December 2022 Release
HITL Configuration Stepper
The 'Configuration' tab under 'Human-In-The-Loop' is now formatted as an
ordered pair of steps to allow for an easier and more structured setup experience.
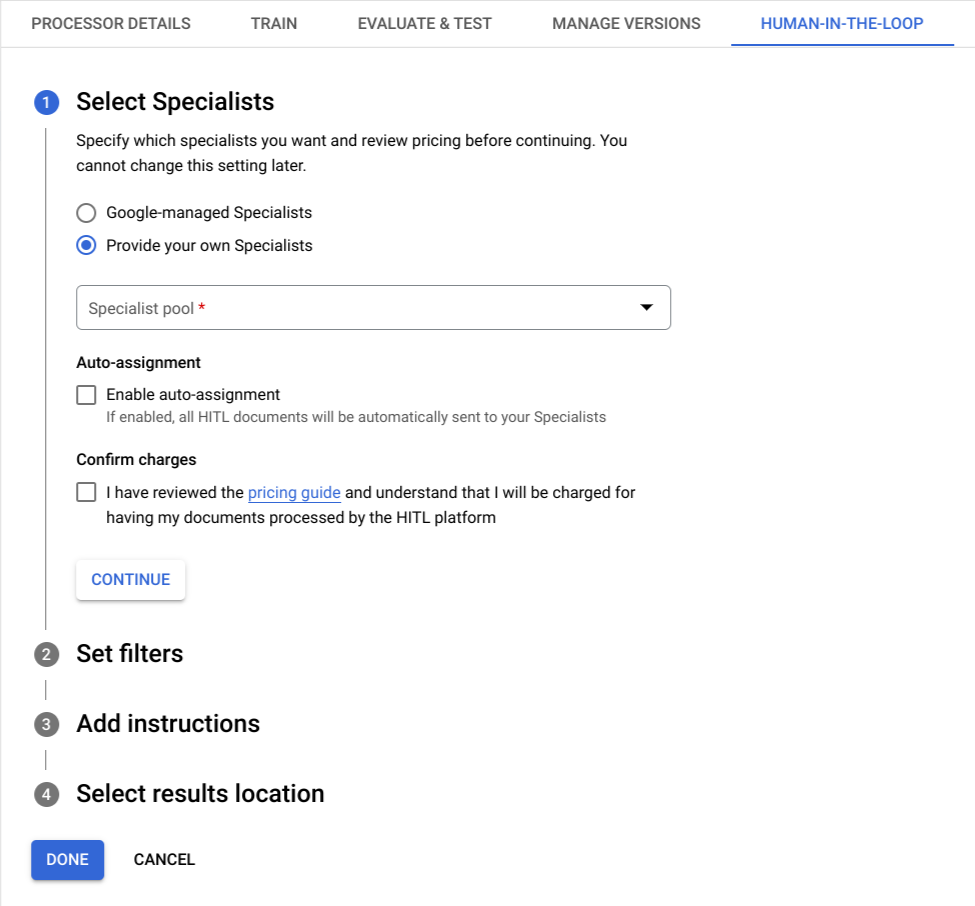 The user can now view separate steps to configure settings related to the specialist pool and filters to trigger HITL, and select instructions and results location for specialists.
The user can now view separate steps to configure settings related to the specialist pool and filters to trigger HITL, and select instructions and results location for specialists.
October 2022 Release
HITL Requester Analytics Dashboard
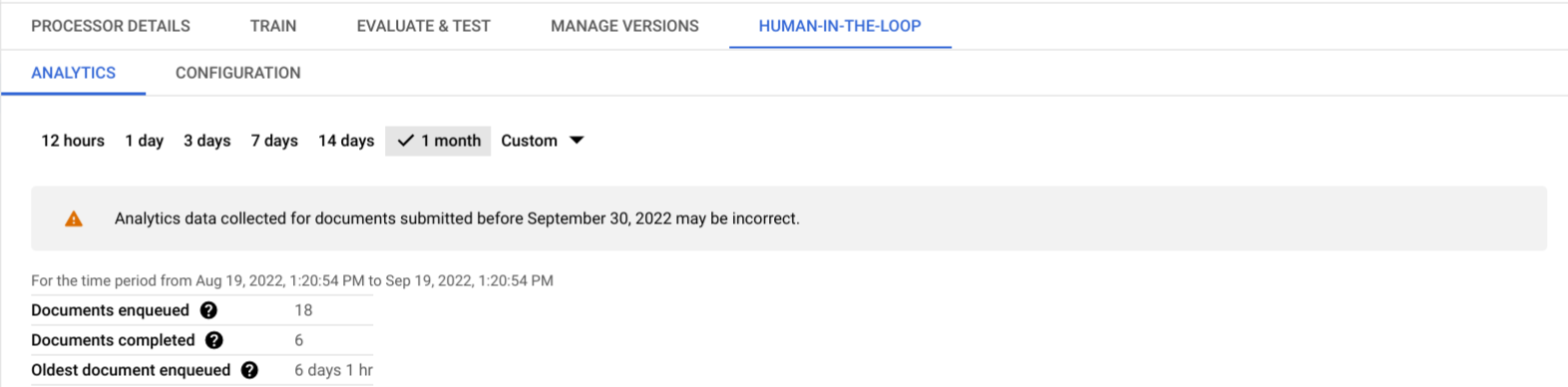
Human in the Loop now has a dedicated tab, called Analytics, that provides the user with metrics and charts to analyze the status of HITL tasks per processor and make changes as needed.
Currently, there are three different metrics that the user can view. The data can be aggregated by a time range selector that provides the user with the following options:

For each selected time range, the user can view the following:
- Aggregated Statistics: A snapshot view of the total number of documents
that were successfully uploaded to the queue, the total number of
documents completed (which means submitted and rejected) by specialists and the time
since the oldest document was added in the queue for the selected time
range.
- Human in the Loop activity chart: A chart showing the time-series data
for when documents were added to the queue (
enqueuedDocumentCount) and when the documents were completed by specialists (completedDocumentCount).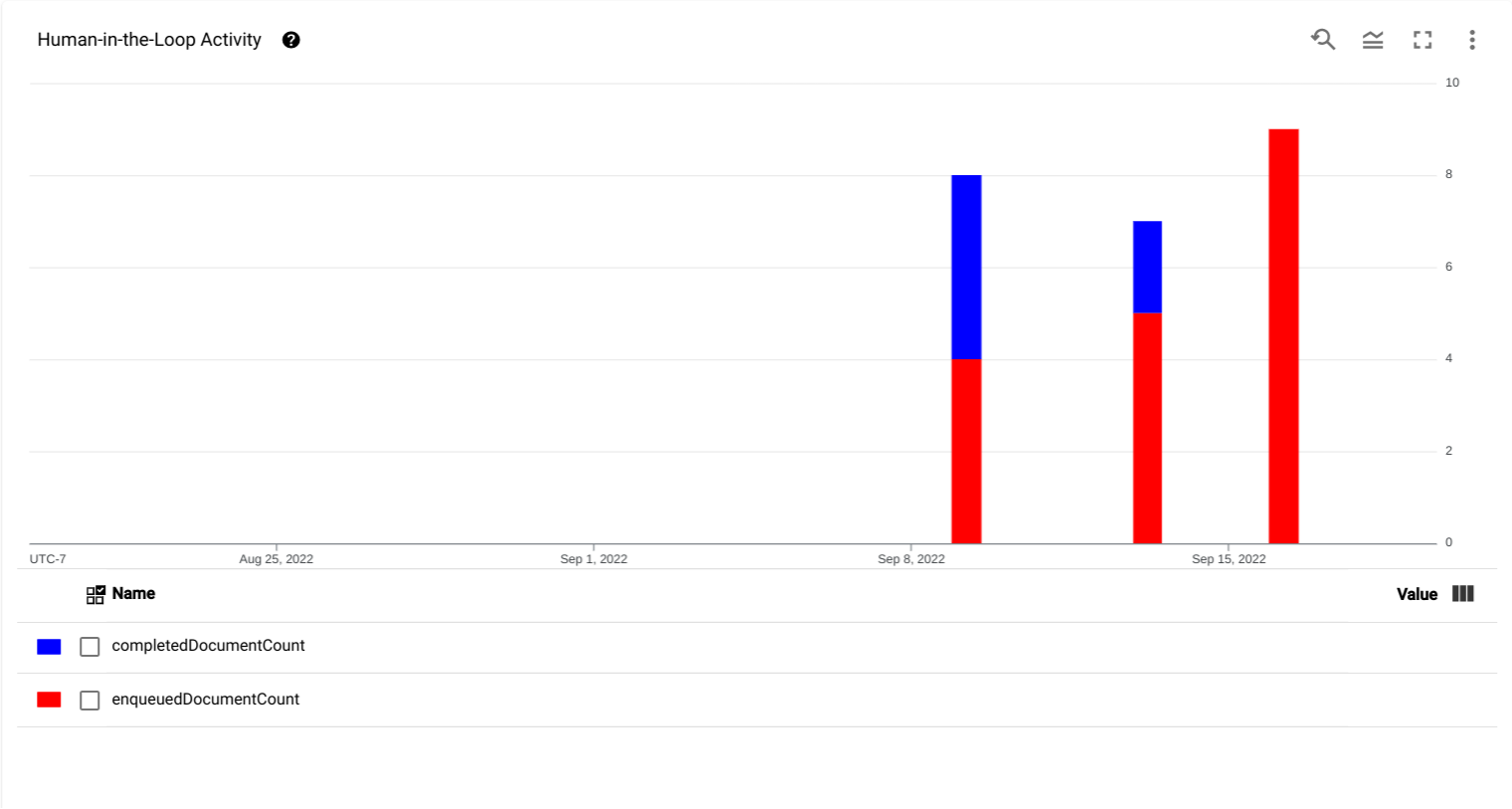
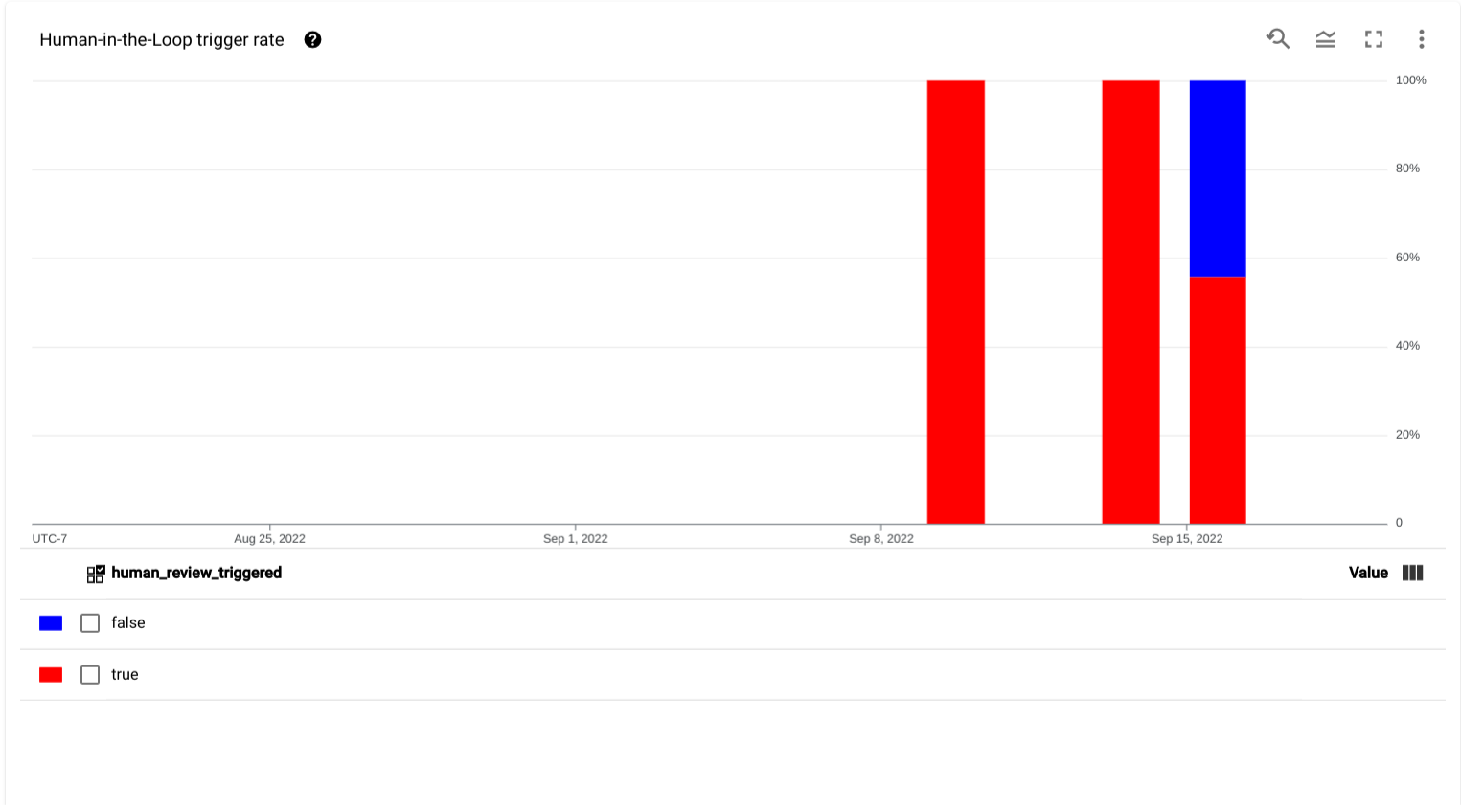
- Human in the Loop trigger rate: A chart showing the time-series data for
the percentage of uploaded documents that triggered Human-in-the-Loop
review within the selected time period.
