Geschätzte Dauer: 5 Tage
Eigentümer der betriebsbereiten Komponente: OLT
Kompetenzprofil: Deployment Engineer
Ab Version 1.14 wird der Abschluss des Deployments anhand der Dashboards des Observability and Monitoring Stack überprüft.
ServiceNow-Dashboard für Vorfälle überprüfen
- Prüfen Sie, ob es neue oder ungelöste Vorfälle im Zusammenhang mit dem Deployment gibt.
Grafana AlertManager-Dashboard prüfen
- Suchen Sie nach aktiven Benachrichtigungen.
Neue Vorfälle und Benachrichtigungen priorisieren Gehen Sie bei jedem neuen ServiceNow-Vorfall oder jeder ausgelösten Grafana-Benachrichtigung so vor:
- Vergleichen Sie das Problem mit dem Dokument zu bekannten Problemen.
- Wenn das Problem nicht als bekanntes Problem aufgeführt ist, eskaliere es an das Engineering-Team, damit es die weitere Vorgehensweise festlegen kann. Möglicherweise müssen Sie Folgendes tun, um das Problem zu beheben:
- Beheben Sie das zugrunde liegende Problem.
- Dokumentieren Sie die Benachrichtigung als neues bekanntes Problem, z. B. wenn es sich um einen Fehlalarm handelt.
37.1. Systemzustand prüfen
Nach der Bereitstellung ist das Fehlen neuer, unerwarteter Vorfälle und Benachrichtigungen sowohl im ServiceNow-Dashboard (SNOW) als auch im Grafana AlertManager-Dashboard der primäre Indikator für den Systemstatus.
37.1.1. ServiceNow-Vorfälle-Dashboard
Das ServiceNow-Dashboard bietet einen allgemeinen Überblick über wichtige Probleme, für die automatisch Tickets vom System erstellt wurden. Nach der Bereitstellung sollten auf diesem Dashboard keine neuen kritischen Vorfälle angezeigt werden.
Ihr Ziel ist es, zu bestätigen, dass keine neuen, nicht dokumentierten Vorfälle ausgelöst wurden. Alle Vorfälle, die angezeigt werden, müssen bereits im Abschnitt „Bekannte Probleme“ aufgeführt sein.
37.1.2. Grafana AlertManager-Dashboard
Das AlertManager-Dashboard bietet eine direktere Echtzeitansicht des Systemstatus, da es aktiv ausgelöste Benachrichtigungen anzeigt. Ein Problem wird hier oft angezeigt, bevor ein ServiceNow-Vorgang erstellt wird.
Bei einem funktionierenden System werden keine neuen Zündbenachrichtigungen angezeigt. Alle aktiven Benachrichtigungen müssen mit der Seite „Bekannte Probleme“ abgeglichen werden, um zu bestätigen, dass es sich um erwartetes Verhalten handelt.
37.1.3. Ergebnisse interpretieren
Wenn in beiden Dashboards keine neuen und nicht dokumentierten Probleme angezeigt werden, ist das ein starker Hinweis darauf, dass die Bereitstellung erfolgreich war und das System stabil ist.
Wenn Sie Vorfälle oder Benachrichtigungen entdecken, die nicht auf der Seite mit bekannten Problemen aufgeführt sind, führen Sie die Triage- und Eskalationsschritte aus, die in der zuvor erwähnten Checkliste beschrieben sind. Neue falsch positive Ergebnisse müssen dem Engineering-Team gemeldet werden, damit sie entsprechend behoben und dokumentiert werden können.
37.2. Beispiel für einen Triage-Workflow
Wenn eine neue Benachrichtigung untersucht werden muss, umfasst der allgemeine Triage-Prozess in Grafana AlertManager die folgenden Schritte:
Nach Priorität gruppieren: Gruppieren Sie zuerst die Benachrichtigungen, um sich auf die wichtigsten Probleme zu konzentrieren.
