Obiettivi
Utilizza Dataproc Hub per creare un ambiente notebook JupyterLab per un singolo utente in esecuzione su un cluster Dataproc.
Crea un notebook ed esegui un job Spark sul cluster Dataproc.
Elimina il cluster e conserva il notebook in Cloud Storage.
Prima di iniziare
- L'amministratore deve concederti l'autorizzazione
notebooks.instances.use(vedi Impostare i ruoli Identity and Access Management (IAM)).
Crea un cluster Dataproc JupyterLab da Dataproc Hub
Seleziona la scheda Notebook gestiti dall'utente nella pagina Dataproc→Workbench nella console Google Cloud .
Fai clic su Apri JupyterLab nella riga che elenca l'istanza di Dataproc Hub creata dall'amministratore.
- Se non hai accesso alla console Google Cloud , inserisci l'URL dell'istanza Dataproc Hub che un amministratore ha condiviso con te nel browser web.
Nella pagina Jupyterhub→Opzioni Dataproc, seleziona una configurazione del cluster e una zona. Se è abilitata, specifica le personalizzazioni, poi fai clic su Crea.
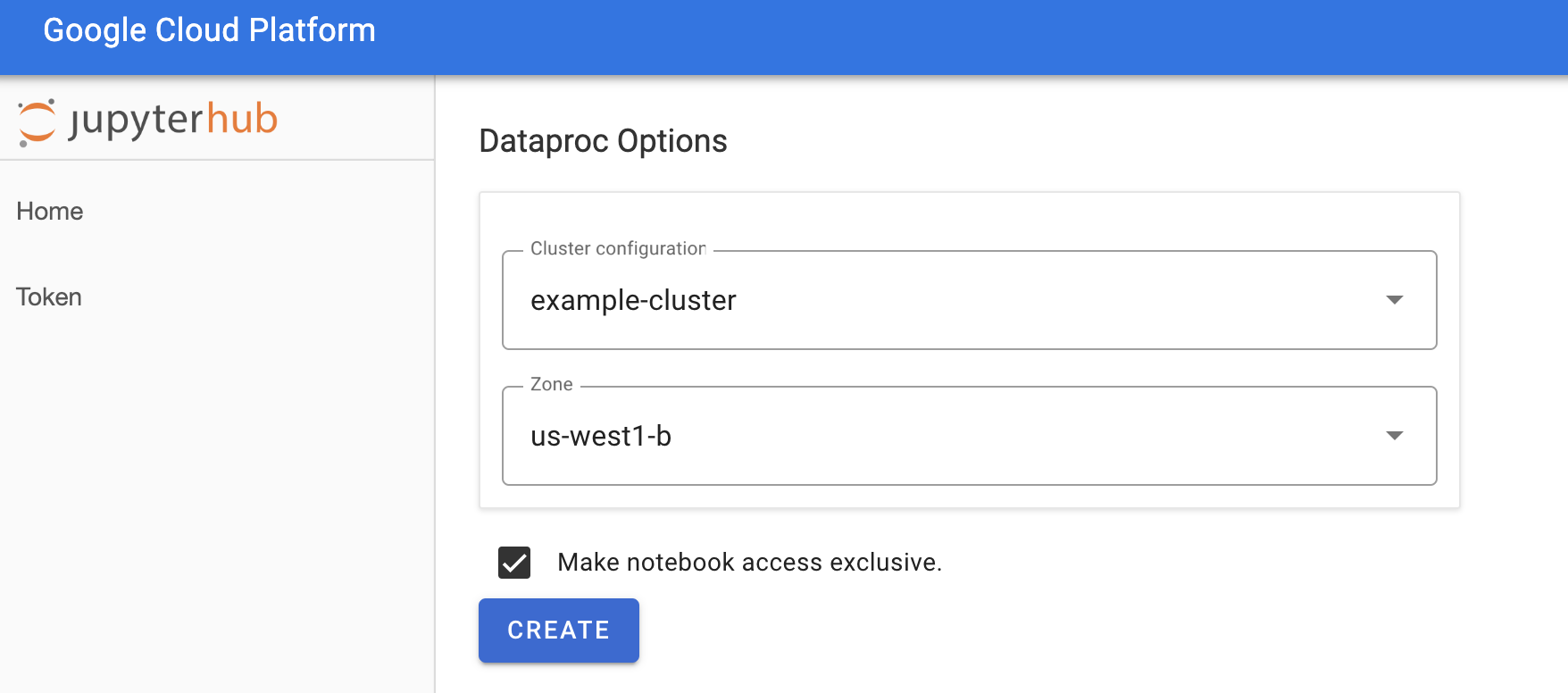
Dopo aver creato il cluster Dataproc, viene visualizzata l'interfaccia JupyterLab in esecuzione sul cluster.
