RunInference API를 사용하여 여러 모델이 포함된 파이프라인을 빌드할 수 있습니다. 멀티 모델 파이프라인은 2개 이상의 ML 모델이 필요한 비즈니스 문제를 해결하기 위해 A/B 테스트와 앙상블 빌드와 같은 태스크에 유용합니다.
여러 모델 사용
다음 코드 예시에서는 RunInference 변환을 사용하여 파이프라인에 여러 모델을 추가하는 방법을 보여줍니다.
여러 모델로 파이프라인을 빌드할 때는 다음 두 가지 패턴 중 하나를 사용할 수 있습니다.
- A/B 브랜치 패턴: 입력 데이터의 한 부분이 하나의 모델로 이동하고 데이터 나머지는 두 번째 모델로 이동합니다.
- 시퀀스 패턴: 입력 데이터가 하나씩 순서대로 두 모델을 통과합니다.
A/B 패턴
다음 코드는 RunInference 변환으로 파이프라인에 A/B 패턴을 추가하는 방법을 보여줍니다.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A 및 MODEL_HANDLER_B는 모델 핸들러 설정 코드입니다.
다음 다이어그램은 이 프로세스의 시각적 표현을 제공합니다.
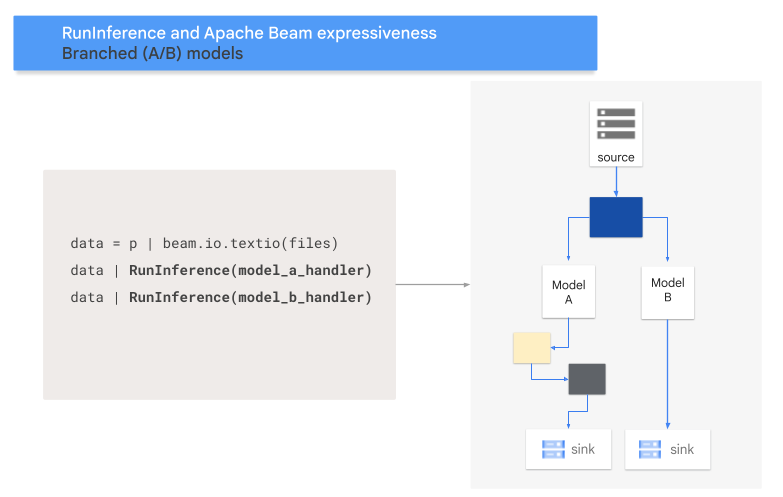
시퀀스 패턴
다음 코드는 RunInference 변환으로 파이프라인에 시퀀스 패턴을 추가하는 방법을 보여줍니다.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A 및 MODEL_HANDLER_B는 모델 핸들러 설정 코드입니다.
다음 다이어그램은 이 프로세스의 시각적 표현을 제공합니다.
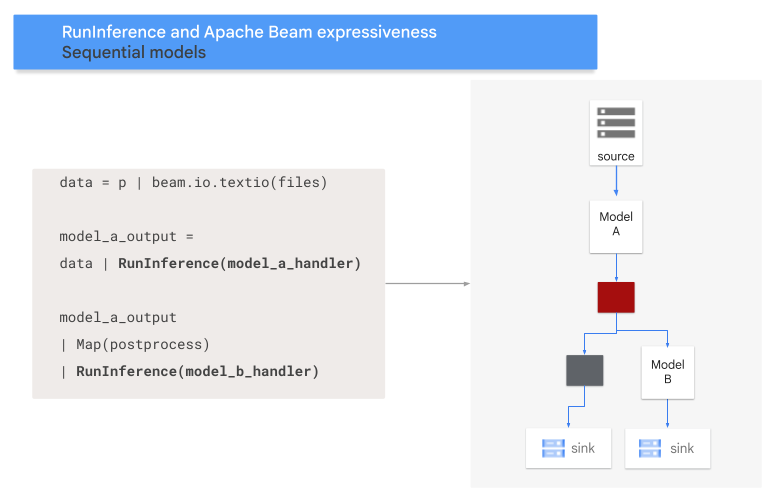
모델을 키에 매핑
키가 지정된 모델 핸들러를 사용하여 여러 모델을 로드하고 키에 매핑할 수 있습니다.
모델을 키에 매핑하면 같은 RunInference 변환에서 서로 다른 모델을 사용할 수 있습니다.
다음 예시에서는 CONFIG_1을 사용하여 모델 하나를 로드하고 CONFIG_2를 사용하여 두 번째 모델을 로드하는 키가 지정된 모델 핸들러를 사용합니다.
파이프라인은 CONFIG_1과 관련된 모델을 사용하여 KEY_1과 관련된 예시에서 추론을 실행합니다.
CONFIG_2와 관련된 모델은 KEY_2 및 KEY_3과 관련된 예시에서 추론을 실행합니다.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
자세한 예시는 서로 다르게 학습된 모델 여러 개로 ML 추론 실행을 참조하세요.
메모리 관리
여러 모델을 동시에 로드하면 메모리 부족 오류(OOM)가 발생할 수 있습니다. 키가 지정된 모델 핸들러를 사용할 때 Apache Beam은 메모리에 로드되는 모델 수를 자동으로 제한하지 않습니다. 모델이 메모리에 맞지 않으면 메모리 부족 오류가 발생하고 파이프라인이 실패합니다.
이 문제를 방지하려면 max_models_per_worker_hint 파라미터를 사용하여 동시에 메모리에 로드되는 모델 수를 제한합니다. 다음 예시에서는 max_models_per_worker_hint 파라미터와 함께 키가 지정된 모델 핸들러를 사용합니다.
max_models_per_worker_hint 파라미터 값이 2로 설정되어 있으므로 파이프라인은 각 SDK 작업자 프로세스에서 동시에 모델을 최대 2개까지 로드합니다.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
파이프라인을 설계할 때 작업자에게 모델 및 파이프라인 변환에 대한 메모리가 충분하게 있는지 확인합니다. 모델에서 사용하는 메모리가 즉시 해제되지 않을 수 있으므로 OOM을 방지하려면 추가 메모리 버퍼를 포함합니다.
모델이 많고 max_models_per_worker_hint 파라미터에 낮은 값을 사용하면 메모리 스래싱이 발생할 수 있습니다. 메모리 스래싱은 메모리를 막론하고 메모리를 바꾸는 데 과도한 실행 시간이 사용되면 발생합니다. 이 문제를 방지하려면 추론 단계 전에 파이프라인에 GroupByKey 변환을 포함합니다. GroupByKey 변환은 키와 모델이 동일한 요소가 같은 작업자에 위치하도록 합니다.
자세히 알아보기
- Apache Beam 문서의 멀티모델 파이프라인 읽어보기
- 서로 다르게 학습된 모델 여러 개로 ML 추론 실행
- Colab에서 대화형 노트북 실행하기