- Aggregated Statistics: A snapshot view of the total number of documents
that were successfully uploaded to the queue, the total number of
documents completed (which means submitted and rejected) by specialists and the time
since the oldest document was added in the queue for the selected time
range.
September 2022 Release
Note: Customers using Document AI Workbench, Purchase Order (PO), Invoice and Expense processors have access to a new schema that enables customers to label checkboxes (if defined in the schema) and accurately represent nested entities i.e. parent child relationship on the HITL annotation and review UI. As more processors adapt the new schema, these release notes will be updated to reflect as such
Nested Entity
- Annotation UI now supports labeling for nested entities. The left panel is refreshed with a new look for nested rows to represent nested entities. The value of "parent" is the concatenation of all its "children".
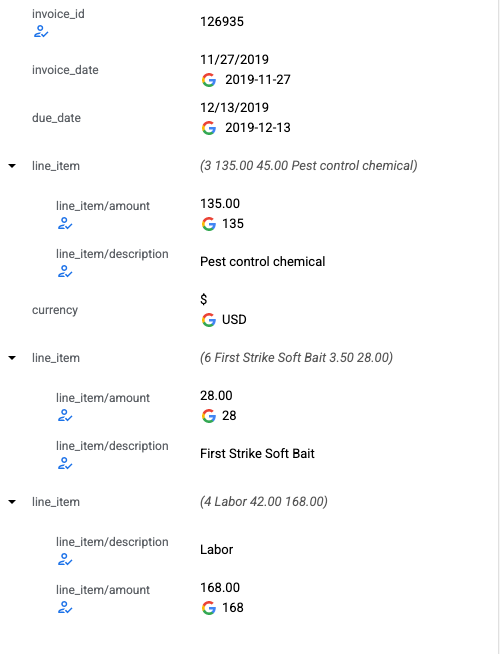
- Left panel entity selection displays parent and child labels.
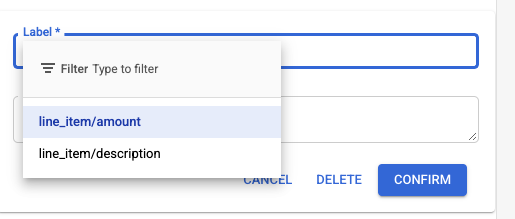
- The in document entity label menu also gets refreshed to support nested entity labeling.
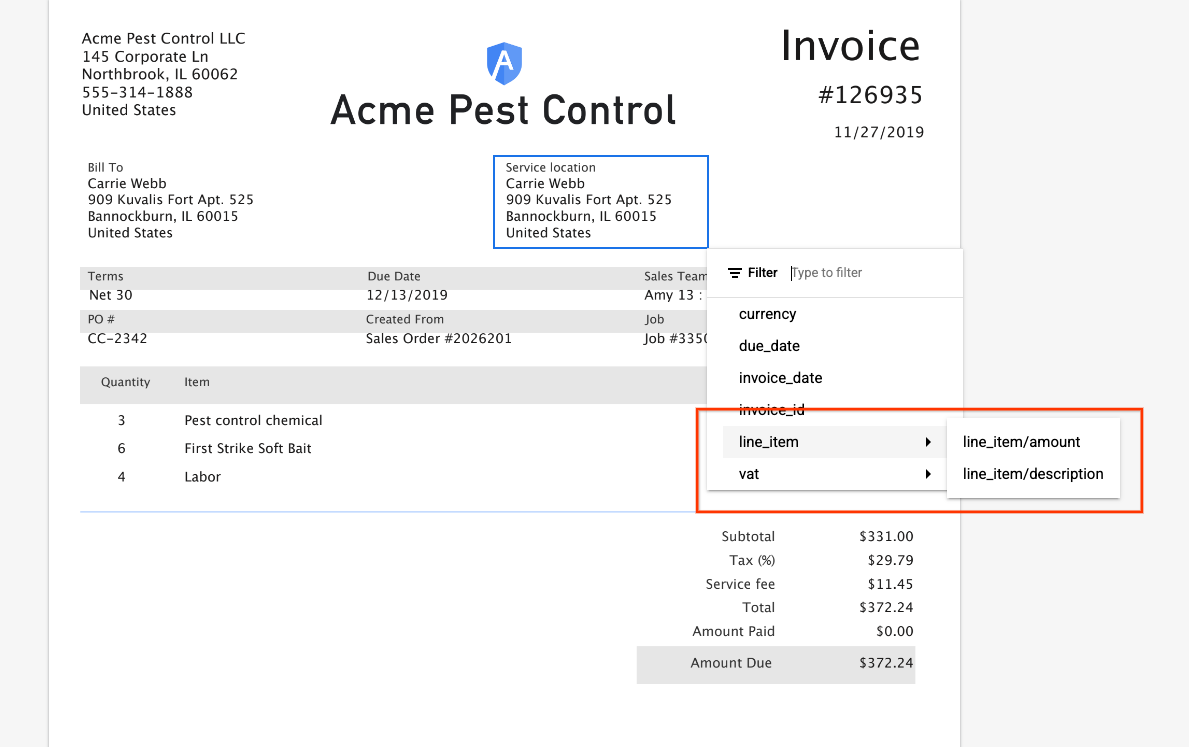
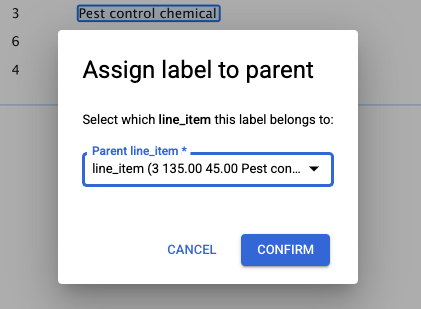
- Clicking on a nested label popups a dialog box to assign the correct parent entity for the nested child entity.
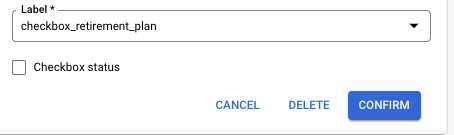
Checkbox
- Annotation UI supports labeling checkboxes. On the left panel, the checkbox can be edited in the row.

- Checkbox editing is also available on entity edit dialog box.
August 2022 Release
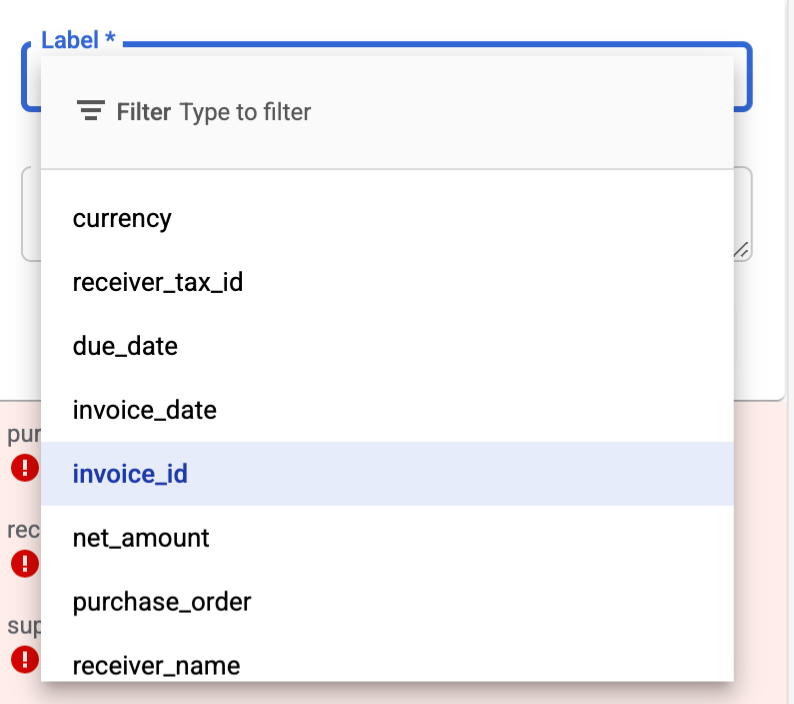
Entity Label Select
- Entity label input is replaced with a dropdown list. This dropdown list contains the available label options when adding a new entity. This change helps prevent labelers from making typos and creating unwanted entity labels.
