Puoi utilizzare l'API RunInference per creare pipeline contenenti più modelli. Le pipeline
multimodello sono utili per attività come i test A/B e la creazione di ensemble per risolvere problemi aziendali che richiedono più di un modello ML.
Utilizzare più modelli
I seguenti esempi di codice mostrano come utilizzare la trasformazione RunInference per aggiungere più modelli alla pipeline.
Quando crei pipeline con più modelli, puoi utilizzare uno dei due pattern:
- Modello di ramo A/B: una parte dei dati di input viene assegnata a un modello e il resto dei dati a un secondo modello.
- Pattern di sequenza:i dati di input attraversano due modelli, uno dopo l'altro.
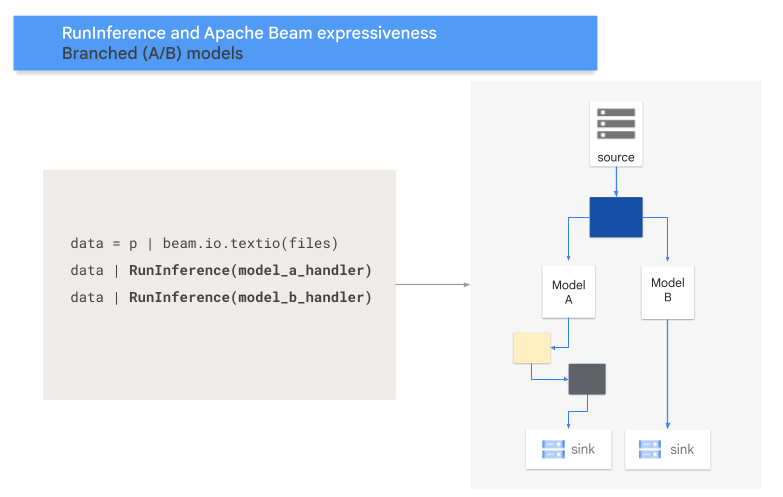
Pattern A/B
Il seguente codice mostra come aggiungere un pattern A/B alla pipeline con la trasformazione RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B sono il codice di configurazione del gestore del modello.
Il seguente diagramma fornisce una presentazione visiva di questa procedura.
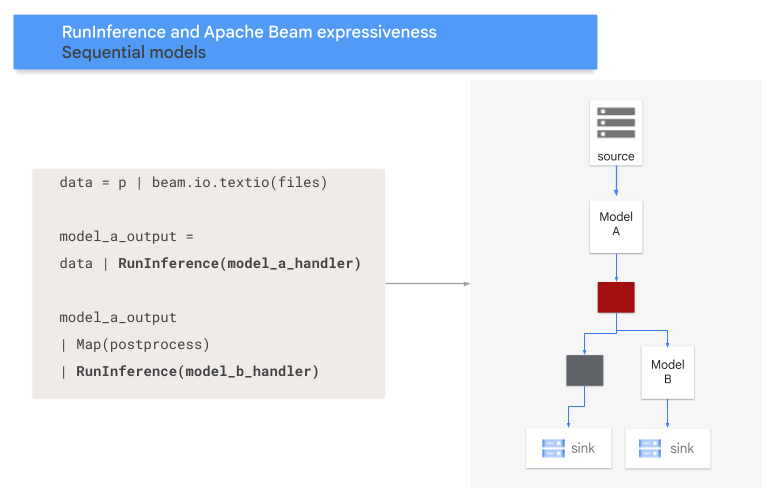
Pattern di sequenza
Il seguente codice mostra come aggiungere un pattern di sequenza alla pipeline con la trasformazione RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B sono il codice di configurazione del gestore del modello.
Il seguente diagramma fornisce una presentazione visiva di questa procedura.
Mappa i modelli alle chiavi
Puoi caricare più modelli e mapparli alle chiavi utilizzando un
handler del modello con chiavi.
La mappatura dei modelli alle chiavi consente di utilizzare modelli diversi nella stessa trasformazione RunInference.
L'esempio seguente utilizza un gestore del modello con chiave che carica un modello utilizzando CONFIG_1 e un secondo modello utilizzando CONFIG_2.
La pipeline utilizza il modello associato a CONFIG_1 per eseguire l'inferenza sugli esempi associati a KEY_1.
Il modello associato a CONFIG_2 esegue l'inferenza sugli esempi associati a KEY_2 e KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Per un esempio più dettagliato, consulta Eseguire l'inferenza ML con più modelli addestrati in modo diverso.
Gestire la memoria
Quando carichi più modelli contemporaneamente, potresti riscontrare errori di OOM (out of memory). Quando utilizzi un gestore del modello con chiave, Apache Beam non limita automaticamente il numero di modelli caricati in memoria. Quando i modelli non rientrano tutti nella memoria, si verifica un errore di memoria insufficiente e la pipeline non va a buon fine.
Per evitare questo problema, utilizza il parametro max_models_per_worker_hint per limitare il numero di modelli caricati contemporaneamente in memoria. L'esempio seguente utilizza un gestore del modello con chiave con il parametro max_models_per_worker_hint.
Poiché il valore del parametro max_models_per_worker_hint è impostato su 2,
la pipeline carica contemporaneamente un massimo di due modelli su ogni processo di worker SDK.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Quando progetti la pipeline, assicurati che i worker dispongano di memoria sufficiente sia per i modelli sia per le trasformazioni della pipeline. Poiché la memoria utilizzata dai modelli potrebbe non essere rilasciata immediatamente, per evitare errori OOM, includi un buffer di memoria aggiuntivo.
Se hai molti modelli e utilizzi un valore basso con il parametro max_models_per_worker_hint, potresti riscontrare un utilizzo eccessivo della memoria. Il thrashing della memoria si verifica quando viene utilizzato un tempo di esecuzione eccessivo per scambiare i modelli all'interno e all'esterno della memoria. Per evitare questo problema, includi una trasformazione GroupByKey nella pipeline prima del passaggio di inferenza. La trasformazione GroupByKey garantisce che gli elementi con la stessa chiave e lo stesso modello si trovino nello stesso worker.
Scopri di più
- Leggi la sezione relativa alle pipeline multimodello nella documentazione di Apache Beam
- Esegui l'inferenza ML con più modelli addestrati in modo diverso.
- Esegui un blocco note interattivo in Colab.