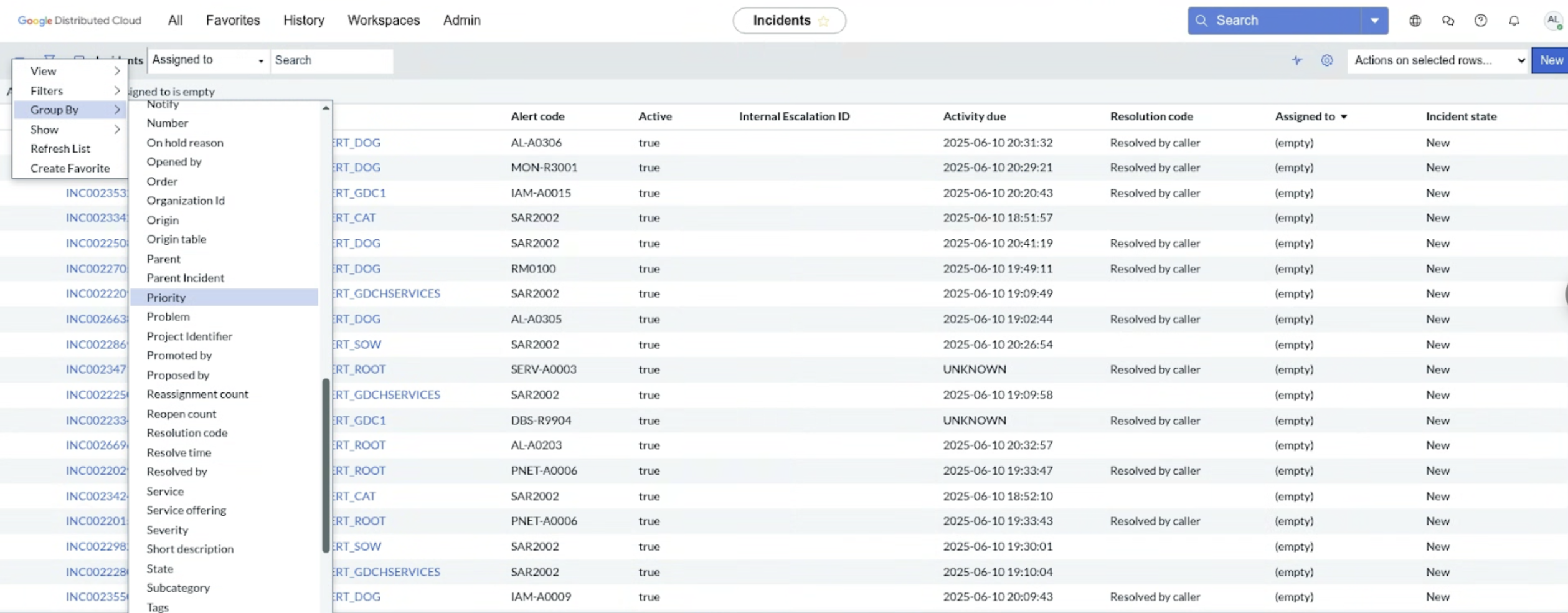
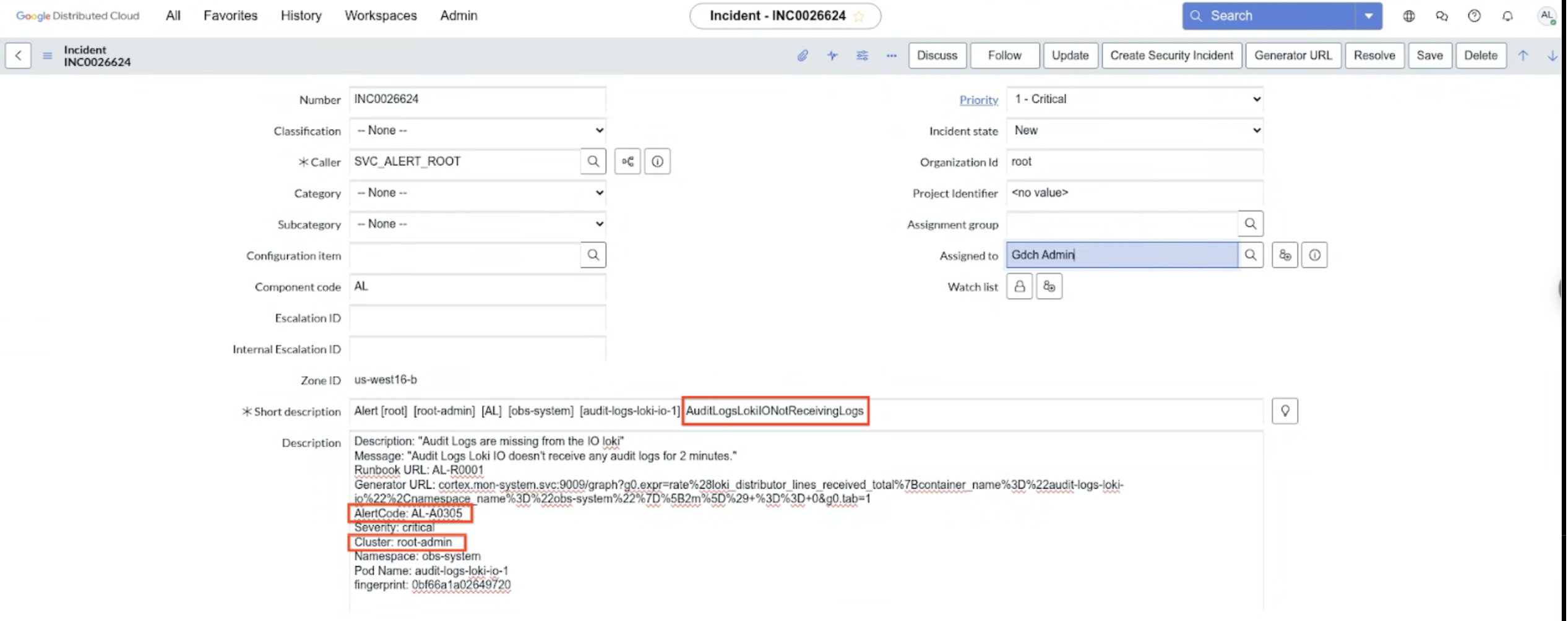
Ticket zuweisen: Weisen Sie der Benachrichtigung ein Ticket zu, um die Inhaberschaft und das Tracking zu gewährleisten.