ISO Date Format
- Normalized dates are displayed in ISO 8601 date format(yyyy-mm-dd).

July 2022 Release
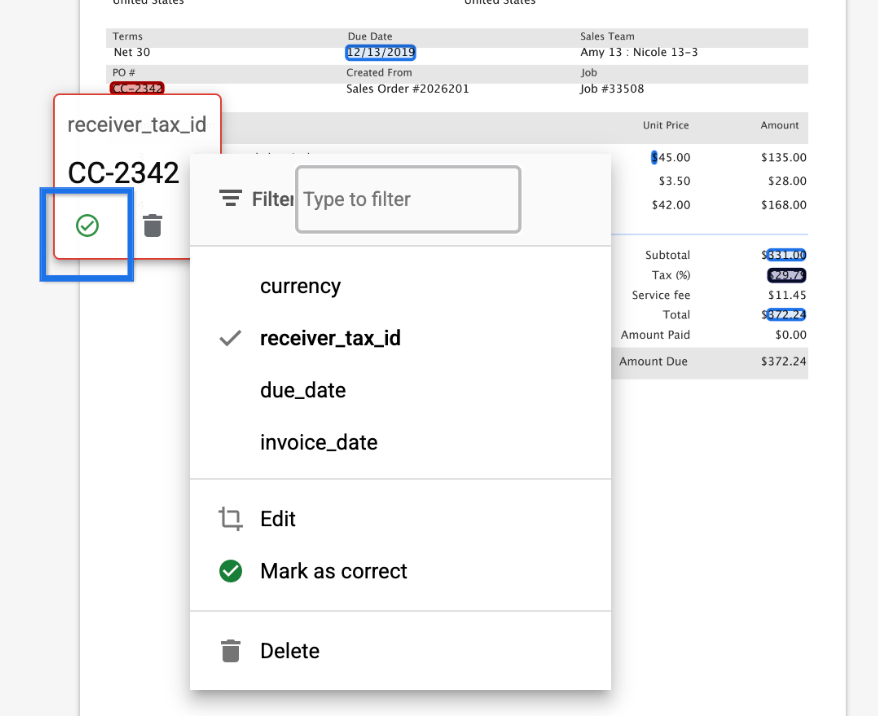
Quick Confirm button
- A Confirm button is available on entity tooltips to quickly review and confirm an entity/label value. The Edit button is removed, as users can click the entity tooltip directly to edit.
January 2022 Release
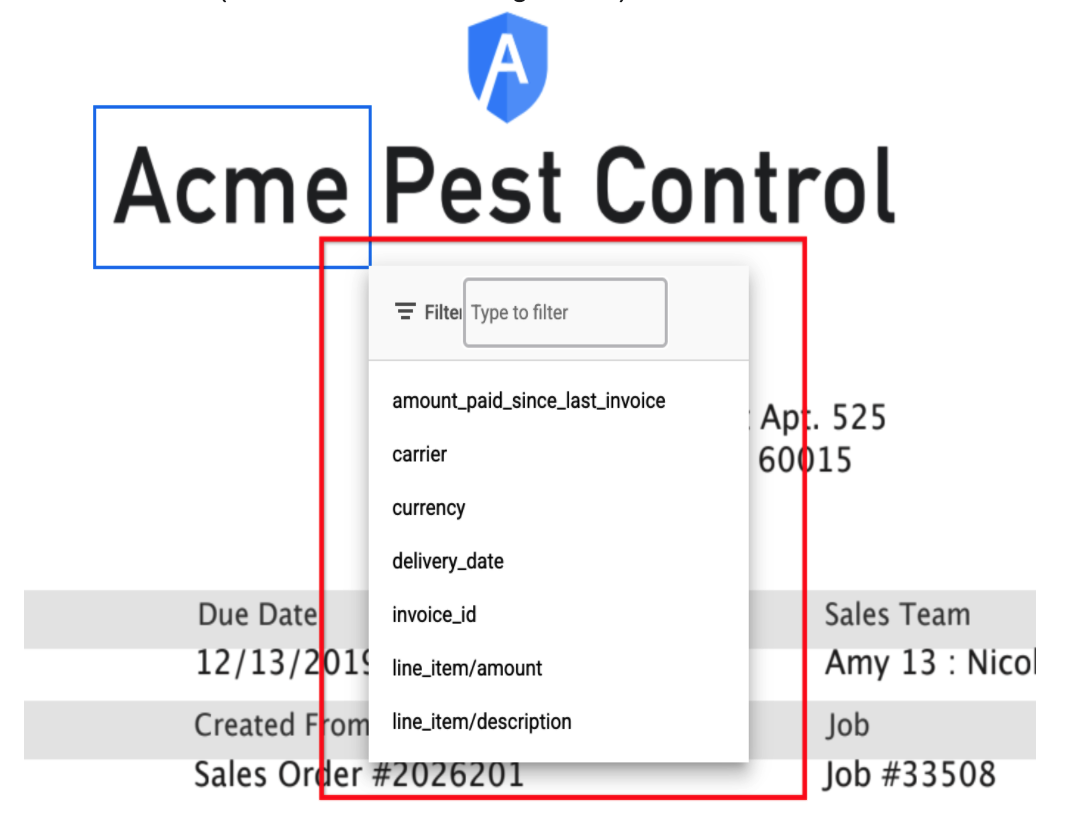
Entity Label options
- Entity label select options now are limited to the list of filtered fields(set in HITL Filter configuration).
Missing Fields
- We now show missing fields (i.e. fields marked "Required" in the HITL filter configuration but the processor hasn't predicted values for the fields) in a distinct red color, making it easy for the Reviewer to update the value of the field.

Random Complete Samples
- We now support complete review (i.e. all entities in the document, not just the filtered fields) of a random sample (e.g. 2% of daily volume) of documents. This is useful to monitor model drift and analytics on processor accuracy in each field - we collect these analytics, which are used to know when up-training is required. This also serves as a dataset with labeled ground truth for up-training models.
- Customers can opt in and set the random sample [1-10%] based on their volume. Targeting 100-500 samples/week would be useful. So, if customer processes 10,000 documents/week, this may be set to 500/10000 = 5%
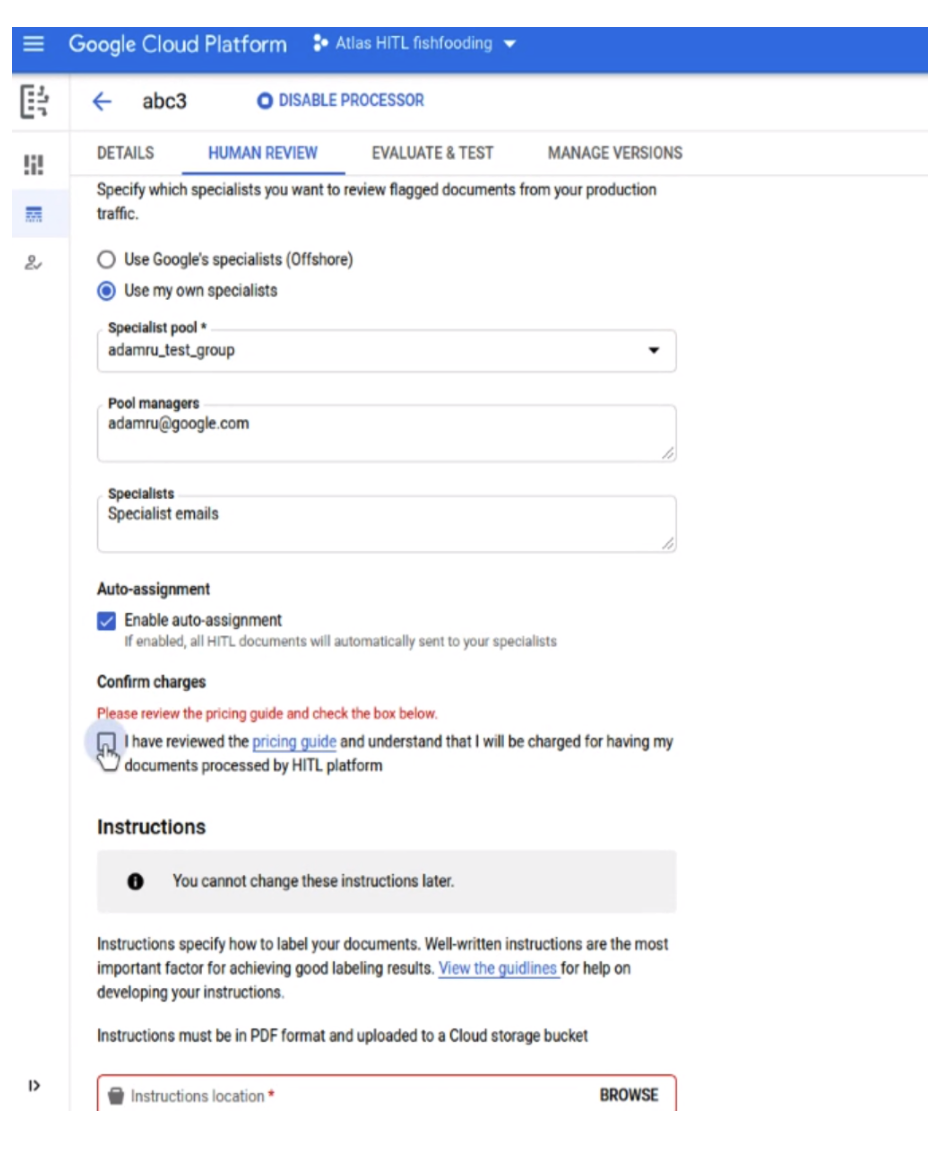
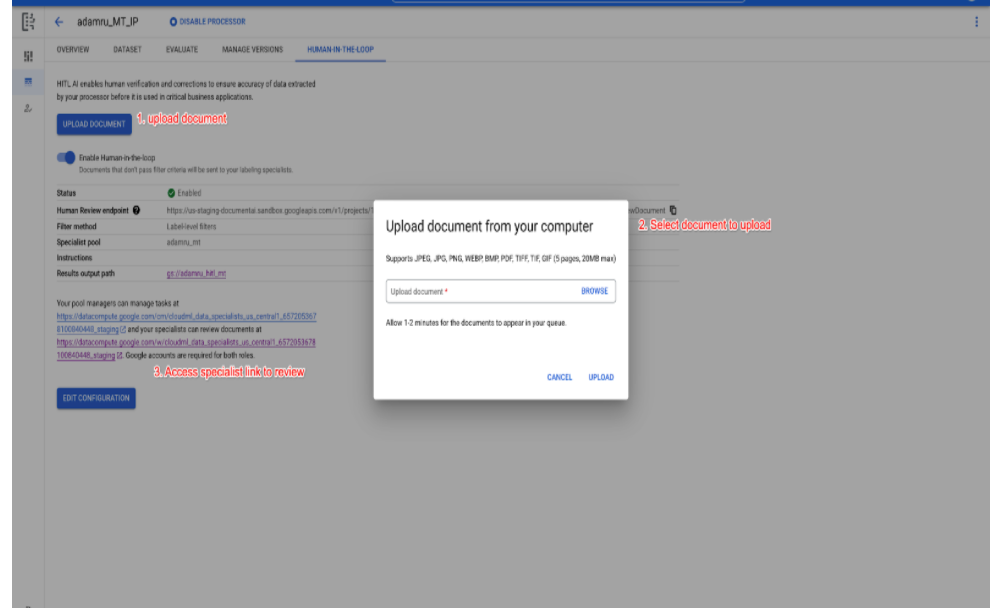
Simplified HITL Configuration for first-time users
- We have simplified the BYOL HITL configuration for first time HITL customers, so they can quickly configure a task, assign Specialists and launch it from a single screen, so they can quickly try it before scaling up production volume or outsourcing the operation.
