Geschätzte Dauer: 4 Tage
Eigentümer der bedienbaren Komponente: HW
Kompetenzprofil: Bereitstellungsingenieur
Führen Sie die folgenden Aufgaben aus, um die Geräte und Systeme zurückzusetzen, die in der Air-Gap-Umgebung von Google Distributed Cloud (GDC) ausgeführt werden.
6.1. Inhaltsverzeichnis
- Übersicht zum Zurücksetzen
- HPE Server Reset
- NetApp StorageGRID Reset
- NetApp ONTAP Reset
- Thales HSM Reset
- Palo Alto-Firewalls zurücksetzen
- Cisco-Switches zurücksetzen
- Zusätzliche Ressourcen
6.2. Voraussetzungen und Sicherheit
6.2.1. Erforderlicher Zugriff
- Physischer Zugriff: Zugriff auf den Rechenzentrumsraum mit Crashcart-Ausrüstung
- Netzwerkzugriff: Verbindung zur Verwaltungsoberfläche oder Konsolenzugriff
- Anmeldedaten: Administratorzugriff auf alle Systeme
- Sicherungen: Vollständige Sicherung aller Secrets und Konfigurationsdaten
6.2.2. Sicherheitscheckliste
- [ ] Physischer Zugriff auf die Infrastruktur
- [ ] Break-Glass-Secrets wurden offline gesichert
- [ ] Sicherung der Infrastruktur (falls erforderlich)
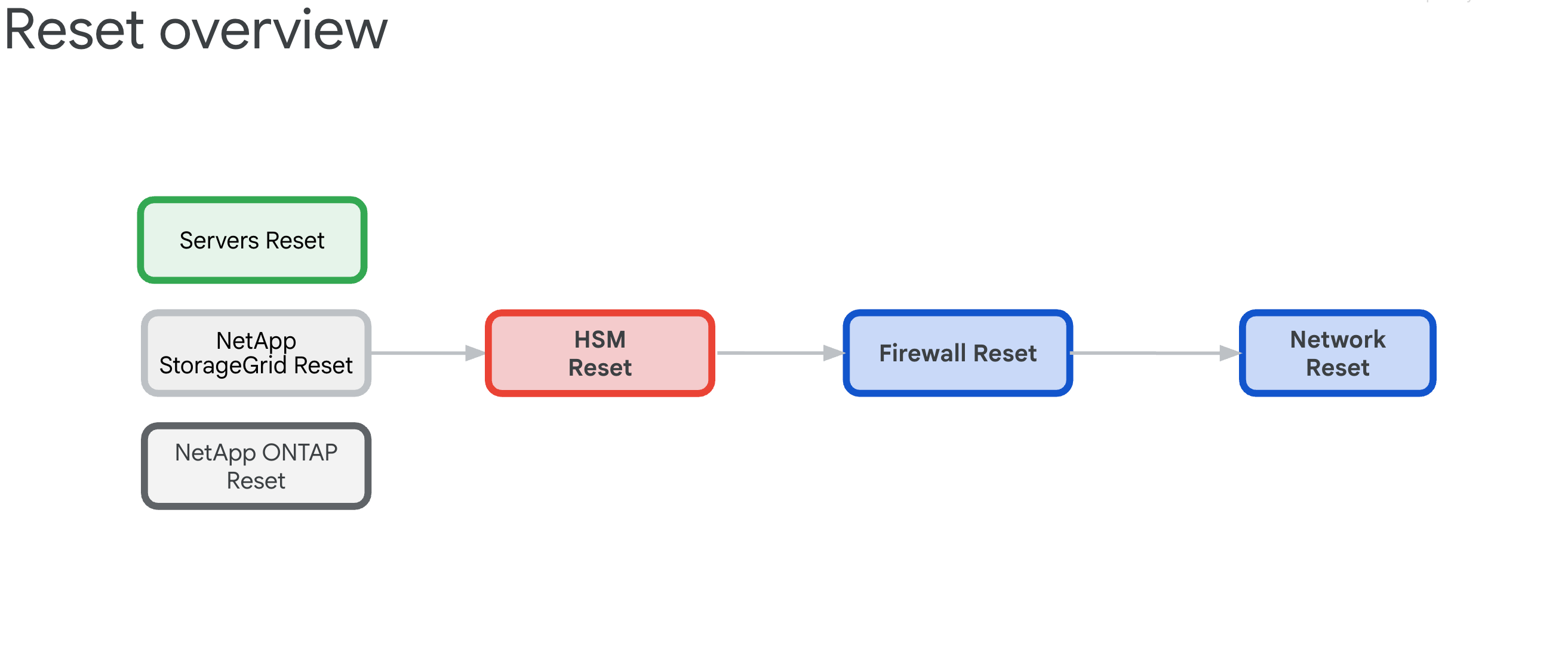
6.3. Übersicht über das Zurücksetzen
Beim Zurücksetzen einer vorhandenen GDC-Zellzone sollen alle Hardwaregeräte von jeglicher Abhängigkeit befreit und dann in den ursprünglichen Zustand zurückversetzt werden.
6.3.1. Infrastrukturabhängigkeiten
Die Komponenten haben die folgenden Abhängigkeiten, die die Reihenfolge des Zurücksetzens bestimmen:
- Server, NetApp ONTAP und NetApp StorageGrid basieren auf den Thales-HSM-Appliances, da diese die Verschlüsselungsschlüssel für ILOs, Festplatten, Mandanten und Buckets bereitstellen.