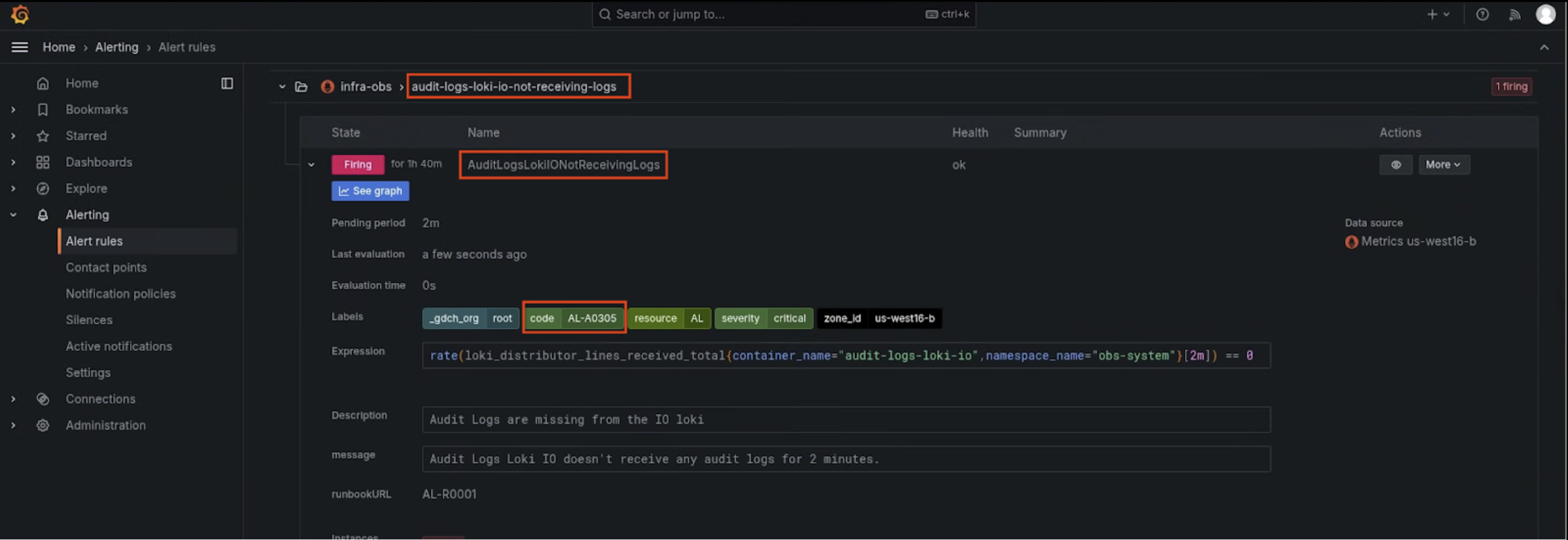
Benachrichtigungsregeln prüfen: Untersuchen Sie die spezifische Benachrichtigungsregel, die ausgelöst wurde, um ihre Bedingungen und ihren Zweck zu verstehen.
Auslösestatus prüfen: Sehen Sie sich die Details und den Status der Auslösebenachrichtigung im Dashboard an.
Warnung bestätigen: Prüfen Sie abschließend, ob die Warnung aktiv ausgelöst wird und ein gültiges Problem darstellt, bevor Sie mit der Eskalierung fortfahren.