Ce tutoriel explique comment joindre un flux de données de Pub/Sub aux données d'une table BigQuery à l'aide de Dataflow SQL.
Objectifs
Dans ce tutoriel, vous allez :
- écrire une requête Dataflow SQL pour joindre un flux de données Pub/Sub aux données d'une table BigQuery ;
- déployer une tâche Dataflow à partir de l'interface utilisateur Dataflow SQL.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - Installer et initialiser gcloud CLI Choisissez l'une des options d'installation.
Il vous faudra peut-être définir la propriété
projectsur le projet utilisé pour ce tutoriel. - Accédez à l'interface utilisateur Web de Dataflow SQL dans la console Google Cloud. Le projet le plus récemment utilisé s'ouvre. Pour changer de projet, cliquez sur le nom du projet dans la partie supérieure de l'interface utilisateur Web de Dataflow SQL, et cherchez le projet que vous souhaitez utiliser.
Accéder à l'UI Web de Dataflow SQL
Créer des sources pour l'exemple présenté dans le tutoriel
Si vous souhaitez suivre l'exemple présenté dans ce tutoriel, créez les sources suivantes afin de les utiliser au cours des différentes étapes du tutoriel.
- Un sujet Pub/Sub appelé
transactions- Flux de données de transaction provenant d'un abonnement à un sujet Pub/Sub. Les données de chaque transaction comprennent des informations telles que le produit acheté, le prix d'achat, le lieu d'achat (ville et État). Après avoir créé le sujet Pub/Sub, créez un script qui publie des messages sur le sujet. Ce script sera exécuté au cours d'une étape ultérieure du tutoriel. - Une table BigQuery appelée
us_state_salesregions- Table fournissant un mappage des États avec les régions de vente. Avant de créer cette table, il vous faudra créer un ensemble de données BigQuery.
Créer un ensemble de données et une table BigQuery
- Dans l'interface utilisateur Web de BigQuery, créez un ensemble de données BigQuery. Un ensemble de données BigQuery est un conteneur de niveau supérieur utilisé pour contenir les tables. Les tables BigQuery doivent appartenir à un ensemble de données.
- Dans le panneau Explorateur, ouvrez les actions de votre projet. Dans le menu, cliquez sur Créer un ensemble de données. Dans la capture d'écran ci-dessous, l'ID de projet est
dataflow-sql.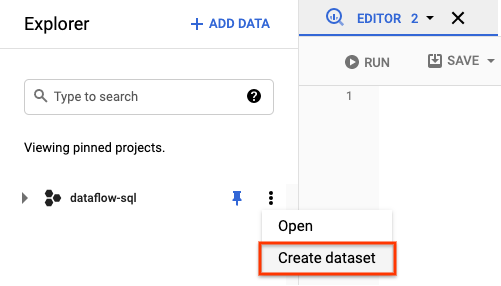
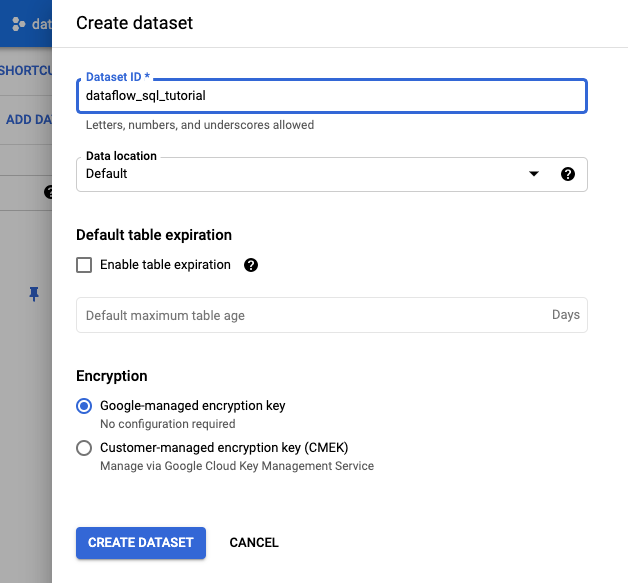
- Dans le panneau Créer un ensemble de données qui s'affiche, pour ID de l'ensemble de données, saisissez
dataflow_sql_tutorial. - Pour Emplacement des données, sélectionnez une option dans le menu.