- Thales-HSM-Appliances sind auf IDP-/Perimeter-Firewalls und Cisco-Switches angewiesen.
- IDP-/Perimeter-Firewalls basieren auf der Netzwerk-Infrastruktur von Cisco-Switches.
- Cisco-Switches müssen als letzte Ressource zurückgesetzt werden, da die Verbindung nach dem Zurücksetzen unterbrochen wird.
6.3.2. Bestellung zurücksetzen (kritisch)
Halten Sie sich genau an diese Reihenfolge, um Systemaussperrungen zu vermeiden:
- HPE-Server: Zuerst HSM-Abhängigkeiten entfernen
- NetApp StorageGRID – Verschlüsselung löschen und Knoten zurücksetzen
- NetApp ONTAP – HSM deaktivieren und Cluster zurücksetzen
- Thales HSM – Auf Werkseinstellungen zurücksetzen und Root of Trust löschen
- Firewalls – Auf Werkseinstellungen zurücksetzen
- Cisco-Switches – Letzte zurücksetzen (unterbricht die Verbindung)
6.4. Sicheres Löschen von Hewlett Packard Enterprise
Es gibt drei Arten von Zurücksetzungsvorgängen, die jeweils als alternative Methode zum Bereinigen der iLO Key Manager-Konfiguration dienen. Das Hauptziel ist, die Abhängigkeit vom Hardwaresicherheitsmodul (HSM) zu beseitigen.
Im Allgemeinen reicht das Zurücksetzen auf die Werkseinstellungen von ILO aus, um die KMS-Konfiguration zu bereinigen. Beim nächsten Bootstrap-Vorgang werden dann die BIOS-Parameter des Servers initialisiert, die Festplatten gelöscht und der Server neu initialisiert.
In diesem Abschnitt wird beschrieben, wie Sie drei Arten von Löschungen vornehmen:
In diesen Löschskripts wird eine Beispiel-CSV-Datei mit dem Namen example.csv verwendet.
Bevor Sie fortfahren, bereiten Sie die folgende CSV-Datei vor:
root@example-bootstrapper:/home/ubuntu/md# cat example.csv
ip,passd
10.251.248.62,XXXXXXXX
10.251.248.64,XXXXXXXX
10.251.248.66,XXXXXXXX
10.251.248.68,XXXXXXXX
10.251.248.70,XXXXXXXX
10.251.248.72,XXXXXXXX
10.251.248.74,XXXXXXXX
10.251.248.76,XXXXXXXX
6.4.1. iLO auf Werkseinstellungen zurücksetzen
Führen Sie ein reguläres Zurücksetzen auf die Werkseinstellungen über iLO durch:
Erstellen Sie eine Datei mit dem Namen
serversreset.pyund fügen Sie das folgende Python-Skript hinzu:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='serversreset.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'Default'} url = '/redfish/v1/Managers/1/Actions/Oem/Hpe/HpeiLO.ResetToFactoryDefaults/' with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+url,data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Führen Sie den folgenden Befehl aus und ersetzen Sie
example.csvdurch Ihre CSV-Datei:python3 serversreset.py -csv example.csvDie Ausgabe muss in etwa so aussehen:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}} {'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.ResetInProgress'}]}}
6.4.2. Zusätzliche manuelle iLO-Schritte
Führen Sie einen manuellen iLO-Reset über die iLO-Benutzeroberfläche durch:
Wählen Sie iLO > Administration > Key Manager > Delete Settings (iLO > Verwaltung > Schlüsselmanager > Einstellungen löschen) aus.
Wählen Sie in der BIOS-Konsole System Utilities > System Configuration > Embedded Raid > Administration > Reset To Default aus.
Schnittstellen nur für LOM1 auf Netboot festlegen. Alle GPU-Knoten haben KEINE LOM1-Karten, sondern Intel-Karten.
Stellen Sie das iLO-Netzwerk auf DHCP ein.
