A linhagem de dados ajuda a entender como os dados se movimentam nos sistemas rastreando as relações entre os recursos de dados e os processos que os transformam. É possível conferir essas informações de linhagem como gráficos e listas no console do Google Cloud .
Este documento fornece uma visão geral do modelo de informações de linhagem de dados, detalhes sobre a granularidade da linhagem no nível da tabela e da coluna, além de instruções sobre como usar as visualizações em gráfico e em lista para explorar a linhagem de dados.
Modelo de informações de linhagem de dados
A linhagem é um registro de dados sendo transformados de origens em destinos. A API Data Lineage coleta essas informações e as organiza em um modelo de dados hierárquico que usa os conceitos de processos, execuções e eventos.
- Processo: uma definição de transformação de dados.
- Execução: a realização de um processo.
- Evento: um registro da movimentação de dados durante uma execução.
Processo
Um processo é a definição de uma operação de transformação de dados para um sistema específico. Para linhagem do BigQuery, um processo é um job de um tipo de job compatível. Todas as execuções da mesma consulta SQL são vinculadas a um único processo, o que permite rastrear todas as instâncias em que uma lógica de transformação específica é usada.
Por exemplo, a seguinte consulta SQL é um processo. Essa consulta cria uma tabela contando o número total de viagens de cada fornecedor em duas tabelas de origem.
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
O formato do nome do recurso REST para um processo é
projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID.
Por exemplo: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
Para mais informações sobre o recurso process, consulte a
Referência do recurso de processo.
Executar
Uma execução é uma única operação de um processo. Os processos podem ter várias execuções.
Cada execução é uma operação única caracterizada por um startTime, um endTime e um estado final, como COMPLETED, FAILED ou ABORTED.
Por exemplo, executar a consulta SQL da seção Processo às 9h cria uma execução específica. Executar a mesma consulta novamente às 10h cria uma execução nova e distinta. As duas execuções estão vinculadas ao mesmo processo principal.
O formato do nome do recurso REST para uma execução mostra que ela é filha de um processo: projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID.
Por exemplo: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
Para mais informações sobre o recurso run, consulte a
referência do recurso "Run".
Evento
Um evento representa um ponto no tempo em que uma transformação de dados move dados entre uma origem e uma entidade de destino. Um evento é um registro granular de um movimento de dados específico que conecta tabelas de origem e de destino para uma execução específica. Um evento também pode ter várias origens e destinos.
Por exemplo, se a execução executar a consulta SQL discutida na seção Processo, um evento de linhagem vai registrar que as tabelas de origem nyc_green_trips_2021 e nyc_green_trips_2022 são usadas para criar a tabela de destino total_green_trips_22_21.
Um evento de linhagem contém uma lista de links que definem a origem e o destino. Os eventos são usados para criar gráficos de linhagem. Embora o console Google Cloud apresente esses gráficos de linhagem, ele não mostra diretamente eventos individuais. É possível criar, ler e excluir eventos usando a API Data Lineage, mas não é possível atualizá-los.
Cada link em um evento define um único caminho de fluxo de dados de uma entidade de origem para uma entidade de destino. Uma entidade é uma referência a um recurso de dados, como uma tabela do BigQuery, e é identificada pelo nome totalmente qualificado (FQN). Um único evento pode conter vários links, o que é comum em operações como junções de tabelas, em que várias fontes contribuem para um destino.
Para detalhes sobre como os eventos oferecem suporte à linhagem no nível da coluna, consulte Linhagem no nível da coluna.
Granularidade da linhagem
Com a linhagem de dados, é possível rastrear a origem e o caminho de transformação dos dados no nível da tabela e da coluna.
Linhagem no nível de tabela
A linhagem no nível da tabela oferece uma visão geral de alto nível dos seus pipelines de dados, mostrando as relações entre tabelas inteiras. Use a linhagem no nível da tabela para tarefas macro, como:
Descoberta de dados. Um analista que cria um painel novo pode usar a linhagem no nível da tabela para rastrear uma tabela de resumo até as fontes e confirmar se os dados vêm de um banco de dados confiável.
