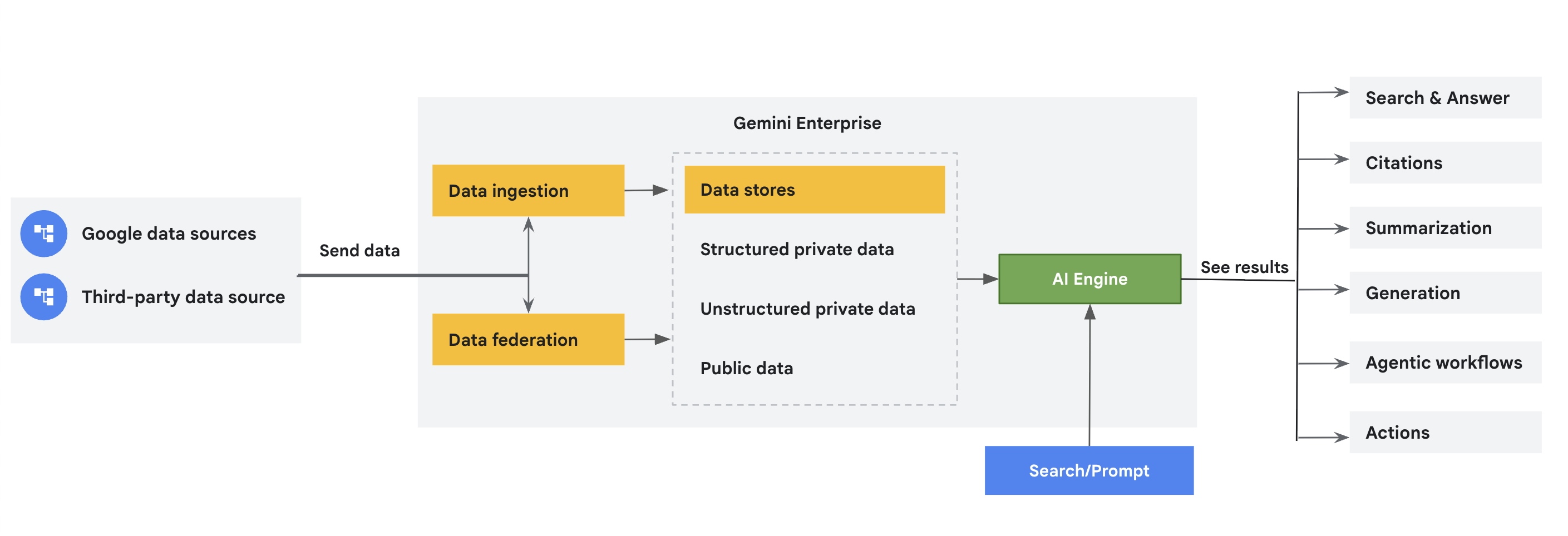
Os conectores recebem dados do Google e de fontes terceirizadas no Gemini Enterprise, armazenando-os em repositórios dedicados. Este documento oferece uma visão geral desses conectores. Centralizar seus dados no Gemini Enterprise aumenta a acessibilidade, a funcionalidade de pesquisa e os recursos de análise.
