本页面介绍了 Google Distributed Cloud for VMware(纯软件)中的高可用性选项。
核心功能
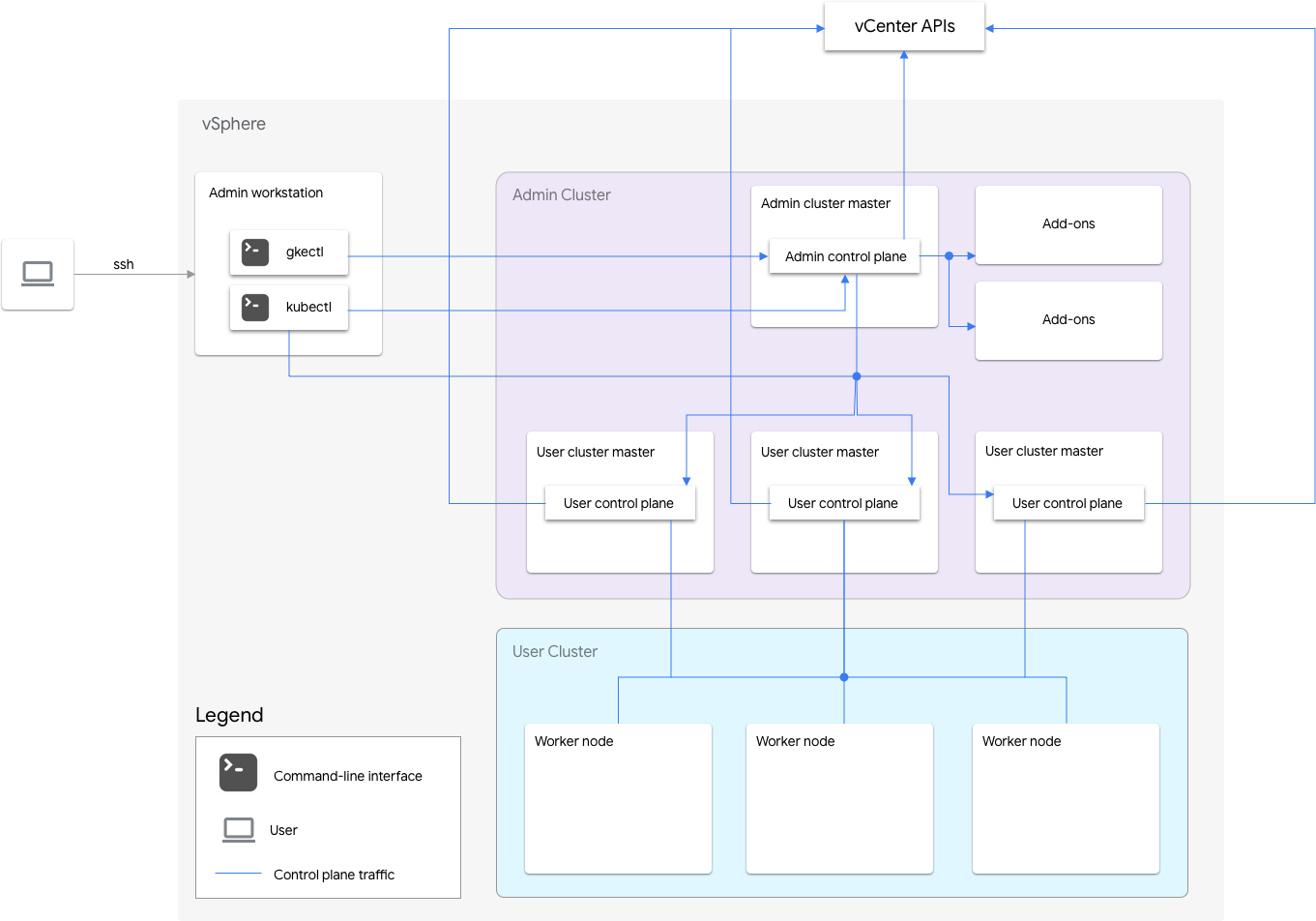
Google Distributed Cloud for VMware 的纯软件安装包括一个管理员集群和一个或多个用户集群。
管理员集群管理用户集群的生命周期,包括用户集群创建、更新、升级和删除。在管理员集群中,管理员主节点管理管理员工作器节点,这些节点包括用户主节点(运行代管式用户集群的控制平面的节点)和插件节点(运行支持管理员集群功能的插件组件的节点)。
对于每个用户集群,管理员集群都有一个运行控制平面的非高可用性节点或三个高可用性节点。控制平面包括 Kubernetes API 服务器、Kubernetes 调度器、Kubernetes 控制器管理器以及用户集群的几个关键控制器。
用户集群控制平面的可用性对于工作负载操作(例如工作负载创建、扩缩和终止)至关重要。换句话说,控制平面中断虽然不会影响正在运行的工作负载,但如果控制平面缺失,现有工作负载将无法对 Kubernetes API 服务器进行管理。
容器化工作负载和服务部署在用户集群工作器节点中。只要应用的部署方式使得可在多个工作器节点上调度冗余 pod,那么任何单个工作器节点对于应用可用性都不是不可或缺的。
启用高可用性
vSphere 和 Google Distributed Cloud 提供了很多有助于实现高可用性 (HA) 的功能。
vSphere HA 和 vMotion
我们建议在托管 Google Distributed Cloud 集群的 vCenter 集群中启用以下两个功能:
在 ESXi 主机出现故障时,这些功能可增强可用性和恢复能力。
vCenter HA 使用配置为集群的多个 ESXi 主机,为在虚拟机中运行的应用提供快速的中断恢复能力和经济实惠的高可用性。我们建议您为 vCenter 集群预配额外的主机,启用 vSphere HA 主机监控,并将 Host Failure Response 设置为 Restart VMs。这样,当 ESXi 主机发生故障时,您的虚拟机可以在其他可用的主机上自动重启。
vMotion 支持将虚拟机从一个 ESXi 主机实时迁移到另一个主机,实现零停机时间。对于计划的主机维护,您可以使用 vMotion 实时迁移完全避免应用停机并确保业务连续性。
管理员集群
Google Distributed Cloud 支持创建高可用性 (HA) 管理员集群。一个 HA 管理员集群有三个节点,用于运行控制平面组件。如需了解要求和限制,请参阅高可用性管理员集群。
请注意,管理员集群控制平面不可用不会影响现有用户集群功能或用户集群中运行的任何工作负载。
管理员集群中有两个插件节点。如果其中一个发生故障,另一个仍然可以处理管理员集群操作。为了实现冗余,Google Distributed Cloud 将关键的插件 Service(例如 kube-dns)分布到两个插件节点上。
如果您在管理员集群配置文件中将 antiAffinityGroups.enabled 设置为 true,Google Distributed Cloud 会自动为插件节点创建 vSphere DRS 反亲和性规则,使它们分布在两个物理主机上,以实现高可用性。
用户集群
您可以在用户集群配置文件中将 masterNode.replicas 设置为 3,从而为用户集群启用高可用性。如果用户集群启用了控制平面 V2(推荐),则 3 个控制平面节点在用户集群中运行。未启用 Controlplane V2 的旧版高可用性用户集群在管理员集群中运行三个控制平面节点。每个控制平面节点还会运行一个 etcd 副本。只要有一个控制平面在运行并且存在 etcd 仲裁,用户集群就会继续工作。etcd 仲裁需要三个 etcd 副本中有两个在正常运行。
