Halaman ini menjelaskan opsi ketersediaan tinggi di Google Distributed Cloud (khusus software) untuk VMware.
Fungsi inti
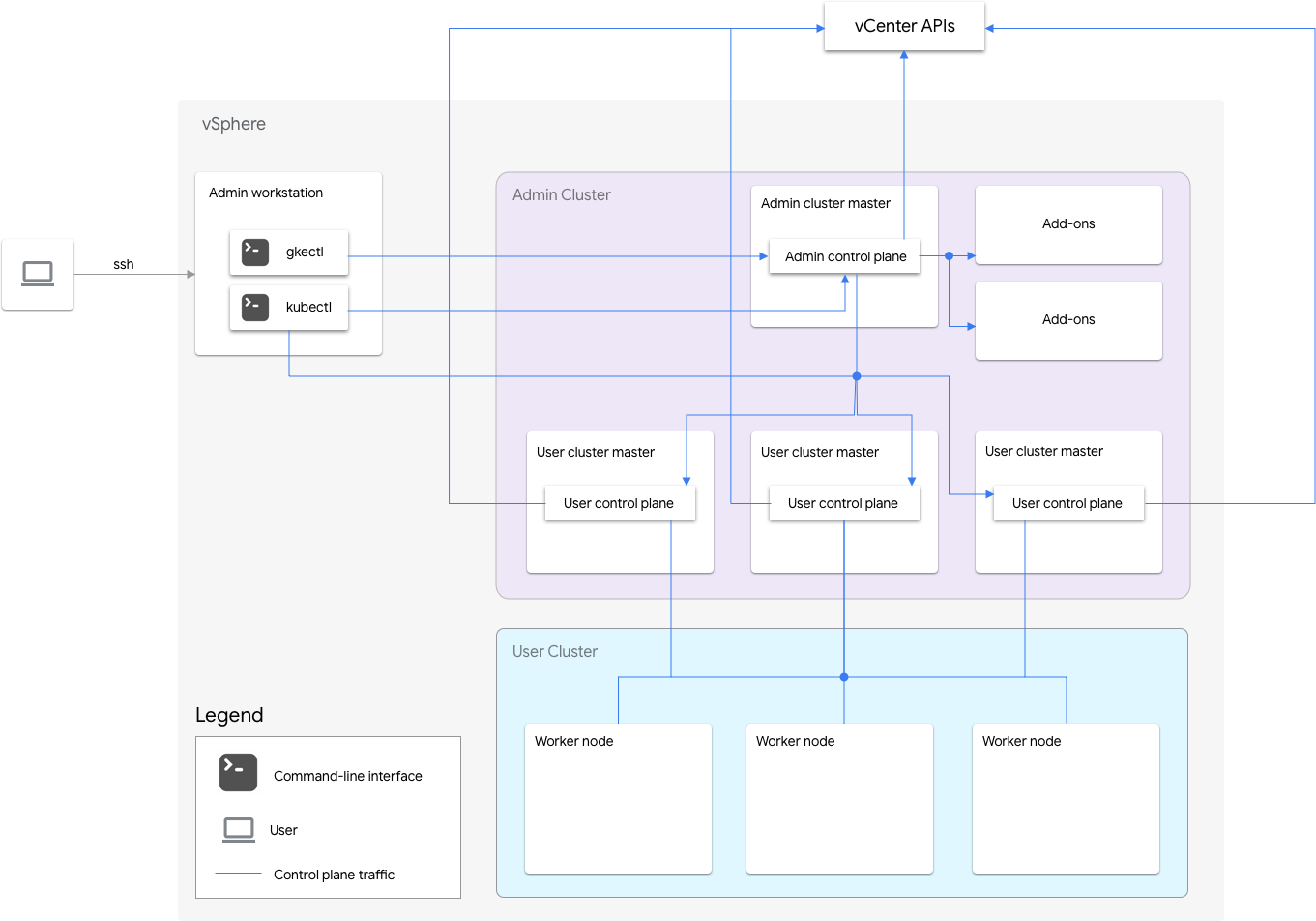
Penginstalan Google Distributed Cloud untuk VMware khusus software mencakup cluster admin dan satu atau beberapa cluster pengguna.
Cluster admin mengelola siklus proses cluster pengguna, termasuk pembuatan, update, upgrade, dan penghapusan cluster pengguna. Di cluster admin, master admin mengelola node pekerja admin, yang mencakup master pengguna (node yang menjalankan bidang kontrol cluster pengguna terkelola) dan node add-on (node yang menjalankan komponen add-on yang mendukung fungsi cluster admin).