Conceitos de conector e repositório de dados
Repositórios de dados |
| Cada fonte de dados oferece suporte a um conjunto de tipos de entidade. Por exemplo, o Jira Cloud tem entidades como problemas, anexos, comentários e registros de trabalho, que são exclusivos da fonte de dados. O Gemini Enterprise cria um repositório de dados separado para cada entidade. Portanto, ao criar um repositório de dados usando o console do Google Cloud , você recebe uma coleção de repositórios de dados que representam essas entidades de dados ingeridas. |
Federação x ingestão (indexação) de dados |
| A federação de dados recupera informações diretamente da fonte especificada. Como os dados não são copiados para o índice da Vertex AI para Pesquisa, não é preciso se preocupar com o armazenamento de dados. No entanto, como os dados não são indexados, a qualidade da pesquisa pode ser menor. A ingestão de dados (indexação) copia os dados para o índice da Vertex AI para Pesquisa. Isso pode melhorar a qualidade da pesquisa. No entanto, esse processo consome mais armazenamento e tempo. |
Dados não estruturados |
| O formato de dados compatível é específico da fonte de dados e do tipo de entidade. Se o conteúdo de uma entidade for armazenado em um formato não estruturado, como HTML, PDF, TXT, PPTX ou DOCX, a Vertex AI para Pesquisa vai criar um repositório de dados não estruturados. Para mais informações e tipos de arquivos compatíveis, consulte Pesquisa não estruturada. |
Dados estruturados |
| O formato de dados compatível é específico da fonte de dados e do tipo de entidade. Se o conteúdo de uma entidade for armazenado em um formato estruturado, a Vertex AI para Pesquisa vai criar um repositório de dados estruturados. Para mais informações, consulte Pesquisa estruturada. |
Esquemas de dados |
| O esquema de dados define a estrutura dos dados. Ao importar dados estruturados usando o Gemini Enterprise, o sistema detecta automaticamente o esquema. É possível usar o esquema detectado automaticamente ou definir o esquema usando a API. Para mais informações, consulte Fornecer ou detectar automaticamente um esquema. |
Regiões de repositório de dados |
| Ao ingerir dados, selecione a região em que você quer armazenar os dados, como global, EUA ou UE. Para mais informações, consulte Locais do Gemini Enterprise. Os dados armazenados nas regiões dos EUA ou da UE exigem criptografia. A criptografia padrão é com Google-owned and Google-managed encryption keys, mas, como alternativa, você pode usar chaves de criptografia gerenciadas pelo cliente. |
Sincronizações de dados |
Uma sincronização de dados extrai e atualiza dados de identidade (como funções, permissões e usuários) e dados de entidade (como dados relacionados a uma fonte de dados específica) da fonte de dados original. Para mais informações, consulte Tipos e programações de sincronização de dados. |
Tipos e programações de sincronização de dados
Uma sincronização de dados captura dados de entidade, dados de identidade ou ambos e atualiza o conteúdo do repositório de dados no Gemini Enterprise.
Tipos de sincronização
Os repositórios de dados no Gemini Enterprise usam dois tipos essenciais de sincronização de dados:
Uma sincronização completa captura todo o estado do app ou serviço de terceiros. Isso inclui adições, atualizações e exclusões. Uma sincronização completa substitui o conteúdo atual do repositório de dados.
Uma sincronização incremental captura periodicamente os dados de entidade que foram adicionados ou atualizados desde a última sincronização. Ela não sincroniza dados de identidade nem exclusões de dados de entidades.
É possível programar uma sincronização completa separadamente para os seguintes tipos de dados:
Uma sincronização de entidades captura dados específicos da fonte de dados de terceiros. Por exemplo, um repositório de dados para um sistema como o Jira pode sincronizar problemas, registros de trabalho, comentários e anexos. As sincronizações de entidades não incluem informações de identidade.
Uma sincronização de identidade captura dados sobre contas de usuário associadas a um grupo de ACL.
Interação entre a sincronização de identidade e a sincronização completa
Para entender como uma execução de sincronização de identidade individual funciona com uma execução de sincronização completa, considere um exemplo de cenário com duas páginas: page_1, vinculada a um grupo de ACL group_1, e page_2, vinculada a um grupo de ACL group_2.
Uma sincronização inicial de identidade é executada e recupera informações sobre os grupos
group_1egroup_2.Suponha que
group_1contenha o usuáriouser_1.Suponha que
group_2contenha o usuáriouser_2.
Essa sincronização de identidade estabelece o seguinte mapeamento:
user_1é mapeado paragroup_1.user_2é mapeado paragroup_2.
Além da sincronização de identidade, uma sincronização completa é executada, buscando
page_1epage_2.Essa sincronização completa estabelece o seguinte mapeamento:
O app
user_1tem acesso aos dados depage_1(viagroup_1).O app
user_2tem acesso aos dados depage_2(viagroup_2).
Programações de sincronização
Para cada repositório de dados, é possível selecionar uma frequência para diferentes tipos de sincronização:
As sincronizações completas de todos os dados de identidade e de entidade podem ser programadas simultaneamente a cada 3, 6, 12 horas, 1 dia ou 3 dias.
Sincronizações completas independentes de todos os dados de identidade e de todas as informações de entidade podem ser programadas separadamente usando qualquer uma das seguintes frequências de sincronização personalizadas:
Dados de entidades: a cada 3 horas, 6 horas, 12 horas, 1 dia, 3 dias, 5 dias e 7 dias.
Dados de identidade: a cada 30 minutos, 1 hora, 3 horas, 6 horas, 12 horas, 1 dia, 3 dias, 5 dias e 7 dias.