6.4.3. BIOS zurücksetzen
Führen Sie die folgenden Schritte aus, um das BIOS zurückzusetzen:
Erstellen Sie eine Datei mit dem Namen
biosreset.pyund fügen Sie das folgende Python-Skript hinzu:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='biosreset.py', \ description='reset BIOS to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/systems/1/bios/Actions/Bios.ResetBios/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Führen Sie den folgenden Befehl aus und ersetzen Sie
example.csvdurch Ihre CSV-Datei:python3 biosreset.py -csv example.csvDie Ausgabe muss in etwa so aussehen:
{'error': {'code': 'iLO.0.10.ExtendedInfo', 'message': 'See @Message.ExtendedInfo for more information.', '@Message.ExtendedInfo': [{'MessageId': 'iLO.2.15.SystemResetRequired'}]}}Nach Ausführung des Befehls sind die Server eingeschaltet. Sie müssen das folgende Skript ausführen, um alle Server auszuschalten:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='power-ilo.py', \ description='power off server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'ResetType': 'PushPowerButton'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post( 'https://' + row['ip'] + '/redfish/v1/systems/1/Actions/ComputerSystem.Reset/', data=json.dumps(payload), headers=headers, verify=False, auth=('administrator', row['passd'])) systemData = system.json() if 'Success' in systemData['error']['@Message.ExtendedInfo'][0][ 'MessageId']: print(f"ilo with ip {row['ip']} succeeded") #print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: print(err)Fahren Sie die Server manuell herunter:
python3 power-ilo.py -csv ~/servers.csv- (Optional) Verwenden Sie das folgende Script, um den Status zu prüfen:
import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='ilostatus.py', \ description='check power status of server') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.get('https://'+row['ip']+'/redfish/v1/Systems/1',headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(f"ilo with ip {row['ip']} has power status of {systemData['PowerState']}") if 'Success' in systemData['error']['@Message.ExtendedInfo'][0]['MessageId']: print(f"ilo with ip {row['ip']} succeeded") print(systemData) else: print(f"ilo with ip {row['ip']} failed") print(systemData) except Exception as err: passFühren Sie dazu diesen Befehl aus:
python3 ilostatus.py -csv ~/servers.csvDie Ausgabe muss in etwa so aussehen:
ilo with ip 172.22.112.96 has power status of Off ilo with ip 172.22.112.97 has power status of Off ilo with ip 172.22.112.98 has power status of Off ilo with ip 172.22.112.100 has power status of Off ilo with ip 172.22.112.101 has power status of Off ilo with ip 172.22.112.102 has power status of Off6.4.4. Sicheres Löschen
Drücken Sie auf dem POST-Bildschirm des Servers F10. Dadurch wird Intelligent Provisioning gestartet.
Klicken Sie nach dem Start von Intelligent Provisioning auf den Abwärtspfeil neben First Time Setup Wizard (Assistent für die Ersteinrichtung), um den Assistenten zu überspringen.
Überspringen Sie die Aufforderung des Assistenten und klicken Sie auf Ja.
Klicken Sie auf Wartung durchführen.
Klicken Sie auf One Button Secure Erase (Sicheres Löschen mit einem Klick).
Eine Meldung wird angezeigt, die besagt, dass Sie nicht über ausreichende Berechtigungen verfügen. Klicken Sie auf Anmelden und geben Sie die Anmeldedaten des Administrators ein.
Klicken Sie auf Fertig.
Klicken Sie auf Senden.
Bestätigen Sie, dass Sie die Daten sicher löschen möchten, und geben Sie LÖSCHEN ein.
Klicken Sie auf LÖSCHEN.
Klicken Sie zum Bestätigen auf Ja.
Klicken Sie im Abschnitt „Jobs queue“ (Warteschlange für Jobs) auf Launch Now (Jetzt starten).
Klicken Sie innerhalb von etwa zwei Minuten auf OK.
Die Maschine wird neu gestartet. Berühren Sie etwa 10 bis 15 Minuten lang nichts.
Nachdem das sichere Löschen abgeschlossen ist, kehren Sie zum BIOS zurück, indem Sie während des POST-Bootvorgangs auf F9 klicken.
Gehen Sie zu Embedded Applications > Integrated Management Log (IML) > View IML > OK (Eingebettete Anwendungen > Integriertes Verwaltungsprotokoll (IML) > IML ansehen > OK). Die Meldung One-button secure erase completed wird angezeigt:

Erstellen Sie eine Datei mit dem Namen
serversreset.pyund fügen Sie das folgende Python-Skript hinzu:import csv import argparse import requests import urllib3 import json urllib3.disable_warnings() PARSER = argparse.ArgumentParser(prog='secureerase.py', \ description='reset ilo to factory settings') PARSER.add_argument('-csv', '--file', help='choose the csv file', type=str) ARGS = vars(PARSER.parse_args()) headers = {'content-type': 'application/json'} payload = {'SystemROMAndiLOErase': True , 'UserDataErase': True} with open(ARGS['file'], encoding="utf8", mode='r') as csv_file: CSV_READER = csv.DictReader(csv_file) for row in CSV_READER: try: system = requests.post('https://'+row['ip']+'/redfish/v1/Systems/1/Actions/Oem/Hpe/HpeComputerSystemExt.SecureSystemErase/',data=json.dumps(payload),headers=headers,verify=False,auth=('administrator',row['passd'])) systemData = system.json() print(systemData) except Exception as err: print(err)Führen Sie den folgenden Befehl aus und ersetzen Sie
example.csvdurch Ihre CSV-Datei:python serversreset.py -csv example.csvNach dem Ausführen des Befehls sind die Server ausgeschaltet. Sie müssen den Server manuell einschalten.
6.5. NetApp StorageGRID-Gerät zurücksetzen
6.5.1. Vorbereitung
Bevor Sie Ihr NetApp StorageGRID-Gerät zurücksetzen, lesen Sie Folgendes: - Wenn das System mit Knoten- und/oder Laufwerkverschlüsselung aktiviert wurde, müssen Sie die Schritte unter HSM-Standortverschlüsselung deaktivieren ausführen. Fahren Sie andernfalls mit dem Zurücksetzen des StorageGRID-Systems fort.
6.5.2. HSM-basierte Verschlüsselung von StorageGRID-Sites auf Storage Controller-Knoten deaktivieren
So rufen Sie die IPs der Storage Controller-Knoten ab (zwei IPs für jeden Speicherknoten):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Wenn das StorageGRID-System zuvor mit einem HSM aktiviert wurde, muss die Verschlüsselung entfernt werden, bevor Sie mit dem Zurücksetzen auf die Werkseinstellungen fortfahren. Führen Sie diese Schritte für jeden Speicherknoten aus, bevor Sie das Gerät zurücksetzen. Andernfalls können die Festplatten und das System gesperrt werden.