- Cliquez sur Créer l'ensemble de données.
- Dans le panneau Explorateur, ouvrez les actions de votre projet. Dans le menu, cliquez sur Créer un ensemble de données. Dans la capture d'écran ci-dessous, l'ID de projet est
- Créez une table BigQuery.
- Créez un fichier texte et nommez-le
us_state_salesregions.csv. - Copiez les données suivantes et collez-les dans
us_state_salesregions.csv. Au cours des étapes suivantes, vous chargerez ces données dans la table BigQuery.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
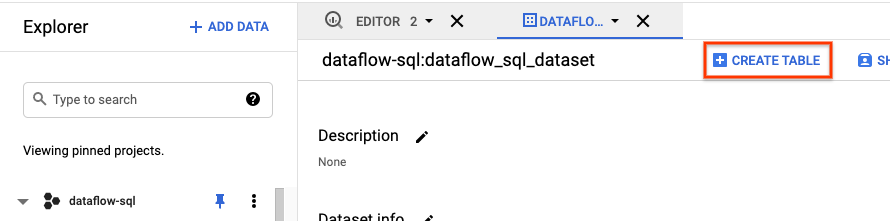
- Dans le panneau Explorateur de l'interface utilisateur de BigQuery, développez votre projet pour afficher l'ensemble de données
dataflow_sql_tutorial. - Ouvrez le menu des actions pour l'ensemble de données
dataflow_sql_tutorial, puis cliquez sur Ouvrir. - Cliquez sur Créer la table.
- Dans le panneau Créer une table qui s'affiche :
- Dans le champ Create table from (Créer une table à partir de), sélectionnez Upload (Importer).
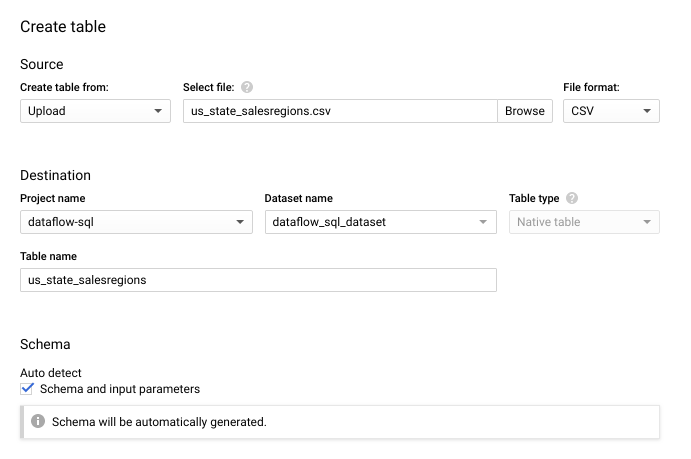
- Dans le champ Sélectionner un fichier, cliquez sur Parcourir et sélectionnez votre fichier
us_state_salesregions.csv. - Pour Table, saisissez
us_state_salesregions. - Dans le champ Schéma, sélectionnez Détection automatique.
- Cliquez sur Advanced options (Options avancées) pour développer la section.