Untuk setiap cluster pengguna, cluster admin memiliki satu node non-HA atau tiga node HA yang menjalankan bidang kontrol. Bidang kontrol mencakup server Kubernetes API, penjadwal Kubernetes, pengelola pengontrol Kubernetes, dan beberapa pengontrol penting untuk cluster pengguna.
Ketersediaan bidang kontrol cluster pengguna sangat penting untuk operasi workload seperti pembuatan, peningkatan dan penurunan skala, serta penghentian workload. Dengan kata lain, gangguan bidang kontrol tidak mengganggu workload yang sedang berjalan, tetapi workload yang ada akan kehilangan kemampuan pengelolaan dari server Kubernetes API jika bidang kontrolnya tidak ada.
Workload dan layanan dalam container di-deploy di node pekerja cluster pengguna. Setiap node pekerja tunggal tidak boleh penting untuk ketersediaan aplikasi selama aplikasi di-deploy dengan pod redundan yang dijadwalkan di beberapa node pekerja.
Mengaktifkan ketersediaan tinggi
vSphere dan Google Distributed Cloud menyediakan sejumlah fitur yang berkontribusi pada ketersediaan tinggi (HA).
vSphere HA dan vMotion
Sebaiknya aktifkan dua fitur berikut di cluster vCenter yang menghosting cluster Google Distributed Cloud Anda:
Fitur ini meningkatkan ketersediaan dan pemulihan jika terjadi kegagalan host ESXi.
vCenter HA menggunakan beberapa host ESXi yang dikonfigurasi sebagai cluster untuk memberikan pemulihan cepat dari pemadaman dan HA yang hemat biaya untuk aplikasi yang berjalan di mesin virtual. Sebaiknya Anda menyediakan cluster vCenter dengan host tambahan dan mengaktifkan Pemantauan Host HA vSphere dengan Host Failure Response yang ditetapkan ke Restart VMs. VM Anda kemudian dapat dimulai ulang secara otomatis di host lain yang tersedia jika terjadi kegagalan host ESXi.
vMotion memungkinkan migrasi langsung VM tanpa waktu henti dari satu host ESXi ke host ESXi lainnya. Untuk pemeliharaan host yang direncanakan, Anda dapat menggunakan migrasi langsung vMotion untuk menghindari downtime aplikasi sepenuhnya dan memastikan kelangsungan bisnis.
Cluster admin
Google Distributed Cloud mendukung pembuatan cluster admin dengan ketersediaan tinggi (HA). Cluster admin HA memiliki tiga node yang menjalankan komponen bidang kontrol. Untuk mengetahui informasi tentang persyaratan dan batasan, lihat Cluster admin ketersediaan tinggi.
Perhatikan bahwa tidak tersedianya bidang kontrol cluster admin tidak memengaruhi fungsi cluster pengguna yang ada atau beban kerja apa pun yang berjalan di cluster pengguna.
Ada dua node add-on di cluster admin. Jika salah satunya tidak berfungsi, yang lainnya
masih dapat melayani operasi cluster admin. Untuk redundansi, Google Distributed Cloud menyebarkan Layanan add-on penting, seperti kube-dns, di kedua node add-on.
Jika Anda menyetel antiAffinityGroups.enabled ke true dalam file konfigurasi cluster admin, Google Distributed Cloud akan otomatis membuat aturan anti-afinitas vSphere DRS untuk node add-on, yang menyebabkan node tersebut tersebar di dua host fisik untuk HA.
Cluster pengguna
Anda dapat mengaktifkan HA untuk cluster pengguna dengan menyetel masterNode.replicas ke 3 di
file konfigurasi cluster pengguna. Jika cluster pengguna telah mengaktifkan
Controlplane V2 (direkomendasikan), 3 node bidang kontrol akan berjalan di cluster pengguna.
Cluster pengguna HA lama yang tidak mengaktifkan Controlplane V2 menjalankan tiga node bidang kontrol di cluster admin. Setiap node bidang kontrol juga menjalankan replika etcd. Cluster pengguna terus berfungsi
selama ada satu bidang kontrol yang berjalan dan kuorum etcd. Kuorum etcd memerlukan dua dari tiga replika etcd agar berfungsi.
Jika Anda menyetel antiAffinityGroups.enabled ke true dalam file konfigurasi cluster admin, Google Distributed Cloud akan otomatis membuat aturan anti-afinitas DRS vSphere untuk tiga node yang menjalankan bidang kontrol cluster pengguna.