Crea un notebook ed esegui un job Spark
Nel riquadro a sinistra dell'interfaccia di JupyterLab, fai clic su
GCS(Cloud Storage).Crea un notebook PySpark dal launcher JupyterLab.

Il kernel PySpark inizializza uno SparkContext (utilizzando la variabile
sc). Puoi esaminare SparkContext ed eseguire un job Spark dal blocco note.rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())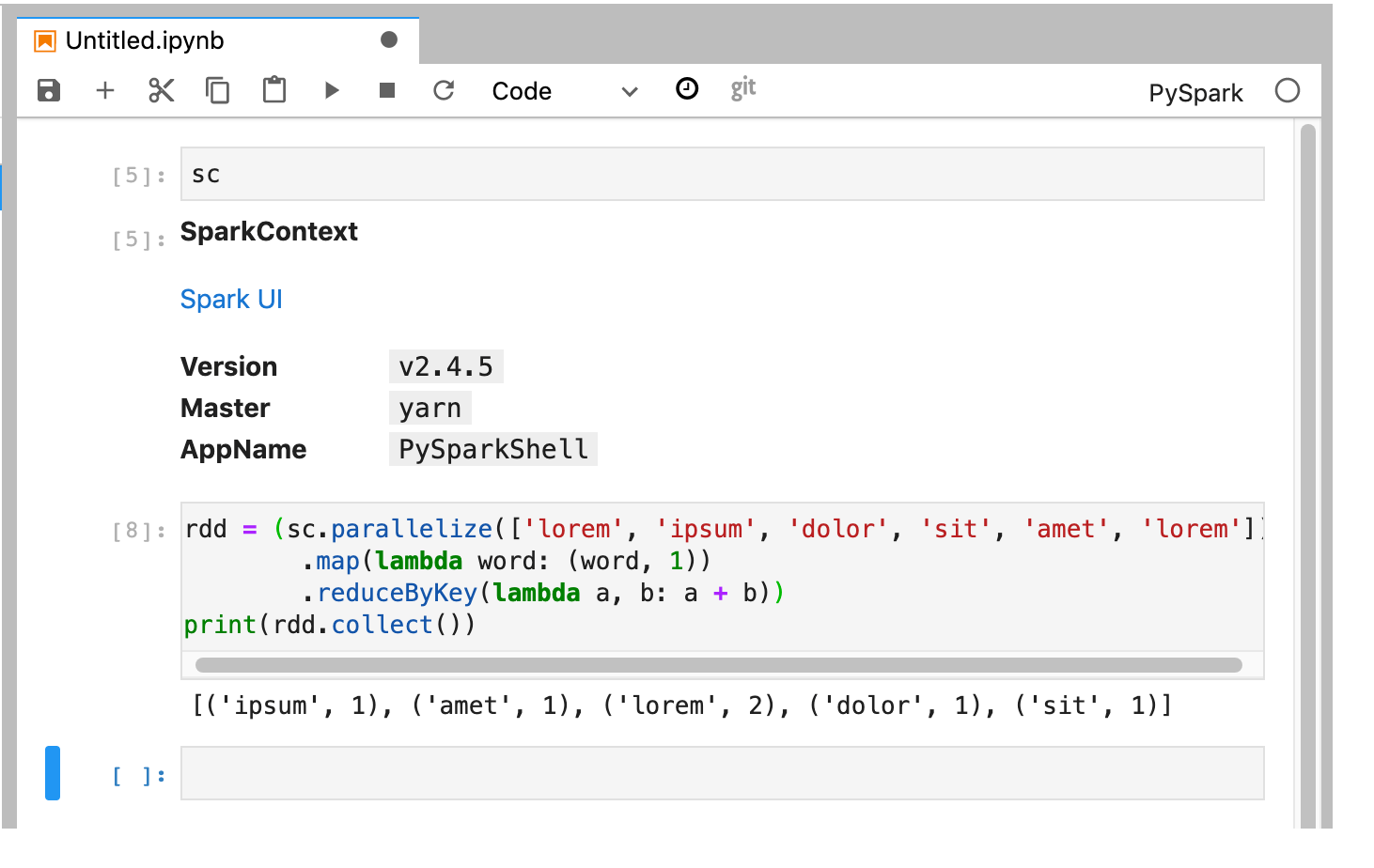
Assegna un nome e salva il notebook. Il blocco note viene salvato e rimane in Cloud Storage dopo l'eliminazione del cluster Dataproc.
Arresta il cluster Dataproc
Dall'interfaccia di JupyterLab, seleziona File→Pannello di controllo hub per aprire la pagina JupyterHub.
Fai clic su Arresta il mio cluster per arrestare (eliminare) il server JupyterLab, che elimina il cluster Dataproc.
Passaggi successivi
- Esplora Spark e Jupyter Notebooks su Dataproc su GitHub.