Planejamento de migração. Um administrador de banco de dados que planeja migrar um banco de dados principal pode usar a linhagem no nível da tabela para identificar todos os relatórios e painéis downstream que dependem dele.
Auditoria e governança. Um administrador de dados pode usar a linhagem no nível da tabela e da coluna para verificar como os dados de uma tabela que contém informações de identificação pessoal (PII) fluem por um pipeline.
Linhagem no nível da coluna
A linhagem no nível da coluna oferece uma visão mais detalhada ao rastrear o fluxo de dados entre colunas individuais. Nessa visualização, os links em um evento de linhagem representam a relação entre uma coluna de origem e uma de destino. Cada um desses links no nível da coluna tem um tipo de dependência que descreve a transformação:
Exact copy: os valores são copiados entre colunas.Other: outros tipos de dependências entre colunas.
Use a linhagem no nível da coluna para tarefas como:
Análise da causa raiz. Se um analista de dados encontrar um valor incorreto em uma coluna, ele poderá usar a linhagem no nível da coluna para rastrear até as colunas de origem e encontrar a causa raiz.
Análise de impacto. Antes de descontinuar uma coluna, um engenheiro de dados pode usar a linhagem no nível da coluna para encontrar todas as colunas downstream que dependem dela.
Verificação da fonte de dados para métricas. Um analista de dados pode usar a linhagem em nível de coluna para identificar quais colunas de origem são usadas para calcular uma métrica sem decifrar uma consulta SQL complexa.
A linhagem no nível da coluna é coletada automaticamente para os seguintes tipos de jobs do BigQuery:
Visualizações de linhagem no console do Google Cloud
Com a linhagem de dados no console Google Cloud , é possível interagir com informações de linhagem de duas maneiras: analisar o gráfico em várias regiões disponíveis ou usar o painel Explorador de linhagem para ter uma visão mais focada em uma região específica. Você também pode alternar entre as visualizações Gráfico e Lista para analisar o fluxo de dados em diferentes níveis de detalhes.
As visualizações de linhagem só estão disponíveis para entradas do catálogo universal do Dataplex, ativos do BigQuery e recursos da Vertex AI (modelos, conjuntos de dados, visualizações do Feature Store e grupos de recursos).
Para conferir as diferentes visualizações discutidas nesta página, consulte Usar linhagem de dados com sistemas Google Cloud .
Visualização do gráfico de linhagem
A visualização Gráfico mostra o fluxo e as relações de recursos de dados entre sistemas e regiões, ajudando você a entender a arquitetura de dados, rastrear origens e destinos e identificar padrões. Esses gráficos de linhagem, gerados pelo serviço da API Data Lineage para uma entrada específica do Dataplex Universal Catalog, mostram como os dados são transformados ao longo do tempo, exibindo fluxos upstream, downstream ou ambos de uma entrada raiz selecionada.
A API Data Lineage recebe automaticamente informações de ativos de sistemas compatíveis e por chamadas de API para fontes personalizadas.
Os principais elementos do gráfico são descritos da seguinte forma:
Nós. Represente as entidades de dados. Em uma visualização no nível da tabela, um nó mostra o nome da tabela e as colunas dela. Em uma visualização no nível da coluna, cada nó representa uma tabela e uma coluna específicas.
Bordas. As linhas que conectam nós e representam os processos que ocorrem entre eles. A aparência de uma aresta depende da visualização de linhagem:
- Na visualização no nível da tabela, as arestas têm ícones que indicam transformações de dados.
- Na visualização no nível da coluna, as arestas têm rótulos para indicar transformações de dados. Por exemplo, um rótulo de aresta pode dizer
Exact copypara descrever como uma coluna de origem foi copiada para uma coluna de destino.
Processar ícones e rótulos. Aparecem nas bordas para fornecer mais informações sobre a transformação.