- Pour Lignes d'en-tête à ignorer, saisissez
1puis cliquez sur Créer une table.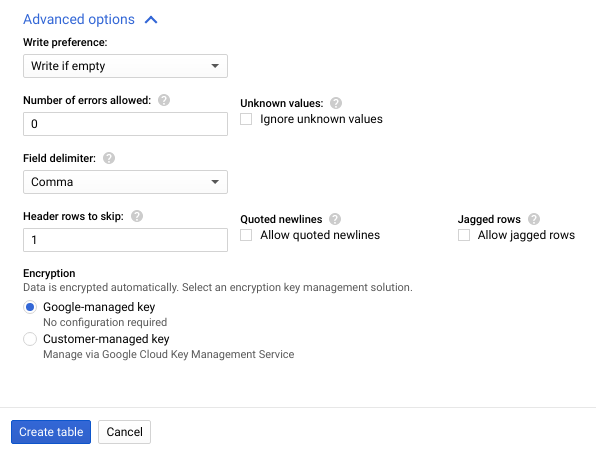
- Dans le champ Create table from (Créer une table à partir de), sélectionnez Upload (Importer).
- Dans le panneau Explorateur, cliquez sur
us_state_salesregions. Sous Schéma, vous pouvez observer le schéma généré automatiquement. Vous pouvez observer les données de la table dans Prévisualiser.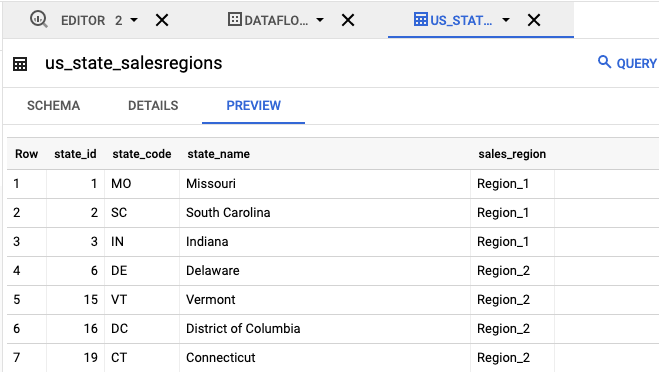
- Créez un fichier texte et nommez-le
Attribuer un schéma au sujet Pub/Sub
L'attribution d'un schéma vous permet d'exécuter des requêtes SQL sur les données de votre sujet Pub/Sub. Dataflow SQL attend des messages sérialisés au format JSON dans les sujets Pub/Sub.
Pour attribuer un schéma aux transactions de l'exemple de sujet Pub/Sub :
Créez un fichier texte et nommez-le
transactions_schema.yaml. Copiez le schéma suivant et collez-le danstransactions_schema.yaml.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATAttribuez le schéma à l'aide de Google Cloud CLI.
a. Mettez à jour gcloud CLI à l'aide de la commande suivante. Assurez-vous que gcloud CLI est de version 242.0.0 ou ultérieure.
gcloud components update
b. Exécutez la commande suivante dans une fenêtre de ligne de commande. Remplacez project-id par votre ID de projet et path-to-file par le chemin d'accès à votre fichier
transactions_schema.yaml.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
Pour plus d'informations sur les paramètres de la commande et sur les formats de fichiers de schéma autorisés, consultez la page de documentation gcloud data-catalog entries update.
c. (Facultatif) Vérifiez que le schéma est bien attribué au sujet Pub/Sub
transactions. Remplacez project-id par l'ID de votre projet :gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
Trouver des sources Pub/Sub
L’interface utilisateur Dataflow SQL permet de rechercher des objets sources de données Pub/Sub pour chaque projet auquel vous avez accès. Il n'est donc pas nécessaire de mémoriser leurs noms complets.
Pour l'exemple de ce tutoriel, accédez à l'éditeur SQL Dataflow et recherchez le sujet Pub/Sub transactions que vous avez créé :
Accédez à SQL Workspace.
