As tarefas de qualidade de dados do catálogo universal do Dataplex permitem-lhe definir e executar verificações de qualidade de dados em tabelas no BigQuery e no Cloud Storage. As tarefas de qualidade de dados do catálogo universal do Dataplex também permitem aplicar controlos de dados regulares em ambientes do BigQuery.
Quando criar tarefas de qualidade de dados do Dataplex Universal Catalog
As tarefas de qualidade de dados do Dataplex Universal Catalog podem ajudar com o seguinte:
- Validar dados como parte de um pipeline de produção de dados.
- Monitorize regularmente a qualidade dos conjuntos de dados em função das suas expetativas.
- Crie relatórios de qualidade de dados para requisitos regulamentares.
Vantagens
- Especificações personalizáveis. Pode usar a sintaxe YAML altamente flexível para declarar as suas regras de qualidade dos dados.
- Implementação sem servidor. O Dataplex Universal Catalog não precisa de nenhuma configuração de infraestrutura.
- Cópia zero e envio automático. As verificações YAML são convertidas em SQL e enviadas para o BigQuery, o que resulta na não cópia de dados.
- Verificações de qualidade de dados agendáveis. Pode agendar verificações de qualidade de dados através do agendador sem servidor no catálogo universal do Dataplex ou usar a API Dataplex através de agendadores externos, como o Cloud Composer, para integração de pipelines.
- Experiência gerida. O Dataplex Universal Catalog usa um motor de qualidade de dados de código aberto, o CloudDQ, para executar verificações de qualidade de dados. No entanto, o Dataplex Universal Catalog oferece uma experiência gerida integrada para realizar as verificações de qualidade de dados.
Como funcionam as tarefas de qualidade de dados
O diagrama seguinte mostra como funcionam as tarefas de qualidade de dados do Dataplex Universal Catalog:
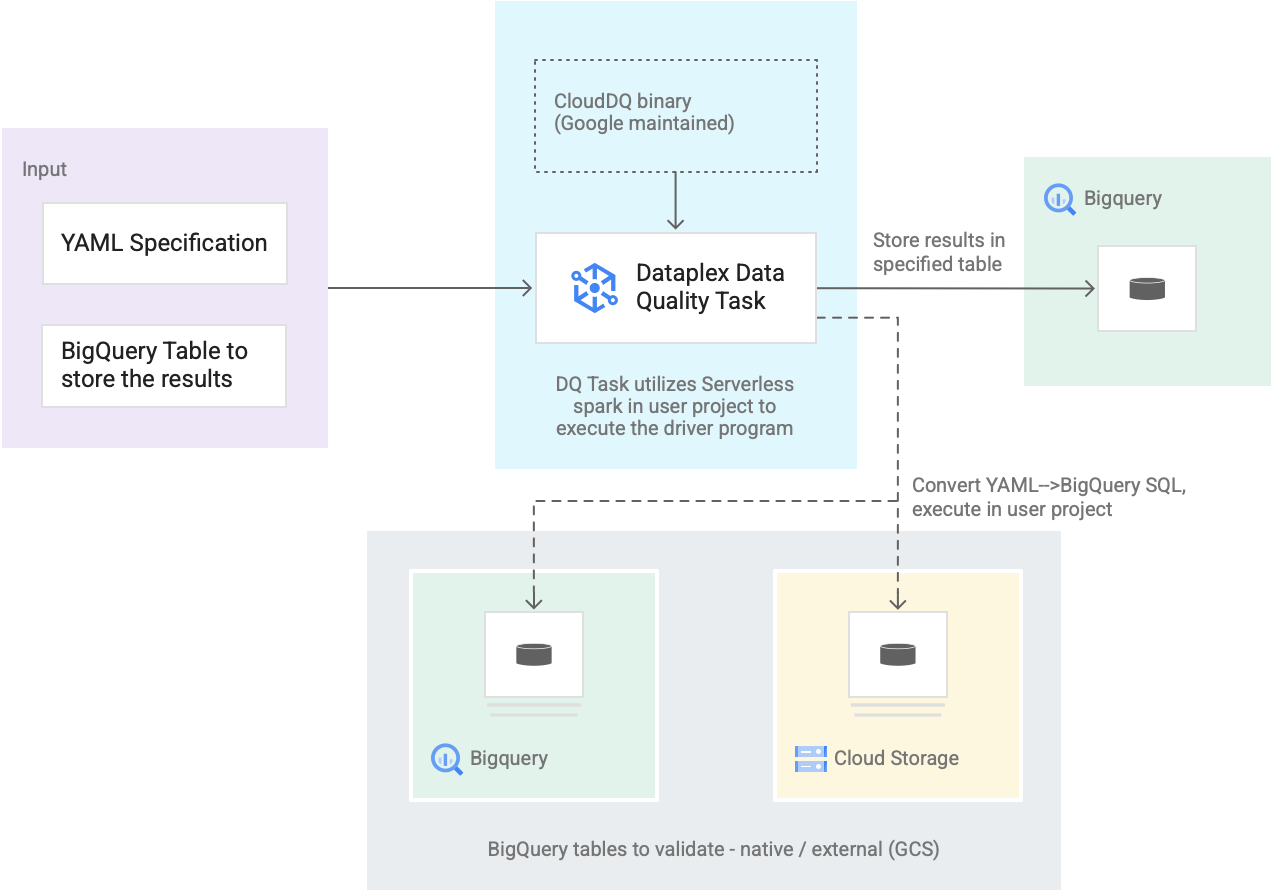
- Introdução dos utilizadores
- Especificação YAML: um conjunto de um ou mais ficheiros YAML que definem regras de qualidade dos dados com base na sintaxe de especificação. Armazene os ficheiros YAML num contentor do Cloud Storage no seu projeto. Os utilizadores podem executar várias regras em simultâneo, e essas regras podem ser aplicadas a diferentes tabelas do BigQuery, incluindo tabelas em diferentes conjuntos de dados ou Google Cloud projetos. A especificação suporta execuções incrementais apenas para validar novos dados. Para criar uma especificação YAML, consulte Crie um ficheiro de especificação.