- Ícones. Representar o processo de transformação. Ao analisar o gráfico manualmente, os ícones nas arestas representam o sistema de origem do processo (por exemplo, BigQuery ou Vertex AI). Se vários processos estiverem envolvidos, um ícone "vários processos" será exibido. Se o sistema de origem do processo for desconhecido, um ícone de engrenagem será usado. Quando você aplica filtros, um ícone de engrenagem é usado para todos os processos.
- Rótulos. Na visualização de linhagem no nível da coluna, um rótulo descreve o tipo de dependência entre colunas:
Exact copyouOther.
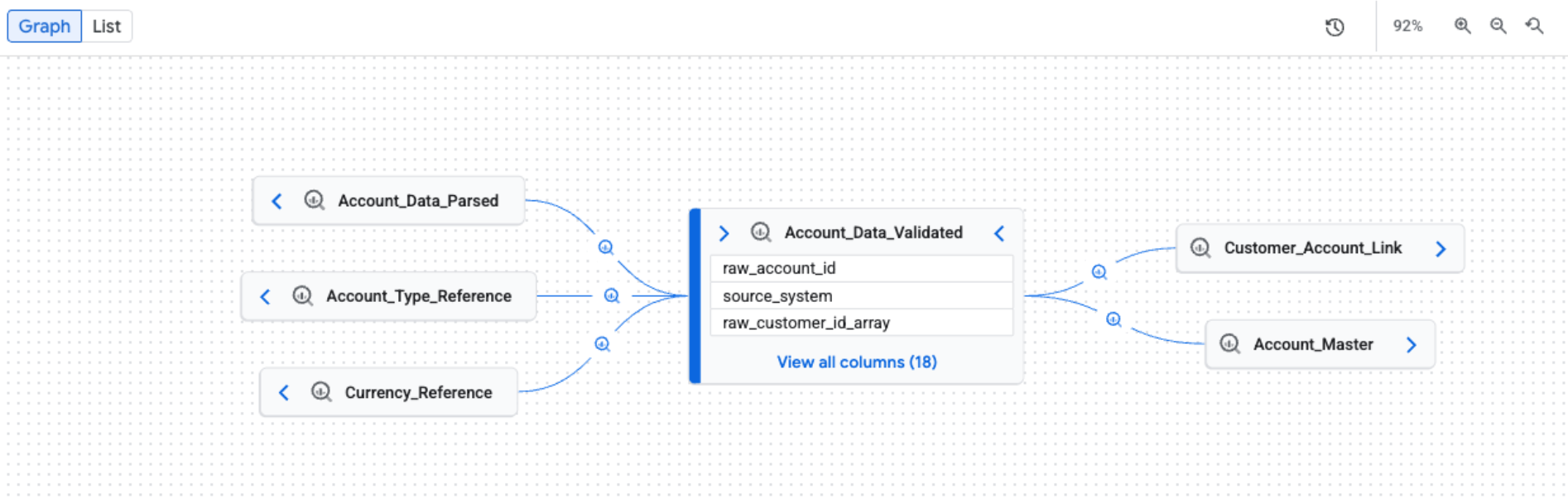
Explorar manualmente o gráfico de linhagem
Ao abrir a guia Linha de origem, você vê a visualização Gráfico padrão. A visualização padrão oferece uma visão geral de alto nível em sistemas e regiões, com expansão manual e incremental do gráfico que pode carregar cinco nós por vez. Os ícones de processo nas bordas representam o sistema de origem ou indicam vários processos.
