É possível usar a API RunInference para criar pipelines que contêm vários modelos. Os pipelines de
vários modelos são úteis para tarefas como teste A/B e criação de conjuntos para
resolver problemas de negócios que exigem mais de um modelo de ML.
Usar vários modelos
Os exemplos de código a seguir mostram como usar a transformação RunInference para adicionar
vários modelos ao pipeline.
Ao criar pipelines com vários modelos, é possível usar um destes dois padrões:
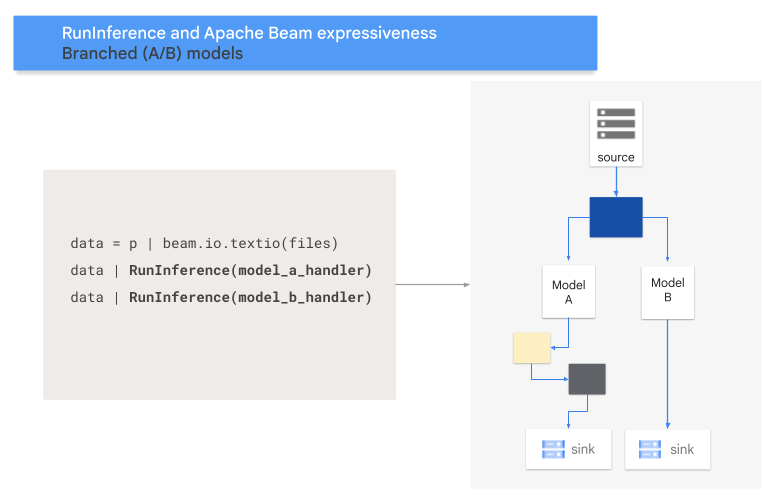
- Padrão de ramificação A/B: uma parte dos dados de entrada vai para um modelo e o restante para outro.
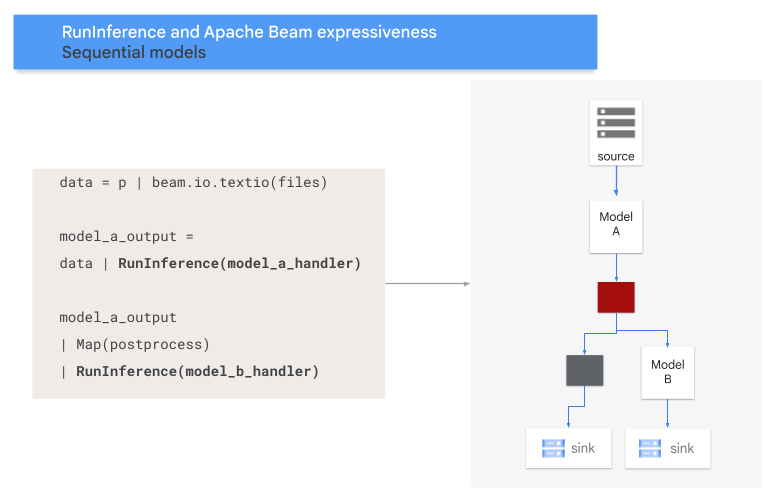
- Padrão de sequência: os dados de entrada são transferidos entre dois modelos, um após o outro.
Padrão A/B
O código a seguir mostra como adicionar um padrão A/B ao pipeline com a
transformação RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B são o código de configuração do gerenciador de modelos.
O diagrama a seguir mostra uma apresentação visual desse processo.
Padrão de sequência
O código a seguir mostra como adicionar um padrão de sequência ao pipeline com a
transformação RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B são o código de configuração do gerenciador de modelos.
O diagrama a seguir mostra uma apresentação visual desse processo.
Mapear modelos para chaves
É possível carregar vários modelos e mapeá-los em chaves usando um
gerenciador de modelos com chaves.
O mapeamento de modelos para chaves possibilita o uso de modelos diferentes na mesma transformação RunInference.
No exemplo a seguir, usamos um gerenciador de modelo com chave que
carrega um modelo usando CONFIG_1 e um segundo usando CONFIG_2.
O pipeline usa o modelo associado a CONFIG_1 para executar a inferência
em exemplos associados a KEY_1.
O modelo associado a CONFIG_2 executa a inferência em
exemplos associados a KEY_2 e KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Para ver um exemplo mais detalhado, consulte Executar inferência de ML com vários modelos treinados de maneira diferente.
Gerenciar memória
Ao carregar vários modelos ao mesmo tempo, você pode encontrar erros de falta de memória (OOMs, na sigla em inglês). Quando você usa um gerenciador de modelos com chave, o Apache Beam não limita automaticamente o número de modelos carregados na memória. Quando nem todos os modelos cabem na memória, ocorre um erro de falta de memória e o pipeline falha.
Para evitar esse problema, use o parâmetro max_models_per_worker_hint para limitar o
número de modelos carregados na memória ao mesmo tempo. No exemplo a seguir, usamos um gerenciador de modelo com chave com o parâmetro max_models_per_worker_hint.
Como o valor do parâmetro max_models_per_worker_hint está definido como 2,
o pipeline carrega no máximo dois modelos em cada processo de worker do SDK ao mesmo tempo.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Ao projetar o pipeline, verifique se os workers têm memória suficiente para os modelos e as transformações do pipeline. Como a memória usada pelos modelos pode não ser liberada imediatamente, inclua um buffer de memória extra para evitar OOMs.
Se você tiver muitos modelos e usar um valor baixo com o parâmetro max_models_per_worker_hint, poderá encontrar sobrecarga de memória. A sobrecarga de memória ocorre quando
um tempo de execução excessivo é usado para trocar modelos na memória. Para evitar
esse problema, inclua uma
transformação GroupByKey
no pipeline antes da etapa de inferência. A transformação GroupByKey
garante que elementos com a mesma chave e modelo estejam localizados no mesmo worker.
Saiba mais
- Leia sobre pipelines de vários modelos na documentação do Apache Beam.
- Execute inferência de ML com vários modelos treinados de maneiras diferentes.
- Execute um notebook interativo no Colab.