Melden Sie sich auf der Object Storage-Website an und rufen Sie die Liste der Knoten in der Seitenleiste auf.
Klicken Sie auf den Namen des Speicherknotens.
Rufen Sie den Tab SANtricity System Manager auf.
Gehen Sie zu Einstellungen > System > Sicherheitsschlüsselverwaltung.

Wählen Sie Externe Schlüsselverwaltung deaktivieren aus und geben Sie die Passphrase ein, um den Sicherungsschlüssel herunterzuladen.
6.5.3. StorageGRID-Administratorknoten und Storage Compute-Knoten auf Werkseinstellungen zurücksetzen
So rufen Sie die IPs der Admin-Knoten ab:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
So rufen Sie die IPs der Storage Compute-Knoten ab:
$ kubectl get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Wenn Sie das StorageGRID-Gerät auf die Werkseinstellungen zurücksetzen möchten, müssen Sie die folgenden Schritte für jeden Knoten (sowohl Speicher- als auch Administratorknoten) am Standort ausführen:
Rufen Sie die Verwaltungs-IPs für jeden Knoten ab. Diese Informationen können aus der Datei „cell.yaml“ abgerufen werden. Suchen Sie dazu nach
ObjectStorageStorageNodeundObjectStorageAdminNode. Sie finden sie auch in den Knotenressourcen im Administratorcluster des Stammclusters.Rufen Sie das Passwort ab und stellen Sie über SSH eine Verbindung zum Knoten her:
Wenn auf dem Knoten StorageGRID nicht installiert ist, verwenden Sie
admin/bycastbzw.root/netapp1!als Nutzername und Passwort. Verwenden Sie den SSH-Port 8022, wenn SSH nicht funktioniert.Wenn auf dem Knoten StorageGRID installiert ist, aber keine Standorteinrichtung erfolgt ist, verwenden Sie
admin/bycastbzw.root/bycastals Nutzername und Passwort.Wenn die Website eingerichtet ist und der Knoten Teil der Website ist:
Rufen Sie die Passphrase für die Bereitstellung ab. Dieser wird in einem Secret mit dem Namen
grid-secretgespeichert, das sich in der Datei „cell.yaml“ befindet. Optional kann der folgende Befehl ausgeführt werden. Achten Sie darauf, das Passwort mit Base64 zu decodieren:echo $(kubectl get secret -n gpc-system grid-secret -ojsonpath="{.data.grid-management-provisioning-password}" | base64 -d)Rufen Sie in der Benutzeroberfläche der Object Storage-Website Wartung > System > Wiederherstellungspaket auf, um das Wiederherstellungspaket herunterzuladen, nachdem Sie die Bereitstellungs-Passphrase eingegeben haben.

Extrahieren Sie nach dem Herunterladen die TAR-Datei. Sie enthält ein weiteres Tarball:
GIDXXXXX_REV1_SAID.zip. Extrahieren Sie das Tarball, um die DateiPasswords.txtzu finden. Verwenden SiePasswordfür den SSH- und Root-Zugriff und ignorieren SieSSH Access Password.Beispieldatei:
Password Data for Grid ID: 546285, Revision: 1 Revision Prepared on: 2022-06-13 20:49:56 +0000 Server "root" and "admin" Account Passwords Server Name Password SSH Access Password ____________________________________________________________ alatl14-gpcstgeadm01 <removed> <removed> alatl14-gpcstgeadm02 <removed> <removed> alatl14-gpcstgecn01 <removed> n/a alatl14-gpcstgecn02 <removed> n/a alatl14-gpcstgecn03 <removed> n/a
Öffnen Sie eine serielle Konsole für den Knoten oder stellen Sie über SSH eine Verbindung zum Knoten her:
ssh -o ProxyCommand=None -o StrictHostKeyChecking=no \ -o UserKnownHostsFile=/dev/null admin@<node-management-ip>Geben Sie die Anmeldedaten ein. Geben Sie
su -ein, um Sudo-Berechtigungen zu erhalten, und geben Sie das Root-Passwort ein, das Sie im zweiten Schritt erhalten haben.Geben Sie den Befehl
sgareinstallein und drücken Siey, um das Gerät weiter zurückzusetzen.Wenn die Verschlüsselung auf dem Gerät aktiviert war, folgen Sie nach dem Zurücksetzen dieser Anleitung, um die Festplattenpools und den SSD-Cache zu löschen.
6.5.4. Festplattenpools und SSD-Cache auf Storage Controller-Knoten löschen
So rufen Sie die IPs der Storage Controller-Knoten ab (zwei IPs für jeden Speicherknoten):
$ kubectl get objectstoragestoragenodes -n gpc-system -o custom-columns="NAME:metadata.name,COMPUTE_NODEA_IP:.spec.network.controllerAManagementIP,COMPUTE_NODEB_IP:.spec.network.controllerBManagementIP"
NAME COMPUTE_NODEA_IP COMPUTE_NODEB_IP
ak-ac-objs01 172.22.210.166/24 172.22.210.167/24
ak-ac-objs02 172.22.210.170/24 172.22.210.171/24
ak-ac-objs03 172.22.210.174/24 172.22.210.175/24
Wenn die Verschlüsselung auf dem Gerät aktiviert war und die Knoten nach dem letzten Abschnitt zurückgesetzt wurden, müssen die Festplattenpools zusammen mit dem Löschen der Laufwerke gelöscht werden. Dies muss vor dem erneuten Bootstrapping der Website erfolgen, damit neue Festplattenpools erstellt werden können. Führen Sie diese Schritte für jeden Speicherknoten (e2860 Storage Controller) auf der Website aus (auch als „controllerAManagementIP“ bezeichnet):
Öffnen Sie einen Webbrowser, rufen Sie
https://<storage-node-controller-ip>:8443auf und geben Sie die Anmeldedaten ein. Wenn Sie keinen Zugriff auf SANtricity-Anmeldedaten haben, gehen Sie so vor.Rufen Sie Speicher > Pools und Volumegruppen auf.