As sincronizações incrementais de dados de entidades atualizados ou adicionados podem ser programadas a cada 3, 6, 12 horas, 1, 3, 5 ou 7 dias. Por padrão, uma sincronização incremental é realizada a cada 3 horas.
Recomendações de frequência
Escolha uma frequência de sincronização de dados que esteja alinhada ao volume de registros buscados e às consultas por segundo (QPS) recomendadas.
A tabela a seguir mostra o número típico de registros recuperados para sincronizações de um, três, cinco e sete dias. O número real de registros pode variar dependendo da fonte de dados e da configuração dela.
| QPS | Volume de registros para sincronização de um dia | Volume de registros para sincronização de três dias | Volume de registros para sincronização de cinco dias | Volume de registros para sincronização de sete dias |
|---|---|---|---|---|
| 5 | 432 mil | 1,296 milhão | 2,16 milhões | 3 milhões |
| 10 | 864 mil | 2,592 milhões | 4,32 milhões | 6 milhões |
| 20 | 1,7 mi | 5,1 mi | 8,5 MI | 11,9 mi |
| 50 | 4,3 milhões | 12,9 mi | 21,5 milhões | 30,1 milhões |
| 100 | 8,6 mi | 25,8 milhões | 43 milhões | 60,2 mi |
Como pausar e retomar sincronizações
É possível pausar e retomar as sincronizações completas e incrementais:
Quando você pausa um tipo de sincronização, o repositório de dados cancela as sincronizações em andamento desse tipo e interrompe o agendamento de novas sincronizações desse tipo.
Quando você retoma um tipo de sincronização, o repositório de dados agenda a nova sincronização com base no último horário agendado, mas não continua a sincronização interrompida anteriormente.
Por exemplo, se você pausar a sincronização completa enquanto ela estiver em andamento, o repositório de dados vai cancelar esse processo. Se você retomar a sincronização completa mais tarde, o repositório de dados vai agendar automaticamente uma nova sincronização completa de acordo com a programação.
Origens de dados do Google
É possível se conectar a fontes de dados do Google, como BigQuery, Spanner e Google Drive.
Lista de verificação para fontes de dados do Google
Antes de enviar dados para o Gemini Enterprise, confira a seguinte lista de verificação:
Configure o controle de acesso para sua fonte de dados. Para mais informações, consulte Identidade e permissões.
Decida se os dados devem ser federados ou ingeridos (indexados).
Decida a frequência de sincronização dos dados.
Se você estiver usando chaves de criptografia gerenciadas pelo cliente (CMEK), crie chaves multirregionais. Para mais informações, consulte Registrar chaves de região única para fontes de dados de terceiros.
Se você tiver informações de identificação pessoal (PII) e quiser usar o preenchimento automático para sugestões de consultas, consulte proteção contra vazamentos de PII.
Fontes de dados do Google compatíveis
| Google Drive | Gmail | Google Agenda | Pesquisa de pessoas |

|

|

|

|
Fontes de dados de terceiros
Os repositórios de dados de terceiros ingerem dados de aplicativos de terceiros no Gemini Enterprise.
Lista de verificação para origens de dados de terceiros
Antes de conectar uma fonte de dados de terceiros ao Gemini Enterprise, confira a seguinte lista de verificação:
Escopos e permissões específicos precisam ser configurados para determinadas fontes de dados. Um administrador do aplicativo de terceiros precisa revisar as credenciais necessárias para conectar uma fonte de dados e configurar a autenticação e as permissões. Para informações sobre os escopos e permissões específicos, consulte a documentação da fonte de dados de terceiros.
Configure o controle de acesso para seu repositório de dados. Para mais informações, consulte Identidade e permissões
Decida se os dados devem ser federados ou ingeridos (indexados).
Se os dados forem ingeridos, verifique se os recursos não estão restritos para a credencial de usuário que você usa para ingerir dados na fonte.
Decida a frequência de sincronização dos dados.
Se você estiver usando chaves de criptografia gerenciadas pelo cliente (CMEK), crie chaves multirregionais e de região única. Para mais informações, consulte Registrar chaves de região única para armazenamentos de dados de terceiros.
Se você tiver informações de identificação pessoal (PII) e quiser usar o preenchimento automático para sugestões de consultas, consulte proteção contra vazamentos de PII.
Origens de dados de terceiros compatíveis
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|