Aplicar filtros para uma visualização de linhagem focada
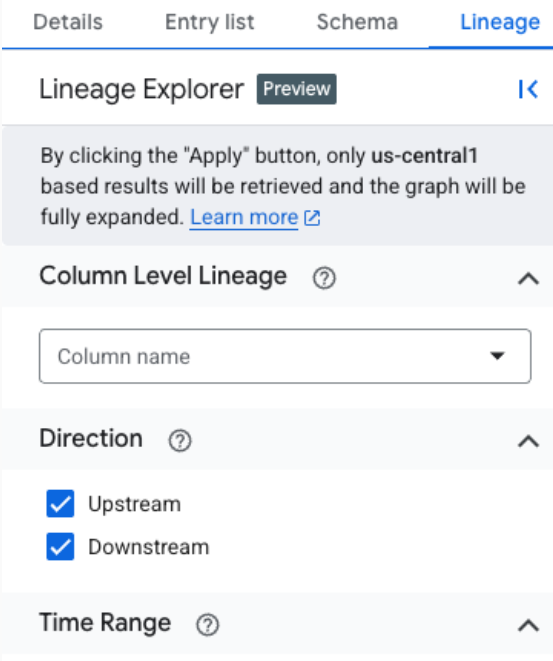
Para filtrar dados de linhagem e fazer uma análise focada em uma região específica, use o painel Explorador de linhagem. Confira alguns critérios que você pode usar para mudar para uma visualização focada:
- Nome da coluna: filtre a linhagem por nome da coluna para ver detalhes no nível da coluna.
- Direção: mostre a linhagem upstream ou downstream, ou ambas.
- Intervalo de tempo: filtre a linhagem com base em um horário de início ou término específico.
- Tipo de dependência: filtre a linhagem no nível da coluna com base no tipo de dependência.
Exemplos de opções disponíveis incluem
AllouExact copy.
A visualização focada expande automaticamente o gráfico em até três níveis, carregando toda a linhagem que corresponde aos critérios de filtro. Ele oferece suporte à linhagem no nível da tabela e da coluna, incluindo a visualização de caminho de qualquer nó selecionado de volta à raiz. Nessa visualização focada, um ícone de engrenagem genérico é usado para todos os processos.

Para conferir a linhagem no nível da coluna, siga um destes métodos:
Em uma visualização de gráfico focada, clique no ícone de coluna em uma tabela para mudar para a linhagem no nível da coluna.
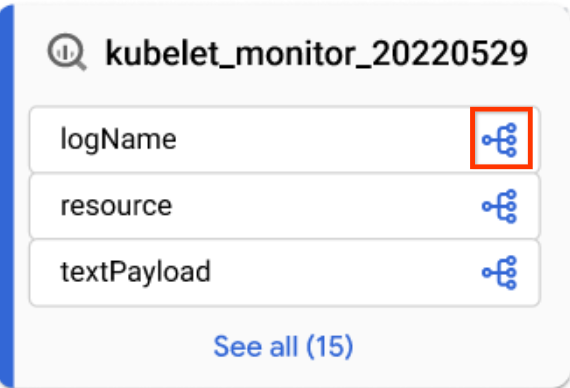
Ícone de coluna Na visualização padrão Gráfico ou na visualização focada Gráfico, aplique um nome de coluna no painel Análise de linhagem.

Para remover todos os filtros e voltar à visualização padrão, clique em redefinir.