SSD-Cache löschen:
Wählen Sie den SSD-Cache aus, um ihn zu markieren.
Wählen Sie das Drop-down-Menü Ungewöhnliche Aufgaben aus und klicken Sie auf Löschen.

Löschen Sie den Laufwerkpool:
Wählen Sie den Datenträgerpool aus, um ihn hervorzuheben.
Wählen Sie das Drop-down-Menü Ungewöhnliche Aufgaben aus und klicken Sie auf Löschen.

Versuchen Sie, einen neuen Festplattenpool zu erstellen. Ein Dialogfeld wird angezeigt, das die Erstellung blockiert und Sie auffordert, die Laufwerke zu löschen.

Da nicht zugewiesene, sicherheitsfähige Laufwerke nicht zum Erstellen von Pools verwendet werden können, müssen Sie sie zuerst löschen. Klicken Sie auf das Optionsfeld Ja – ich möchte die Laufwerke auswählen, die für den Vorgang gelöscht werden sollen und wählen Sie dann alle Laufwerke aus, die gelöscht werden sollen. Bestätigen Sie den Löschvorgang und klicken Sie auf OK. Erstellen Sie keinen neuen Pool.
Folgen Sie der Anleitung im Abschnitt zum Entfernen der Knotenverschlüsselung.
6.5.5. Knotenverschlüsselung auf StorageGRID-Administratorknoten und Storage Compute-Knoten entfernen
So rufen Sie die IPs der Admin-Knoten ab:
$ kubectl get objectstorageadminnodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objsadm01 ak-obj-site-1 172.22.210.160/24 True 12d
ak-ac-objsadm02 ak-obj-site-1 172.22.210.162/24 True 12d
So rufen Sie die IPs der Storage Compute-Knoten ab:
$ kr get objectstoragestoragenodes -n gpc-system
NAME SITE NAME MANAGEMENT IP READY AGE
ak-ac-objs01 ak-obj-site-1 172.22.210.164/24 True 12d
ak-ac-objs02 ak-obj-site-1 172.22.210.168/24 True 12d
ak-ac-objs03 ak-obj-site-1 172.22.210.172/24 True 12d
Wenn die Verschlüsselung auf dem Gerät aktiviert war und die Knoten nach diesen Schritten zurückgesetzt wurden und die Festplattenpools und der SSD-Cache mit diesen Schritten gelöscht wurden, führen Sie die folgenden Schritte auf jedem Knoten aus, um die Knotenverschlüsselung zu entfernen:
Rufen Sie die StorageGRID Appliance Installer-Benutzeroberfläche auf.
Rufen Sie Hardware konfigurieren > Knotenverschlüsselung auf.
Klicken Sie auf KMS-Schlüssel löschen und Daten löschen.

Sobald das Löschen ausgelöst wird, wird der Controller neu gestartet. Das kann etwa 15 Minuten dauern.
6.5.6. StorageGRID neu installieren
Starten Sie jeden Knoten manuell neu.
Öffnen Sie eine serielle Konsole für den Knoten, rufen Sie das GRUB-Bootloader-Menü auf und wählen Sie StorageGRID Appliance: Force StorageGRID reinstall (StorageGRID-Appliance: StorageGRID-Neuinstallation erzwingen) aus.

6.5.7. SANtricity-Anmeldedaten abrufen
Öffnen Sie eine serielle Konsole zu einem der SANtricity-Controller.
Verwenden Sie die folgenden Anmeldedaten, um sich anzumelden:
- Nutzername:
spri - Passwort:
SPRIentry
- Nutzername:
Nach der Anmeldung wird ein Menü wie dieses angezeigt:
Service Interface Main Menu ============================== 1)Display IP Configuration 2)Change IP Configuration 3)Reset Storage Array Administrator Password 4)Display 7-segment LED codes 5)Disable SAML 6)Unlock remote admin account Q)Quit Menu Enter Selection: 3 Are you sure that you want to reset the Storage Array Password ? (Y/N): Y Storage Array Password reset successfulMelden Sie sich bei den SANtricity-Controllern an. Das Zurücksetzen des Passworts ist dann möglich.
6.6. NetApp ONTAP-Gerät zurücksetzen
6.6.1. Vorbereitung
Bevor Sie Ihr NetApp ONTAP-Gerät zurücksetzen, lesen Sie bitte Folgendes:
Wenn das System zuvor mit einem Hardwaresicherheitsmodul (HSM) aktiviert wurde, müssen Sie die Schritte unter Hardwaresicherheitsmodul deaktivieren ausführen, bevor Sie die ONTAP-Systeme zurücksetzen.
