload esistenti perdono le funzionalità di gestione dal server API Kubernetes se il control plane non è presente.
I carichi di lavoro e i servizi containerizzati vengono implementati nei nodi worker del cluster utente. Nessun singolo nodo worker deve essere fondamentale per la disponibilità dell'applicazione a condizione che l'applicazione venga sottoposta a deployment con pod ridondanti pianificati su più nodi worker.
Abilitazione dell'alta disponibilità
vSphere e Google Distributed Cloud forniscono una serie di funzionalità che contribuiscono all'alta disponibilità.
vSphere HA e vMotion
Ti consigliamo di attivare le seguenti due funzionalità nel cluster vCenter che ospita i cluster Google Distributed Cloud:
Queste funzionalità migliorano la disponibilità e il ripristino in caso di errore di un host ESXi.
vCenter HA utilizza più host ESXi configurati come cluster per fornire un rapido
recupero dalle interruzioni e un'alta disponibilità conveniente per le applicazioni
in esecuzione nelle macchine virtuali. Ti consigliamo di eseguire il provisioning del cluster vCenter con host aggiuntivi e di attivare il monitoraggio host vSphere HA con Host Failure Response impostato su Restart VMs. Le VM possono quindi essere
riavviate automaticamente su altri host disponibili in caso di errore dell'host ESXi.
vMotion consente la migrazione live senza tempi di inattività delle VM da un host ESXi a un altro. Per la manutenzione pianificata dell'host, puoi utilizzare la migrazione live di vMotion per evitare completamente i tempi di inattività dell'applicazione e garantire la continuità aziendale.
Cluster di amministrazione
Google Distributed Cloud supporta la creazione di cluster di amministrazione ad alta disponibilità. Un cluster di amministrazione HA ha tre nodi che eseguono i componenti del control plane. Per informazioni su requisiti e limitazioni, vedi Cluster di amministrazione ad alta affidabilità.
Tieni presente che l'indisponibilità del control plane del cluster di amministrazione non influisce sulla funzionalità del cluster utente esistente o su qualsiasi workload in esecuzione nei cluster utente.
In un cluster di amministrazione sono presenti due nodi del componente aggiuntivo. Se uno non funziona, l'altro
può comunque gestire le operazioni del cluster di amministrazione. Per la ridondanza,
Google Distributed Cloud distribuisce i servizi aggiuntivi critici, come kube-dns,
su entrambi i nodi aggiuntivi.
Se imposti antiAffinityGroups.enabled su true nel file di configurazione del cluster di amministrazione, Google Distributed Cloud crea automaticamente regole anti-affinità vSphere DRS per i nodi del componente aggiuntivo, che vengono distribuiti su due host fisici per la HA.
Cluster utente
Puoi attivare l'alta disponibilità per un cluster utente impostando masterNode.replicas su 3 nel file di configurazione del cluster utente. Se il cluster utente ha
Controlplane V2
abilitato (opzione consigliata), i tre nodi del control plane vengono eseguiti nel cluster utente.
I cluster utente HA legacy in cui non è abilitato Controlplane V2
eseguono i tre nodi del control plane nel cluster di amministrazione. Ogni nodo del control plane
esegue anche una replica etcd. Il cluster utente continua a funzionare
finché è in esecuzione un control plane ed è presente un quorum etcd. Un quorum etcd
richiede che due delle tre repliche etcd funzionino.
Se imposti antiAffinityGroups.enabled su true nel file di configurazione del cluster di amministrazione, Google Distributed Cloud crea automaticamente regole di anti-affinità vSphere DRS per i tre nodi che eseguono il control plane del cluster utente.
In questo modo, le VM vengono distribuite su tre host fisici.