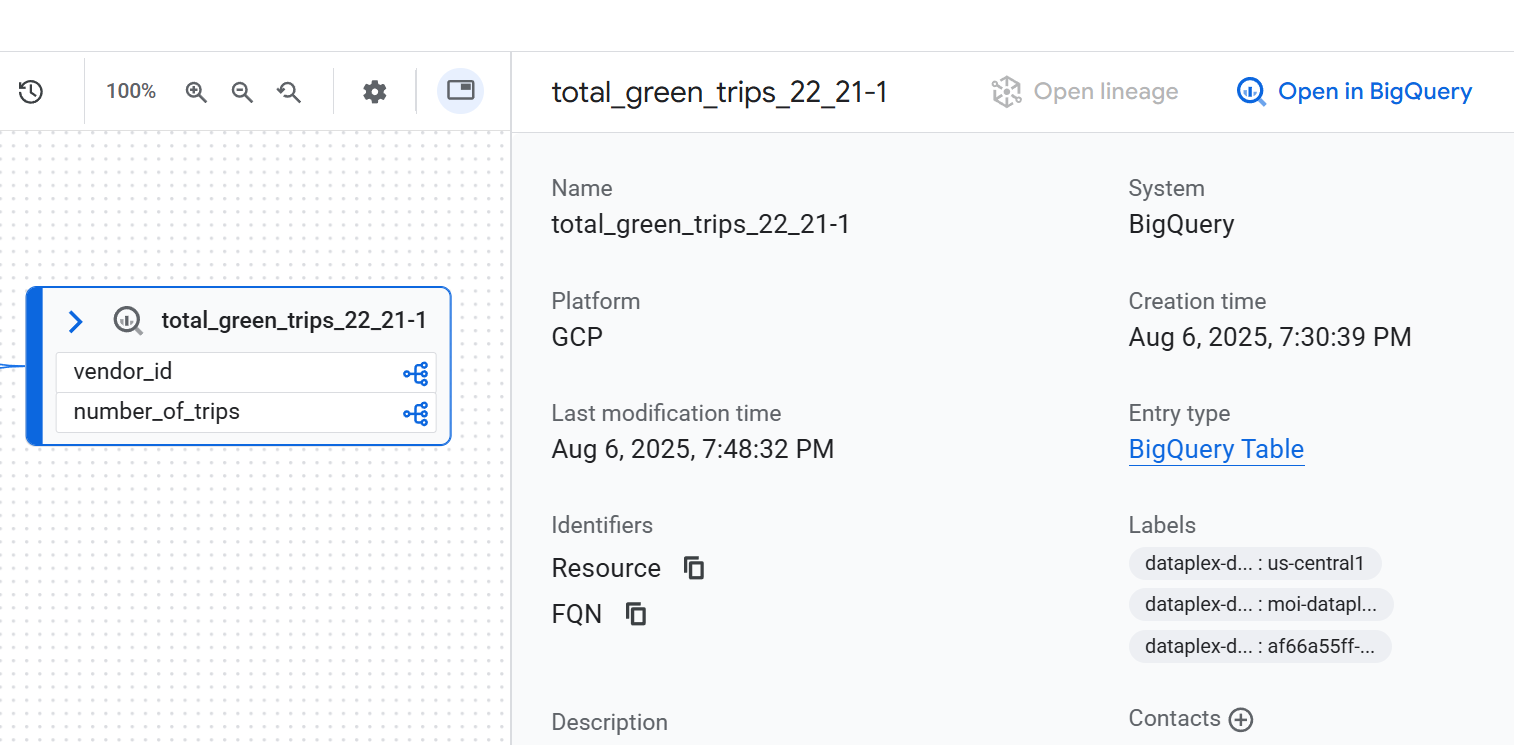
Detalhes do nó
Para conferir os detalhes de um nó, clique nele. Um painel lateral aparece e mostra informações detalhadas sobre o recurso de dados selecionado. Por exemplo, em uma visualização de linhagem no nível da tabela, clicar em um nó mostra informações como o nome totalmente qualificado, o tipo e outros atributos relevantes do recurso.
Auditoria e histórico de execuções
Um gráfico de linhagem completo é o resultado de execuções de vários jobs diferentes, com cada job criando um link específico no gráfico. Várias execuções são registradas como novas execuções, mas não mudam a aparência estática do gráfico.
Para ver os detalhes dessas execuções individuais, clique em uma aresta com um processo no gráfico. No painel Consulta, clique na guia Execuções.

Inspecionar a lógica de transformação
Para entender a lógica de negócios de uma transformação sem procurar o código, é possível conferir a consulta SQL exata que foi executada. Para conferir o código SQL, clique em uma aresta com um processo no gráfico. No painel lateral que aparece, clique na guia Detalhes.
Visualização do caminho de linhagem
A visualização do caminho de linhagem ajuda a rastrear o caminho de qualquer nó selecionado no gráfico até a entrada raiz. Quando você seleciona um nó e clica em Visualizar caminho, o gráfico destaca apenas os nós e processos que formam o caminho de linhagem direta até a entrada raiz.