Dans le panneau Éditeur SQL de Dataflow, recherchez
projectid=project-id transactionsdans la barre de recherche. Remplacez project-id par l'ID de votre projet.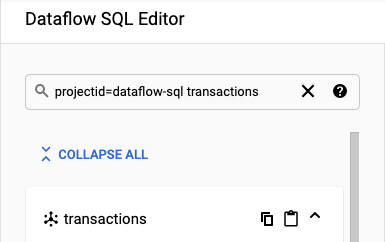
Afficher le schéma
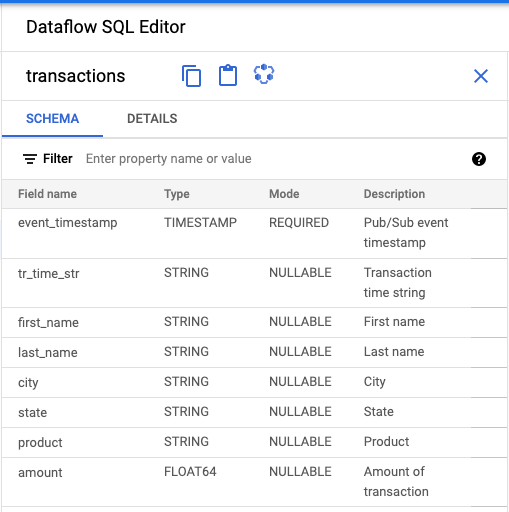
- Dans le panneau Éditeur Dataflow SQL de l'interface utilisateur Dataflow SQL, cliquez sur Transactions ou recherchez un sujet Pub/Sub en saisissant
projectid=project-id system=cloud_pubsub, puis sélectionnez le sujet. Sous Schéma, vous pouvez observer le schéma attribué au sujet Pub/Sub.
Créer une requête SQL
L'interface utilisateur Dataflow SQL permet de créer des requêtes SQL pour exécuter les tâches Dataflow.
La requête SQL suivante est une requête d'enrichissement des données. Elle ajoute un champ supplémentaire (sales_region) au flux d’événements Pub/Sub (transactions) à l'aide d'une table BigQuery (us_state_salesregions) qui met en correspondance les États et les zones de vente.
Copiez la requête SQL suivante et collez-la dans l'éditeur de requête. Remplacez project-id par l'ID de votre projet.
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Lorsque vous saisissez une requête dans l'interface utilisateur Dataflow SQL, l'outil de validation des requêtes vérifie la syntaxe de la requête. Une icône en forme de coche verte s'affiche lorsque la requête est valide. Si la requête n'est pas valide, une icône en forme de point d'exclamation rouge s'affiche. Dans le cas où la syntaxe de votre requête n'est pas valide, cliquez sur l'icône de l'outil de validation pour obtenir des informations sur les problèmes à résoudre.
La capture d'écran suivante montre l'affichage d'une requête valide dans l'éditeur de requête. L'icône de validation est une coche verte.

Créer une tâche Dataflow pour exécuter une requête SQL
Pour exécuter votre requête SQL, créez une tâche Dataflow depuis l'interface utilisateur Dataflow SQL.
Au-dessus de l'Éditeur de requête, cliquez sur Créer une tâche.
Dans le panneau Créer une tâche Dataflow qui s'affiche :
- Pour Destination, sélectionnez BigQuery.
- Dans le champ ID de l'ensemble de données, sélectionnez
dataflow_sql_tutorial. - Pour le Nom de la table, saisissez
sales.