Google Distributed Cloud crea anche regole anti-affinità vSphere DRS per i nodi worker del cluster utente, in modo da distribuirli in almeno tre host fisici. Per ogni pool di nodi del cluster utente vengono utilizzate più regole di anti-affinità DRS in base al numero di nodi. In questo modo, i nodi worker possono trovare host su cui essere eseguiti, anche quando il numero di host è inferiore al numero di VM nel pool di nodi del cluster utente. Ti consigliamo di includere host fisici aggiuntivi nel cluster vCenter. Configura inoltre DRS in modo che sia completamente automatizzato, in modo che, nel caso in cui un host non sia disponibile, DRS possa riavviare automaticamente le VM su altri host disponibili senza violare le regole anti-affinità delle VM.
Google Distributed Cloud gestisce un'etichetta di nodo speciale, onprem.gke.io/failure-domain-name, il cui valore è impostato sul nome host ESXi sottostante. Le applicazioni utente che richiedono alta disponibilità possono configurare
regole podAntiAffinity con questa etichetta come topologyKey per garantire che
i pod dell'applicazione siano distribuiti su VM e host fisici diversi.
Puoi anche configurare più pool di nodi per un cluster utente con datastore diversi ed etichette di nodi speciali. Allo stesso modo, puoi configurare regole podAntiAffinity
con questa etichetta di nodo speciale come topologyKey per ottenere una disponibilità
maggiore in caso di errori del datastore.
Per la HA per i workload utente, assicurati che il cluster utente abbia un numero sufficiente
di repliche in nodePools.replicas, il che garantisce il numero desiderato di nodi worker del cluster utente in esecuzione.
Puoi utilizzare datastore separati per i cluster di amministrazione e i cluster utente per isolare i relativi errori.
Bilanciatore del carico
Esistono due tipi di bilanciatori del carico che puoi utilizzare per l'alta disponibilità.
Bilanciatore del carico MetalLB in bundle
Per il
bilanciatore del carico MetalLB in bundle,
ottieni l'alta disponibilità avendo più di un nodo con enableLoadBalancer: true.
MetalLB distribuisce i servizi sui nodi del bilanciatore del carico, ma per un singolo servizio esiste un solo nodo leader che gestisce tutto il traffico per quel servizio.
Durante l'upgrade del cluster, si verifica un tempo di inattività durante l'upgrade dei nodi del bilanciatore del carico. La durata dell'interruzione del failover di MetalLB aumenta con l'aumentare del numero di nodi del bilanciatore del carico. Con meno di 5 nodi, l'interruzione dura 10 secondi.
Bilanciamento del carico manuale
Con il bilanciamento del carico manuale, configuri Google Distributed Cloud in modo che utilizzi un bilanciatore del carico a tua scelta, ad esempio F5 BIG-IP o Citrix. Configura l'alta affidabilità sul bilanciatore del carico, non in Google Distributed Cloud.
Utilizzo di più cluster per il ripristino di emergenza
Il deployment di applicazioni in più cluster su più server vCenter può fornire una disponibilità globale più elevata e limitare il raggio d'azione durante le interruzioni.
Questa configurazione utilizza il cluster esistente nel data center secondario per il ripristino di emergenza anziché configurare un nuovo cluster. Di seguito è riportato un riepilogo di alto livello per raggiungere questo obiettivo:
Crea un altro cluster di amministrazione e un altro cluster utente nel data center secondario. In questa architettura multi-cluster, richiediamo agli utenti di avere due cluster di amministrazione in ogni data center e ogni cluster di amministrazione esegue un cluster utente.
Il cluster utente secondario ha un numero minimo di nodi worker (tre) ed è un hot standby (sempre in esecuzione).
I deployment delle applicazioni possono essere replicati nei due vCenter utilizzando Config Sync oppure l'approccio preferito è utilizzare una toolchain DevOps (CI/CD, Spinnaker) per le applicazioni esistente.
In caso di emergenza, il cluster utente può essere ridimensionato in base al numero di nodi.
Inoltre, è necessario un cambio di DNS per indirizzare il traffico tra i cluster al data center secondario.