- As shown in the screenshot below, the user is made the default Manager of the pool, and they can add additional Specialists, all of who are auto-assigned to the task in the same screen.
- Previously, the assigned Manager would be emailed a link to the Manager Console where they add Specialists and assign the task to these specialists.
- Upon submitting the task, they (and other specialists assigned) can go to the HITL app to review documents.
- The user can also upload a test document (one-at-a-time) to the task queue.
Remove trailing line breaker
- Trailing line breakers('\n') are removed in entity.mentionText.
December 2021 Release
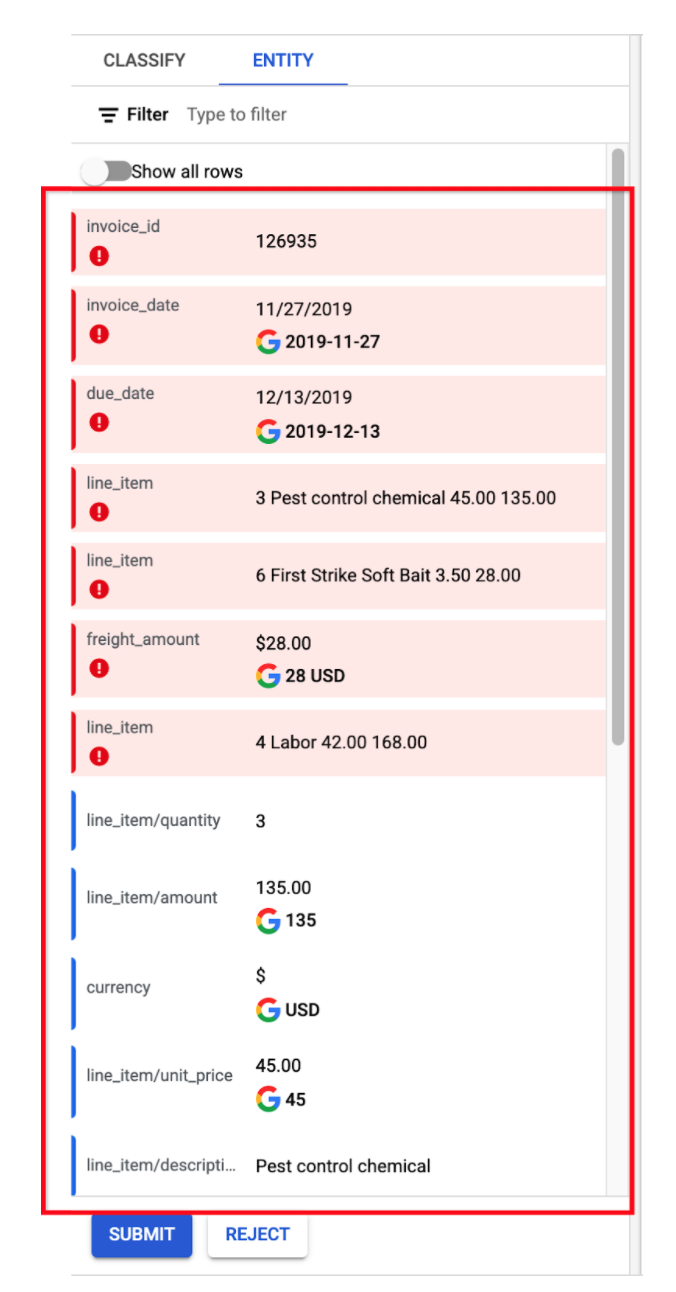
Sort low-confidence score entities to the top
- The low-confidence score entities (i.e. entities below the confidence threshold) are now sorted to the top of the page, enabling the Specialist to focus on these entities. This drives further efficiencies in labeling.
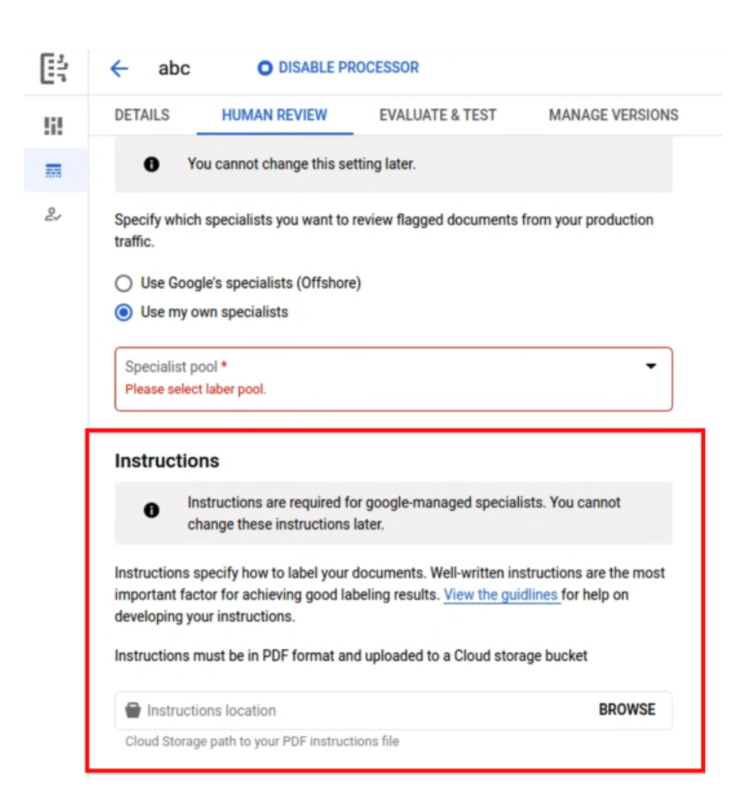
Instructions Optional for BYOL Tasks
- The PDF instructions to be uploaded to configure an HITL task is now optional. This simplifies testing and quick internal launches where the Specialists don't need an instruction guide.
Fit-to-width and fit-to-page-height option
- Button to fit the page to width or to height. This is useful when Specialists have variable sized documents (e.g. Receipts) in a task.

Task name displayed in Specialist UI
- Task name is now shown in the Specialist UI to provide them additional context on the task and document type, which is very useful when specialist is assigned to multiple tasks.
- Note that this is displayed in new processors spun up after this release.

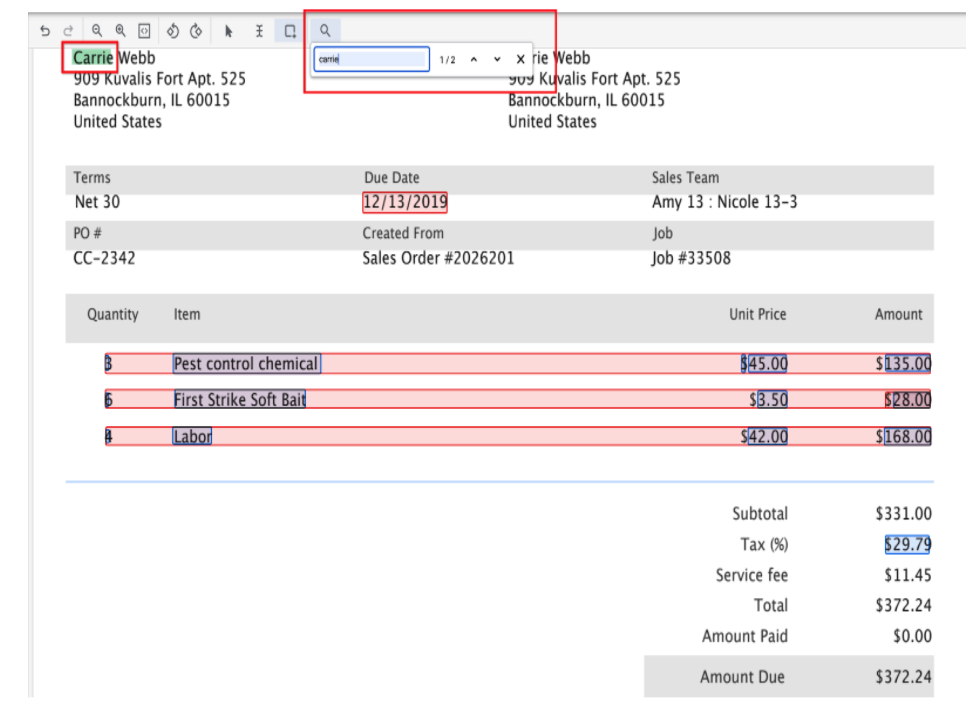
Search box for Specialists
- Specialists can search for entities/text in documents. This is helpful especially for large multi-page documents and makes the Specialists more productive.