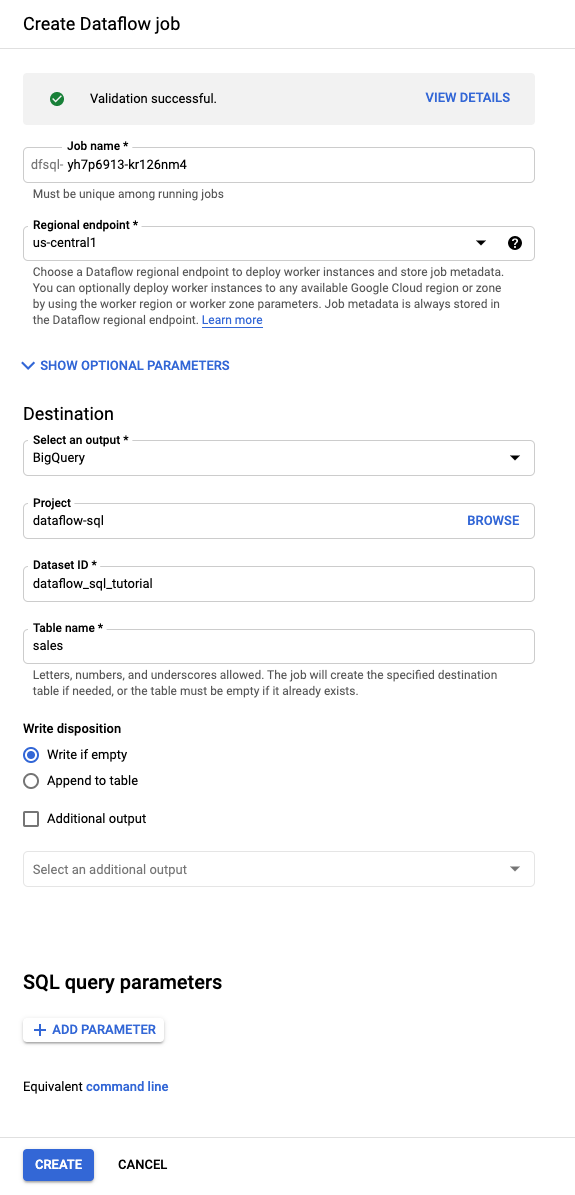
Facultatif : Dataflow choisit automatiquement les paramètres optimaux pour votre tâche Dataflow SQL, mais vous pouvez développer le menu Paramètres facultatifs pour spécifier manuellement les options de pipeline suivantes :
- Nombre maximal de nœuds de calcul
- Zone
- Adresse e-mail du compte de service
- Type de machine
- Tests supplémentaires
- Configuration des adresses IP des nœuds de calcul
- Réseau
- Sous-réseau
Cliquez sur Créer. Le démarrage de la tâche Dataflow prend quelques minutes.
Afficher la tâche Dataflow
Dataflow transforme la requête SQL en pipeline Apache Beam. Cliquez sur Afficher la tâche pour ouvrir l'interface utilisateur Web de Dataflow, où vous pouvez voir une représentation graphique de votre pipeline.
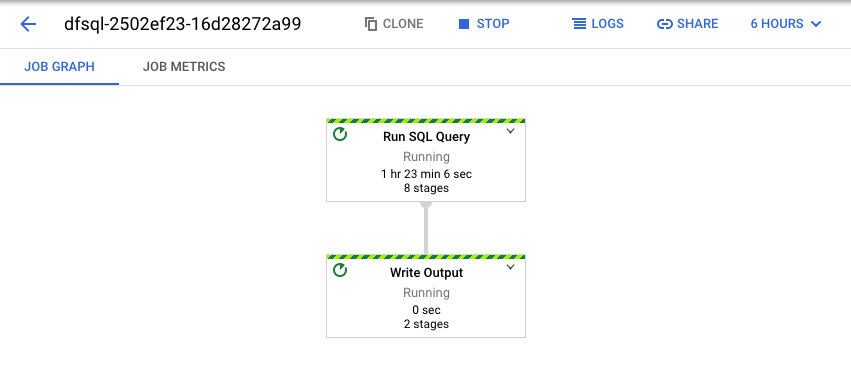
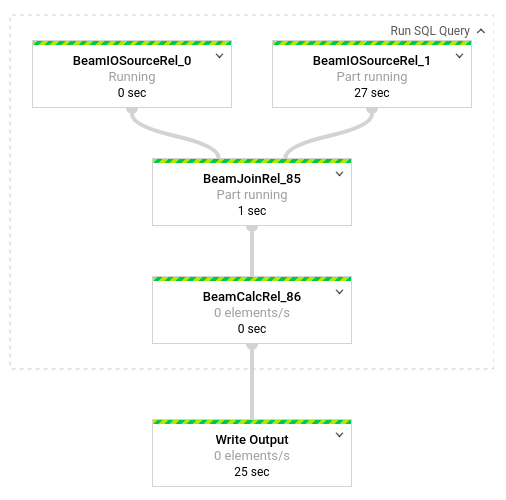
Pour afficher la répartition des transformations se produisant dans le pipeline, cliquez sur les cases. Par exemple, si vous cliquez sur la première case de la représentation graphique, nommée Exécuter la requête SQL, un graphique s'affiche montrant les opérations effectuées en arrière-plan.