Dies ist ein destruktiver Vorgang, bei dem alle CipherTrust Manager-Daten gelöscht werden, einschließlich, aber nicht beschränkt auf Schlüssel, Sicherungen, Sicherungsschlüssel und Systemprotokolle.
Stellen Sie sicher, dass Sie eine gültige CipherTrust Manager-Sicherung aller Daten und Sicherungsschlüssel haben.
Wenn ein eingebettetes HSM verfügbar ist, wird es bei diesem Vorgang nicht zurückgesetzt.
Optional: Die Neuinitialisierung eines eingebetteten HSM nach diesem Vorgang wird dringend empfohlen, um es als Root of Trust zu konfigurieren.
Wenn ein externes PIN-Eingabegerät (PED) verwendet wurde, muss es nach Abschluss wieder angeschlossen werden.
Dieser Vorgang kann bis zu 15 Minuten dauern. Sorgen Sie für eine Notstromversorgung.
6.6.2. Hardwaresicherheitsmodul deaktivieren
Wenn das System zuvor mit einem HSM aktiviert wurde, führen Sie diese Schritte aus, bevor Sie die ONTAP-Systeme zurücksetzen. Andernfalls können die Festplatten und das System gesperrt werden. Führen Sie die folgenden Befehle im ONTAP-Cluster aus:
Legen Sie die Berechtigungsstufe auf „Erweitert“ fest:
set -privilege advancedListen Sie den Datenschlüssel der Festplatte und die FIPS-Authentifizierungsschlüssel (Federal Information Processing Standards) auf, die sie verwendet:
storage encryption disk showLegen Sie für jede Festplatte im System die Daten- und FIPS-Authentifizierungsschlüssel-ID für den Knoten wieder auf die Standard-MSID 0x0 fest:
storage encryption disk modify -disk * -fips-key-id 0x0 storage encryption disk modify -disk * -data-key-id 0x0Prüfen Sie mit den folgenden Schritten, ob der Vorgang erfolgreich war:
storage encryption disk show-statusWiederholen Sie den Befehl
show-status, bis SieDisks Begun == Disks Doneerhalten. Diese Ausgabe bedeutet, dass der Vorgang abgeschlossen ist.cluster1:: storage encryption disk show-status FIPS Latest Start Execution Disks Disks Disks Node Support Request Timestamp Time (sec) Begun Done Successful ------- ------- -------- ------------------ ---------- ------ ------ ---------- cluster1 true modify 1/18/2022 15:29:38 3 14 5 5 1 entry was displayed.Entfernen Sie die Konfiguration des External Key Managers:
Wenn die HSM-Verbindung aktiv ist, fahren Sie direkt mit Schritt f fort. Wenn die HSM-Verbindung unterbrochen ist, fahren Sie mit Schritt b fort.
cluster1::> security key-manager external show-statusWechseln Sie in den
diag-Modus, indem Sieset -priv diagausführen.Führen Sie den folgenden Befehl aus, um alle Volume-Verschlüsselungsschlüssel aufzurufen.
debug smdb table kmip_external_key_cache_mdb_v2 show.Erfassen Sie das Attribut
vserver-id.Führen Sie den folgenden Befehl für alle Schlüsselserver aus, um die Schlüssel zu löschen:
debug smdb table kmip_external_key_cache_mdb_v2 delete -vserver-id <vserver-id> -key-id * -key-server <key-server endpoint>.Löschen Sie alle Volumes über die ONTAP-Benutzeroberfläche oder manuell über die Console.
Wenn Sie die Knoten über die Console löschen, müssen Sie die Root-Volumes für die Knoten ignorieren. Diese haben in der Regel den Namen
vol0und einen der Knoten alsvserver. Ein Volume mit einem Knoten alsvserverdarf in der Regel nicht gelöscht werden und sollte nicht gelöscht werden.Wenn andere Volumes als
vol0aus dem vorherigen Schritt nicht über die Benutzeroberfläche gelöscht werden können, versuchen Sie es mit der CLI:cluster1::> vol offline -volume volume_to_be_deleted -vserver vserve-id cluster1::> vol delete -volume volume_to_be_deleted -vserver vserver-idWenn Sie sich über die Benutzeroberfläche in einem Speichercluster anmelden möchten, rufen Sie den Nutzernamen und das Passwort mit den folgenden Befehlen aus dem Secret ab. Ersetzen Sie dabei CELL_ID durch die eindeutige ID der Zelle, die Sie installieren:
kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_username}' | base64 --decode kubectl get secret -n gpc-system ontap-CELL_ID-stge-clus-01-credential -o jsonpath='{.data.netapp_password}' | base64 --decodeRufen Sie dann Volumes auf, wählen Sie alle aus und klicken Sie auf Löschen. Sie müssen die Schritte für jede Seite mehrmals wiederholen. Hinweis: Sie können einen Fehler, der darauf hinweist, dass ein Volume nicht gelöscht werden konnte, ignorieren. Weitere Informationen finden Sie in der NetApp-Wissensdatenbank.