Hal ini menyebabkan VM tersebut tersebar di tiga host fisik.
Google Distributed Cloud juga membuat aturan anti-afinitas vSphere DRS untuk node pekerja di cluster pengguna Anda, yang menyebabkan node tersebut tersebar di setidaknya tiga host fisik. Beberapa aturan anti-afinitas DRS digunakan per node pool cluster pengguna berdasarkan jumlah node. Hal ini memastikan bahwa node pekerja dapat menemukan host untuk dijalankan, meskipun jumlah host kurang dari jumlah VM di node pool cluster pengguna. Sebaiknya sertakan host fisik tambahan dalam cluster vCenter Anda. Konfigurasi juga DRS agar sepenuhnya otomatis sehingga jika host menjadi tidak tersedia, DRS dapat secara otomatis memulai ulang VM di host lain yang tersedia tanpa melanggar aturan anti-afinitas VM.
Google Distributed Cloud mempertahankan label node khusus, onprem.gke.io/failure-domain-name, yang nilainya ditetapkan ke nama host ESXi yang mendasarinya. Aplikasi pengguna yang menginginkan ketersediaan tinggi dapat menyiapkan aturan
podAntiAffinity dengan label ini sebagai topologyKey untuk memastikan bahwa Pod
aplikasinya tersebar di berbagai VM serta host fisik.
Anda juga dapat mengonfigurasi beberapa node pool untuk cluster pengguna dengan
datastore dan label node khusus yang berbeda. Demikian pula, Anda dapat menyiapkan aturan podAntiAffinity
dengan label node khusus tersebut sebagai topologyKey untuk mencapai ketersediaan
yang lebih tinggi saat terjadi kegagalan penyimpanan data.
Untuk memiliki HA bagi beban kerja pengguna, pastikan cluster pengguna memiliki jumlah replika yang memadai di bawah nodePools.replicas, yang memastikan jumlah node pekerja cluster pengguna yang diinginkan dalam kondisi berjalan.
Anda dapat menggunakan penyimpanan data terpisah untuk cluster admin dan cluster pengguna guna mengisolasi kegagalannya.
Load balancer
Ada dua jenis load balancer yang dapat Anda gunakan untuk ketersediaan tinggi.
Load balancer MetalLB yang dibundel
Untuk
load balancer MetalLB yang dibundel,
Anda mencapai ketersediaan tinggi dengan memiliki lebih dari satu node dengan enableLoadBalancer: true.
MetalLB mendistribusikan layanan ke node load balancer, tetapi untuk satu layanan, hanya ada satu node pemimpin yang menangani semua traffic untuk layanan tersebut.
Selama upgrade cluster, akan ada periode nonaktif saat node load balancer diupgrade. Durasi gangguan failover MetalLB bertambah seiring dengan bertambahnya jumlah node load balancer. Dengan kurang dari 5 node, gangguan terjadi dalam waktu 10 detik.
Load balancing manual
Dengan load balancing manual, Anda mengonfigurasi Google Distributed Cloud untuk menggunakan load balancer pilihan Anda, seperti F5 BIG-IP atau Citrix. Anda mengonfigurasi ketersediaan tinggi pada load balancer, bukan di Google Distributed Cloud.
Menggunakan beberapa cluster untuk pemulihan dari bencana
Men-deploy aplikasi di beberapa cluster di beberapa server vCenter dapat memberikan ketersediaan global yang lebih tinggi dan membatasi radius dampak saat terjadi gangguan.
Penyiapan ini menggunakan cluster yang ada di pusat data sekunder untuk pemulihan dari bencana, bukan menyiapkan cluster baru. Berikut adalah ringkasan tingkat tinggi untuk melakukannya:
Buat cluster admin dan cluster pengguna lain di pusat data sekunder. Dalam arsitektur multi-cluster ini, kami mewajibkan pengguna memiliki dua cluster admin di setiap pusat data, dan setiap cluster admin menjalankan cluster pengguna.
Cluster pengguna sekunder memiliki jumlah minimum node pekerja (tiga) dan merupakan standby aktif (selalu berjalan).
Deployment aplikasi dapat direplikasi di dua vCenter menggunakan Config Sync, atau pendekatan yang lebih disukai adalah menggunakan toolchain DevOps aplikasi (CI/CD, Spinnaker) yang ada.
Jika terjadi bencana, cluster pengguna dapat diubah ukurannya menjadi jumlah node.
Selain itu, pengalihan DNS diperlukan untuk merutekan traffic antara cluster ke pusat data sekunder.