如果您在管理员集群配置文件中将 antiAffinityGroups.enabled 设置为 true,Google Distributed Cloud 会自动为运行用户集群控制平面的三个节点创建 vSphere DRS 反亲和性规则。这会使这些虚拟机分布到三个物理主机上。
Google Distributed Cloud 还会为用户集群中的工作器节点创建 vSphere DRS 反亲和性规则,使这些节点分布到至少三个物理主机上。每个用户集群节点池根据节点数量使用多个 DRS 反亲和性规则。这样可以确保工作器节点能够找到要运行它的主机,即使主机数量少于用户集群节点池中的虚拟机数量也是如此。我们建议您在 vcenter 集群中添加额外的物理主机。此外,请将 DRS 配置为完全自动化,这样,如果某个主机不可用,DRS 可以自动在其他可用主机上重启虚拟机,而不会违反虚拟机的反亲和性规则。
Google Distributed Cloud 会维护一个特殊节点标签 onprem.gke.io/failure-domain-name,其值设置为底层 ESXi 主机名。需要高可用性的用户应用可以设置 podAntiAffinity 规则并将此标签作为 topologyKey,以确保其应用 Pod 分布到不同的虚拟机和物理主机上。您还可以为具有不同数据存储区和特殊节点标签的用户集群配置多个节点池。同样,您可以设置 podAntiAffinity 规则并将该特殊节点标签作为 topologyKey,以便在数据存储区发生故障时实现更高的可用性。
如需使用户工作负载具有高可用性,请确保用户集群在 nodePools.replicas 下有足够数量的副本,这将确保有所需数量的用户集群工作器节点处于运行状态。
您可以为管理员集群和用户集群使用不同的数据存储区,以隔离它们的故障。
负载均衡器
您可以使用两种负载均衡器类型来实现高可用性。
捆绑式 MetalLB 负载均衡器
对于捆绑式 MetalLB 负载均衡器,您可以通过将多个节点使用 enableLoadBalancer: true 来实现 HA。
MetalLB 将服务分发到负载均衡器节点,但对于单个服务,只有一个主节点来处理该服务的所有流量。
在集群升级期间,负载均衡器节点的升级会导致一些停机时间。随着负载均衡器节点数量的增加,MetalLB 的故障转移中断时长也会增加。如果节点少于 5 个,则中断在 10 秒内。
手动负载均衡
使用手动负载均衡时,您可以将 Google Distributed Cloud 配置为使用您选择的负载均衡器,例如 F5 BIG-IP 或 Citrix。您可以在负载均衡器上(而非在 Google Distributed Cloud 中)配置高可用性。
使用多个集群进行灾难恢复
在跨多个 vCenter 服务器的多个集群中部署应用可提供更高的全球可用性并限制中断的影响范围。
此设置使用次要数据中心中的现有集群进行灾难恢复,而不是设置新集群。下面是实现此设置的简要概述:
在次要数据中心中再创建一个管理员集群和用户集群。在这种多集群架构中,我们要求用户在每个数据中心中有两个管理员集群,并且每个管理员集群运行一个用户集群。
次要用户集群具有最少数量的工作器节点(3 个),并且是热备用(始终运行)。
可以使用 Config Sync 在两个 vCenter 之间复制应用部署,或者首选方法是利用现有应用 DevOps(CI/CD、spinnaker)工具链。
如果发生灾难,用户集群的大小可以调整为节点数量。
此外,需要使用 DNS 切换将集群之间的流量路由到次要数据中心。