ag-stge-clus-01::*> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ag-ad-stge01-01 vol0 aggr0_ag_ad_stge01_01 online RW 151.3GB 84.97GB 40% ag-ad-stge01-02 vol0 aggr0_ag_ad_stge01_02 online RW 151.3GB 86.69GB 39% ag-ad-stge02-01 vol0 aggr0_ag_ad_stge02_01 online RW 151.3GB 83.62GB 41% ag-ad-stge02-02 vol0 aggr0_ag_ad_stge02_02 online RW 151.3GB 85.97GB 40% ag-ad-stge03-01 vol0 aggr0_ag_ad_stge03_01 online RW 151.3GB 89.19GB 37% ag-ad-stge03-02 vol0 aggr0_ag_ad_stge03_02 online RW 151.3GB 88.74GB 38%
Führen Sie nach dem Löschen aller Volumes den folgenden Befehl aus, um die Wiederherstellungswarteschlange zu leeren:
recovery-queue purge-all -vserver <vserver>.Führen Sie den folgenden Befehl aus, um den externen Schlüsselmanager zu löschen:
clusterl::> security key-manager external remove-servers -vserver <CLUSTER_NAME> -key-servers <IP1:PORT,IP2:PORT,...>. Nach diesem Schritt erhalten Sie möglicherweise die folgende Fehlermeldung:Error: command failed: The key server at "172.22.112.192" contains authentication keys that are currently in use and not available from any other configured key server.Dieser Fehler weist darauf hin, dass noch Schlüssel vorhanden sind. So löschen Sie die verbleibenden Schlüssel:
Führen Sie den folgenden Befehl aus, um die verbleibenden Schlüssel aufzulisten:
security key-manager key queryDie Ausgabe sieht etwa so aus wie im folgenden Beispiel.
Node: ag-ad-stge01-01 Vserver: ag-stge-clus-01 Key Manager: 172.22.112.192:5696 Key Manager Type: KMIP Key Manager Policy: - Key Tag Key Type Encryption Restored ------------------------------------ -------- ------------ -------- ag-ad-stge01-01 NSE-AK AES-256 true Key ID: 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Notieren Sie sich den Wert für Key ID aus der vorherigen Ausgabe. Verwenden Sie den Befehl
security key-manager key delete -key-id+ den Wert Schlüssel-ID, um die verbleibenden Schlüssel zu löschen:security key-manager key delete -key-id 00000000000000000200000000000100454007f1854b3e3f5c90756bc5cfa6cc0000000000000000Wiederholen Sie die Schritte i und j, um die verbleibenden Schlüssel zu löschen. Wenn Sie fertig sind, sieht die Ausgabe etwa so aus:
ag-stge-clus-01::*> security key-manager key query No matching keys found.6.6.3. ONTAP-Knoten zurücksetzen
So setzen Sie ONTAP-Knoten zurück:
Starten Sie den Knoten neu, um über die Systemeingabeaufforderung mit dem Befehl
system node rebootauf das Bootmenü zuzugreifen. Hinweis: Warnungen zum Neustart des Systems können Sie ignorieren.Beispiele:
ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge03-02". Use the "network interface show -curr-node ag-ad-stge03-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge03-02 -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge03-02"? {y|n}: y Connection to 172.22.115.134 closed.ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 Error: command failed: Taking node "ag-ad-stge02-02" out of service might result in a data service failure and client disruption for the entire cluster. If possible, bring an additional node online to improve the resiliency of the cluster and to ensure continuity of service. Verify the health of the node using the "cluster show" command, then try the command again, or provide "-ignore-quorum-warnings" to bypass this check. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Error: Could not migrate LIFs away from node: Failed to migrate one or more LIFs away from node "ag-ad-stge02-02". Use the "network interface show -curr-node ag-ad-stge02-02" command to identify LIFs that could not be migrated off that node. Use the "network interface migrate" command to manually migrate the LIFs off the node. Reissue the command with "-skip-lif-migration-before-reboot" to skip the migration and continue with takeover. ag-stge-clus-01::> system reboot -node ag-ad-stge02-02 -ignore-quorum-warnings -skip-lif-migration-before-reboot Warning: Are you sure you want to reboot node "ag-ad-stge02-02"? {y|n}: y Connection to 172.22.115.132 closed.Wenn Sie sich im Menü
LOADERbefinden, geben Sieboot_ontapein, um mit dem Neustart fortzufahren. Drücken Sie während des NeustartsCtrl-C, um das Bootmenü aufzurufen, wenn Sie dazu aufgefordert werden. Der Knoten zeigt die folgenden Optionen für das Bootmenü an:(1) Normal Boot. (2) Boot without /etc/rc. (3) Change password. (4) Clean configuration and initialize all disks. (5) Maintenance mode boot. (6) Update flash from backup config. (7) Install new software first. (8) Reboot node. (9) Configure Advanced Drive Partitioning Selection (1-9)?Wählen Sie die Option
(9) Configure Advanced Drive Partitioningaus. Für den Knoten sind die folgenden Optionen verfügbar:* Advanced Drive Partitioning Boot Menu Options * ************************************************* (9a) Destroy aggregates, unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. (9f) Remove disk ownership.Wählen Sie die Option
9aaus und geben Sienoein, wenn Sie zur Kündigung aufgefordert werden. Nach9awird im Knoten wieder die folgende Option angezeigt:(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu. ```Führen Sie den
9a-Vorgang für alle Speicherknoten im Cluster aus, bevor Sie fortfahren.Führen Sie für jeden Knoten die Option
9baus und geben Sieyesein, um die Auswahl zu bestätigen.(9a) Unpartition all disks and remove their ownership information. (9b) Clean configuration and initialize node with partitioned disks. (9c) Clean configuration and initialize node with whole disks. (9d) Reboot the node. (9e) Return to main boot menu.Wenn ein HA-Paar vorhanden ist, wird die folgende Meldung angezeigt. Achten Sie darauf, dass alle Knoten im Cluster Schritt 9a abgeschlossen haben, bevor Sie Schritt 9b darauf ausführen.