- Tabela de resultados do BigQuery: uma tabela especificada pelo utilizador onde os resultados da validação da qualidade dos dados são armazenados. O Google Cloud projeto no qual esta tabela reside pode ser um projeto diferente daquele no qual a tarefa de qualidade dos dados do catálogo universal do Dataplex é usada.
- Tabelas a validar
- Na especificação YAML, tem de especificar as tabelas que quer validar para que regras, também conhecido como associação de regras. As tabelas podem ser tabelas nativas do BigQuery ou tabelas externas do BigQuery no Cloud Storage. A especificação YAML permite-lhe especificar tabelas dentro ou fora de uma zona do Dataplex Universal Catalog.
- As tabelas do BigQuery e do Cloud Storage validadas numa única execução podem pertencer a projetos diferentes.
- Tarefa de qualidade de dados do Dataplex Universal Catalog: uma tarefa de qualidade de dados do Dataplex Universal Catalog é configurada com um binário PySpark do CloudDQ pré-criado e mantido, e usa a especificação YAML e a tabela de resultados do BigQuery como entrada. Semelhante a outras tarefas do catálogo universal do Dataplex, a tarefa de qualidade de dados do catálogo universal do Dataplex é executada num ambiente do Spark sem servidor, converte a especificação YAML em consultas do BigQuery e, em seguida, executa essas consultas nas tabelas definidas no ficheiro de especificação.
Preços
Quando executa tarefas de qualidade de dados do catálogo universal do Dataplex, são-lhe cobrados custos de utilização do BigQuery e do Serverless para Apache Spark (batches).
A tarefa de qualidade de dados do catálogo universal do Dataplex converte o ficheiro de especificação em consultas do BigQuery e executa-as no projeto do utilizador. Consulte os preços do BigQuery.
O catálogo universal do Dataplex usa o Spark para executar o programa de controlador open source CloudDQ pré-criado e mantido pela Google para converter a especificação do utilizador em consultas do BigQuery. Consulte os preços do Serverless para Apache Spark.
Não existem custos pela utilização do Dataplex Universal Catalog para organizar dados nem pela utilização do programador sem servidor no Dataplex Universal Catalog para agendar verificações de qualidade dos dados. Consulte os preços do Dataplex Universal Catalog.