Les deux premières cases représentent les deux entrées jointes : le sujet Pub/Sub (transactions) et la table BigQuery (us_state_salesregions).
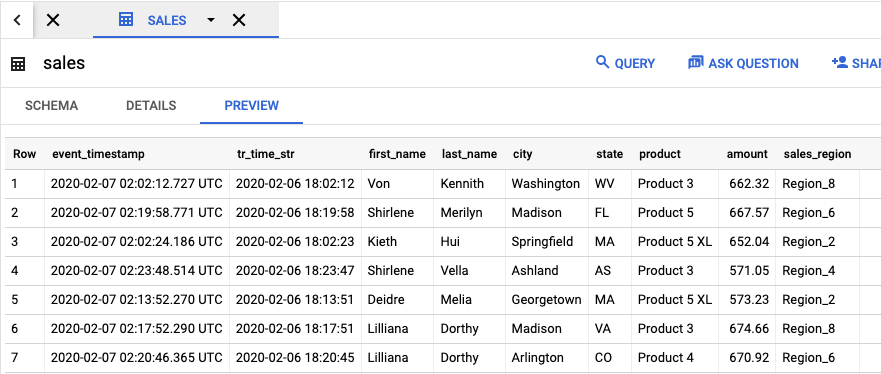
Pour afficher la table de sortie qui contient les résultats de la tâche, accédez à l'interface utilisateur de BigQuery.
Dans le panneau Explorateur de votre projet, cliquez sur l'ensemble de données dataflow_sql_tutorial que vous avez créé. Ensuite, cliquez sur la table de sortie sales. L'onglet Preview (Prévisualiser) affiche le contenu de la table de sortie.
Afficher les anciennes tâches et modifier les requêtes
L'interface utilisateur Dataflow stocke les tâches et les requêtes passées dans la page Tâches de Dataflow.
Vous pouvez utiliser la liste de l'historique des tâches pour afficher les requêtes SQL précédentes. Vous pouvez, par exemple, modifier la requête pour agréger les ventes par région toutes les 15 secondes. Accédez à la page Tâches pour accéder à la tâche en cours d'exécution que vous avez démarrée en début de tutoriel, copier la requête SQL et exécuter une autre tâche avec une requête modifiée.
Sur la page Tâches de Dataflow, cliquez sur la tâche que vous souhaitez modifier.
Sur la page Informations sur la tâche, dans le panneau Informations sur la tâche, sous Options du pipeline, localisez la requête SQL. Recherchez la ligne correspondant à queryString.