Para ver a visualização do caminho de linhagem, no painel Explorador de linhagem, aplique um filtro para criar uma visualização focada do Gráfico. Em seguida, na visualização Gráfico em foco, selecione um nó. No painel de detalhes do nó selecionado, clique em Visualizar caminho.
A visualização do caminho de linhagem está disponível para linhagem no nível da tabela e da coluna. Também é possível usar a visualização do caminho de linhagem na visualização em Lista.
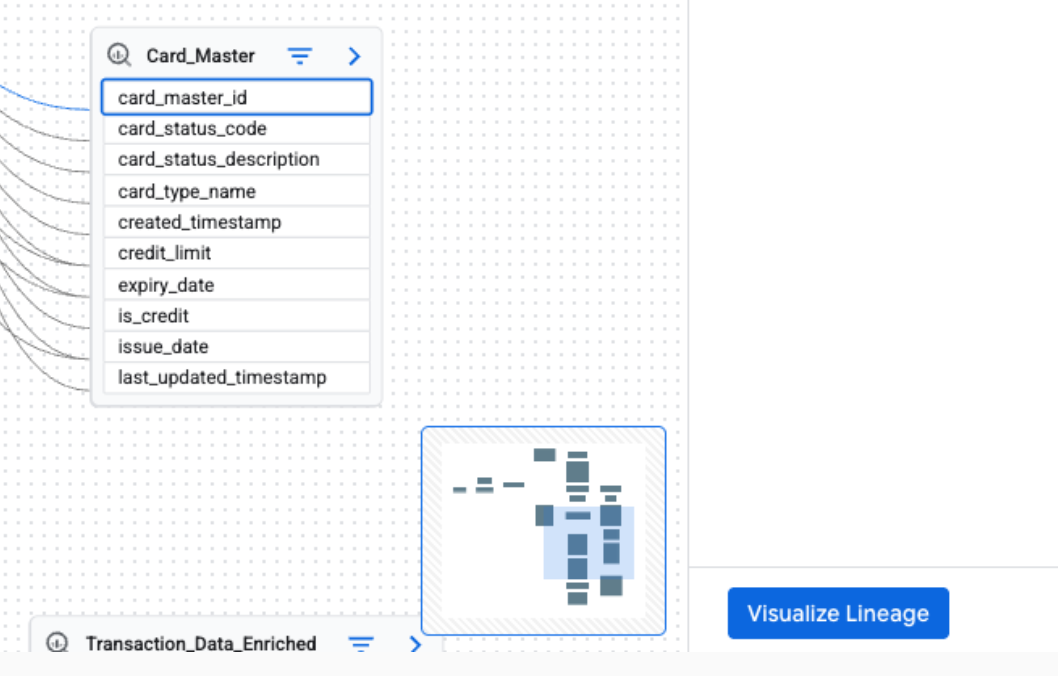
Visualização em lista da linhagem
A visualização Lista oferece uma representação tabular e estruturada da linhagem, sincronizada com a visualização Gráfico. Ela facilita a classificação, a filtragem e o download de recursos de dados. Essa visualização é ideal para analisar relações de origem-destino, detalhar os recursos envolvidos e exportar dados de linhagem.
A visualização Lista está disponível para linhagem no nível da tabela e da coluna. É possível alternar entre as seguintes visualizações de lista detalhada e simplificada.
Visualização simplificada em lista: útil para ter uma lista condensada e exclusiva de todos os recursos envolvidos na linhagem. As colunas Sistema, Projeto, Entidade, FQN (nome totalmente qualificado), Direção e Profundidade ajudam a ver todos os recursos de dados na linhagem, onde eles estão, a origem original e a distância do recurso central que está sendo analisado. É ideal para uma visão geral de alto nível de todas as entidades que participam do fluxo de dados. Essa é a visualização padrão.