September 2021 Release
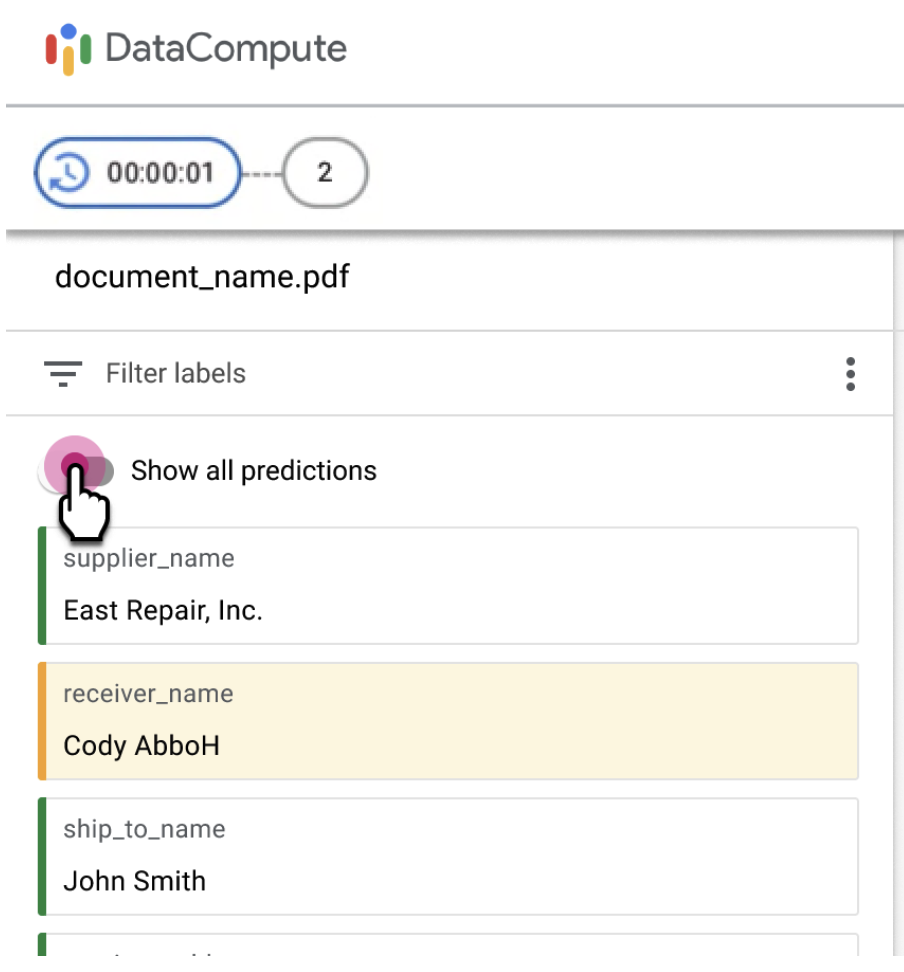
Toggle to show all fields
- Labelers might need to review and update fields that aren't in the filtered
set of entities for specific documents in the queue.
You can toggle the Show all predictions option
to allow labelers to review non-filtered fields.
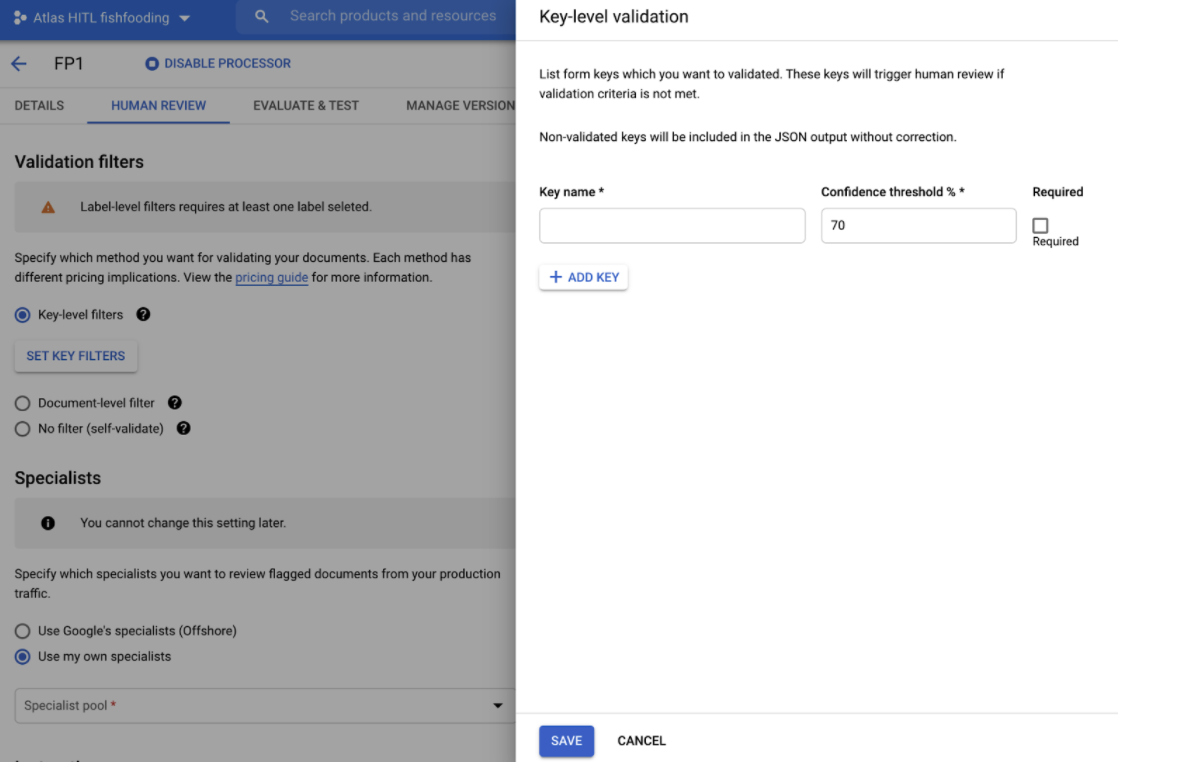
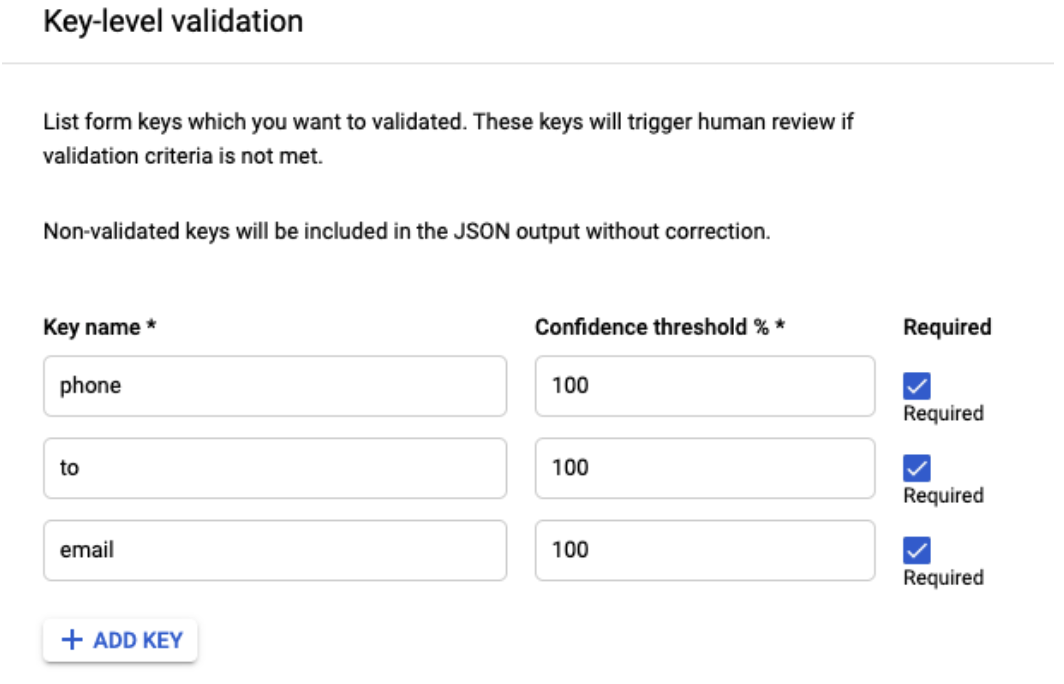
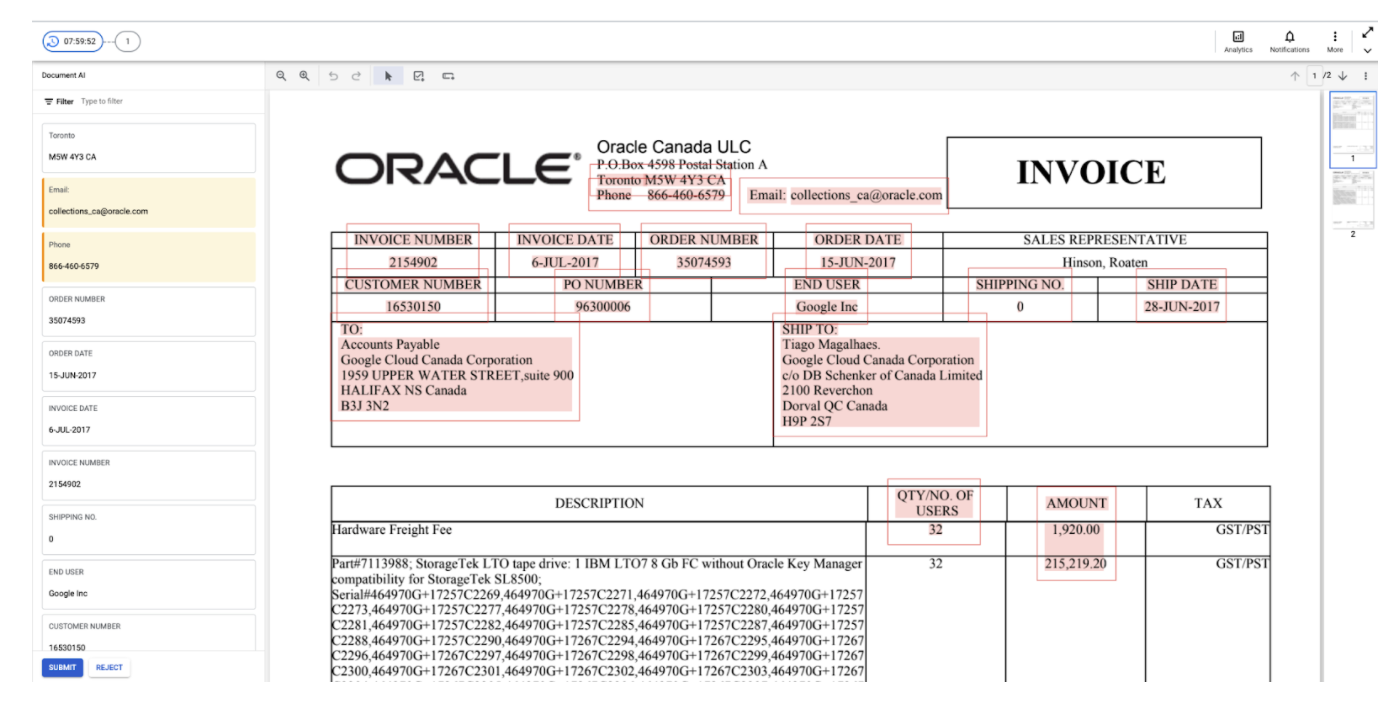
HITL for Form Parser
- HITL now supports Form Parser, so users can review and correct the key-value pairs extracted by Form Parser. The customer can enable HITL on Form Parser processor in DocAI platform and configure the key names (as shown in screenshot below) they would like to filter for HITL review. The HITL output is dropped as JSON files in the customer-specified Google Cloud Storage bucket after HITL review is completed.