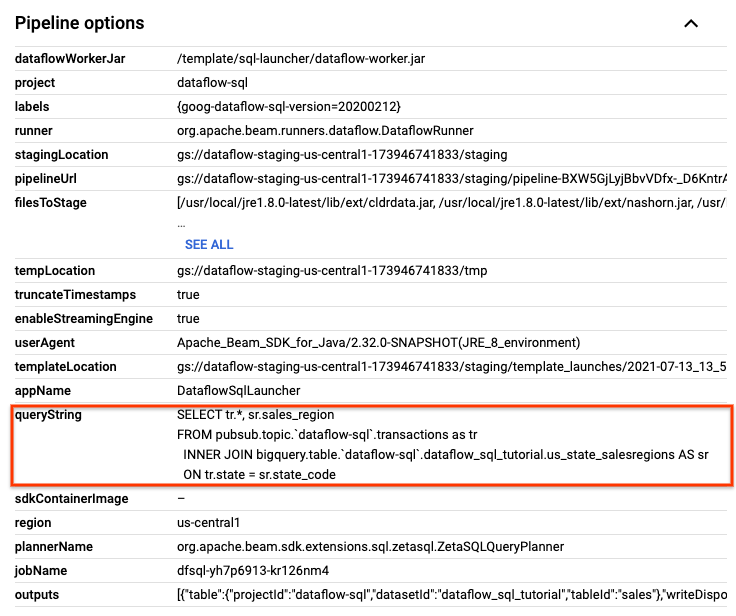
Copiez la requête SQL suivante et collez-la dans l'éditeur Dataflow SQL de l'espace de travail SQL afin d'ajouter les fenêtres de bascule. Remplacez project-id par l'ID de votre projet.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
Cliquez sur Créer un job pour créer un job avec la requête modifiée.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte de facturation Cloud, procédez comme suit :
Arrêtez le script de publication
transactions_injector.pys'il est encore en cours d'exécution.Arrêtez vos tâches Dataflow. Accédez à l'interface utilisateur Web de Dataflow dans la console Google Cloud.
Accéder à l'interface utilisateur Web de Dataflow
Pour chaque tâche créée lors de ce tutoriel, procédez comme suit :
Cliquez sur le nom de la tâche.
Sur la page Informations sur la tâche, cliquez sur Arrêter. La boîte de dialogue Stop Job (Arrêter la tâche) affiche les options d'arrêt de la tâche.
Sélectionnez Annuler.
Cliquez sur Stop job (Arrêter la tâche). Cela permet de stopper toutes les ingestions et tous les traitements de données dans les meilleurs délais possibles. La commande Cancel (Annuler) interrompt immédiatement le traitement de données. Cela peut donc entraîner la perte des données en cours de transfert. L'arrêt d'une tâche peut prendre plusieurs minutes.
Supprimez l'ensemble de données BigQuery. Accédez à l'UI Web de BigQuery dans la console Google Cloud.
Accéder à l'UI Web de BigQuery
Dans la section Ressources du panneau Explorateur, cliquez sur l'ensemble de données dataflow_sql_tutorial que vous avez créé.
Dans le panneau des détails, cliquez sur Supprimer. Une boîte de dialogue de confirmation s'affiche.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant
delete, puis cliquez sur Supprimer.
Supprimez le sujet Pub/Sub. Accédez à la page des sujets Pub/Sub dans la console Google Cloud.
Accéder à la page des sujets Pub/Sub
Sélectionnez le sujet
transactions.Cliquez sur Delete (Supprimer) pour supprimer définitivement le sujet. Une boîte de dialogue de confirmation s'affiche.
Dans la boîte de dialogue Supprimer le sujet, confirmez la commande de suppression en saisissant
delete, puis cliquez sur Supprimer.Accédez à la page Abonnements Pub/Sub.
Sélectionnez les abonnements restants à
transactions. Si les tâches ne sont plus en cours d'exécution, il n'y a peut-être aucun abonnement présent.Cliquez sur Delete (Supprimer) pour supprimer définitivement l'abonnement. Dans la boîte de dialogue de confirmation, cliquez sur Supprimer.
Supprimez le bucket de préproduction Dataflow dans Cloud Storage. Accédez à la page Buckets de Cloud Storage dans la console Google Cloud.
Sélectionnez le bucket de préproduction Dataflow.
Cliquez sur Delete (Supprimer) pour supprimer définitivement le bucket. Une boîte de dialogue de confirmation s'affiche.
Dans la boîte de dialogue Supprimer le bucket, confirmez la commande de suppression en saisissant
DELETE, puis cliquez sur Supprimer.
Étape suivante
- Découvrez Dataflow SQL.
- Apprenez-en plus sur les principes de base du pipeline de streaming.
- Explorez la documentation de référence de Dataflow SQL.
- Regardez la démonstration sur l'analyse par flux présentée à Cloud Next 2019.