Visualização de lista detalhada: criada para analisar relações individuais de origem-destino. Ao fornecer colunas separadas para Origem e Destino, você pode ver cada link de transformação de dados específico. Essa visualização é ideal para tarefas que exigem um entendimento profundo de como os dados se movem entre pares específicos de recursos, como auditoria de fluxos de dados individuais, compreensão de dependências entre tabelas ou exportação de registros detalhados de linhagem para cada conexão.
Visualização em lista da linhagem no nível da tabela
Essa visualização mostra as relações entre as tabelas como um todo. Use os filtros fornecidos para selecionar as colunas necessárias.
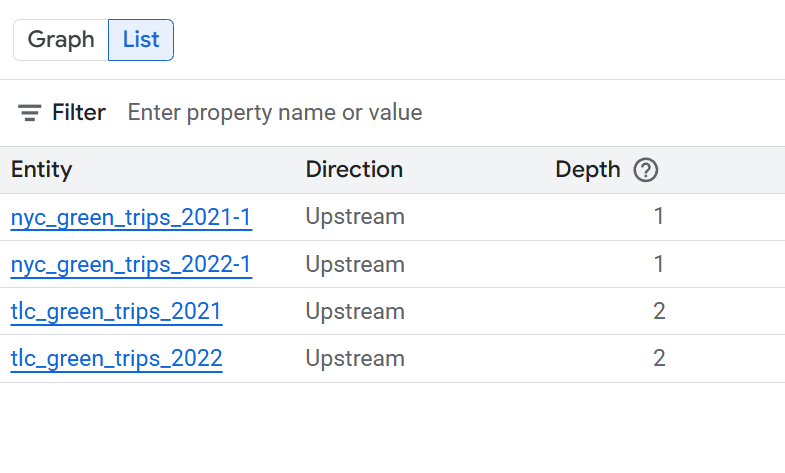
Abra as seções a seguir para conferir as colunas disponíveis nas visualizações de lista no nível da tabela.
Colunas disponíveis na visualização simplificada em lista no nível da tabela
- Sistema: o sistema em que o recurso de dados está localizado. Exemplos incluem o BigQuery.
- Projeto: o ID do projeto Google Cloud que contém o recurso de dados.
- Entidade: o nome do recurso de dados. Os exemplos incluem um nome de tabela.
- FQN: o nome totalmente qualificado (FQN) da entidade ou coluna de origem original.
- Direção: indica se o recurso listado é upstream (origem) ou downstream (destino) no fluxo de linhagem.
- Profundidade: o número de etapas de linhagem do recurso central que está sendo analisado.
Colunas disponíveis na visualização em lista detalhada no nível da tabela
- Sistema de origem: o sistema em que o recurso de dados de origem está localizado. Exemplos incluem o BigQuery.
- Projeto de origem: o ID do projeto Google Cloud que contém o recurso de dados de origem.
- Origem: o nome do recurso de dados de origem. Exemplos incluem um nome de tabela.
- FQN de origem: o FQN da entidade de origem.
- Sistema de destino: o sistema em que o recurso de dados de destino está localizado. Exemplos incluem o BigQuery.
- Projeto de destino: o ID do projeto Google Cloud que contém o recurso de dados de destino.
- Destino: o nome do recurso de dados de destino. Exemplos incluem um nome de tabela.
- FQDN de destino: o FQDN da entidade de destino.
- Direção: indica se o recurso listado é upstream (origem) ou downstream (destino) no fluxo de linhagem.
- Profundidade: o número de etapas de linhagem do recurso central que está sendo analisado.
Visualização em lista da linhagem no nível da coluna
Essa visualização mostra as relações entre colunas individuais nas tabelas de origem e de destino. Use os filtros fornecidos para selecionar as colunas necessárias.