- They can specify comma-separated alternate key-names, for example, "customer, customer name, client, account #, account number" so that the HITL filter catches documents with all key-name variations and sends for HITL review.
August 2021 Release
Audit/QA Pipeline
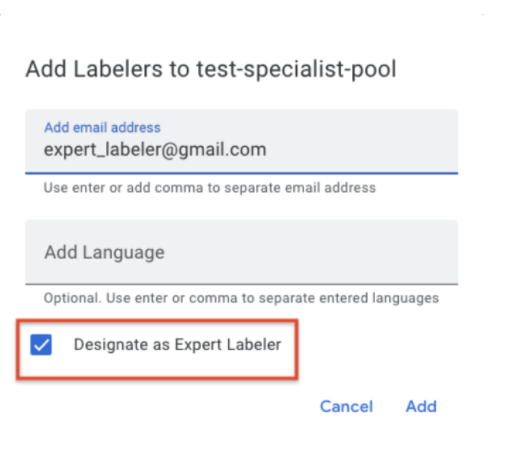
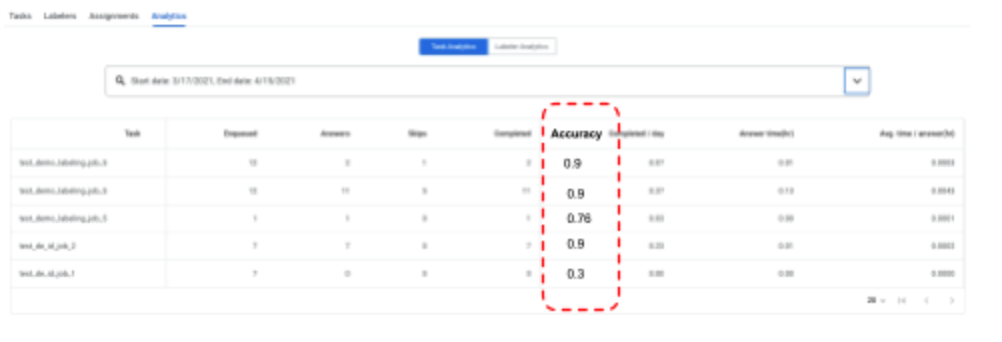
- HITL now enables a 2nd stage QA or audit stage, and reports the accuracy of the Review tasks (and the Labelers). A QA team or auditor can be assigned as an "expert Labeler" to a task. The QA team/Auditor receives X percent (say 1%-100%, this is configurable by the customer) of the reviewed documents. The Auditor can correct the Reviewer's output. The system tracks the corrections and assigns an Accuracy score (e.g. 90%) to each audited document. The aggregate accuracy score of a task or labeler is reported in the Task and Labeler Analytics dashboards respectively.
- Here are detailed instructions on configuring an Audit pipeline.
- Designating an Auditor
- Reporting Accuracy
Lending AI Parsers (Aug 15)
- HITL is now supported on some Lending AI parsers including 1040, 1040 Schedule E, 1040 schedule C, 1099 DIV, 1099 G, 1099 INT, 1099 MISC, Paystubs, Banks Statements, W2, W9, 1120, 1120S, 1065, SSA-1099, 1099 NEC, 1099-R.
July 2021 Release
Standard vs Urgent Queues (July 2)
- We now support 2 priority queues (vs 1 queue) for each processor, based on the urgency of each document.
- Submission - After prediction, the extracted documents can be evaluated for urgency and submitted to 2 queues (Standard vs Urgent/Fast-track) based on urgency of the document. For example, invoices with urgent due-dates can be submitted to the Fast-track queue. The logic that evaluates the urgency is currently outside HITL and can be a custom function.
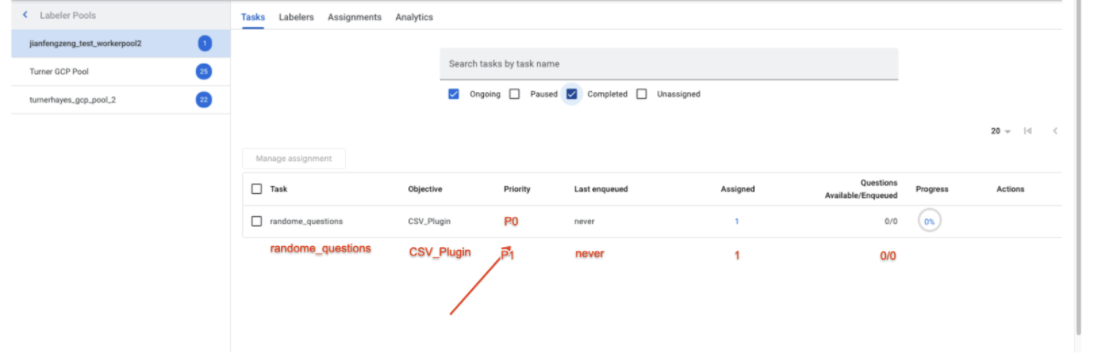
- Task Assignment - The labeling manager sees 2 different queues with different priorities, as shown in the screenshot below, and may assign the same group of labelers to both queues.
- Task Prioritization - Labelers assigned to both tasks will always process any pending documents in the Fast-track queue first before processing the Standard queue (i.e. the queue prioritization is automatically handled by the system)