Selection (9a-9f)?: 9b 9b Option (9a) MUST BE COMPLETED on BOTH nodes in an HA pair (and DR/DR-AUX partner nodes if applicable) prior to starting option (9b). Has option (9a) been completed on all the nodes (yes/no)? yes yes
Wenn die Meldung
Welcome to the cluster setup wizardangezeigt wird, ist das Zurücksetzen abgeschlossen.
6.7. Thales k570 zurücksetzen
Um den Thales k570 zurückzusetzen, setzen Sie zuerst den Ciphertrust Manager auf die Werkseinstellungen zurück und dann das Luna HSM.
6.7.1. System auf Werkseinstellungen zurücksetzen
Erstellen Sie ein temporäres Arbeitsverzeichnis für HSM-Anmeldedaten:
TMPPWDDIR=/run/user/$(id --user)/hsm mkdir -p $TMPPWDDIR chmod 700 $TMPPWDDIRStellen Sie eine SSH-Verbindung zum HSM her:
export ADMIN_SSH_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[].metadata.name | tr -d '"' | grep "ssh"` kubectl get secret $ADMIN_SSH_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.ssh-privatekey}' \ | base64 --decode > $TMPPWDDIR/hsm-ssh-privatekey chmod 0600 $TMPPWDDIR/hsm-ssh-privatekey ssh -i $TMPPWDDIR/hsm-ssh-privatekey ksadmin@$HSM_MGMT_IPWenn das nicht möglich ist, stellen Sie über ein serielles Kabel eine Verbindung zwischen Ihrem Computer und dem Konsolenport her. Führen Sie den folgenden Befehl auf einem anderen Tab aus, um das
ksadmin-Passwort abzurufen.export KSADMIN_SECRET_NAME=`kubectl get secrets -n hsm-system -o json | jq .items[]metadata.name | tr -d '"' | grep "ksadmin"` kubectl get secret $KSADMIN_SECRET_NAME \ --namespace=hsm-system \ --output jsonpath='{.data.password}' \ | base64 --decodeSobald Sie sich über die serielle Schnittstelle anmelden, wird eine Anmeldeaufforderung angezeigt. Geben Sie den Nutzernamen als
ksadminein und fügen Sie das Passwort aus dem vorherigen Befehl ein.Bevor Sie den Befehl
factory-resetausführen:Vermeiden Sie es, das System während dieser Zeit neu zu starten, da die erneute Verbindung mehrere Systemneustarts erfordert und nicht rückgängig gemacht werden kann.
Sorgen Sie für eine Notstromversorgung.
Führen Sie den folgenden Befehl aus, um das Gerät auf die Werkseinstellungen zurückzusetzen:
sudo /opt/keysecure/ks_reset_to_factory.shDas Zurücksetzen dauert etwa 10 Minuten.
6.7.2. Luna HSM zurücksetzen
Beim Zurücksetzen auf die Werkseinstellungen wird das Root of Trust nicht aus den HSMs gelöscht. Führen Sie die folgenden Befehle aus, um das Luna HSM zurückzusetzen:
Führen Sie auf dem CipherTrust Manager-Host entweder über SSH oder über die serielle Konsole den folgenden Befehl aus:
/usr/safenet/lunaclient/bin/lunacmlunacm:> hsm factoryResetLöschen Sie das temporäre Arbeitsverzeichnis aus dem Bootstrapper:
rm $TMPPWDDIR
6.8. Firewalls zurücksetzen
Eine Anleitung zum Zurücksetzen Ihrer Firewalls auf die Werkseinstellungen finden Sie unter Firewall auf Werkseinstellungen zurücksetzen.
6.9. Cisco-Switches zurücksetzen
Führen Sie die folgenden Schritte aus, um Cisco-Switches zurückzusetzen. Diese Anleitung gilt auch für Speicherwechsel wie stgesw.
- Melden Sie sich bei den Switches an.
Schalter beschreiben, löschen und neu laden:
write erase reloadWenn die Schalter bereits konfiguriert wurden und Sie ein
cellcfg-Verzeichnis haben, können Sie stattdessen der Anleitung zur Vorab-Bereinigung folgen.Prüfen Sie, ob die Switches sich im POAP-Modus (Power On Auto Provisioning) befinden.
Wenn der Switch richtig zurückgesetzt wurde, sollte beim Verbinden mit dem Konsolenserver die folgende Aufforderung angezeigt werden:
Abort Power On Auto Provisioning [yes - continue with normal setup, skip - bypass password and basic configuration, no - continue with Power On Auto Provisioning] (yes/skip/no)[no]:
6.10. Zusätzliche Informationen zum Zurücksetzen
Weitere Informationen zum Zurücksetzen finden Sie in den folgenden Ressourcen:
https://docs.netapp.com/us-en/ontap/system-admin/manage-node-boot-menu-task.htmlhttps://docs.netapp.com/us-en/ontap/encryption-at-rest/return-seds-unprotected-mode-task.html