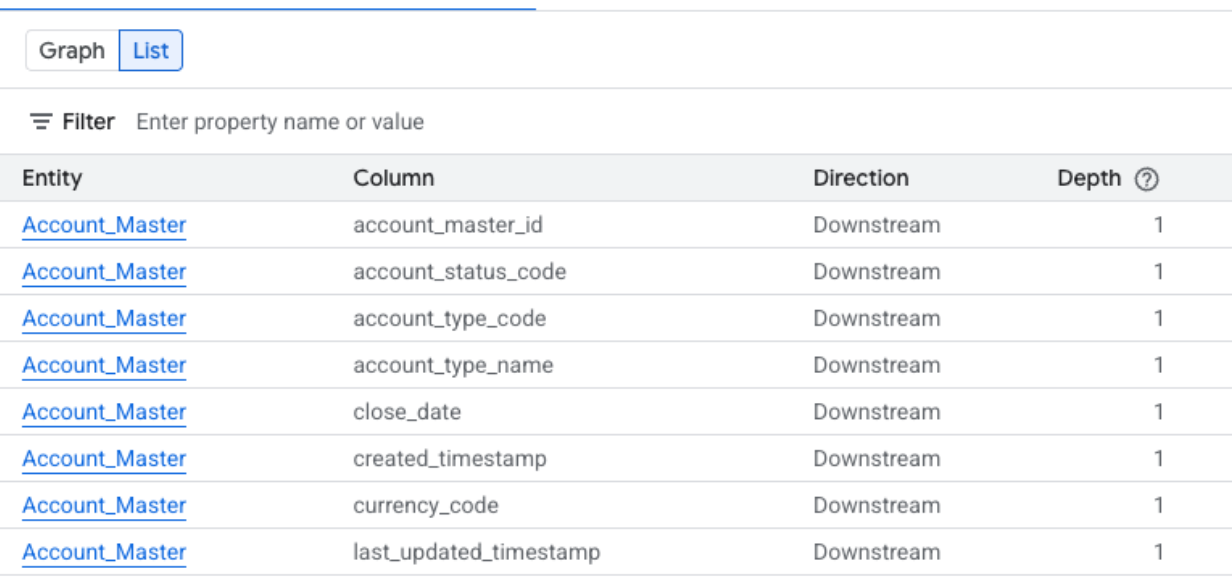
Expanda as seções a seguir para conferir as colunas disponíveis nas visualizações de lista no nível da coluna.
Colunas disponíveis na visualização simplificada em lista no nível da coluna
- Sistema: o sistema em que o recurso de dados está localizado. Exemplos incluem o BigQuery.
- Projeto: o ID do projeto Google Cloud que contém o recurso de dados.
- Entidade: o nome do recurso de dados. Os exemplos incluem um nome de tabela.
- Coluna: a coluna específica escolhida no painel Análise de linhagem dentro da entidade.
- FQN: o nome totalmente qualificado (FQN) da entidade ou coluna de origem original.
- Direção: indica se o recurso listado é upstream (origem) ou downstream (destino) no fluxo de linhagem.
- Profundidade: o número de etapas de linhagem do recurso central que está sendo analisado.
Colunas disponíveis na visualização em lista detalhada no nível da coluna
- Sistema de origem: o sistema em que o recurso de dados de origem está localizado.
- Projeto de origem: o ID do projeto Google Cloud que contém o recurso de dados de origem.
- FQN de origem: o FQN da coluna de origem.
- Sistema de destino: o sistema em que o recurso de dados de destino está localizado.
- Projeto de destino: o ID do projeto Google Cloud que contém o recurso de dados de destino.
- FQDN de destino: o FQDN da coluna de destino.
- Direção: indica se o fluxo de dados é upstream ou downstream.
- Tipos de dependência: descreve a natureza da relação entre as colunas.
- Profundidade: o número de etapas de linhagem do recurso central que está sendo analisado.
A seguir
Saiba mais sobre as origens de linhagem.
Saiba como rastrear a linhagem de dados de uma cópia de tabela do BigQuery e jobs de consulta.
Saiba como usar a linhagem de dados com sistemas Google Cloud .