- API call - Set the priority field in the ReviewDocument
- UI screenshot (of tasks in Labeling Manager UI) -
June 2021 Release
Validation Filters for HITL End-point (June 24th)
- The validation filters (configured in the processor) that filter the fields by confidence score to determine documents to be queued for human review, are now also applied to documents submitted to the HITL end-point.
- When calling the ReviewDocument API, set the enable_schema_validation field to true.
- Note that if this is set, and validation decides the document doesn't need to trigger human review, a CANCELLED error is returned.
Cancel API
Customer can cancel a doc enqueued for HITL processing by invoking the Cancel API for a given operation ID. An operation ID is returned for each document submitted to HITL.
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
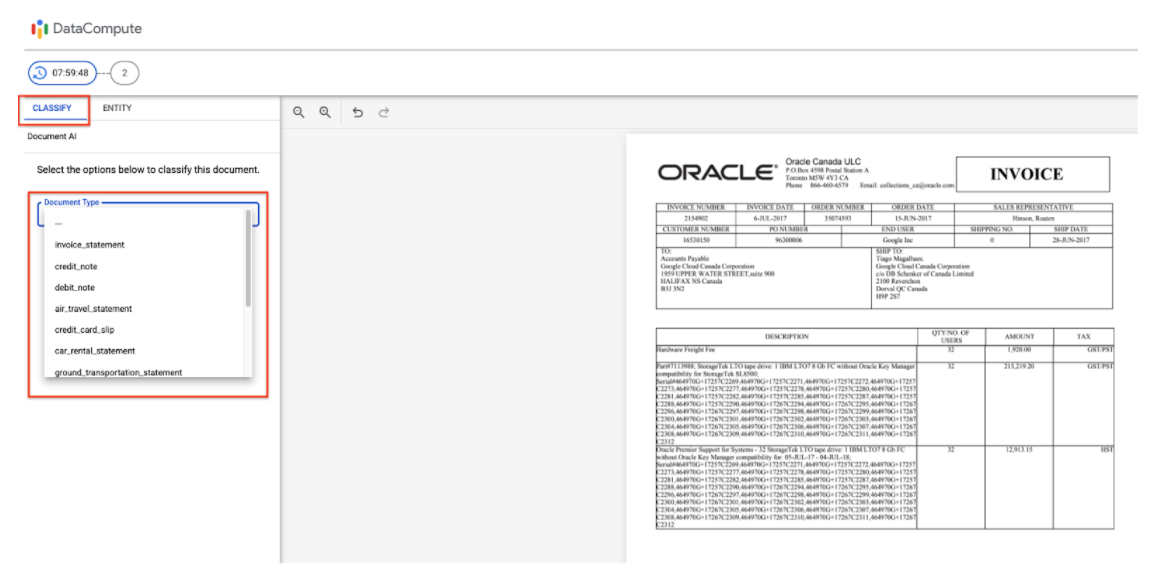
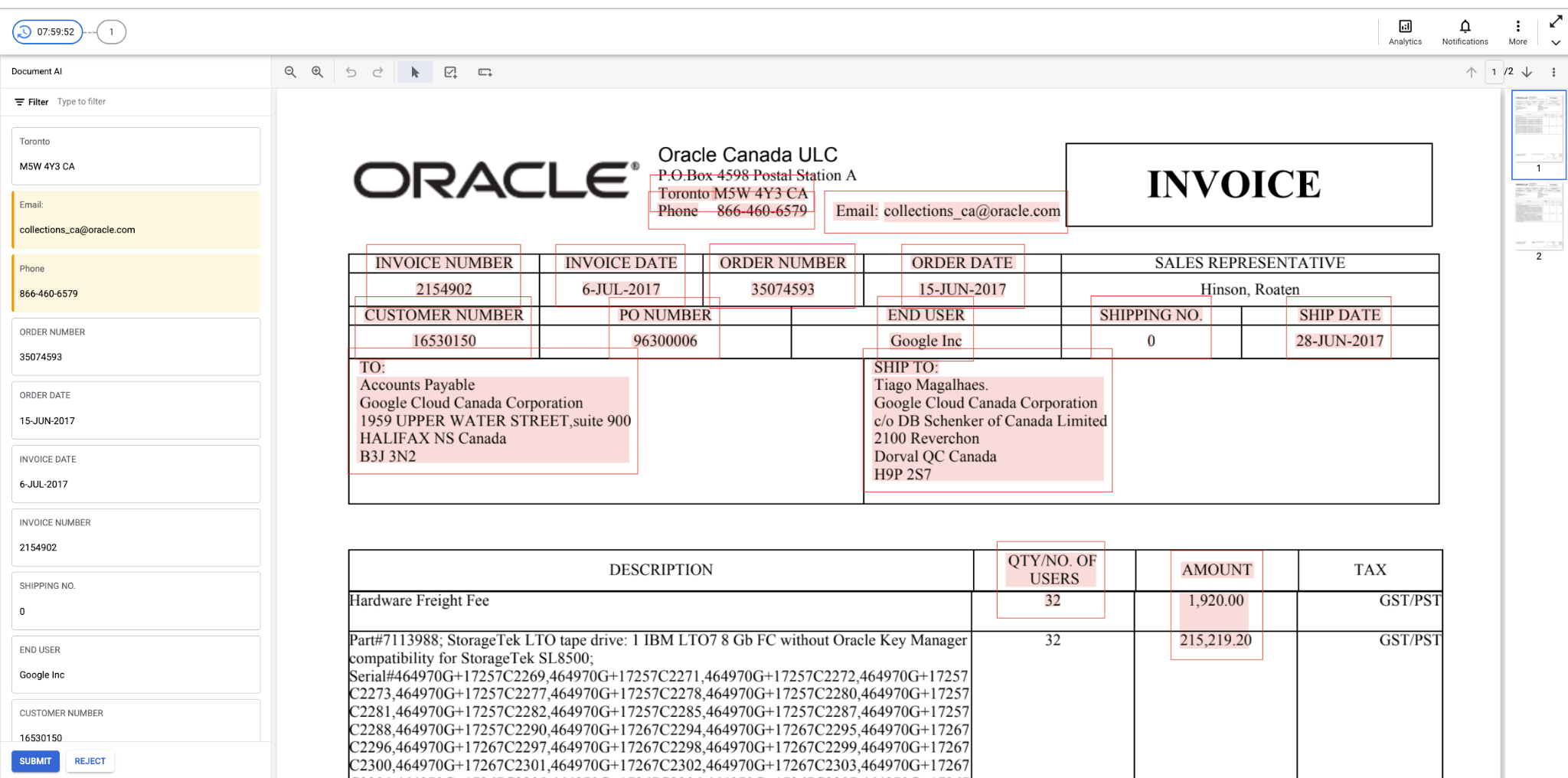
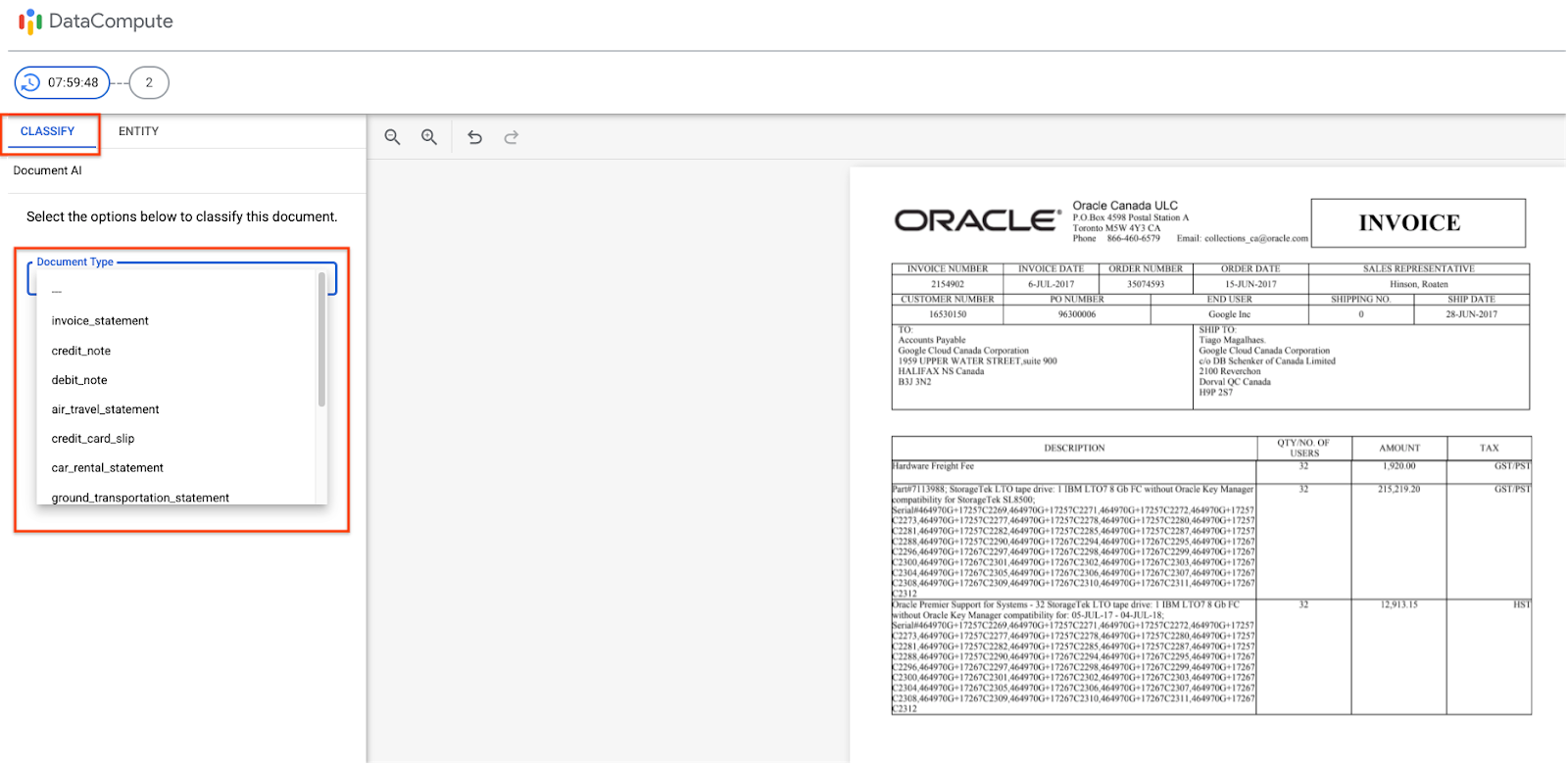
Invoice Type (Classification Review)
- The Labeler Workbench supports reviewing Invoice Type classification.
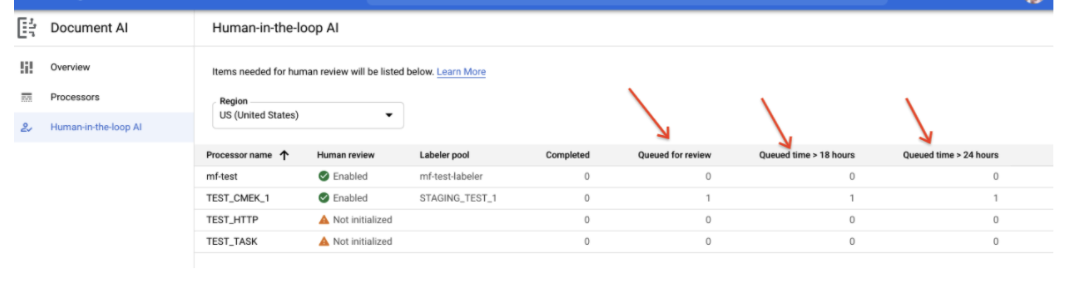
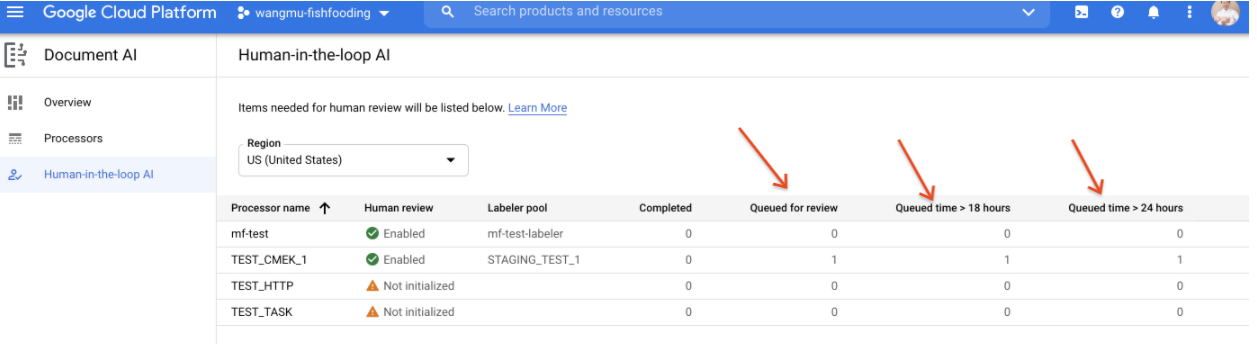
Time-in-queue (HITL Latency SLO) Report
- A report shows how many documents are enqueued for >18 hours and >24 hours. This is useful for users that need to manage an SLO expectation on HITL latency.
Known URL for Labeler Workbench
- Labelers assigned to a single pool can now access the workbench at a known URL, and do not need to look for cryptic URLs sent in email notifications (by the system or by the Labeling Manager). This URL does not work for labelers assigned to multiple pools.
Sticky Zoom Setting
- The plug-in now remembers the labeler's Zoom setting (full-width vs full-page) for the next document reviews in the queue, so that they do not need to Zoom in for every document.
HITL for Form Parser
- HITL now supports Form Parser. Users can review and correct the key-value pairs extracted by Form Parser, and enable HITL on Form Parser processor in DocAI platform and configure the key names (as shown in screenshot below) they would like to filter for HITL review. The HITL output is saved to JSON files in the customer-specified Google Cloud Storage bucket after HITL review is completed.
- UI Screenshots to configure HITL on Form Parsers
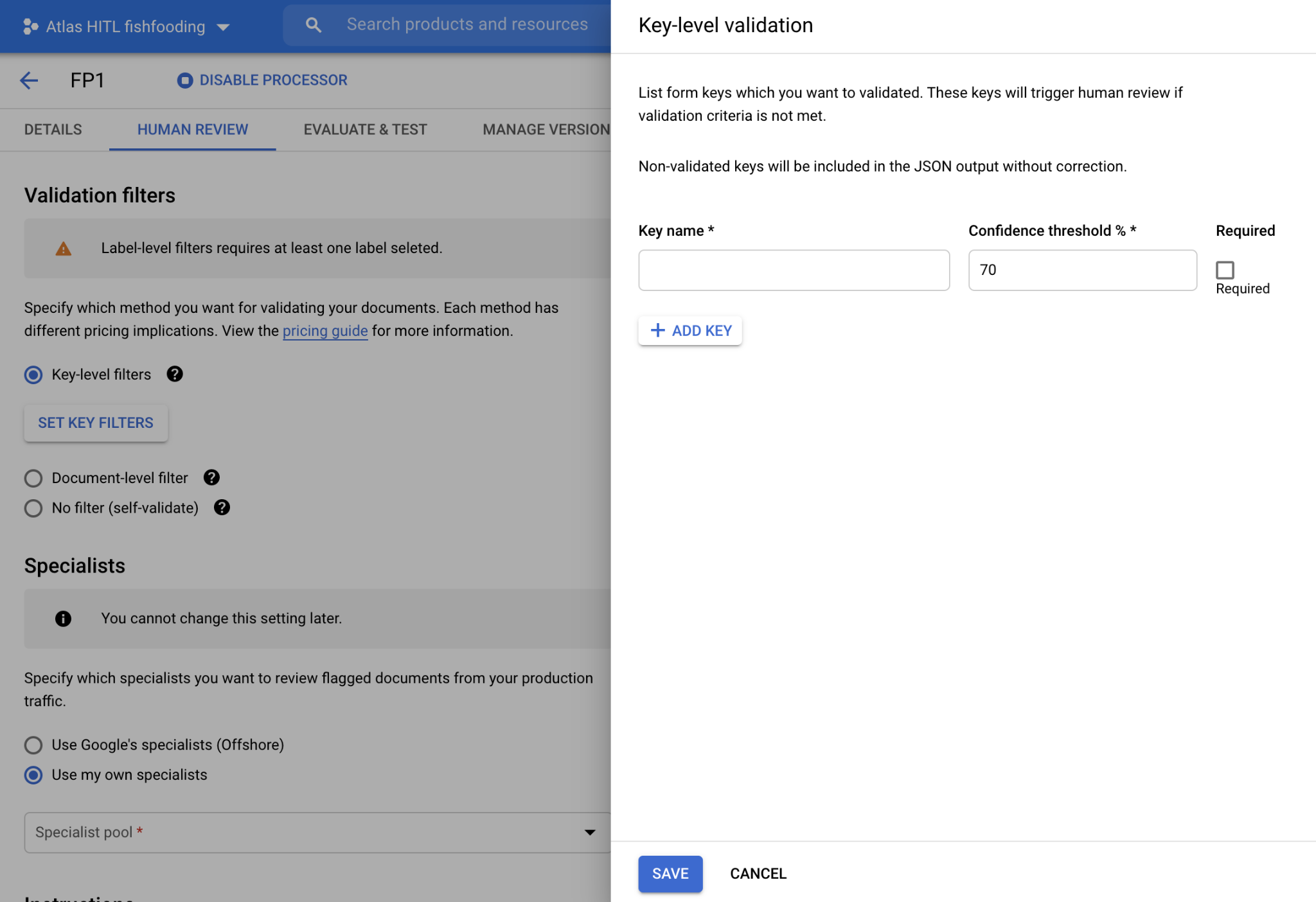
- UI to configure key-level validation

- Labeler UI
Audit/QA Pipeline
- HITL now enables a 2nd stage QA or audit stage, and reports the accuracy of the Review tasks (and the Labelers). A QA team or auditor can be assigned as an "expert Labeler" to a task. The QA team/Auditor will receive X percent (say 1%-100%, this is configurable by the customer) of the reviewed documents. The Auditor can correct the Reviewer's output. The system tracks the corrections and assigns an Accuracy score (e.g. 90%) to each audited document. The aggregate accuracy score of a task or labeler is reported in the Task and Labeler Analytics dashboards respectively. Here are detailed instructions on configuring an Audit pipeline.
Designating an Auditor
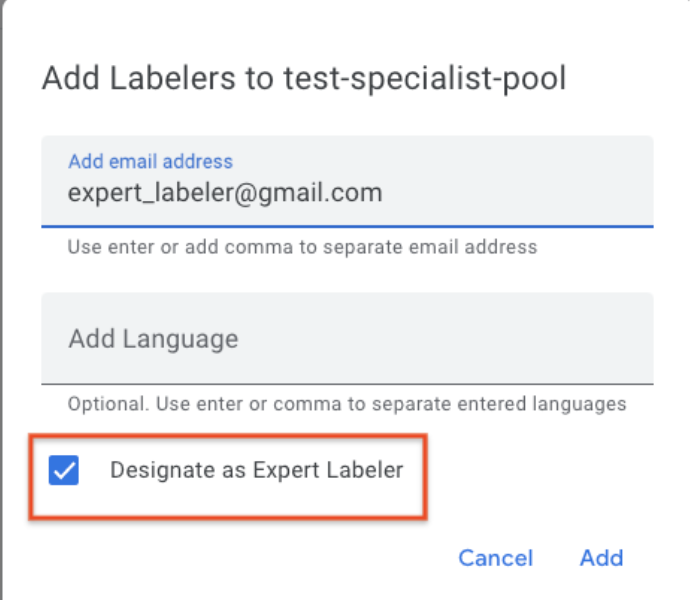
Reporting accuracy
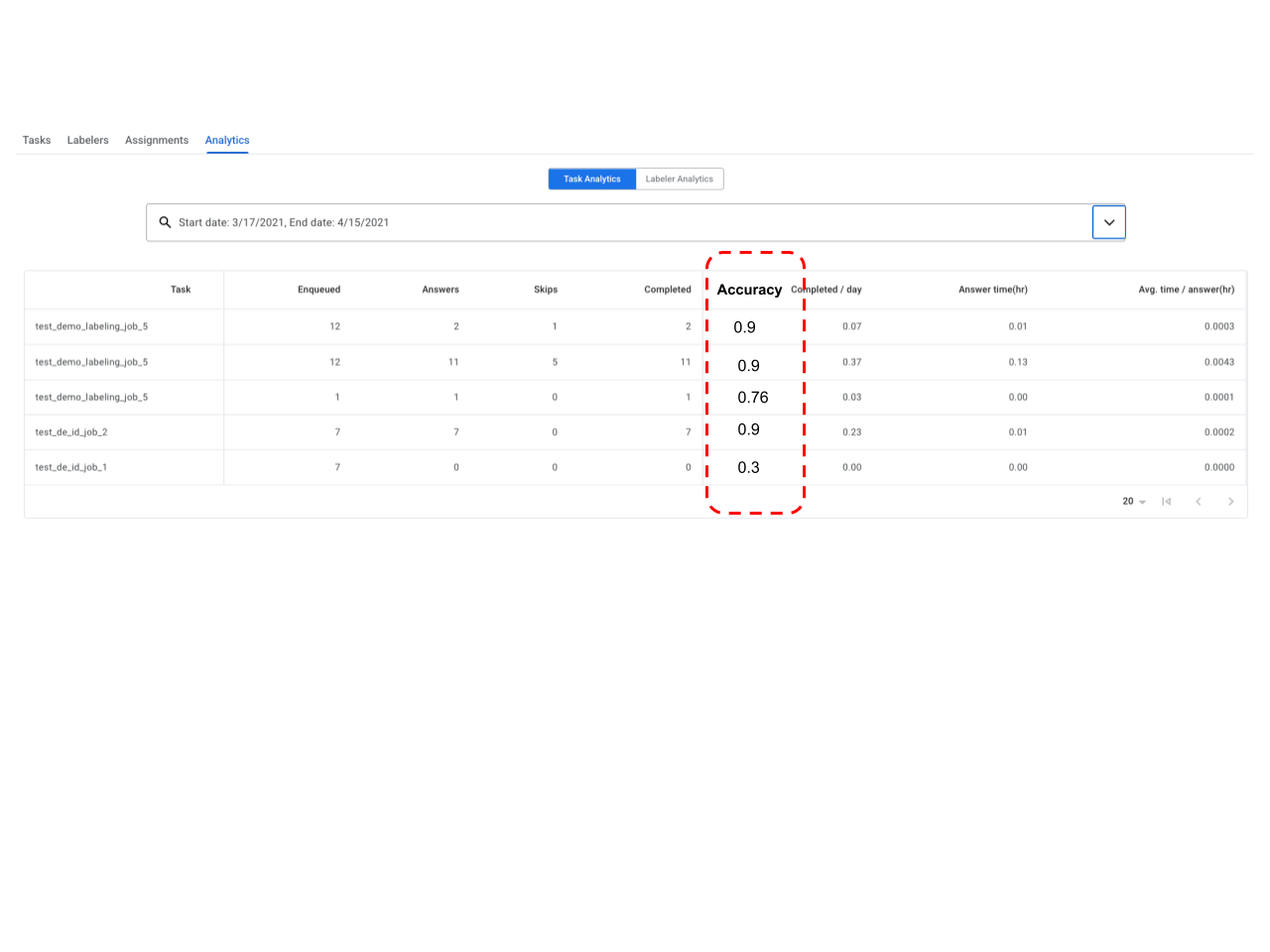
Lending AI Parsers (July 31)
- HITL is now supported on some Lending AI parsers including 1040, 1040 Schedule E, 1040 schedule C, 1099 DIV, 1099 G, 1099 INT, 1099 MISC, Paystubs, Banks Statements, W2, W9, 1120, 1120S, 1065, SSA-1099, 1099 NEC, 1099-R
Standard vs Fast Track Queues (July 2)
- We now support 2 priority queues (vs 1 queue) for each processor, based on the urgency of each document.
- Submission - After prediction, the extracted documents can be evaluated for urgency and submitted to 2 queues (Standard vs Urgent/Fast-track) based on urgency of the document. For example, invoices with urgent due-dates can be submitted to the Fast-track queue. The logic that evaluates the urgency can be entered through a custom function.
- Task Assignment - The labeling manager sees 2 different queues with different priorities, as shown in the screenshot below, and may assign the same group of labelers to both queues.
- Task Prioritization - Labelers assigned to both tasks will always process any pending documents in the Fast-track queue first before processing the Standard queue (i.e. the queue prioritization is automatically handled by the system)
- API call - Set the priority field in the ReviewDocument
- UI screenshot (of tasks in Labeling Manager UI)

Validation Filters for HITL End-point (June 24th)
- The validation filters (configured in the processor) that filter the fields by confidence score to determine documents to be queued for human review, are now also applied to documents submitted to the HITL end-point.
- When calling the
ReviewDocumentAPI, set the enable_schema_validation field to true. Note that if this is set, and validation decides the document doesn't need to trigger human review, an CANCELLED error will be returned.
Cancel API
You can cancel a doc enqueued for HITL processing by invoking the Cancel API for a given operation ID. [An operation ID is returned for each document submitted to HITL]
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
Invoice Type (Classification Review)
- The Labeler Workbench supports reviewing Invoice Type classification.
Time-in-queue (HITL Latency SLO) Report
- A report shows how many documents are enqueued for >18 hours and >24 hours. This is useful for users that need to manage an SLO expectation on HITL latency.
Known URL for Labeler Workbench
- Labelers that are assigned to a single pool can now access the workbench at a known URL https://datacompute.corp.google.com/w/. This is useful in case you lose the email with the URL that was sent by the system or Labeling Manager. This URL doesn't work for labelers assigned to multiple pools.
Sticky Zoom Setting
- The plug-in now remembers a labeler's Zoom setting (full-width vs full-page) for the next document reviews in the queue, so that they don't need to Zoom in for every document.